王金传 , 谭喜成, 王召海
, 谭喜成, 王召海
WANG Jinchuan, TAN Xicheng, WANG Zhaohai
通讯作者:
收稿日期: 2018-05-12
修回日期: 2018-07-25
网络出版日期: 2018-10-25
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:王金传(1993-),男,硕士,主要从事遥感技术应用、深度学习和WebGIS应用研究。E-mail: wangjnchuan@163.com
展开
摘要
遥感影像目标识别在众多领域中具有极高的理论意义与应用价值,更快速、更精确的目标识别方法研究是目前遥感及图像研究领域的热点与难点。本文将深度学习的方法应用于遥感影像目标识别中,提出基于Faster R-CNN深度学习网络的目标快速精确识别方法。该方法采用了包括基于RPN的建议区域提取方法和VGG16训练卷积网络模型,构建了面向遥感影像目标识别的深度卷积神经网络。为验证该方法的精度及性能,在Caffe深度学习框架上,选取高分辨率遥感影像中飞机、油罐、操场及立交桥目标进行验证实验。结果表明,基于Faster R-CNN的深度学习方法能够实现对遥感影像目标的快速、准确识别,同时具有较好的推广性。通过本文的研究,证明基于Faster R-CNN深度学习的高分遥感影像目标识别方法具有显著优势和潜力,对基于其他深度学习方法的目标识别研究也有一定的参考意义。
关键词:
Abstract
Object recognition of remote sensing image is of great theoretical significance and application value in many fields. Faster and more accurate object identification methods are hot and difficult points in the field of remote sensing and image. In this paper, the method of deep learning is applied to remote sensing image object recognition, and a fast and accurate method of object recognition based on Faster R-CNN deep learning network is proposed. This method uses the proposal region extraction method based on RPN and the VGG16 training convolution network model, and constructs a deep convolutional neural network for the object recognition of remote sensing image. In order to verify the accuracy and performance of the method, the GPU accelerated computing model was used in the Caffe deep learning framework. Firstly, the aircraft target recognition experiment in remote sensing image was designed. The aircraft target recognition accuracy reached 96.67%. Then, after the experiment was successful, we continued to identify other target features, and selected the high-resolution remote sensing image of the oil tank, playground and overpass object for verification experiments. In the same experiment environment, the same good experimental verification results were obtained, the target recognition rate was at a high level, and the cost time of recognition in each picture was less than 0.2 seconds, which fully verified the validity and reliability of the model studied in this paper. After analysis and comparison, the conclusion is that the deep learning method based on Faster R-CNN can realize the fast and accurate recognition of the selected targets, which proves that the method has a good promotion significance in high-resolution remote sensing image target recognition applications. Therefore, the model has great application value, and it also has certain reference significance for target recognition research based on other deep learning methods.
Keywords:
近年来,图像目标识别已成为遥感影像地物目标识别、计算机视觉等领域非常重要的研究热点,通过目标识别可以获取影像中的特定目标以及目标的类型和目标的具体位置,在智能交通、智慧城市、公共安全、军事战争等应用中起到十分重要的作用,因此针对遥感影像数据的目标识别研究具有重大意义[1,2]。随着对地观测技术的发展,遥感影像时空分辨率不断提高,遥感数据呈现越来越明显的大数据特征[3,4,5,6],为地面目标识别提供了更好的数据基础,遥感影像目标识别将应用在更为广泛的领域,因此进行遥感影像目标识别研究具有重要的理论与实际应用价值。
借助于图像检测算法,遥感影像目标识别研究工作不断展开,图像检测算法大致可以分为3种:滑动窗口搜索方法[7]、感兴趣区域(ROI)提取方法[8]和样本目标学习方法。滑动窗口搜索方法通过使用人工标记的目标样本模板与落入滑动窗口内的图像块进行匹配度计算,根据阈值进行判定。该方法具有较大的局限性,当样本模板被标记后,该特定模板只能用来识别形状、大小、方向一致的目标;并且对于地球空间大场景下的遥感图片,滑动窗口特征匹配需要耗费大量的时间,导致算法的执行效率低下。面对这个问题,出现了基于感兴趣区(ROI)提取的方法,根据图像的颜色和纹理属性来提取感兴趣区,排除掉无关的背景区域,缩小目标搜索空间,提高检测效率。在机器学习理论的支持下,样本目标学习方法更具优势,大量的目标检测算法被应用,如神经网络(NN)[9,10]、支持向量机(SVM)[11,12]、随机森林(RF)[13]等算法。该方法通过样本训练建立机器学习模型,具有很强的针对性和较高的识别精度,是目前遥感影像目标识别研究的重点与难点。
深度学习理论在推动遥感影像目标识别技术的发展中起到十分重要的作用。深度学习是机器学习中的一个新领域,目的是建立模拟人脑进行分析学习的神经网络[14],然后通过组合低层特征形成更加抽象的高层特征。在深度学习中,不需要告诉计算机如何解决问题,计算机能从数据中学习,通过学习结果,自行解决问题。深度学习的优势有:① 高效性,相比于传统方法,计算量减少;② 可塑性,使用模型解决不同的问题,深度学习只需要调整参数就可以改变模型;③ 普适性,使用神经网络来解决问题,可以适用于各种问题,而不是局限于固定的某个问题。深度学习方法因其很强的通用性,目前已经拓展到其他更多的领域,在图像分类、目标检测[15]、姿态估计、图像分割和语音识别[16]等方面取得了大量成果。
基于区域的卷积神经网络(Region-based Convolutional Neutral Network,R-CNN)深度学习模型在图像目标检测领域中发展非常迅速[17],为了提高识别精度和速度,模型不断优化,产生了Fast R-CNN和Faster R-CNN模型[18]。目前,Faster R-CNN模型在目标检测精度和检测速度上具有明显的优势。2015年Faster R-CNN模型在COCO检测大赛中夺得第一名的好成绩,并在PACAL VOC 2007和PACAL VOC 2012上的表现也十分突出,达到了当时最高的目标检测准确率。此外,Faster R-CNN模型已经在车辆检测[19]、车型识别和车辆方向识别等研究中被广泛应用。Tang等[20]基于Faster R-CNN模型对航拍图片中的车辆数据进行检测研究。桑军等[21]针对BIT-Vehicle数据集,设计了Faster R-CNN与ResNet-101模型相结合的车型识别方案,其车型识别率高达91.3%。Azam等[22]研究了车辆4个不同方位(前、后、左和右)的方向识别的Faster R-CNN模型。针对机场场面飞机检测,戴陈卡等[23]分析机场场面中飞机目标轮廓不完整、姿态不一的特点,提出基于Faster R-CNN以及飞机部件结合的检测方法,对于白天日光和夜晚灯光场景下的飞机目标检测皆取得不错的效果。
本文基于深度学习的方法,采用Faster R-CNN模型对遥感影像飞机目标识别进行研究,在Caffe GPU深度学习框架上进行实验,并与R-CNN、Fast R-CNN深度学习网络进行了对比分析。实验结果表明,采用Faster R-CNN深度学习网络能够实现遥感影像中目标更快速、更精准的识别。在对其他目标识别的扩展实验中,进行遥感影像中油罐、操场和立交桥其他目标的识别测试。测试结果表明,本文模型可以实现多场景下的多种遥感影像目标识别任务,在保证较高的识别精度的情况下,识别效率也具有明显优势,达到了快速、准确的识别效果。
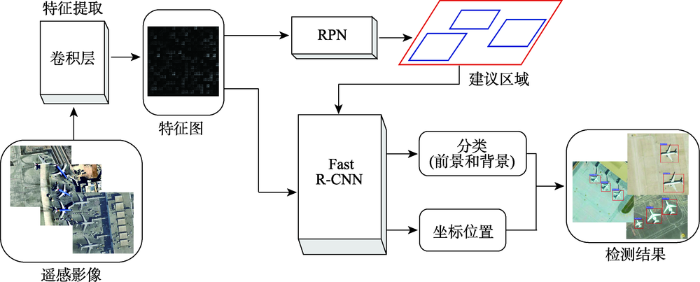
通过对R-CNN和Fast R-CNN模型的优化,Ren等[18]提出了新一代的目标检测网络模型——Faster R-CNN。Faster R-CNN网络模型优势在于包括了一个用来生成高质量建议区域框的区域建议网络(Region Proposal Network,RPN),它的出现取代了原来的选择性搜索(Selective Search,SS)[24]等方法,实现了与检测网络卷积层的共享,大大缩短了区域建议检测所要耗费的时间。Faster R-CNN的整体结构可以看作是“RPN”与“Fast R-CNN”二者的结合,这种集成具有明确的分工,建议区域的确定可以由RPN来完成,学习建议区域特征和负责分类的工作交给了Fast R-CNN。在Fast R-CNN中,有2个输出层:① 用于对每个建议区域的分类概率进行预测,判别出目标与非目标;② 优化每个建议区域坐标的偏移,获得更加精准的目标位置。本文所采用的遥感影像目标识别Faster R-CNN网络模型结构如图1所示。
目标检测网络设计中都需要用到区域寻找算法来提前预测目标所在图像中的位置,对比选择性搜索SS方法,区域建议网络(RPN)是目前最先进的建议框提取算法。该算法提出将提取建议区域的工作交给卷积神经网络CNN来实现,它能和整个检测网络共享全图的卷积特征,使得提取过程花费很少的时间。RPN网络是一个全卷积网络(Fully Convolutional Network,FCN),是在特征提取网络CNN上增加了2个卷积层,因此可以完成端对端地建议区域生成任务,同时能够预测出目标的建议框位置和得分。以VGG16网络模型为例,初始图像经过第5个卷积模块(卷积层+激活层+池化层)后得到512个特征图,然后区域建议网络(RPN)根据共享的特征图,生成候选区域并进行分类(前景或背景),流程结构如图2所示。
从图2可看出,RPN具有2个分支,2个平行的全连接层:① 窗口回归层,这个分支是根据特征图的每一位置来预测对应原始图片上的建议区域;② 分类层,用来预测该建议区域属于前景和背景(正负样本)的概率,实现对每个建议区域的分类。
RPN的核心思想是使用CNN卷积神经网络直接产生建议区域,使用的方法本质上就是滑动窗口,只需要在卷积层的最后一层上进行一次滑动,接下来的anchor机制和边框回归可以得到多尺度的建议区域。anchor机制的过程为:首先把每个特征点映射回原图的感受野中心当成一个基准点,然后围绕这个基准点选取k个不同面积、不同长宽比的anchor,anchor的面积大小为1282,2562,5122,长宽比分别取值为1,0.5,2。关于正负样本的划分,需要考察训练集中的每张图片的所有anchor。划分流程为:① 对每个标定的真实区域,与其重叠比例最大的anchor记为正样本,保证每个区域至少对应一个正样本anchor;② 对剩余的anchor,如果其与每个标定区域重叠比例大于0.7,记为正样本,每个真实区域可能会对应多个正样本anchor,但每个正样本anchor只可能对应一个所标定的真实区域;如果其与任意一个标定区域的重叠比例都小于0.3,记为负样本;③ 丢弃未被标记的anchor,并且跨越图像边界的anchor也弃去不用。不是所有的anchor都用来训练,每张图像中随机抽取256个anchor,前景样本和背景样本均取128个,达到正负比例为1:1。如果一个图像中的正样本数小于128,则多用一些负样本以满足有256个建议区用于训练。
训练方式分为2种:分阶段训练(alt-opt)和端到端训练(end-to-end)。端到端使用的显存更小并且训练更快,同时保证较高识别准确率,实验中采用端到端的训练方式。Faster R-CNN目前提供了3种训练网络模型,分别是ZF模型(小型)、VGG_CNN_M_1024模型(中型)、VGG16模型(大型)。尽管VGG16模型会占用很大的GPU显存,但是其深度更深,能更好地提取特征,检测效果比较好,本文选择VGG16模型作为训练网络模型。
本文采用的训练卷积网络结构如图3所示,该网络使用了13个卷积层和4个池化层。根据VGG16模型结构,13个卷积层被分成5个组(Group),每组之间通过Max pool层来连接。为了适应本研究对遥感影像的目标识别,对VGG16网络进行了部分调整。卷积层采用非线性ReLU激活函数,输入图像尺寸为256×256。因每个卷积层包含的卷积核大小均为3×3,步长为1,卷积层并不会改变特征图的大小。每个池化层均采用2×2窗口尺度的Max pool形式,步长设定为2,所以长宽变为原来的1/2,经过4个池化层后特征图的大小为16×16,最后一个卷积层输出为512个16×16的特征图,RPN和Fast R-CNN共享这个特征图。该模型网络更深,通道数量更多,经过该网络13个卷积层的特征提取,目标特征更加明显,有利于提高检测效果。
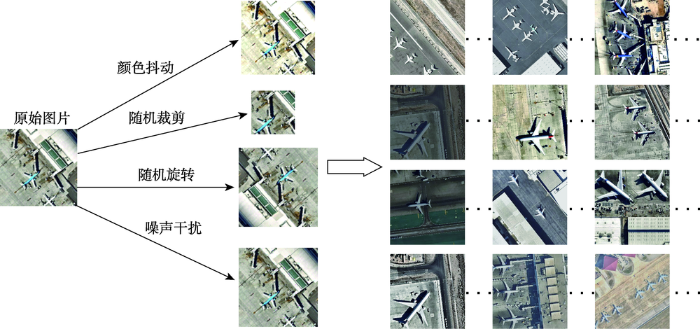
在飞机识别的实验中,本文实验中所用到的高分辨率遥感影像均来自MapQuest网站的网络地图卫星图片,该网站对不同类型的地点进行标识,根据机场地点爬取带有飞机目标的遥感影像瓦片图,图片尺寸为256×256。在深度学习训练过程中,当训练集中样本数量不够多,或者某一类的数据比较少,特征不够明显,或者是为了防止过拟合现象等情况,需要进行数据扩充[25]操作。常见的几种数据扩充方式:色彩抖动、随机修剪、旋转变换、噪声扰动等,过程如图4所示。经过数据扩充,获得数据集共计1538张图片,按照 train:val=1:1的比例进行训练。
参考VOC2007的数据集格式,主要包括3部分:① 训练图片集(JPEGImages),JPEGImages中的图片编号以6位数字命名,图片格式为JPEG或JPG,如000001.jpg;图片的长宽比要在0.462-0.682之间。② 原始图像目标坐标信息(Annotations),该文件为xml格式,Faster R-CNN训练需要图片的bounding box信息作为监督(目标所在区域),图像上所有可能的目标使用框标注,一个训练图片对应Annotations下的一个同名的xml文件。本文使用VOC框图工具labelimg来标记目标对象区域,然后生成xml格式的位置文件。③ 编号文件,test.txt用来存放测试数据的编号,train.txt中存放训练数据的编号,val.txt中存放验证数据的编号,trainval.txt则是训练和验证的集合,训练和验证数据数量比为1:1。
实验在Ubuntu16.04操作系统下,以配置了型号为NVIDIA GeForce GTX 970的GPU显卡的机器,选择Caffe深度学习框架,对1538张MapQuest的网络卫星图片(尺寸为256×256)进行训练,训练与验证的图片数量比为1:1。图片飞机目标经过VOC框图工具人工标定,标定后的图片和位置信息输入到Faster R-CNN开始训练。选择VGG16网络模型作为训练网络,迭代次数设置为15 000,学习率为0.001,得到飞机识别深度学习模型。使用该模型对200张来自百度地图的网络卫星图片进行测试,测试结果如图5所示。测试图片包括了中国北京、上海、广州、深圳、香港等城市的机场卫星影像,飞机类型主要为大中小型客机。从图5可看出,机场背景与飞机颜色、大小和形状相对于训练数据集都有变化,但是该模型仍然具有非常好识别效果。
本文增加了R-CNN和Fast R-CNN对比实验,对比分析得到,Faster R-CNN首先在识别速度上具有非常大的提升,平均每张图片的检测时间消耗为0.14 s,达到了更快速的检测效果;并且CNN训练网络选择深度较深的VGG16网络模型,识别精度达到96.67%。R-CNN、Fast R-CNN和Faster R-CNN 3种方法的测试性能对比如表1所示。R-CNN方法使用Selective Search搜索方法生成1000~2000个建议区,每一个建议区都需要进入CNN网络计算,建议区存在大量的范围重叠,重复的特征提取带来巨大的计算浪费,使得该方法的识别效率十分低,根据实验测试,该方法对每张图片的平均检测耗时为13.4 s。Fast R-CNN方法仍然使用Selective Search搜索方法生成建议区,将整张图像归一化后直接送入深度网络,特征提取完成后,加入候选框信息,不需对所有的建议区进行单独的CNN计算,在一定程度上提高检测速度,测试中每张图片检测耗时为4.6 s。Faster R-CNN方法使用区域生成网络(RPN)代替Selective Search搜索方法,将生成建议区的任务交给共享特征提取网络CNN,大大提高了识别效率,测试中每张图片检测耗时为0.14 s。并且,相对于R-CNN和Fast R-CNN方法使用的Caffenet网络,Faster R-CNN方法能够使用深度更深的VGG16网络,飞机目标识别精度达到96.67%,整体测试效果非常好。
表1 R-CNN、Fast R-CNN和Faster R-CNN测试性能对比
Tab. 1 The test performance comparison in R-CNN, Fast R-CNN and Faster R-CNN
| 深度学习方法 | 识别精度/% | 每张图片识别耗时/s |
|---|---|---|
| R-CNN | 77.10 | 13.40 |
| Fast R-CNN | 77.50 | 4.60 |
| Faster R-CNN | 96.67 | 0.14 |
进一步验证Faster R-CNN深度学习网络模型在其他遥感影像目标识别中的推广性,对武汉大学收集制作的航空遥感图像目标检测数据集进行推广实验,该数据集作为文献[26,27]的实验数据,取得了很好的研究成果。文献[26]对比分析了卷积神经网络与传统的目标识别方法在图像目标识别上的差异性,采用了降维的AlexNet-DR & GoogleNet-DR的CNN网络,并与LBP-HF 和EFT-HOG传统算法进行对比,取得了较好的遥感目标识别效果。本文使用该数据集中的油罐、学校操场和立交桥影像数据来完成Faster R-CNN深度学习网络模型的推广实验。实验中获取到该训练集的165幅油罐影像共1586个油罐目标、189幅学校操场影像共191个操场目标和176幅城市立交桥影像共180个立交桥目标。根据实验需求将其调整为VOC2007数据集格式进行训练,经过15 000次迭代训练,最终油罐、学校操场和立交桥目标的识别测试结果如图6所示。
图6 油罐、学校操场和立交桥目标识别结果
Fig. 6 The oil tank, playground and overpass target recognition results
基于Faster R-CNN+VGG16的深度学习网络模型在对该数据集目标识别的性能表现为:油罐目标的识别精度达到97.46%,学校操场目标的识别精度达到97.41%,立交桥目标的识别精度达到81.08%。由此可见,基于Faster R-CNN深度学习网络模型可以适应于多种复杂场景下的其他遥感影像目标识别。通过进一步分析对比,本文模型的识别精度与文献测试结果相近,由于所获取到的数据集只是文献[26]数据集的一部分,尤其立交桥目标的样本数量较少,导致立交桥目标的识别精度略逊于AlexNet-DR & GoogleNet-DR方法;但是对比识别效率,本文的模型具有更好的识别速度表现,4种目标识别效率均优于AlexNet-DR & GoogleNet-DR方法,每张遥感影像目标识别耗时在0.2 s以内,Faster R-CNN模型和文献中AlexNet-DR & GoogleNet-DR方法的识别精度和识别效率对比如表2所示。
表2 本文模型与文献模型识别精度与识别效率对比
Tab.2 Comparison of recognition accuracy and recognition efficiency between our model and reference
| 目标类别 | Faster R-CNN + VGG16 | AlexNet-DR & GoogleNet-DR | |||
|---|---|---|---|---|---|
| 识别精度/% | 识别效率/s | 识别精度/% | 识别效率/s | ||
| 飞机 | 96.67 | 0.144 | 94.99 | 37.292 | |
| 油罐 | 97.46 | 0.184 | 94.47 | 38.283 | |
| 操场 | 97.41 | 0.143 | 97.18 | 11.928 | |
| 立交桥 | 81.08 | 0.186 | 88.30 | 5.360 | |
本文在Caffe深度学习框架之上构建了基于VGG16卷积方法的Faster R-CNN的深度学习网络模型,通过高分辨率遥感影像数据中的飞机目标识别的实验,对深度学习方法Faster R-CNN网络模型在遥感影像目标快速、准确识别进行研究分析,同时和R-CNN、Fast R-CNN模型进行了比较。实验结果表明,相比于R-CNN和Fast R-CNN,Faster R-CNN在遥感影像目标识别精度和速度上具有明显的提升,达到了快速精准的检测效果。根据遥感影像中油罐、学校操场和立交桥的目标识别结果,证明了Faster R-CNN网络模型具有良好的可靠性和可推广性。随着高分辨率卫星的发展,遥感影像数据具有明显的海量、多源特征,对深度学习网络的复杂度和计算机大数据运算能力提出了更高的要求,而Faster R-CNN深度网络模型的高效特征,将在应对遥感大数据目标识别中发挥作用。今后将继续深入开展相关研究,进一步提升目标识别的精度,开展目标细分算法研究,如飞机目标型号识别,将该研究拓展到汽车、舰船等精细目标识别中,提高高分辨率遥感影像在军事、民用等领域的应用价值。
The authors have declared that no competing interests exist.
| [1] |
光学遥感图像舰船目标检测与识别综述 [J].https://doi.org/10.3724/SP.J.1004.2011.01029 Magsci [本文引用: 1] 摘要
遥感图像舰船目标自动检测与识别是遥感图像处理与分析领域备受关注的课题, 其核心任务是判断遥感图像中是否存在舰船目标,并对其进行检测、分类与精确定位, 它在海面交通监控、船只搜救、渔业管理和海域态势感知等领域具有广阔的应用前景. 本文主要围绕光学卫星遥感图像中的舰船目标自动检测与识别, 分析舰船目标检测与识别面临的难点问题, 综述当前光学遥感图像舰船检测与识别的主要处理方法, 在此基础上指出研究中尚存在的问题并展望未来的发展趋势.
State-of-the-art of ship detection and recognition in optical remotely sensed imagery [J].https://doi.org/10.3724/SP.J.1004.2011.01029 Magsci [本文引用: 1] 摘要
遥感图像舰船目标自动检测与识别是遥感图像处理与分析领域备受关注的课题, 其核心任务是判断遥感图像中是否存在舰船目标,并对其进行检测、分类与精确定位, 它在海面交通监控、船只搜救、渔业管理和海域态势感知等领域具有广阔的应用前景. 本文主要围绕光学卫星遥感图像中的舰船目标自动检测与识别, 分析舰船目标检测与识别面临的难点问题, 综述当前光学遥感图像舰船检测与识别的主要处理方法, 在此基础上指出研究中尚存在的问题并展望未来的发展趋势.
|
| [2] |
高分辨率遥感影像目标分类与识别研究进展 [J].https://doi.org/10.3724/SP.J.1047.2015.01080 URL Magsci [本文引用: 1] 摘要
高分辨率遥感影像的目标分类与识别,是对地观测系统进行图像分析理解,以及自动目标识别系统提取目标信息的重要手段。本文综述了当前国内外在可见光、红外、合成孔径雷达和合成孔径声纳等遥感影像的目标分类与识别的关键技术和最新研究进展。首先,讨论了高分辨率遥感影像的目标分类与识别问题的主要研究层次和内容;其次,深入分析了高分辨率遥感影像目标分类与识别,在滤波降噪、特征提取、目标检测、场景分类、目标分类和目标识别的关键技术及其所存在的问题;最后,结合并行计算、神经计算和认知计算等技术,讨论了目标分类与识别的可行性方案。具体包括:(1)高性能并行计算在高分辨率遥感图像处理的主流技术,并给出了基于Hadoop+OpenMP+CUDA的高分辨率遥感影像混合并行处理架构;(2)深度学习对于提升目标分类和识别精度的应用前景,以及基于深度神经网络的多层次遥感影像目标识别方法;(3)认知计算在解决遥感影像大数据不确定性分析的模型与算法,并讨论了层次主题模型的多尺度遥感影像场景描述方案。此外,根据媒体神经认知计算的相关研究,探讨了遥感影像大数据的目标分类和识别的发展趋势和研究方向。
Review on high resolution remote sensing image classification and recognition [J].https://doi.org/10.3724/SP.J.1047.2015.01080 URL Magsci [本文引用: 1] 摘要
高分辨率遥感影像的目标分类与识别,是对地观测系统进行图像分析理解,以及自动目标识别系统提取目标信息的重要手段。本文综述了当前国内外在可见光、红外、合成孔径雷达和合成孔径声纳等遥感影像的目标分类与识别的关键技术和最新研究进展。首先,讨论了高分辨率遥感影像的目标分类与识别问题的主要研究层次和内容;其次,深入分析了高分辨率遥感影像目标分类与识别,在滤波降噪、特征提取、目标检测、场景分类、目标分类和目标识别的关键技术及其所存在的问题;最后,结合并行计算、神经计算和认知计算等技术,讨论了目标分类与识别的可行性方案。具体包括:(1)高性能并行计算在高分辨率遥感图像处理的主流技术,并给出了基于Hadoop+OpenMP+CUDA的高分辨率遥感影像混合并行处理架构;(2)深度学习对于提升目标分类和识别精度的应用前景,以及基于深度神经网络的多层次遥感影像目标识别方法;(3)认知计算在解决遥感影像大数据不确定性分析的模型与算法,并讨论了层次主题模型的多尺度遥感影像场景描述方案。此外,根据媒体神经认知计算的相关研究,探讨了遥感影像大数据的目标分类和识别的发展趋势和研究方向。
|
| [3] |
Towards building a multi-datacenter infrastructure for massive remote sensing image processing [J].https://doi.org/10.1002/cpe.2966 URL [本文引用: 1] |
| [4] |
A Web 2.0-based science gateway for massive remote sensing image processing [J].https://doi.org/10.1002/cpe.3049 URL [本文引用: 1] 摘要
Summary With the incessant expansion of applications and the frequent update of the software, Science Gateway for Massive Remote Sensing Image Processing (SGMRSIP), developed by client/server model or traditional browser/server model, has received more and more challenges. Fortunately, the Web 2.0 technologies, proposed in recent years, bring us a new user experience (UE) that has a fast response speed and a good interface. In particular, the remote sensing image can be processed smoothly in the absence of client software by Web 2.0 technologies. Hence, a Web 2.0-based browser/server model is designed for SGMRSIP to enhance the UE in this paper. Firstly, functions of a parallel remote sensing image processing portal, based on high performance cluster and client/server model, are summarized. And then, a Web 2.0-based interaction model is built, and all these functions are accomplished again on the basis of this model. Finally, the Web 2.0-based Science Gateway is achieved. In addition, we design different workflows for different satellite data, and all the processing tasks are finished successfully to verify the feasibility of this Science Gateway. The experimental results showed that the software scalability and interaction were improved and a better UE was achieved, compared with the existing SGMRSIP. Copyright 2013 John Wiley & Sons, Ltd.
|
| [5] |
G-IK-SVD: Parallel IK-SVD on GPUs for sparse representation of spatial big data [J].https://doi.org/10.1007/s11227-016-1652-8 URL [本文引用: 1] 摘要
Sparse representation is a building block for many image processing applications such as compression, denoising, fusion and so on. In the era of “Big data”, the current spare representation methods generally do not meet the demand of time-efficiently processing the large image dataset. Aiming at this problem, this paper employed the contemporary general-purpose computing on the graphics processing unit (GPGPU) to extend a sparse representation method for big image datasets, IK-SVD, namely G-IK-SVD. The GPU-aided IK-SVD parallelized IK-SVD with three GPU optimization methods: (1) a batch-OMP algorithm based on GPU-aided Cholesky decomposition algorithm, (2) a GPU sparse matrix operation optimization method and (3) a hybrid parallel scheme. The experimental results indicate that (1) the GPU-aided batch-OMP algorithm shows speedups of up to 30 times than the sparse coding part of IK-SVD, (2) the optimized sparse matrix operations improve the whole procedure of IK-SVD up to 15 times,(3) the proposed parallel scheme can further accelerate the procedure of sparsely representing one large image dataset up to 24 times, and (4) G-IK-SVD can gain the same quality of dictionary learning as IK-SVD. 08 2016 Springer Science+Business Media New York
|
| [6] |
Spectral-spatial multi-feature-based deep learning for hyperspectral remote sensing image classification [J].https://doi.org/10.1007/s00500-016-2246-3 URL [本文引用: 1] |
| [7] |
基于滑动窗口的遥感图像人造目标检测算法 [J].Man-made object extraction from the remote sensing image based on sliding windows [J]. |
| [8] |
航天遥感图像感兴趣区域的自动提取方法 [J].Method for automatic extraction of region of interest in space remote sensing images [J]. |
| [9] |
一种用于图像目标识别的神经网络及其车型识别应用 [J].An neural network for image object recognition and its application to car type recognition [J]. |
| [10] |
基于卷积神经网络的SAR图像目标识别研究 [J].https://doi.org/10.12000/JR16037 Magsci [本文引用: 1] 摘要
<p>针对合成孔径雷达(Synthetic Aperture Radar, SAR)的图像目标识别应用, 该文提出了一种基于卷积神经网络(Convolutional Neural Network, CNN)的SAR图像目标识别方法。首先通过在误差代价函数中引入类别可分性度量, 提高了卷积神经网络的类别区分能力;然后利用改进后的卷积神经网络对SAR图像进行特征提取;最后利用支持向量机(Support Vector Machine, SVM)对特征进行分类。使用美国运动和静止目标获取与识别(Moving and Stationary Target Acquisition and Recognition, MSTAR)SAR图像数据进行实验, 识别结果证明了所提方法的有效性。</p>
SAR ATR based on convolutional neural network [J].https://doi.org/10.12000/JR16037 Magsci [本文引用: 1] 摘要
<p>针对合成孔径雷达(Synthetic Aperture Radar, SAR)的图像目标识别应用, 该文提出了一种基于卷积神经网络(Convolutional Neural Network, CNN)的SAR图像目标识别方法。首先通过在误差代价函数中引入类别可分性度量, 提高了卷积神经网络的类别区分能力;然后利用改进后的卷积神经网络对SAR图像进行特征提取;最后利用支持向量机(Support Vector Machine, SVM)对特征进行分类。使用美国运动和静止目标获取与识别(Moving and Stationary Target Acquisition and Recognition, MSTAR)SAR图像数据进行实验, 识别结果证明了所提方法的有效性。</p>
|
| [11] |
基于SVM的遥感影像目标检测中的样本选取 [J].https://doi.org/10.3321/j.issn:1002-8331.2006.09.064 URL [本文引用: 1] 摘要
在基于支持向量机的遥感影像目标检测中,因为有限的目标样本和相对复杂的背景,造成检测结果的虚警率偏高。论文提出了自举算法用于样本的选取,试验表明该方法可使检测的虚警率成倍降低。
Samples selection for RS object detection based on SVM [J].https://doi.org/10.3321/j.issn:1002-8331.2006.09.064 URL [本文引用: 1] 摘要
在基于支持向量机的遥感影像目标检测中,因为有限的目标样本和相对复杂的背景,造成检测结果的虚警率偏高。论文提出了自举算法用于样本的选取,试验表明该方法可使检测的虚警率成倍降低。
|
| [12] |
基于支持向量机的目标检测算法综述 [J].https://doi.org/10.13195/j.kzyjc.2013.0891 URL [本文引用: 1] 摘要
目标检测的目的在于从静态图片或视频中检测并定位设定种类的目标物体,已有研究大都将目标检测问题简化为一个二分类问题.鉴于支持向量机在模式识别领域尤其是解决二分类问题中所表现出来的优越性,如何将其应用于目标检测已成为当今计算机视觉领域关注的重点.对此,从支持向量机原理、目标特征模型构建、学习训练和目标检测框确定等角度,综述了基于支持向量机的目标检测算法的研究现状,并就进一步的发展进行了展望.
Review of object detection methods based on SVM [J].https://doi.org/10.13195/j.kzyjc.2013.0891 URL [本文引用: 1] 摘要
目标检测的目的在于从静态图片或视频中检测并定位设定种类的目标物体,已有研究大都将目标检测问题简化为一个二分类问题.鉴于支持向量机在模式识别领域尤其是解决二分类问题中所表现出来的优越性,如何将其应用于目标检测已成为当今计算机视觉领域关注的重点.对此,从支持向量机原理、目标特征模型构建、学习训练和目标检测框确定等角度,综述了基于支持向量机的目标检测算法的研究现状,并就进一步的发展进行了展望.
|
| [13] |
基于随机森林的精确目标检测方法 [J].https://doi.org/10.3969/j.issn.1001-3695.2016.09.063 URL [本文引用: 1] 摘要
针对复杂场景中目标检测精确度过低的问题,基于随机森林算法提出一种能适应由姿态、视角和形状引起外观变化的目标检测方法,同时还能有效预测最佳检测框大小,使其与真实目标区域有很高的重叠度。首先,提出一种基于图像块多维特征的树节点分裂函数;然后利用Boosting算法逐层生成树,使得每次分裂中错分样本更受关注;最后,扩展了随机森林输入输出空间,使其在分类同时还可预测目标检测框的最优长宽比。实验结果表明,该方法在不增加时间开销的同时提高了检测的精确度,对森林中树生成算法的改进提升了分类性能,对森林输出空间的扩展使得目标检测框与真实目标区域有更高的重叠率。
Random forests for accurate object detection [J].https://doi.org/10.3969/j.issn.1001-3695.2016.09.063 URL [本文引用: 1] 摘要
针对复杂场景中目标检测精确度过低的问题,基于随机森林算法提出一种能适应由姿态、视角和形状引起外观变化的目标检测方法,同时还能有效预测最佳检测框大小,使其与真实目标区域有很高的重叠度。首先,提出一种基于图像块多维特征的树节点分裂函数;然后利用Boosting算法逐层生成树,使得每次分裂中错分样本更受关注;最后,扩展了随机森林输入输出空间,使其在分类同时还可预测目标检测框的最优长宽比。实验结果表明,该方法在不增加时间开销的同时提高了检测的精确度,对森林中树生成算法的改进提升了分类性能,对森林输出空间的扩展使得目标检测框与真实目标区域有更高的重叠率。
|
| [14] |
深度学习研究综述 [J].Overview of deep learning [J]. |
| [15] |
Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. |
| [16] |
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups [J]. |
| [17] |
卷积神经网络在图像分类和目标检测应用综述 [J].https://doi.org/10.3778/j.issn.1002-8331.1703-0362 URL [本文引用: 1] 摘要
卷积神经网络具有强大的特征学习能力,随着大数据时代的到来和计算机能力的提升,近年来卷积神经网络在图像识别、目标检测等领域取得了突破性进展,掀起了新的研究热潮。综述卷积神经网络的基本原理,以及其在图像分类、目标检测上的研究进展和典型模型,最后分析了卷积神经网络目前的问题,并展望了未来的发展方向。
Application of convolution neural network in image classification and object detection [J].https://doi.org/10.3778/j.issn.1002-8331.1703-0362 URL [本文引用: 1] 摘要
卷积神经网络具有强大的特征学习能力,随着大数据时代的到来和计算机能力的提升,近年来卷积神经网络在图像识别、目标检测等领域取得了突破性进展,掀起了新的研究热潮。综述卷积神经网络的基本原理,以及其在图像分类、目标检测上的研究进展和典型模型,最后分析了卷积神经网络目前的问题,并展望了未来的发展方向。
|
| [18] |
Faster R-CNN: Towards real-time object detection with region proposal networks [J].https://doi.org/10.1109/TPAMI.2016.2577031 URL PMID: 27295650 [本文引用: 2] 摘要
Abstract State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet [1] and Fast R-CNN [2] have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features-using the recently popular terminology of neural networks with 'attention' mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model [3] , our detection system has a frame rate of 5 fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks. Code has been made publicly available.
|
| [19] |
Faster R-CNN模型在车辆检测中的应用 [J].Application of Faster R-CNN model in vehicle detection [J]. |
| [20] |
Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining [J].https://doi.org/10.3390/s17020336 URL [本文引用: 1] |
| [21] |
Faster-RCNN的车型识别分析 [J].https://doi.org/10.11835/j.issn.1000-582X.2017.07.005 URL [本文引用: 1] 摘要
车型识别是目标检测领域在智能交通的重要应用,也是近年来国内外学者的研究热点之一。针对已有车辆检测方法缺乏识别车型能力的问题,提出了基于Faster-RCNN目标检测模型与ZF、VGG-16以及ResNet-101 3种卷积神经网络分别结合的策略,实验对比了该策略中的3种结合模型方案在BIT-Vehicle和CompCars2种大型车型数据库的车型识别能力。在BIT-Vehicle数据集上,基于Faster-RCNN与ResNet-101结合模型方案的车型识别率高与其余2种结合模型方案,其车型识别率高达91.3%;在迁移测试CompCars数据集上,3种结合模型方案均展现了很好的泛化能力。
Vehicle detection based on faster-RCNN [J].https://doi.org/10.11835/j.issn.1000-582X.2017.07.005 URL [本文引用: 1] 摘要
车型识别是目标检测领域在智能交通的重要应用,也是近年来国内外学者的研究热点之一。针对已有车辆检测方法缺乏识别车型能力的问题,提出了基于Faster-RCNN目标检测模型与ZF、VGG-16以及ResNet-101 3种卷积神经网络分别结合的策略,实验对比了该策略中的3种结合模型方案在BIT-Vehicle和CompCars2种大型车型数据库的车型识别能力。在BIT-Vehicle数据集上,基于Faster-RCNN与ResNet-101结合模型方案的车型识别率高与其余2种结合模型方案,其车型识别率高达91.3%;在迁移测试CompCars数据集上,3种结合模型方案均展现了很好的泛化能力。
|
| [22] |
Vehicle pose detection using region based convolutional neural network [ |
| [23] |
基于Faster RCNN以及多部件结合的机场场面静态飞机检测 [J].Aeroplane detection in static aerodrome based on faster RCNN and multi-part model [J]. |
| [24] |
Selective search for object recognition [J].https://doi.org/10.1007/s11263-013-0620-5 URL [本文引用: 1] |
| [25] |
遥感图像飞机目标分类的卷积神经网络方法 [J].https://doi.org/10.11834/jig.160595 URL [本文引用: 1] 摘要
目的遥感图像飞机目标分类,利用可见光遥感图像对飞机类型进行有效区分,对提供军事作战信息有重要意义。针对该问题,目前存在一些传统机器学习方法,但这些方法需人工提取特征,且难以适应真实遥感图像的复杂背景。近年来,深度卷积神经网络方法兴起,网络能自动学习图像特征且泛化能力强,在计算机视觉各领域应用广泛。但深度卷积神经网络在遥感图像飞机分类问题上应用少见。本文旨在将深度卷积神经网络应用于遥感图像飞机目标分类问题。方法在缺乏公开数据集的情况下,收集了真实可见光遥感图像中的8种飞机数据,按大致4:1的比例分为训练集和测试集,并对训练集进行合理扩充。然后针对遥感图像与飞机分类的特殊性,结合深度学习卷积神经网络相关理论,有的放矢地设计了一个5层卷积神经网络。结果首先,在逐步扩充的训练集上分别训练该卷积神经网络,并分别用同一测试集进行测试,实验表明训练集扩充有利于网络训练,测试准确率从72.4%提升至97.2%。在扩充后训练集上,分别对经典传统机器学习方法、经典卷积神经网络LeNet-5和本文设计的卷积神经网络进行训练,并在同一测试集上测试,实验表明该卷积神经网络的分类准确率高于其他两种方法,最终能在测试集上达到97.2%的准确率,其余两者准确率分别为82.3%、88.7%。结论在少见使用深度卷积神经网络的遥感图像飞机目标分类问题上,本文设计了一个5层卷积神经网络加以应用。实验结果表明,该网络能适应图像场景,自动学习特征,分类效果良好。
Aircraft classification in remote-sensing images using convolutional neural networks [J].https://doi.org/10.11834/jig.160595 URL [本文引用: 1] 摘要
目的遥感图像飞机目标分类,利用可见光遥感图像对飞机类型进行有效区分,对提供军事作战信息有重要意义。针对该问题,目前存在一些传统机器学习方法,但这些方法需人工提取特征,且难以适应真实遥感图像的复杂背景。近年来,深度卷积神经网络方法兴起,网络能自动学习图像特征且泛化能力强,在计算机视觉各领域应用广泛。但深度卷积神经网络在遥感图像飞机分类问题上应用少见。本文旨在将深度卷积神经网络应用于遥感图像飞机目标分类问题。方法在缺乏公开数据集的情况下,收集了真实可见光遥感图像中的8种飞机数据,按大致4:1的比例分为训练集和测试集,并对训练集进行合理扩充。然后针对遥感图像与飞机分类的特殊性,结合深度学习卷积神经网络相关理论,有的放矢地设计了一个5层卷积神经网络。结果首先,在逐步扩充的训练集上分别训练该卷积神经网络,并分别用同一测试集进行测试,实验表明训练集扩充有利于网络训练,测试准确率从72.4%提升至97.2%。在扩充后训练集上,分别对经典传统机器学习方法、经典卷积神经网络LeNet-5和本文设计的卷积神经网络进行训练,并在同一测试集上测试,实验表明该卷积神经网络的分类准确率高于其他两种方法,最终能在测试集上达到97.2%的准确率,其余两者准确率分别为82.3%、88.7%。结论在少见使用深度卷积神经网络的遥感图像飞机目标分类问题上,本文设计了一个5层卷积神经网络加以应用。实验结果表明,该网络能适应图像场景,自动学习特征,分类效果良好。
|
| [26] |
Accurate object localization in remote sensing images based on convolutional neural networks [J].https://doi.org/10.1109/TGRS.2016.2645610 URL [本文引用: 3] 摘要
In this paper, we focus on tackling the problem of automatic accurate localization of detected objects in high-resolution remote sensing images. The two major problems for object localization in remote sensing images caused by the complex context information such images contain are achieving generalizability of the features used to describe objects and achieving accurate object locations. To address these challenges, we propose a new object localization framework, which can be divided into three processes: region proposal, classification, and accurate object localization process. First, a region proposal method is used to generate candidate regions with the aim of detecting all objects of interest within these images. Then, generic image features from a local image corresponding to each region proposal are extracted by a combination model of 2-D reduction convolutional neural networks (CNNs). Finally, to improve the location accuracy, we propose an unsupervised score-based bounding box regression (USB-BBR) algorithm, combined with a nonmaximum suppression algorithm to optimize the bounding boxes of regions that detected as objects. Experiments show that the dimension-reduction model performs better than the retrained and fine-tuned models and the detection precision of the combined CNN model is much higher than that of any single model. Also our proposed USB-BBR algorithm can more accurately locate objects within an image. Compared with traditional features extraction methods, such as elliptic Fourier transform-based histogram of oriented gradients and local binary pattern histogram Fourier, our proposed localization framework shows robustness when dealing with different complex backgrounds.
|
| [27] |
Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images [J].https://doi.org/10.1080/01431161.2014.999881 URL [本文引用: 1] |

/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}