刘文涛 , 李世华
, 李世华
LIU Wentao, LI Shihua
通讯作者:
收稿日期: 2018-04-2
修回日期: 2018-09-14
网络出版日期: 2018-11-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:刘文涛(1989- ),男,硕士,主要研究方向为计算机视觉。E-mail: liuwentaoboy@126.com
展开
摘要
高分辨率遥感影像在地面自动目标提取中得到了广泛应用,然而利用传统算法,很难高精度地进行实时的建筑物屋顶绘图。本文使用深度学习方法探讨建筑物屋顶分割,由于卷积运算对形变、旋转、光照条件的不敏感,设计了一种用于建筑物屋顶提取的深度卷积神经网络,提出的网络为级联式全卷积神经网络,在深度卷积神经网络的设计中使用了特征复用和特征增强,实现建筑物的自动精确提取。以美国马萨诸塞州建筑物数据集为基础的实验结果表明,本文提出的网络结构取得了92.3%的总体预测精度,和其他方法相比,本文提出的方法具有更高的精度
关键词:
Abstract
The very high resolution remotely sensed imagery has been widely applied in automatic extraction of ground objects, However, it is hard to conduct timely operational building roof mapping with high accuracy using conventional algorithms. This paper investigate building roof segmentation with deep learning method, since the convolution operations upon images is not sensitive to deformation,rotation and illumination condition, a Deep Convolutional Neural Network (DCNN) is designed for building roof extraction, the proposed network has a cascaded structure with fully convolutional layers, with strategies for feature reuse and enhancement in the design of DCNN, it is expected to accurately extract building roof. The experiment is carried out upon building sample data set acquired in Massachusetts, USA, the results show that the proposed network achieved overall accuracy of 92.3%, and the comparison with other methods suggest the proposed network is able to map building roof with high accuracy.
Keywords:
高分辨率遥感影像能够提供地表海量的、具有丰富纹理和光谱特征的地物信息,因此,在地图制图中得到了广泛的应用。建筑物作为城市区域地物的最重要组成部分之一,精确、及时地获取建筑物信息在地图测绘、城市规划、土地利用调查、数字城市等领域具有十分重要的作用。快速、精确、智能的提取建筑物一直都是遥感影像处理领域极其重要的内容之一[1]。近年来,研究者尝试使用多种方法来实现高分辨率遥感影像中建筑物的自动提取,安文等[2]融合了建筑物的几何结构、光谱特征等图像信息,实现对建筑物的提取;赵凌君等[3]采用分层处理的思路来检测建筑物的几何信息,实现建筑物的准确提取;候蕾等[4]使用Hough变换,结合了几何、灰度特征提取建筑物轮廓;巩丹超等[5]提出基于边界线检测建筑物的方法,
实现了建筑物自动提取。然而这些传统算法只重视建筑物的几何特征,虽然达到了自动提取建筑物的目的,但是精度不高、受环境影响大、依赖人工操作。综合来看,目前从遥感影像中自动提取建筑物存在许多困难,主要表现为3个方面:① 城市建筑物的大小差异较大,根据几何或者结构特征自动提取的往往是较大的建筑,较小的建筑会漏检或错检;② 一般建筑物的外观为规则形状(如方形的居民楼),但是城市建筑物的外观复杂多变且形状各异(如椭圆形的体育馆),如果只有人工设计的形状特征却没有上下文信息,很难提取到所有类型的建筑物;③ 城市建筑物经常被茂密的树木遮挡,而且低层建筑往往被高层建筑的阴影被遮蔽,导致提取完整的、全部的建筑物异常困难。
在建筑物、水体、植被等众多不同的地物类型之中,水体和植被等地物类型的形状多为不规则形状,所占的比重较小,并且这些地物类型在城市规划及智慧城市的建设中的重要性远小于建筑物及道路,所以提取建筑物和道路用于城市建设的变化监测是本文最核心的思想。
从计算机视觉的角度看,基于遥感影像的建筑物自动提取属于图像语义分割问题,即图像中每一个像素都有属于自己的类别,只有像元级别的分割才会产生最精确的结果。卷积神经网络[6]对二维图像的旋转、平移、缩放等变化不敏感,因而对于物体在图像中的位置变化、大小变化、角度变化而造成的识别困难具有非常好的识别效果;同时深度学习方法[7]比传统方法更能适应图像中存在的大量且复杂的特征。2012年,深度学习算法在国际视觉领域竞赛ILSVRC(ImageNet Large Scale Visual Recognition Competition)2012中取得了第一名,在百万量级的ImageNet数据集上,效果大幅度超过传统的方法,在ILSVRC-2012数据集上,深度学习算法的Top-5测试误差是15.3%,比第二名的26.2%提升将近11个百分点。该深度学习算法提出一种人工神经网络模型AlexNet[8],AlexNet通过将样本与标签进行对比,并定义损失函数(Loss Function)求解出样本与标签之间的残差,再通过链式求导法则,将残差通过求解的偏导数逐层向上传递,然后逐层调整每层的权重和偏置,直到损失函数满足全局最优解。
曲景影等[9]提出一种基于卷积神经网络模型的光学遥感图像目标识别方法,在传统LetNet-5网络结构[6]的基础上,使用卷积展开技术将卷积运算转换为矩阵乘法,提高目标识别的准确性和效率;Mnih[10]建立了基于深度卷积神经网络的遥感影像目标地物自动提取系统,通过在网络训练过程中结合上下文信息,并且使用随机条件场算法对结果进行后处理,优化了神经网络的预测结果;Nicolas等[11]提出在遥感图像中使用不同尺度的卷积核的人工神经网络,分别预测遥感图像中不同尺寸的建筑物,并在国际摄影测量与遥感学会的官方数据集上取得最好的结果;Saito等[12]提出一种用于自动提取遥感图像中建筑物的卷积神经网络,将这个神经网络同时作为分类器和提取器,并使用通道抑制多分类(channel-wise inhibited softmax)代替原来的softmax多分类,为了避免过拟合,将8张有移位的输入图与单个模型的8个输出图进行匹配及合并,达到了同时检测和提取建筑物的目的。尽管图像卷积操作对图像内容有较强的抽象能力,但在卷积计算过程中由于平滑效应导致图像损失了大量有用信息,这使得卷积神经网络在建筑物边缘识别上精度较低,需要对识别结果进行后处理。
本文基于深度学习的思想,提出一种级联式全卷积神经网络结构。该网络结构引入级联结构[13]对全卷积神经网络FCN(Fully Convolutional Networks)[14]进行改进,利用卷积神经网络CNN(Convolutional Neural Network)权值共享、局部连接、逐层学习的特点构建密集深度神经网络,再引入空洞卷积[15]扩大卷积操作产生的特征图的感受野。本文提出的网络模型不仅可以减少网络参数规模,而且还可以提高预测结果的总体精度。
深度学习算法中的深度卷积神经网络和传统的浅层机器学习分类模型SVM(Support Vector Machine)[16]、Boosting算法[17]相比较,深度卷积神经网络具有更深的网络结构和更强大的非线性拟合能力,能够从像素级原始数据到抽象的语义概念逐层提取信息;而从特征提取的角度看,相对传统的特征提取算法SIFT(Scale-invariant Feature Transform)[18],深度卷积神经网络可以从大量数据中自动学习特征,而非采用手工设计的特征。
深度卷积神经网络有强大的学习能力和高效的特征表达能力,使它在提取图像的全局、局部特征和上下文信息方面具有突出的优势,为图像分割带来了新的思路。
本文提出一种基于深度学习算法提取遥感影像中建筑物的级联式全卷积神经网络。本文将原始的遥感影像定义为R:
式中:R(n)是单幅多波段遥感影像。将多通道像元级的标签影像定义为G:
式中:G(n)是单幅标签影像,标签影像也称为真实值。本文提出的算法需要从遥感影像S中预测出像元级的建筑物分割图像
本文的基础网络结构采用VGG-Net[19],并在此基础上构建新的网络结构。由于VGG-Net已经在拥有120万张图像的ImageNet数据集上训练并得到优秀的分类结果,所以本文保留了原来VGG-Net网络结构的5组共13个卷积层,将原本用于提取特征的2个全连接卷积层和用于分类特征的1个全连接层去除,但是大小为256×256的输入图像在经过卷积神经网络后最终得到的输出图像的大小会变成输入图像的1/32即8×8,这样的分辨率显然不满足输出结果的需要。
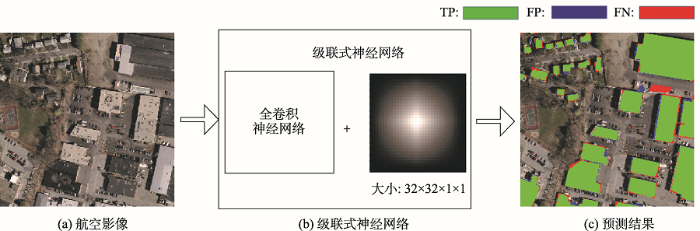
本文提出的级联式全卷积网络结构(图1)不仅满足输出结果要求,还可以达到以下4个目的:
(1)特征图变大:网络最终输出为原始输入图像的1/32,为了让输入特征图像尺寸变大,在原有的每一组卷积层后面增加1×1大小的卷积层,再使用反卷积操作进行上采样,最后和前一组卷积的输出结果进行级联,一起作为下一组卷积层的输入,这样有利于减少信息损失。
(2)感受野增大:为了使神经元的感受野增大,在最后两组卷积层中加入了空洞卷积,神经元的感受野的增大可以保证每一个神经元对应的特征图区域变大,可以包含更多的上下文信息,有利于大物体的识别。
(3)特征增强:为了达到重复利用特征信息,并同时强化特征传播路径的目的,在原有的每一组卷积层产生的特征图像后面融合了输入图像,经过特征融合后生成的新特征图像直接可以使用原始输入图像的信息,并且还使用了之前卷积层对原始输入图像处理之后的信息,这样可以使网络内部的信息流量最大化,也保证了更加密集的输出特征,为最后的特征提取奠定了优良的数据基础。具体网络内部参数如表1所示。
表1 网络层参数
Tab. 1 Network layer parameters
| 网络层 | 大小 | 网络层 | 大小 |
|---|---|---|---|
| Conv1-1 | 3×3×64 | Deconv1-1 | 1×1 |
| Conv1-2 | 3×3×64 | Deconv1-2 | 1×1 |
| MaxPooling | 2×2 | - | - |
| Conv2-1 | 3×3×128 | Deconv2-1 | 4×4 |
| Conv2-2 | 3×3×128 | Deconv2-2 | 4×4 |
| MaxPooling | 2×2 | - | - |
| Conv3-1 | 3×3×256 | Deconv3-1 | 8×8 |
| Conv3-2 | 3×3×256 | Deconv3-2 | 8×8 |
| Conv3-3 | 3×3×256 | Deconv3-3 | 8×8 |
| MaxPooling | 2×2 | - | - |
| Conv4-1 | 3×3×512 | Deconv4-1 | 16×16 |
| Conv4-2 | 3×3×512 | Deconv4-2 | 16×16 |
| Conv4-3 | 3×3×512 | Deconv4-3 | 16×16 |
| MaxPooling | 2×2 | - | - |
| Conv5-1 | 3×3×512 | Deconv5-1 | 32×32 |
| Conv5-2 | 3×3×512 | Deconv5-2 | 32×32 |
| Conv5-3 | 3×3×512 | Deconv5-3 | 32×32 |
(4)影像分块:一般情况下,深度神经网络的输入图像的尺寸为或者更小的尺寸。经过多次卷积以后,权值参数大量增加,对计算机性能的要求也越来越高,而遥感影像的大小远远超过了目前神经网络的输入图像的大小限制,本文引入一个很重要的“分块”机制,确保计算机不会因为显存不够而宕机,也可以保证网络的正常训练。
在图1的网络结构中,卷积层主要用于提取特征;池化层主要用于下采样,降低维度;反卷积层主要用于语义信息填充与恢复;链接(黑色曲线,Concat层)实现了多输入到单输出,主要通过Crop(裁剪)、增加Padding及大小为1×1的卷积层实现同样大小不同通道的特征图的数据融合;空洞卷积Dilation rate=2。
本文将所有的输入的遥感影像看做一个图像数据的组合
其中,
则损失函数可以表示标准的交叉熵形式:

式中:|n|代表一张训练图像中像素点的总数目,即256×256 = 6553个。
在深度神经网络训练的过程中,通常需要设置一些超参数来初始化网络结构和训练模式,包括学习率、动量、权值衰减等等。
学习率是深度神经网络中的一个重要的超参,如何调整学习率是训练出好模型的关键要素之一。在通过随机梯度下降求解极小值时,如果学习率太大,随着迭代次数增大,loss(残差)值可能不会出现减小的趋势;学习率太小会导致无法快速地找到好的下降方向,随着迭代次数增大loss(残差)值几乎不变。本文尝试了不同的学习率,包括1e-1、1e-2、1e-3、1e-4、1e-5,并且让学习率在训练过程中不断更新来降低网络训练的误差,训练结果证实1e-5可以满足网络对随机梯度下降算法的要求。
由于本文的数据量较大,计算机不可能一次性处理所有的输入数据,所以必须采用分批处理的思想,即每次都取出一定数量(Batchsize=12&24)的数据进行迭代,所有数据完成一次迭代训练,作为一个epoch。
为了避免随机梯度下降算法过程中结果陷入局部最小值,本文加入动量因子(momentum: 0.9),这样可以保证当结果陷入局部最小值后网络具有继续搜索极值的能力。
权值衰减是避免网络过拟合的一个重要参数,因为当网络出现过拟合时权值会逐渐变大,此时过拟合的风险增加,网络的泛化能力降低,为了防止这种情况发生,需要设置权值衰减惩罚项使权值收敛到较小的权值,并惩罚较大的权值,常用的惩罚项是所有权值的平方乘以一个衰减常量之和。
本文使用深度学习框架Caffe[20]训练深度卷积神经网络,在内存8 G、英伟达GTX 1060显卡(显存4 GB)中完成一次完整的训练需要27 h。网络超参数设置如表2所示。
表2 超参数
Tab. 2 Hyper parameters
| 超参数 | 设置方案一 | 设置方案二 |
|---|---|---|
| 批处理大小 | 24 | 12 |
| 权值衰减 | 5e-4 | 5e-4 |
| 动量因子 | 0.9 | 0.9 |
| 最大迭代次数 | 20 000 | 15 000 |
| 学习率 | 1e-4 | 1e-5 |
在使用机器学习算法中,针对不同场景需要不同的评价指标,比如精确率与召回率、ROC(receiver operating characteristic curve)、混淆矩阵((Confusion Matrix))、Kappa系数、准确率(Precision)等等。在ILSVRC(ImageNet Large Scale Visual Recognition Competition)和MicroSoft COCO(MicroSoft Common Object in Context)等国际主流计算机视觉竞赛中,一般采用了精确率与召回率、混淆矩阵和准确率等指标来进行结果评价与对比,
本文也沿用这3个指标来评价建筑物分割精度。在机器学习的二分类问题中,分类器将一个实例的分类结果标记为是或否,这可以用一个混淆矩阵来表示。
混淆矩阵将分类预测结果与实际目标进行比较,并汇总成N×N列联表(N为分类类型数)。混淆矩阵的4个值,如表3所示;本文设置阈值为0.5,超过此阈值定义为建筑物(1),低于此阈值定义为非建筑物(0),最后可以计算出混淆矩阵。
TP(True Positive):指正确分类的正样本数,即预测结果为正样本,实际样本也是正样本。本文设置TP为绿色。
FP(False Positive):指被错误的标记为正样本的负样本数,即实际样本为负样本,而被预测为正样本。本文设置FP为蓝色。
TN(True Negative):指正确分类的负样本数,即预测结果为负样本,实际样本也是负样本。
FN(False Negative):指被错误的标记为负样本的正样本数,即实际样本为正样本,而被预测为负样本。本文设置FN为红色。
精确率表示为预测正确的正样本数目与所有预测为正样本的数目的比值。
召回率表示为预测正确的正样本数目与测试集所有正样本数目的比值。
本文使用的评价指标为Precision-Recall(准确率-召回率),通常绘制Precison-Recall曲线表示预测的准确率和模型的可靠性。
准确率(Accuracy)衡量分类结果正确的比例。设
式中:I(x)是indicator function(指标函数),当预测结果与真实情况完全相符时准确率为1,二者越不相符准确率越低。
可视化神经网络的思想的主旨构建一个具有逆向输出功能的卷积神经网络(不包括训练过程),将原网络各个网络层的特征图作为输入,逆向生成像元级图片。逆向输出的目的是研究不同网络层中每一个神经元对应的特征的真实情况[21]。本文使用深度学习框架Caffe训练级联式全卷积神经网络,提取出建筑物的有用特征,将数据集存储成 l mdb格式,保存网络训练迭代15 000次时生成的网络模型,运用Jupyter Notebook进行神经网络内部特征可视化。
卷积过程是使用一个可以反向传播训练的卷积核(即滤波器)fx和输入图像进行卷积操作,再加上转置参数bx,组成了卷积层Cx。卷积层的形式如式(8)所示。
式中:l代表层数;k代表卷积核;Mj代表输入层的所以特征图的集合。
本文提出的级联式卷积神经网络的第一层卷积核大小为64×3×3,权值参数如图2所示。
由于卷积产生了大量特征,计算复杂度呈指数级上升,为了消除非极大值,从而降低计算复杂度,在卷积过程之后就是采样过程,采样过程提供了一种平移不变的形式[22]。
下采样是常用的一种采样方法。通过计算图像某一个区域里某个特定特征的平均值(或最大值)。这些统计特征具有很低的维度,同时还不容易过拟合。这种数据聚合的操作就叫做池化(pooling),有时也称为平均池化(Average-pooling)或者最大池化(Max-pooling)。本文采用最大池化的方法对经过卷积操作的输入图像进行下采样,输入的航空影像和对应的标签影像如图3所示。
卷积神经网络第一个卷积层检测低阶特征(如边、角、曲线等),第二个卷积层的输入实际上是第一层的输出,第二层的卷积层可以检测低价特征的组合(如圆、多边形等)。随着卷积层的增加,检测到更多的高阶特征,这些特征更加复杂,更加抽象,它们是更低阶特征的组合,经过卷积运算的特征图如图4所示。
整个神经网络的结构是:卷积层+池化层+激活函数层+[卷积层+池化层+激活函数层]n+分类层,其中卷积层是神经网络的核心所在,卷积操作大约占据了神经网络所有计算量的70%~80%。神经网络的学习方式属于监督学习,依靠输入的训练数据和标记数据,神经网络网络可以进行自我修正,这个过程称为反向传播。反向传播在高层将反馈发送到上一层的节点,告诉它真实值和预测值差了多少。然后,该层再将反馈发送到上一层,再传到上一层,直到它回到第一个卷积层,对网络的所有权值参数进行调整,让每个神经元在随后的图像在网络中传递时更好地识别特征。这个过程会一直反复进行,直到神经网络定义的损失函数收敛到一个很小的范围(0-0.3),在神经网络的最后,需要判断预测的结果是否为建筑物,本文使用32×32×1×1的卷积层(卷积核大小为1×1,卷积核数量为32×32),根据二分类算法将建筑物特征标记为1,将非建筑物特征标记为0。最终预测过程如图5所示。
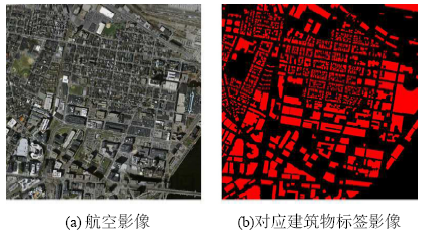
本文的实验采用的数据集来自Mnih和Hinton教授在2013年建立的美国马萨诸塞州建筑物和道路公开数据集(官方数据集下载网址见文献[23]),该数据集含有151张遥感影像,每张遥感影像的分辨率为1500×1500,并且每张影像涵盖了美国波士顿地区大约2.25 km2的区域。本文把数据集划分为3部分:训练数据集(137张)、验证数据集(4张)、测试数据集(10张),然后用大小为256×256、步长为64的滑动窗口分别在原始训练数据集和原始测试数据集上截取图像块,这些图像块会作为深度神经网络的输入训练数据和输入测试数据。图6是本文将采用的建筑物数据集中的两张R(n)和对应的G(n)。其中R(n)是某一幅遥感影像,G(n)是对应的标签影像。
图6 航空影像和航空影像对应建筑物标签影像注:红色为建筑物屋顶,黑色为非建筑
Fig. 6 Aerial image and label image of builing correponding to aerial image
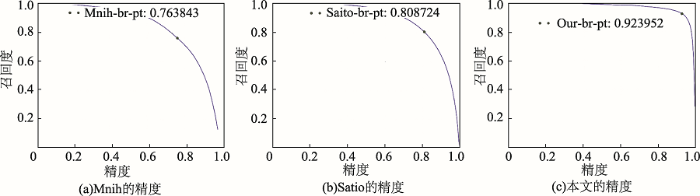
Mnih[10]提出3个卷积层+2个全连接层的网络结构,Satio[12]提出13个卷积层+5个池化层+3个全连接层的网络结构,本文实现了上述2种卷积神经网络结构,并与本文提出的级联式全卷积神经网络进行比较。总体结果使用Precision-Recall曲线表示3种结果,具体结果如图7所示。可以看出本文的总体结果(Our-br-pt:0.923952)明显优于其他2种方法(Mnih-br-pt:0.763843和Saito-br-pt:0.808724)。
图7 Mnih的精度、Satio的精度和本文的精度
Fig. 7 The accuracy of Mnih, andthe accuracy of Satio and the accuracy of this article
其中,Our-br-pt表示预测结果的精确率-召回率最大值,即Pecision和Recall的最大值转折点。一般情况下,二者取值在0和1之间,数值越接近1,精确率或召回率就越高;而最大转折点的数值越大,说明模型的预测能力越高。
本文从1500×1500的原始遥感图像中任意选取5张作为测试图像。在每一幅测试图像中,以左上角像素点为坐标原点(0,0),随机设置起始坐标点,截取五个128×128的图像,随机坐标点设置如表4。
表4 测试图像的随机坐标点(pixel)
Tab. 4 Test images of random coordinate points
| 图像ID | 坐标(X) | 坐标(Y) |
|---|---|---|
| Patch ID:1 | 600 | 600 |
| Patch ID:2 | 700 | 300 |
| Patch ID:3 | 900 | 900 |
| Patch ID:4 | 500 | 600 |
| Patch ID:5 | 600 | 500 |
测试结构测试图像的建筑物分类精度如表5,精度介于0和1之间,数值越大则分类精度越高,可以看到本文的预测精度均比Mnih[10]和Satio[12]高。与Mnih[10]比较,最大提升9.1%,与Satio[12]比较,最大提升4.7%。
表5 测试图像的分类精度
Tab. 5 Accuracies of the test images
| 图像ID | Patch ID:1 | Patch ID:2 | Patch ID:3 | Patch ID:4 | Patch ID:5 |
|---|---|---|---|---|---|
| Mnih[10] | 0.890 | 0.845 | 0.856 | 0.863 | 0.883 |
| Satio[12] | 0.909 | 0.879 | 0.899 | 0.904 | 0.910 |
| Ours | 0.939 | 0.913 | 0.934 | 0.913 | 0.953 |
| Ours(vs)Mnih[10] | 5.5%+ | 8.0%+ | 9.1%+ | 5.8%+ | 7.9%+ |
| Ours(vs)Satio[12] | 3.3%+ | 3.9%+ | 3.9%+ | 0.1%+ | 4.7%+ |
使用绿色表示TP(True Positive),即预测结果为建筑物,实际样本也为建筑物;使用蓝色表示FP(False Positive),即实际样本为非建筑物,但预测结果为建筑物;用红色表示FN(False Negative),即实际样本为建筑物,预测结果为非建筑物;最终将所有建筑物的预测结果用分类图来表示。白色虚线是相同图像的相同位置里的不同预测结果,如图8所示。
本文提出了一种级联式全卷积神经网络结构。改进了传统的全卷积神经网络,将级联结构引入深度卷积神经网络,利用特征复用和特征增强等方法提高了网络内部信息之间的流动,另外,避免了网络反向传播过程中梯度消失现象的出现,可以让网络层的深度大大增加;加入了空洞卷积,可以保证卷积神经网络在不做池化处理的情况下增大感受野,让每个卷积的输出特征图像都包含更多信息,有助于融合图像的全局信息和局部信息,提高分割的精度;并引入图像分块的思想保证网络可以正常训练,最终得到精度较高的网络模型。本文提出的网络结构的优势在于只需要输入一幅原始遥感影像,不需要裁剪、放缩、白化、主成分分析、归一化等其他任何图像预处理方法,便可以得到同尺寸的高精度建筑物提取结果图,最终本文得到了优于其他主流方法的建筑物提取精度。
在未来工作中要尝试采用更深的网络结构如具有100层以上网络层的ResNet、有更小卷积核和更宽网络结构的Inception等网络结构,这些在视觉识别领域的前沿工作都可以在遥感图像处理领域得到拓展;深度卷积神经网络的超参数逐渐抛弃经验值,而需要利用贝叶斯优化方法找到最优值;推导适应性更强的激活函数和性能更好的损失函数都会提升精度,这些都是未来的工作要探索的内容。
The authors have declared that no competing interests exist.
| [1] |
高空间分辨率遥感影像建筑物提取研究综述 [J].
遥感影像上建筑物提取的基础理论研究始于20世纪80年代,本文首先对遥感影像上建筑物提取 的研究历史进行分析,总结高分辨率航空相片或卫星影像提取建筑物等人工地物信息的主要方法,从影像数据、分辨率与方法几个方面概括建筑物提取的发展历史。 深入分析建筑物自动提取三个主要类别的提取方法,即基于区域分割的方法、基于直线和角点检测与匹配的方法、利用辅助知识的方法,在此基础上,总结高空间分 辨率遥感影像建筑物提取研究的现状以及发展趋势。
Research review on the extraction of high spatial resolution remote sensing images [J].
遥感影像上建筑物提取的基础理论研究始于20世纪80年代,本文首先对遥感影像上建筑物提取 的研究历史进行分析,总结高分辨率航空相片或卫星影像提取建筑物等人工地物信息的主要方法,从影像数据、分辨率与方法几个方面概括建筑物提取的发展历史。 深入分析建筑物自动提取三个主要类别的提取方法,即基于区域分割的方法、基于直线和角点检测与匹配的方法、利用辅助知识的方法,在此基础上,总结高空间分 辨率遥感影像建筑物提取研究的现状以及发展趋势。
|
| [2] |
高分辨率遥感影像的建筑物自动提取 [J].
文章结合结构图分析方法,提出一种针对高分辨率遥感影像中建筑物 自动提取方法.该方法利用几何限制对线基元进行初连接,解决由于边缘检测无法完整提取建筑外边缘问题;通过构造结构图确立线基元之间连接关系,搜索结构图 中闭合路径,建立高级别特征,对过于散列的线基元进行整合;在此基础上,综合考虑建筑物的几何结构、光谱特征等图像信息筛选闭合路径,实现对建筑物的提 取.最后通过对天绘一号高分辨率遥感影像进行建筑物自动提取验证了该方法的有效性.
Building automatic extraction of high resolution remote sensing images [J].
文章结合结构图分析方法,提出一种针对高分辨率遥感影像中建筑物 自动提取方法.该方法利用几何限制对线基元进行初连接,解决由于边缘检测无法完整提取建筑外边缘问题;通过构造结构图确立线基元之间连接关系,搜索结构图 中闭合路径,建立高级别特征,对过于散列的线基元进行整合;在此基础上,综合考虑建筑物的几何结构、光谱特征等图像信息筛选闭合路径,实现对建筑物的提 取.最后通过对天绘一号高分辨率遥感影像进行建筑物自动提取验证了该方法的有效性.
|
| [3] |
高分辨率SAR图像建筑物提取方法研究[D] .Research on extraction method of high resolution SAR image buildings[D] . |
| [4] |
一种遥感图像中建筑物的自动提取方法 [J].The automatic extraction method of buildings in a remote sensing image [J]. |
| [5] |
基于航空影像的建筑物半自动提取技术研究 [J].https://doi.org/10.3969/j.issn.0494-0911.2002.10.005 URL [本文引用: 1] 摘要
从立体像对上提取建筑物是地形测图和城市3维建模的重要任务,建筑物的自动提取也一直是数字摄影测量领域研究的主要内容之一.针对规则房屋的半自动提取技术展开研究,提出几种房屋提取的方法和策略.
Research on the semi-automatic extraction of buildings based on aerial images [J].https://doi.org/10.3969/j.issn.0494-0911.2002.10.005 URL [本文引用: 1] 摘要
从立体像对上提取建筑物是地形测图和城市3维建模的重要任务,建筑物的自动提取也一直是数字摄影测量领域研究的主要内容之一.针对规则房屋的半自动提取技术展开研究,提出几种房屋提取的方法和策略.
|
| [6] |
Global training of document processing systems using graph transformer networks [J].https://doi.org/10.1109/CVPR.1997.609370 URL [本文引用: 2] 摘要
We propose a new machine learning paradigm called Graph Transformer Networks that extends the applicability of gradient-based learning algorithms to systems composed of modules that take graphs as inputs and produce graphs as output. Training is performed by computing gradients of a global objective function with respect to all the parameters in the system using a kind of back-propagation procedure. A complete check reading system based on these concepts is described. The system uses convolutional neural network character recognizers, combined with global training techniques to provide record accuracy on business and personal checks. It is presently deployed commercially and reads million of checks per month
|
| [7] |
A fast learning algorithm for deep belief nets [J].https://doi.org/10.1162/neco.2006.18.7.1527 URL [本文引用: 1] 摘要
We show how to use “complementary priors” to eliminate the explaining-away effects thatmake inference difficult in densely connected belief nets that have many hidden layers. Using complementary priors, we derive a fast, greedy algorithm that can learn deep, directed belief networks one layer at a time, provided the top two layers form an undirected associative memory. The fast, greedy algorithm is used to initialize a slower learning procedure that fine-tunes the weights using a contrastive version of thewake-sleep algorithm. After fine-tuning, a networkwith three hidden layers forms a very good generative model of the joint distribution of handwritten digit images and their labels. This generative model gives better digit classification than the best discriminative learning algorithms. The low-dimensional manifolds on which the digits lie are modeled by long ravines in the free-energy landscape of the top-level associative memory, and it is easy to explore these ravines by using the directed connections to displaywhat the associativememory has in mind.
|
| [8] |
ImageNet classification with deep convolutional neural networks [J].https://doi.org/10.1145/3065386 URL [本文引用: 1] 摘要
Abstract We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into the 1000 dif-ferent classes. On the test data, we achieved top-1 and top-5 error rates of 37.5% and 17.0% which is considerably better than the previous state-of-the-art. The neural network, which has 60 million parameters and 650,000 neurons, consists of five convolutional layers, some of which are followed by max-pooling layers, and three fully-connected layers with a final 1000-way softmax. To make train-ing faster, we used non-saturating neurons and a very efficient GPU implemen-tation of the convolution operation. To reduce overfitting in the fully-connected layers we employed a recently-developed regularization method called "dropout" that proved to be very effective. We also entered a variant of this model in the ILSVRC-2012 competition and achieved a winning top-5 test error rate of 15.3%, compared to 26.2% achieved by the second-best entry.
|
| [9] |
基于CNN模型的高分辨率遥感图像目标识别 [J].https://doi.org/10.3969/j.issn.1002-8978.2016.08.011 URL [本文引用: 1] 摘要
遥感图像目标识别作为当前遥感图像应用领域中的主要研究内容,具有重要的理论意义和广泛的应用价值。近年来,深度学习成为机器学习领域的一个新兴研究方向,卷积神经网络(convolutional neural networks,CNN)是一种得到广泛研究与应用的深度学习模型。提出一种基于CNN模型的光学遥感图像目标识别方法,在传统LeNet-5网络结构的基础上,引入ReLU激活函数代替传统的Sigmoid函数和tanh函数,使用卷积展开技术将卷积运算转换为矩阵乘法,并对网络结构进行调整优化,提高目标识别的准确性和效率。利用Quick Bird上的0.6m分辨率的遥感图像进行验证,实验结果表明,基于改进的CNN模型的方法可以取得较高的目标识别准确率和效率。
The target recognition of high-resolution remote sensing image based on CNN model [J].https://doi.org/10.3969/j.issn.1002-8978.2016.08.011 URL [本文引用: 1] 摘要
遥感图像目标识别作为当前遥感图像应用领域中的主要研究内容,具有重要的理论意义和广泛的应用价值。近年来,深度学习成为机器学习领域的一个新兴研究方向,卷积神经网络(convolutional neural networks,CNN)是一种得到广泛研究与应用的深度学习模型。提出一种基于CNN模型的光学遥感图像目标识别方法,在传统LeNet-5网络结构的基础上,引入ReLU激活函数代替传统的Sigmoid函数和tanh函数,使用卷积展开技术将卷积运算转换为矩阵乘法,并对网络结构进行调整优化,提高目标识别的准确性和效率。利用Quick Bird上的0.6m分辨率的遥感图像进行验证,实验结果表明,基于改进的CNN模型的方法可以取得较高的目标识别准确率和效率。
|
| [10] |
Machine learning for aerial image labeling[D] . |
| [11] |
Semantic segmentation of earth observation data using multimodal and multi-scale deep networks [J]. |
| [12] |
Multiple object extraction from aerial imagery with convolutional neural networks [J].https://doi.org/10.2352/ISSN.2470-1173.2016.10.ROBVIS-392 URL [本文引用: 6] 摘要
An automatic system to extract terrestrial objects from aerial imagery has many applications in a wide range of areas. However, in general, this task has been performed by human experts manually, so that it is very costly and time consuming. There have been many attempts at automating this task, but many of the existing works are based on class-specific features and classifiers. In this article, the authors propose a convolutional neural network (CNN)-based building and road extraction system. This takes raw pixel values in aerial imagery as input and outputs predicted three-channel label images (building-road-background). Using CNNs, both feature extractors and classifiers are automatically constructed. The authors propose a new technique to train a single CNN efficiently for extracting multiple kinds of objects simultaneously. Finally, they show that the proposed technique improves the prediction performance and surpasses state-of-the-art results tested on a publicly available aerial imagery dataset.
|
| [13] |
The cascade-correlation learning architecture [J]. |
| [14] |
Fully convolutional networks for semantic segmentation [C]. |
| [15] |
Deep lab semantic image segmentation with task-Specific edge detection using CNNs and a discriminatively trained domain transform [C]. |
| [16] |
Support-vector networks [J]. |
| [17] |
A Decision-theoretic generalization of on-line learning and an application to boosting [J].https://doi.org/10.1007/3-540-59119-2_166 URL [本文引用: 1] 摘要
We consider the problem of dynamically apportioning resources among a set of options in a worst-case on-line framework. The model we study can be interpreted as a broad, abstract extension of the well-studied on-line prediction model to a general decision-theoretic setting. We show that the multiplicative weight-update rule of Littlestone and Warmuth [10] can be adapted to this mode yielding bounds that are slightly weaker in some cases, but applicable to a considerably more general class of learning problems. We show how the resulting learning algorithm can be applied to a variety of problems, including gambling, multiple-outcome prediction, repeated games and prediction of points in 鈩 n . We also show how the weight-update rule can be used to derive a new boosting algorithm which does not require prior knowledge about the performance of the weak learning algorithm.
|
| [18] |
Object recognition from local scale-invariant features [C]. |
| [19] |
Very deep convolutional networks for large-scale image recognition [J]. |
| [20] |
Caffe: Convolutional architecture for fast feature embedding [M]. |
| [21] |
Visualizing and Understanding Convolutional Networks [C]. |
| [22] |
A Theoretical Analysis of Feature Pooling in Visual Recognition [C]. |
| [23] |
|

/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}