梁艳平 , 毛政元, 邹为彬
, 毛政元, 邹为彬
LIANG Yanping, MAO Zhengyuan, ZOU Weibin
通讯作者:
收稿日期: 2018-06-11
修回日期: 2018-07-19
网络出版日期: 2018-10-25
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:梁艳平(1993-),男,硕士生,研究方向为短时交通流量预测、智能算法。E-mail: 497336236@qq.com
展开
摘要
短时交通流量预测是交通控制和诱导涉及的关键技术问题,由于短时交通流量存在不确定性和时变性,其预测难度较大,是相关研究领域与工程实践中亟待解决的难题。为提高短时交通流量预测的准确性,本文设计与实现了基于相似数据聚合和变K值KNN(KNN-SDA)的短时交通流量预测算法。该算法首先采用互信息法在经过预处理的交通流量数据集提取交通流量序列最佳延迟时间信息,生成状态向量,并构建交通流量历史数据库;然后以本文所提出的相似数据聚合方法完成历史数据的聚合与清洗得到训练数据集;最后通过交叉验证确定每个时刻的最优K近邻数,完成算法实现。实验结果表明,本文提出的变K值KNN-SDA算法在保证执行效率的同时能明显提高短时交通流量的预测精度。
关键词:
Abstract
Real-time and accurate short-term traffic flow prediction, a critical technical problem in traffic control and guidance which is challenging and needs to be solved urgently in related research fields and engineering practice, still remains because of the hardship caused by the uncertainty and the temporal variability in traffic flow datasets acquired in different times. In order to improve the performance of the short-term traffic flow prediction, a new method based on similar data aggregation techniques and a modified KNN algorithm with varying K-value (KNN-SDA) was proposed and the related algorithm was also implemented and tested on actual measured datasets in this paper. Firstly state vectors were generated from the preprocessed traffic flow datasets by calculating the optimal time delay with the help of the mutual information theory. Each of our state vectors is composed of two parts, the first one of which is a regular state vector and the second one of which is a modified state vector which makes a contribution to a higher similarity between our state vectors and those in training datasets. Subsequently a historical traffic flow database of temporal series was constructed on the basis of results mentioned above for further experiments. After that, the proposed similar data aggregation techniques were applied to aggregate and clean data to obtain 144 training data sets in different times from historical traffic flow database, which would effectively improve the prediction accuracy and efficiency of the proposed algorithm. At last, the optimal K-values, each of which corresponded to a moment, were determined through the cross validation method. So far, the overall process of the KNN-SDA algorithm with varying K-value has been completed. In order to verify the performance of the proposed method, we compared the experimental results derived from our method with those from three other ones. It turns out that the KNN-SDA algorithm with varying K-value proposed in this article can improve the prediction accuracy significantly and ensure high execution efficiency as well.
Keywords:
随着经济的发展与城市化水平的提升,交通流量快速增加与相关基础设施建设滞后的矛盾越来越尖锐,交通拥堵已经成为国内大中城市管理中必须面对和解决的主要问题之一。智能交通控制和诱导是解决城市交通问题的有效途径,实时准确的交通流量预测、特别是时长在15 min以内的短时交通流量预测是智能交通控制和诱导的重要依据,对于解决城市交通问题更具实用价值。
道路交通是一个复杂的非线性系统,它受到多种自然和人为因素的影响,具有不确定性和时变性等特征,这些特征给交通流量的预测带来了较大困难。短时交通流量受随机干扰因素影响更大,不确定性和时变性更强,其预测也更具挑战性,是其中的难点。
现有文献中提出的短时交通流量预测模型(方法)可归纳为以下3种类型:① 经典数学模型,如贝叶斯网络[1]、卡尔曼滤波[2,3];② 人工智能模型,如神经网络[4]、极端学习机[5,6]、支持向量回归[7,8];③ 非参数回归方法,如K近邻算法[9,10,11,12,13,14,15,16,17,18,19,20]。其中,前两类模型是试图用数学表达式显式(经典数学模型)或隐式(人工智能模型)地描述影响变量X与预测变量Y之间的函数关系,这些方法侧重解决交通流量预测中的非线性函数关系问题,但对短时交通流量中的不确定性和时变性考虑较少;其次,当新观测数据加入到模型中时,需要重新计算模型参数,这个过程将非常耗时。因此,将其用于解决具有非线性、时变性与不确定性的短时交通流量预测问题时仍存在明显的局限性。
非参数回归是一类基于数据驱动的预测方法,预测过程中不需要建立影响变量与预测变量具体的函数关系,而是依据已有数据决定输入输出关系。新的观测数据可以随时加入到模型中作为历史数据样本;另外,非参数回归中不需对原始数据做平滑处理,其历史数据库中的数据保持了原始数据的特性,因此,其受不确定性与时变性影响更小,且在特殊路况出现时,非参数回归预测更为准确。因此,其被越来越多的研究者用于解决短时交通流量预测问题,大量通过实时检测器获取的交通流数据是该方法用于短时交通流量预测的前提[12]。
Davis等[11]最早将非参数回归方法应用于交通流量预测,指出KNN方法之所以适用于交通流量预测,源于交通流量数据本身所体现的非线性特性,但该算法运行时间相对较长。Smith等[12]在Davis等研究的基础上通过对状态向量进行改进,取得了比神经网络更好的效果,并指出聚类分析有助于提高预测精度。刘洋等[13]将K-means聚类分析与非参数回归结合,把交通流量分割为不同的交通流量模式,且每种模式都视为一种独立的训练数据集,提高了非参数回归的预测精度。张晓利等[16]采用聚类方法和平衡二叉树结构建立历史数据库,以提高KNN算法的搜索速度;孟梦等[17]在张晓利等的工作基础上做了进一步的改进,通过在KNN匹配中加入模式向量提高KNN算法的预测精度。Frank等[18]在KNN模式匹配中加入时间信息对算法进行改进,但该方法不能兼顾算法的运行效率。这些改进在一定程度上提高了预测精度和算法执行效率,但当数据库容量较大时,仍然难以满足实时预测的需求。现有文献中基于非参数回归方法预测短时交通流量的研究成果主要存在以下2个方面的局限性:① 因历史数据库的不合理分割所导致的不相关数据匹配问题;② 因采用全局最优K值所导致的交通流量模式误判问题。
本文提出一种基于相似数据聚合和变K值KNN的短时交通流量预测方法(变K值KNN-SDA),试图通过克服上述2个方面的局限性提高预测精度。
模式识别是KNN非参数回归预测方法的基础,即利用数据库模式匹配的思想,找到一组与输入数据对应或相似的数据进行预测[12]。在KNN短时交通流量预测中,
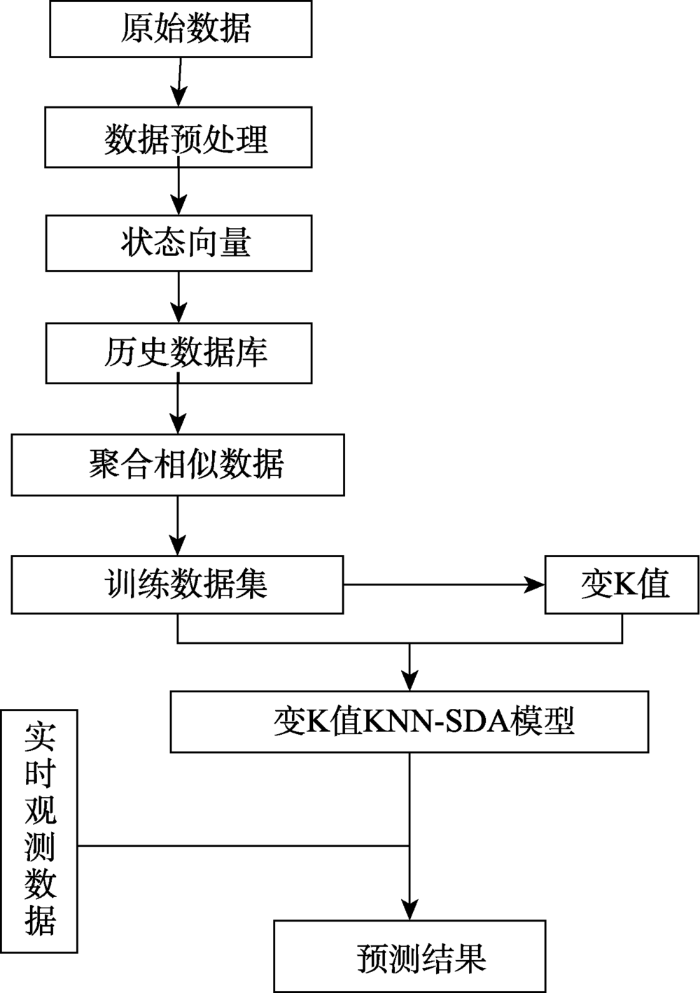
本文提出的变K值KNN-SDA短时交通流量预测的算法流程如图1所示,其中增加了一般KNN方法没有的相似数据聚合与变K值2个步骤,并针对状态向量做了改进。该算法的两项核心工作为确定变K值KNN-SDA算法所需的训练数据集与K值,算法具体过程为:
图1 基于KNN-SDA短时交通流量预测算法流程图
Fig. 1 The figure of short-term traffic flow prediction method based on KNN-SDA
(1)首先对原始交通流量数据做预处理,接着使用互信息发法求解交通流量序列的最佳延迟时间并生成状态向量,所有状态向量构成交通流量历史数据库;
(2)然后以本文提出的方法(见2.3节)聚合与清洗历史数据,得到KNN-SDA算法所需的训练数据集,不同时刻对应不同的训练数据集;
(3)再通过交叉验证确定每个时刻的最优K近邻数;
(4)最后利用距离倒数权重法预测短时交通流量,详细过程见见2.5节。
在KNN短时交通流量预测中,状态向量[15] (即输入变量)
式中:
考虑2个离散信息系统
式中:
在给定
其中,
因此有:
式中:
定义
式中:
基于KNN预测短时交通流量最重要的环节是使用距离度量准则准确地匹配与当前状态最为相似的邻居。传统方法仅以2个状态向量之间的“距离”为依据,没有考虑到两者所对应的交通流量变化趋势是否相同。本文通过在状态向量
文献[10]中指出对当前时刻预测有用的邻居可在附近时段内找到,为此将历史数据集中的状态向量按照0:00-24:00点每10 min为间隔分为144个不同的子集。聚合相似数据的目的是确定可用于待预测时刻的历史数据子集,该方法按照同样的流程分别在144个历史数据子集中划分用于聚合的相似数据,因此,不同时刻间聚合后的数据集可能存在重叠。相似数据聚合完成后,最近邻搜索过程中只需要考虑聚合后的相似数据集而不是整个历史数据库,可提高搜索匹配的效率与准确性。
为确定某时刻的数据集对于预测当前时刻交通流量的贡献,引入预测误差指标作为数据选择与聚合的标准。
2.3.1 选取相似数据
将交通流量历史数据库
式中:
相似数据聚合的过程是以当前时刻的交通流量数据集为基准从左右两侧分别聚合下一时刻的数据集,即
依次类推。分别使
2.3.2 剔除异常数据
聚合后的数据集
式中:
矩阵相似度r定义为:
式中:
设式(12)中A为
K值表示从训练数据集中选取的近邻个数,其大小对KNN预测算法的精度有直接影响,故如何选取合理的K值成为与KNN预测算法相关的重要研究内容[17]。本文摒弃传统的全局最优K值(即所有预测时刻为一个固定的K值)的方法,而分别为每个预测时刻对应的训练数据集选取最合适的K值。
对于每个时刻,本文先在区间[2,20]上为其分配一组K值,对每个K值都做十折交叉验证(即十次交叉验证)得到一个预测误差,选取预测误差最小的K值作为当前时刻的近邻数,重复此过程,得到所有时刻的近邻数。
交叉验证过程中,对2.3节得到的每个时刻的训练数据集
将经过上述匹配机制在训练数据集中获取的K个近邻点用于预测下一时刻的交通流量。本文选用带权重的预测算法[15],其计算公式为:
式中:
本文数据源通过微波传感器实时采集,采集地点为福州市五四路东大路口,采集时间为2016年4月1日至2016年6月30日,采集频率为每10 min一次。原始数据经预处理后用于本文实验。本文算法全部采用Python编程语言实现,算法均在Intel i7-6700 CPU、8G内存及Windows 10环境下运行。
本节实验为KNN-SDA算法建立所需训练数据集,其中3.1.1节为构建状态向量,3.1.2节则以3.1.1节构建的状态向量为基础建立训练数据集。
3.1.1 确定状态向量X
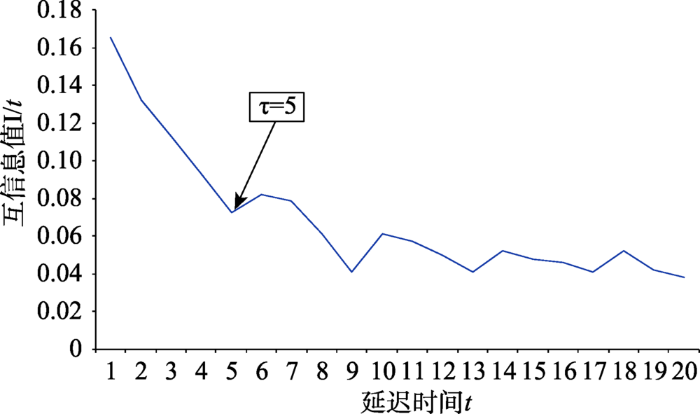
原始交通流量数据经过数据筛选、异常数据替换后即可用于建立状态向量,本小节实验使用MI算法计算交通流量序列的最佳延迟时间
3.1.2 确定训练数据集
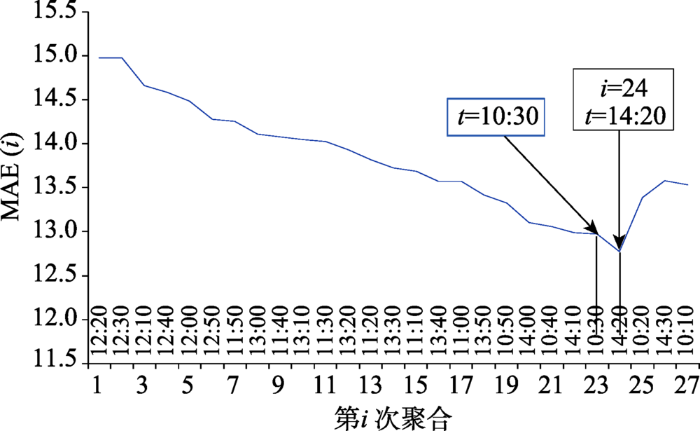
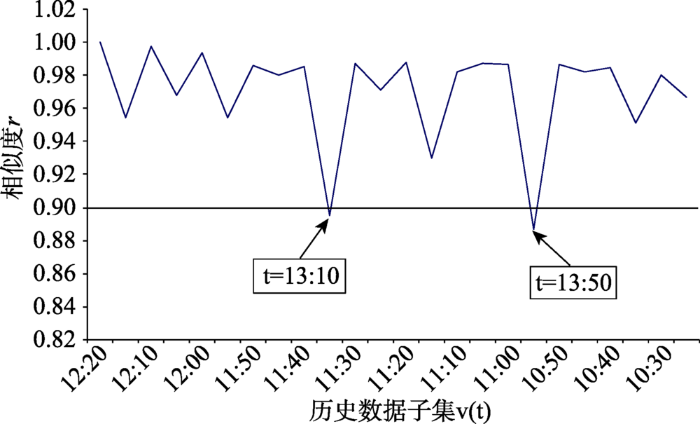
本节实验按照2.2节中所述方法确定样本数据集。首先将3.11节中确定的状态向量按照2.3节所述方法分割为144个历史数据子集;然后按照2.3.1节所述方法为每个子集确定相似数据集,即各对应时刻的训练数据集。
本节实验以12:20历史数据子集为例为其确定相似数据集,
确定好聚合边界后,再按照2.2.2节所述方法剔除上述实验得到的训练数据集
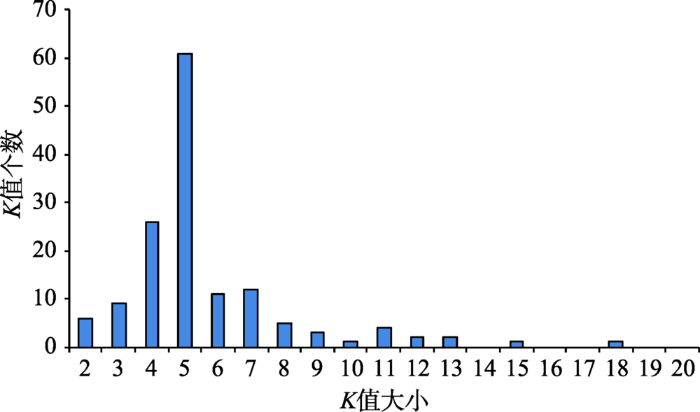
本节实验按照2.3节所述方法采用3.1节实验确定的训练数据集为每个时刻选取不同的K值,K值的分布如图5所示。观察该图可知,K值集中分布在3、4、5、6、7这5个值上,只有少数几个时刻对应的K值大于10,K值整体上偏小的主要原因是本实验对数据进行了精细的划分,使训练数据集中的数据相比历史数据库中的数据分布更集中。
为精确地评价本算法及比较算法的预测效果,本文引入4种精度评价指标[20],分别是:平均绝对误差(MAE)、平均绝对百分误差(MAPE)、均方根误差(RMSE)、均等系数(EC)。其中,MAE、MAPE、RMSE越小,说明预测误差越小,即预测效果越好;EC越接近1,说明预测值与真实值之间的拟合度越好,EC值大于0.9时说明模型性能较好[6]。4种评价指标公式如下:
式中:
本文共包含3组实验,分别是KNN算法参数分析及比较实验、KNN算法与其他算法比较实验以及分离工作日与非工作日数据的对比实验。
3.4.1 KNN算法参数分析及比较实验
如表1所示,本小节共包含5种算法,其中算法F1为原始KNN算法,F5为本文所提出的KNN算法,F2、F3、F4为3种采用不同参数的同类算法;F2算法所使用状态向量未包含
本节实验以表1所述5种算法为标准,数据通过预处理使其适用于F5算法,通过参数选取分别为F1-F5算法分配所需数据及参数。本节实验采用交叉验证(十折交叉验证)的思想,得到如表2所示的预测结果误差比较表。
表2 预测结果误差比较表
Tab. 2 Error comparison of prediction results
| 算法 | MAE | MAPE/% | RMSE | EC |
|---|---|---|---|---|
| F1 | 15.64 | 7.92 | 21.47 | 0.899 |
| F2 | 13.25 | 6.78 | 18.93 | 0.945 |
| F3 | 13.67 | 7.0 | 19.35 | 0.944 |
| F4 | 11.61 | 5.93 | 16.84 | 0.952 |
| F5 | 11.07 | 5.69 | 16.29 | 0.969 |
表2中EC列的值表明,除F1之外的其他4种算法均为可靠的预测算法;从F2、F3、F4算法与F5算法的预测误差比较来看,状态向量、数据聚合方式、K值的改变对预测结果均有影响。其中,K值的改变(F4)对算法预测精度的影响最小,这主要是因为F4中选取的K值为5,而F5算法中的K值主要集中在5附近(参见3.2.3节);状态向量的改进(F2),数据聚合的改进(F3)均对预测精度有显著影响,说明本文针对这3种参数所做的改进都有助于提高KNN模型的预测精度。
3.4.2 全部数据、工作日及非工作日数据分离比较实验
本节的3组实验均采用本文提出的算法完成,区别在于历史数据集不同。全部数据与3.3.1节F5算法相同;工作日数据与节假日数据分离表示从历史数据库分别提取工作日数据与非工作日数据,生成两个独立的子数据库,分别用于实验。实验采用交叉验证思想,预测结果误差如表3所示。
表3 预测结果误差表
Tab. 3 Error comparison of prediction results
| 数据类型 | MAE | MAPE/% | RMSE | EC |
|---|---|---|---|---|
| 全部数据 | 11.07 | 5.69 | 16.29 | 0.969 |
| 工作日数据 | 10.53 | 5.62 | 15.6 | 0.973 |
| 非工作日数据 | 11.81 | 5.91 | 17.38 | 0.952 |
由表3评价指标,3组实验误差相差很小,说明本文设计的实验可以同时适用于工作日和非工作日。其中,非工作日的预测结果最差,这主要是因为非工作日数据量少且非工作日的交通模式差别大;工作日取得了较好的结果,说明在数据充沛的情况下对数据集进行精细的分割有助于提高模型的预测精度。结合非参数模型的特性(对历史数据库质量要求较高),说明本文所设计的数据聚合方法能够选择到合适的训练数据集,据此下文实验所用数据不再区分工作日与非工作日。
3.4.3 与其他预测算法的比较实验
本节实验选择目前在短时交通流量预测领域被广泛应用的支持向量回归(SVR)、神经网络(BP)以及KNN(3.4.1节中F1算法)作为比较算法。
本节采用的SVR算法参数设置为:核函数rbf、惩罚系数le4gamma系数0.001。
本节采用的BP算法为三层BP神经网络,其中输入层单元个数为4,输出层单元个数为1,隐含层单元个数为5,相关参数设置为最大循环次数10000,目标误差0.001,动量常数0.001,学习速率0.001。
本节实验中将最后一周的数据作为测试数据,剩余数据作为训练数据,预测结果误差如表4所示。
表4 预测结果误差表
Tab. 4 Error comparison of prediction results
| 算法 | MAE | MAPE/% | RMSE | EC | 时间/s |
|---|---|---|---|---|---|
| KNN | 16.01 | 8.41 | 641.64 | 0.898 | 14.59 |
| SVR | 14.84 | 7.72 | 536.68 | 0.935 | 5.86 |
| BP | 13.08 | 6.70 | 378.79 | 0.943 | 6.31 |
| KNN-SDA | 11.75 | 6.22 | 332.55 | 0.949 | 6.17 |
由表4可知,KNN-SDA算法的4种评价指标均优于其他3种算法,说明KNN-SDA算法的预测结果更准确,且KNN-SDA算法的EC值比其他2种算法的EC值更接近1,说明该模型的预测值与实际值拟合更佳。同时与SVR、BP算法相比,本文算法用时适中,但明显小于KNN算法,说明本文对KNN算法的改进可更好地满足实时预测的需求。
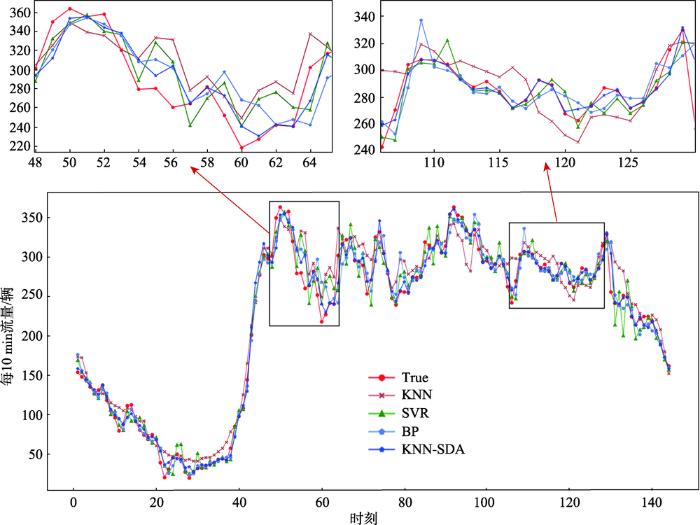
为了更直观地反映3种算法预测结果与真实交通流量之间的差异、对比三者的预测结果,本文以2016年6月24日全天的交通数据为例,在图6中分别展示真实交通流量及3种算法预测的交通流量。
从图5整体预测效果及左上、右上两幅子图的曲线拟合效果来看,KNN-SDA算法的预测结果与真实交通流量拟合度最好,在整个交通流量曲线上突刺(偏差较大处)偏少,而其他3种算法尤其是SVR算法在整个曲线上存在更多突刺,而KNN算法预测值则与真实交通流量值之间存在明显偏差。KNN-SDA算法优于其他3种算法的原因为:① KNN算法比较适用解决短时交通流量预测这类具有时变、不确定的非线性问题;② 本文为全天144个时刻分别分配合理的训练数据集与K值,参数设置的优化使KNN-SDA算法能够更加准确地搜索到所需历史数据。
非参数回归摒弃了传统求解数学模型的方法,仅在历史数据库的支持下,就可较好地适应短时交通流量预测问题的不确定性、时变性和非线性。只要有完备的历史数据,并制定适宜的交通流量模式匹配机制,即可取得满意的预测结果。本文中对KNN方法进行了若干改进,包括与预测密切相关的输入变量X、训练数据集与K值等,这些改进优化了KNN模式匹配精度。研究表明,与在短时交通流量预测研究领域常用的支持向量机(SVR)与BP神经网络等模型相比,本文提出的KNN-SDA算法具有训练参数少、预测精度高、时效性好等相对优势。但本文算法(仅)适用于单路口短时交通流量预测,对于不同的路口,仍需要构造对应的训练数据集与K值。如何改进该算法使其适用于大规模城市路网短时交通流量预测是后续研究努力的方向。
The authors have declared that no competing interests exist.
| [1] |
A bayesian network approach to traffic flow forecasting [J].https://doi.org/10.1109/TITS.2006.869623 URL [本文引用: 1] 摘要
A new approach based on Bayesian networks for traffic flow forecasting is proposed. In this paper, traffic flows among adjacent road links in a transportation network are modeled as a Bayesian network. The joint probability distribution between the cause nodes (data utilized for forecasting) and the effect node (data to be forecasted) in a constructed Bayesian network is described as a Gaussian mixture model (GMM) whose parameters are estimated via the competitive expectation maximization (CEM) algorithm. Finally, traffic flow forecasting is performed under the criterion of minimum mean square error (mmse). The approach departs from many existing traffic flow forecasting models in that it explicitly includes information from adjacent road links to analyze the trends of the current link statistically. Furthermore, it also encompasses the issue of traffic flow forecasting when incomplete data exist. Comprehensive experiments on urban vehicular traffic flow data of Beijing and comparisons with several other methods show that the Bayesian network is a very promising and effective approach for traffic flow modeling and forecasting, both for complete data and incomplete data
|
| [2] |
Adaptive Kalman filter approach for stochastic short-term traffic flow rate prediction and uncertainty quantification [J].https://doi.org/10.1016/j.trc.2014.02.006 URL [本文引用: 1] |
| [3] |
高速公路旅行时间的自适应插值卡尔曼滤波预测 [J].Prediction of expressway travel time based on adaptive interpolation Kalman filtering [J]. |
| [4] |
Urban traffic flow prediction system using a multifactor pattern recognition model [J].https://doi.org/10.1109/TITS.2015.2419614 URL [本文引用: 1] 摘要
Current urban traffic congestion costs are increasing on account of the population growth of cities and increasing numbers of vehicles. Many cities are adopting intelligent transportation systems (ITSs) to improve traffic efficiency. ITSs can be used for monitoring traffic congestion using detectors, such as calculating an estimated time of arrival or suggesting a detour route. In this paper, we propose an urban traffic flow prediction system using a multifactor pattern recognition model, which combines Gaussian mixture model clustering with an artificial neural network. This system forecasts traffic flow by combining road geographical factors and environmental factors with traffic flow properties from ITS detectors. Experimental results demonstrate that the proposed model produces more reliable predictions compared with existing methods.
|
| [5] |
Probabilistic forecasting of traffic flow using multikernel based extreme learning machine [J]. |
| [6] |
基于相空间重构和RELM的短时交通流量预测 [J].https://doi.org/10.3969/j.issn.1000-565X.2016.04.016 URL [本文引用: 2] 摘要
为了提高短时交通流量预测的精度,构建了基于相空间重构和正则化极端学习机的短时交通流量预测模型.首先采用C-C算法求解交通流量时间序列的最佳时间延迟和嵌入维数,进行相空间重构;然后选用G-P算法计算序列关联维数,判断出短时交通流量序列具有混沌特性.在此基础上,将重构数据作为正则化极端学习机的输入和输出来训练模型,并采用网格搜索法优化模型参数.最后以实测数据为基础,对模型的预测效果进行对比分析.结果表明,新构建模型的预测效果良好,能够有效提高短时交通流量预测精度.
Short-term traffic flow prediction based on phase space reconstruction and RELM [J].https://doi.org/10.3969/j.issn.1000-565X.2016.04.016 URL [本文引用: 2] 摘要
为了提高短时交通流量预测的精度,构建了基于相空间重构和正则化极端学习机的短时交通流量预测模型.首先采用C-C算法求解交通流量时间序列的最佳时间延迟和嵌入维数,进行相空间重构;然后选用G-P算法计算序列关联维数,判断出短时交通流量序列具有混沌特性.在此基础上,将重构数据作为正则化极端学习机的输入和输出来训练模型,并采用网格搜索法优化模型参数.最后以实测数据为基础,对模型的预测效果进行对比分析.结果表明,新构建模型的预测效果良好,能够有效提高短时交通流量预测精度.
|
| [7] |
基于支持向量机方法的短时交通流量预测方法 [J].https://doi.org/10.3969/j.issn.1671-5497.2006.06.010 URL Magsci [本文引用: 1] 摘要
<P><FONT face=Verdana>在总结已有多种预测模型的基础上,充分考虑了交通本身所存在的非线性、复杂性和不确定性,提出了一种基于支持向量机的短时交通流量预测模型。实例数据验证结果和基于BP神经网络的预测模型的对比结果表明,该模型在精度、收敛时间、泛化能力、最优性等方面均优于基于BP神经网络的预测模型。</FONT></P>
Short-term traffic flow prediction method based on SVM [J].https://doi.org/10.3969/j.issn.1671-5497.2006.06.010 URL Magsci [本文引用: 1] 摘要
<P><FONT face=Verdana>在总结已有多种预测模型的基础上,充分考虑了交通本身所存在的非线性、复杂性和不确定性,提出了一种基于支持向量机的短时交通流量预测模型。实例数据验证结果和基于BP神经网络的预测模型的对比结果表明,该模型在精度、收敛时间、泛化能力、最优性等方面均优于基于BP神经网络的预测模型。</FONT></P>
|
| [8] |
基于混合人工鱼群优化SVR的交通流预测模型 [J].Traffic flow forecasting based on optimized SVR with hybrid artificial fish swarm algorithm [J]. |
| [9] |
An improved K -nearest neighbor model for short-term traffic flow prediction [J].https://doi.org/10.1016/j.sbspro.2013.08.076 URL [本文引用: 1] 摘要
In order to accurately predict the short-term traffic flow, this paper presents a k-nearest neighbor (KNN) model. Short-term urban expressway flow prediction system based on k-NN is established in three aspects: the historical database, the search mechanism and algorithm parameters, and the predication plan. At first, preprocess the original data and then standardized the effective data in order to avoid the magnitude difference of the sample data and improve the prediction accuracy. At last, a short-term traffic prediction based on k-NN nonparametric regression model is developed in the Matlab platform. Utilizing the Shanghai urban expressway section measured traffic flow data, the comparison of average and weighted k-NN nonparametric regression model is discussed and the reliability of the predicting result is analyzed. Results show that the accuracy of the proposed method is over 90 percent and it also rereads that the feasibility of the methods is used in short-term traffic flow prediction. (C) 2013 The Authors. Published by Elsevier Ltd.
|
| [10] |
Segmentation of vehicle detector data for improved k-nearest neighbours-based traffic flow prediction [J]. |
| [11] |
Nonparametric regression and short-term freeway traffic forecasting [J].https://doi.org/10.1061/(ASCE)0733-947X(1991)117:2(178) URL [本文引用: 2] |
| [12] |
Comparison of parametric and nonparametric models for traffic flow forecasting [J].https://doi.org/10.1016/S0968-090X(02)00009-8 URL [本文引用: 4] 摘要
Single point short-term traffic flow forecasting will play a key role in supporting demand forecasts needed by operational network models. Seasonal autoregressive integrated moving average (ARIMA), a classic parametric modeling approach to time series, and nonparametric regression models have been proposed as well suited for application to single point short-term traffic flow forecasting. Past research has shown seasonal ARIMA models to deliver results that are statistically superior to basic implementations of nonparametric regression. However, the advantages associated with a data-driven nonparametric forecasting approach motivate further investigation of refined nonparametric forecasting methods. Following this motivation, this research effort seeks to examine the theoretical foundation of nonparametric regression and to answer the question of whether nonparametric regression based on heuristically improved forecast generation methods approach the single interval traffic flow prediction performance of seasonal ARIMA models.
|
| [13] |
基于聚类分析的非参数回归短时交通流预测方法 [J].https://doi.org/10.3963/j.issn.1674-4861.2013.02.007 URL [本文引用: 2] 摘要
大部分非参数回归预测算法并不对交通流历史数据进行区分,而是将全部历史流量数据建立模式库进行分析.基于交通流的现实特征,提出基于聚类分析的非参数回归短时交通流预测方法,首先根据流量分布特点运用聚类分析将其分类成不同的流量模式,然后选择匹配待预测时刻的流量模式作为样本数据库运用非参数回归进行预测.实例计算结果表明,其预测精度优于传统非参数回归方法.
Non-parametric regression for short-term traffic flow forecasting based on cluster analysis [J].https://doi.org/10.3963/j.issn.1674-4861.2013.02.007 URL [本文引用: 2] 摘要
大部分非参数回归预测算法并不对交通流历史数据进行区分,而是将全部历史流量数据建立模式库进行分析.基于交通流的现实特征,提出基于聚类分析的非参数回归短时交通流预测方法,首先根据流量分布特点运用聚类分析将其分类成不同的流量模式,然后选择匹配待预测时刻的流量模式作为样本数据库运用非参数回归进行预测.实例计算结果表明,其预测精度优于传统非参数回归方法.
|
| [14] |
非参数回归方法在短时交通流预测中的应用 [J].Non-parametric regression and application for short-term traffic flow forecasting [J]. |
| [15] |
基于K近邻非参数回归的短时交通流预测方法 [J].
<FONT face=Verdana>采用K近邻的非参数回归方法对短时交通流量进行了预测,考察了模型中关键因素对预测效果的影响.在4种不同状态向量和预测算法组合下的实验方法比较中,以相邻四个时间间隔的流量和占有率数据作为状态向量,并采用带权重的预测算法取得了良好的效果.将利用$K$值构造的预测区间用于特殊路况的预测中,得到了明显的改进效果.最后,对非参数回归和神经网络的方法进行了比较,结果表明了非参数回归预测方法的高精度和强移植性.<BR></FONT>
K-NN based nonparametric regression method for short-term traffic flow forecasting [J].
<FONT face=Verdana>采用K近邻的非参数回归方法对短时交通流量进行了预测,考察了模型中关键因素对预测效果的影响.在4种不同状态向量和预测算法组合下的实验方法比较中,以相邻四个时间间隔的流量和占有率数据作为状态向量,并采用带权重的预测算法取得了良好的效果.将利用$K$值构造的预测区间用于特殊路况的预测中,得到了明显的改进效果.最后,对非参数回归和神经网络的方法进行了比较,结果表明了非参数回归预测方法的高精度和强移植性.<BR></FONT>
|
| [16] |
基于K-邻域非参数回归短时交通流预测方法 [J].
实时、准确的短时交通流预测是交通控制与诱导中的一个关键问题和难点.非参数回归是解决短时交通流预测问题的较好方法,但是案例库生成难和搜索速度慢是其目前实际应用的两大障碍.为此,提出一种基于平衡二叉树的K-邻域非参数回归(KNN-NPR)的短时交通流预测方法,采用聚类方法和平衡二叉树结构建立案例数据库,以提高预测精度和满足实时性要求.给出了预测示例说明了方法的有效性.
Short-term traffic flow forecasting based on K-nearest neighbors non-parametric regression [J].
实时、准确的短时交通流预测是交通控制与诱导中的一个关键问题和难点.非参数回归是解决短时交通流预测问题的较好方法,但是案例库生成难和搜索速度慢是其目前实际应用的两大障碍.为此,提出一种基于平衡二叉树的K-邻域非参数回归(KNN-NPR)的短时交通流预测方法,采用聚类方法和平衡二叉树结构建立案例数据库,以提高预测精度和满足实时性要求.给出了预测示例说明了方法的有效性.
|
| [17] |
A two-stage short-term traffic flow prediction method based on AVL and AKNN techniques [J].https://doi.org/10.1007/s11771-015-2582-y URL [本文引用: 3] 摘要
Short-term traffic flow prediction is one of the essential issues in intelligent transportation systems (ITS). A new two-stage traffic flow prediction method named AKNN-AVL method is presented, which combines an advanced k -nearest neighbor (AKNN) method and balanced binary tree (AVL) data structure to improve the prediction accuracy. The AKNN method uses pattern recognition two times in the searching process, which considers the previous sequences of traffic flow to forecast the future traffic state. Clustering method and balanced binary tree technique are introduced to build case database to reduce the searching time. To illustrate the effects of these developments, the accuracies performance of AKNN-AVL method, k -nearest neighbor (KNN) method and the auto-regressive and moving average (ARMA) method are compared. These methods are calibrated and evaluated by the real-time data from a freeway traffic detector near North 3rd Ring Road in Beijing under both normal and incident traffic conditions. The comparisons show that the AKNN-AVL method with the optimal neighbor and pattern size outperforms both KNN method and ARMA method under both normal and incident traffic conditions. In addition, the combinations of clustering method and balanced binary tree technique to the prediction method can increase the searching speed and respond rapidly to case database fluctuations.
|
| [18] |
Time-Aware Multivariate Nearest Neighbor Regression Methods for Traffic Flow Prediction [J].https://doi.org/10.1109/TITS.2015.2453116 URL [本文引用: 2] 摘要
Traffic flow prediction is a fundamental functionality of intelligent transportation systems. After presenting the state of the art, we focus on nearest neighbor regression methods, which are data-driven algorithms that are effective yet simple to implement. We try to strengthen their efficacy in two ways that are little explored in literature, i.e., by adopting a multivariate approach and by adding awareness of the time of the day. The combination of these two refinements, which represents a novelty, leads to the definition of a new class of methods that we call time-aware multivariate nearest neighbor regression (TaM-NNR) algorithms. To assess this class, we have used publicly available traffic data from a California highway. Computational results show the effectiveness of such algorithms in comparison with state-of-the-art parametric and non-parametric methods. In particular, they consistently perform better than their corresponding standard univariate versions. These facts highlight the importance of context elements in traffic prediction. The ideas presented here may be further investigated considering more context elements (e.g., weather conditions), more complex road topologies (e.g., urban networks), and different types of prediction methods.
|
| [19] |
A map reduce-based nearest neighbor approach for big-data-driven traffic flow prediction [J].https://doi.org/10.1109/ACCESS.2016.2570021 URL [本文引用: 1] 摘要
In big-data-driven traffic flow prediction systems, the robustness of prediction performance depends on accuracy and timeliness. This paper presents a new MapReduce-based nearest neighbor (NN) approach fortraffic flow predictionusingcorrelationanalysis (TFPC) on a Hadoop platform. In particular, we develop a real-time prediction system including two key modules, i.e., offline distributed training (ODT) and online parallel prediction (OPP). Moreover, we build a parallel$k$-nearest neighbor optimization classifier, which incorporates correlation information among traffic flows into the classification process. Finally, we propose a novel prediction calculation method, combining the current data observed in OPP and the classification results obtained from large-scale historical data in ODT, to generate traffic flow prediction in real time. The empirical study on real-world traffic flow big data using the leave-one-out cross validation method shows that TFPC significantly outperforms four state-of-the-art prediction approaches, i.e., autoregressive integrated moving average, Na茂ve Bayes, multilayer perceptron neural networks, and NN regression, in terms of accuracy, which can be improved 90.07% in the best case, with an average mean absolute percent error of 5.53%. In addition, it displays excellent speedup, scaleup, and sizeup.
|
| [20] |
基于非参数回归的短时交通流量预测方法研究 [D].A study on short-term traffic volume forecasting based on non-parametric regression [D]. |
| [21] |
确定延迟时间互信息法的一种算法 [J].https://doi.org/10.3969/j.issn.1001-246X.2006.02.010 URL [本文引用: 1] 摘要
介绍了相空间重构中确定重构延迟时间的互信息法理论及其具体的计算方法.针对互信息法应用中计算复杂、程序难以编写问题,提出了一种基于网格层数的简便实用程序算法.对网格层数参数进行了结果分析,表明在利用互信息法确定重构延迟时间时,只需要计算到某一个网格层数即可,不需要计算出精确的互信息值,简化了计算的复杂程度.最后通过对Lorenz和Rossler两个吸引于的Lyapunov指数计算,证实了该算法的合理性.
An algorithm of selecting delay time in the mutual information method [J].https://doi.org/10.3969/j.issn.1001-246X.2006.02.010 URL [本文引用: 1] 摘要
介绍了相空间重构中确定重构延迟时间的互信息法理论及其具体的计算方法.针对互信息法应用中计算复杂、程序难以编写问题,提出了一种基于网格层数的简便实用程序算法.对网格层数参数进行了结果分析,表明在利用互信息法确定重构延迟时间时,只需要计算到某一个网格层数即可,不需要计算出精确的互信息值,简化了计算的复杂程度.最后通过对Lorenz和Rossler两个吸引于的Lyapunov指数计算,证实了该算法的合理性.
|
| [22] |
基于矩阵相似度的最佳样本块匹配算法及其在图像修复中的应用 [J].https://doi.org/10.3969/j.issn.1002-137X.2014.01.062 URL [本文引用: 1] 摘要
在基于纹理合成的图像修复算法中,最佳样本块匹配算法存在匹配精度不高和时间复杂度高等问题。针对上述问题,首先构造了块匹配算法,采用矩阵相似度来计算模板块与样本块之间的匹配度,以相对较粗的粒度初步选出最佳样本块的候选集。然后,又构造了像素点匹配算法,采用模板块与候选最佳样本块之间的误差矩阵的内积来计算对应像素点之间的匹配度,以更细的粒度来确定最终的最佳样本块。块匹配算法降低了时间复杂度,像素点匹配算法提高了匹配精度,因此,在此基础上构造的基于相似矩阵的最佳样本块匹配算法能够在不增加时间复杂度的情况下提高算法的匹配精度。实例验证结果表明,与当前基于纹理的图像修复算法相比,该算法的匹配精度提高,时间复杂度降低。
Optimal exemplar metching algorithm based on matrix similarity and its application in image inpainting [J].https://doi.org/10.3969/j.issn.1002-137X.2014.01.062 URL [本文引用: 1] 摘要
在基于纹理合成的图像修复算法中,最佳样本块匹配算法存在匹配精度不高和时间复杂度高等问题。针对上述问题,首先构造了块匹配算法,采用矩阵相似度来计算模板块与样本块之间的匹配度,以相对较粗的粒度初步选出最佳样本块的候选集。然后,又构造了像素点匹配算法,采用模板块与候选最佳样本块之间的误差矩阵的内积来计算对应像素点之间的匹配度,以更细的粒度来确定最终的最佳样本块。块匹配算法降低了时间复杂度,像素点匹配算法提高了匹配精度,因此,在此基础上构造的基于相似矩阵的最佳样本块匹配算法能够在不增加时间复杂度的情况下提高算法的匹配精度。实例验证结果表明,与当前基于纹理的图像修复算法相比,该算法的匹配精度提高,时间复杂度降低。
|

/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}