邬群勇 , 苏克云, 邹智杰
, 苏克云, 邹智杰
1. 福州大学地理空间信息技术国家地方联合工程研究中心,福州 350002;2. 空间数据挖掘与信息共享教育部重点实验室,福州 350002
WU Qunyong, SU Keyun, ZOU Zhijie
通讯作者:
收稿日期: 2017-08-10
修回日期: 2018-03-7
网络出版日期: 2018-05-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
展开
摘要
公交乘客出行OD能够反映居民出行特征和出行需求,是进行公交系统评价、调度和线路优化的重要基础数据,对城市规划具有重要的实用价值。现有公交OD推算方法多适用于少量公交数据,无法直接快速地推算海量公交乘客出行OD,因此本文提出了一种基于MapReduce的海量公交乘客OD并行推算方法。首先将公交数据从关系型数据库迁移至HBase数据库;接着利用MapReduce并行计算框架,根据HBase中IC卡数据的Region数量分成多个map任务,每个map任务中Map函数计算上车站点,Reduce函数将上车站点以用户为单位进行归并输出到HDFS;然后在上车记录数据的基础上,根据HDFS存储的块数量分成多个map任务,针对每个乘客的出行记录,综合考虑出行链方法和历史相似出行行为规律实现对公交乘客下车站点较为精确的推算。最后以厦门2015年6月13日至26日的IC卡数据和公交车辆GPS数据进行实例分析,共计算出295条公交线路,16 879 661条上车记录,14 410 058条完整OD记录,占IC卡数据的78.9%,计算效率相比传统方法有较大幅度提升。结果表明:该方法不仅可以较为准确地推算公交乘客上下车站点,而且计算效率较高。
关键词:
Abstract
Bus passengers' origin and destinations (OD) can truly reflect travel characteristics and demands of residents, which is an important basic data for bus system evaluation, scheduling and route optimization, with significantly practical value in urban planning. Existing OD estimation methods are mostly applied to a small amount of bus data, which cannot directly and rapidly calculate mass transit passenger OD. In order to solve these problems, a parallel method for calculation of massive transit passengers' origin and destinations based on MapReduce is investigated. Firstly, database migration tool was applied to transfer massive bus data stored in relational database to HBase. Secondly, MapReduce parallel computing framework was introduced to divide the IC card data into multiple Map tasks in the light of region numbers in HBase to calculate origins. The origins are grouped and stored into HDFS by user in the Reduce function. Thirdly, the destinations are estimated by origins in parallel which are divided into multiple Map tasks according to block numbers stored in HDFS. According to the travel record of each passenger, destinations can be accurately calculated by the means of public transit chain method and history similarity. In the end, taking IC card data and GPS bus data in Xiamen from June 13 to 26, 2015 as the example, which has 295 bus lines, 16 879 661 bus records, and 14 410 058 complete OD pairs which accounted for 78.9% of IC card data. Comparing with the traditional method, the computational efficiency has substantially improved. The results illustrate that the parallel method can not only calculate bus passenger OD accurately, but also has higher computational efficiency.
Keywords:
随着智能公交系统的发展与普及,智能公交系统收费、车辆监控等系统中积累了海量的IC卡数据和公交车辆GPS数据,蕴藏着真实、全面的公交客流信息[1,2]。如何利用大数据技术和数据挖掘技术从这些海量数据中快速获取真实全面的公交客流OD(Origin-Destination)信息,发现其中隐含的公共交通模式及规则,获得高层的、潜在的规律是智能公交系统建设的重点,也是研究的热点问题。
目前我国的公交收费大都是一票制的,即只需上车刷卡,下车无需刷卡。在缺乏准确定位信息的情况下,通过对IC卡数据的刷卡时间间隔进行聚类,将聚类结果结合公交车辆调度信息和线路站点信息来推算公交乘客的上车站点[3,4,5,6]。随着车辆GPS定位技术的发展与普及,公交车辆实时的位置信息以及其他状态信息更容易获得,研究者更青睐于基于公交车辆GPS数据和IC卡数据来推算上车站点,利用乘客在公交线间的换乘信息以及地铁 和公交线间的换乘信息来推算公交乘客的上车站点[7,8]。而更多的是基于IC卡刷卡时间和公交车辆到离站时间,建立一定的匹配约束规则来推算上车站点[9,10,11,12,13,14]。对于下车站点的推算,根据公交乘客的出行特征主要有3种推算方法:基于公交站点的站点吸引权法、基于单个乘客的连续出行链方法和基于多源数据通勤出行方法。基于公交站点的站点吸引权法是指同时考虑居民公交出行距离近似符合泊松分布规律、受站点周边用地性质影响以及该站点上下车人数吸引强度3个影响因子来确定乘客出行在每个站点的下车概率,推算乘客的下车站 点[15,16]。基于单个乘客的出行链方法是在连续公交出行假设的基础上推算乘客的下车站点[17,18,19,20,21],但连续公交出行只是公交出行一部分,有的学者在出行链的基础上结合站点吸引权法来推算下车站点[22]。基于多源数据通勤出行方法是在多种数据源的条件下追踪乘客的出行及换乘记录推算下车站点[23,24]。
上述研究方法大多是利用一条或者几条公交线路的刷卡数据来推算乘客的上下车点。随着大数据和并行技术的发展,为海量公交数据OD推算提供了一种新的解决方案。本文提出一种基于MapReduce的海量公交乘客OD并行推算方法,这种方法运用大数据领域目前比较成熟的MapReduce并行计算框架、HBase非关系型数据库,融合连续出行链方法和居民出行特征较为准确地推算乘客的上下车站点,真实全面地反映居民公交出行的客流信息,并以厦门市的公交数据验证了所提出方法的实用性。
本文数据主要有厦门IC卡数据、公交车辆GPS数据、公交车辆基本信息数据和厦门市公交线路站点数据。公交IC卡原始数据包括运营公司、数据库时间(刷卡记录存储到服务器时间)、IC卡编号、刷卡时间、刷卡金额、卡类型、线路编号、IC卡设备编号、公交车辆编号等字段。原始公交车辆GPS数据有22个字段,不仅记录车辆的实时位置信息,还记录车辆到达与离开站点的相关信息。在进行公交OD推算之前需要对原始数据进行预处理,删除冗余字段,保留所需字段信息,并转换成所需的数据格式。本文研究选取IC卡数据的IC卡编号、刷卡时间、线路编号、公交车辆编号4个字段属性,选取公交车辆GPS数据的GPS设备编号、GPS时间、纬度、经度、行驶方向、进出站标志、站点编号、线路编号8个字段属性。
本文使用HBase数据库来存储公交数据,公交IC卡数据以IC卡编号和刷卡时间为组合行键,分别将IC卡编号、刷卡时间、线路编号、公交车辆编号添加到指定列簇,如表1所示。公交车辆GPS数据以GPS设备编号和GPS时间为组合行键,分别将GPS设备编号、线路编号、行驶方向、GPS时间、进出站标志、站点编号、经度、纬度添加到指定的列簇,如表2所示。HBase数据库根据IC卡数据表中行键的值进行分区,每个行键区间构成一个分区(Region),共有52个Region,每个Region表示一定数量IC卡号的刷卡记录。公交车辆GPS数据表和IC卡数据表一样按照行键值被分成184个Region,每个Region表示一定数量公交车辆的GPS数据。
表2 公交车辆GPS数据结构
Tab. 2 Data structure of bus GPS
| 行键 | 列簇 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| GPS设备编号:GPS时间 | GPS设 备编号 | 线路 编号 | 行驶 方向 | GPS 时间 | 进出站标志 | 站点编号 | 经度 | 纬度 | |
公交线路站点数据包括公交线路信息及其所属站点的经纬度信息,本文将公交线路站点数据以公交线路编号为键,以该条线路所属的所有站点信息为值,存储到HDFS。公交车辆信息包括车辆编号与GPS设备编号的对应关系,以公交车辆编号为键,以对应的GPS设备编号为值存储到HDFS。
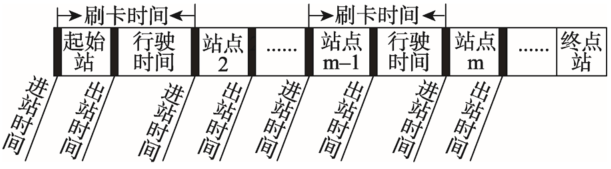
通常来讲,公交乘客是在公交车辆进站停稳后依次刷卡上车,车辆在乘客全部上车后启动离开公交站台,公交乘客的刷卡时间应位于公交车辆的进出站时间之内。但是实际的公交乘车情况比较复杂,尤其是上下班高峰期,出现多辆公交车排队进站时就上下客的情况,导致部分乘客的刷卡时间早于车辆进站时间。也可能由于车内拥挤,出现一些乘客先上车在车辆出站后刷卡的现象,导致一部分乘客的刷卡时间晚于车辆出站时间。为了提高推算公交乘客上车站点的准确率,为后续推算下车站点提供保障,本文采用基于相邻进站时间的时间匹配方法来推算公交乘客的上车站点。基本思想是:公交乘客的刷卡时间如果位于公交车辆相邻进站时间之内,计算乘客刷卡时间与出站时间差的绝对值和刷卡时间与后进站时间差的绝对值,比较这二者时间差,比较结果将对应着不同的上车站点,刷卡时间和车辆进出站时间关系如图1所示。
图1 乘客刷卡时间与车辆进出站时间关系示意图
Fig. 1 The relationship between boarding time and arrival-departure time
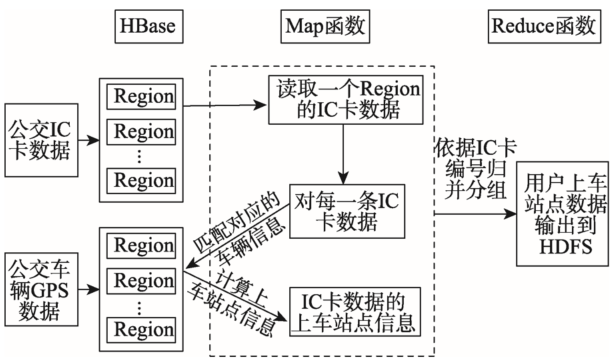
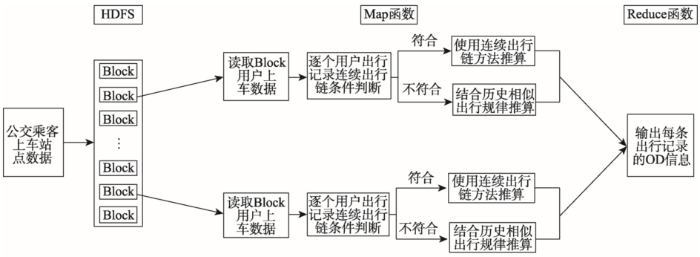
图2 上车站点并行推算流程
Fig. 2 The parrallel estimating flow of bus passengers boarding station
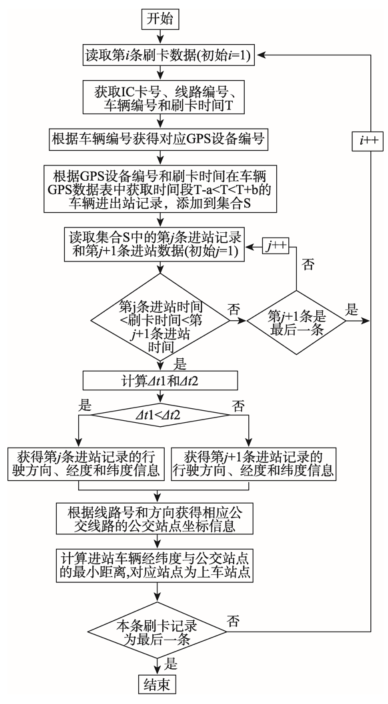
MapReduce模型的核心是Map函数和Reduce函数,Map函数主要是读入一组键值对数据,经过一系列变换处理,然后映射到一组新的键值对并输出;Reduce函数主要任务是归并,将Map函数输出的一系列具有相同键的键值对以某种方式组合起来,输出处理后的键值对数据。基于HBase数据库进行MapReduce并行计算时,一个map任务对应一个Region,根据IC卡数据的Region数量将IC卡数据划分成多个map任务并行计算上车站点。在Map函数中实现上车站点的推算,Reduce函数负责实现整理、归并Map函数的推算结果并输出到HDFS存储,公交乘客上车站点并行推算方法如图2所示。Map函数中推算上车站点的具体流程如图3所示,图中T为乘客该次乘车的刷卡时间,a和b为时间阈值,T-a<T<T+b表示刷卡时间前后一定的时间范围。S表示从车辆GPS数据表中获取同一辆车基于刷卡时间一定时间范围内的车辆进出站记录。Δt1表示刷卡时间与出站时间的时间差绝对值,Δt2表示刷卡时间与第二次进站时间的时间差绝对值。
图3 Map函数中推算上车站点流程
Fig. 3 The estimating flow in Map function of bus passengers boarding station
针对Map函数中输出的上车记录,在Reduce函数中以IC卡号为键,以该用户按时间排序的所有上车记录为值,归并输出到HDFS,作为后续下车站点推算的数据基础。
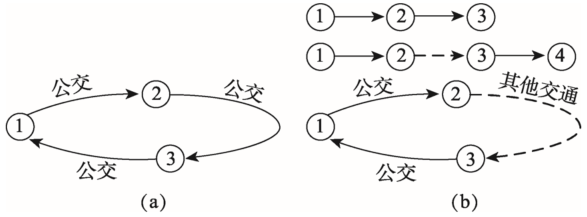
本文乘客下车站点推算方法只针对一票制的公交刷卡数据,未考虑其它交通(如BRT、地铁等)刷卡记录。在通常的公交出行中,普遍存在一种代刷卡的现象,即一张IC卡在同一辆公交车出现连续两次或者多次的刷卡记录(连续定义为同一张IC卡的相邻刷卡时间小于一定的时间阈值)。本文假设这些代刷记录都具有相同的出行目的地,即具有相同的下车站点。居民的公交出行行为根据出行链方法可以分为连续性公交出行链和非连续性公交出行链,如图4所示。图4(a)表示连续性公交出行链,有3个假设条件:① 连续两次公交出行之间不使用其他交通工具。② 下一次公交出行的起点是上一次公交出行的终点或者终点可接受步行换乘距离之内的站点。③ 一天中的最后一次出行终点为当天的第一次出行起点或者第二天首次出行的起点。而非连续性公交出行链如图4(b)所示,其中实线为公交出行,虚线为其他交通方式出行。从 图4可以看出,非连续性公交出行包含以下3种情形:① 用户乘坐公交连续出行,但是最后一次公交出行并未返回当天的起点;② 用户在换乘时使用其他交通方式,并且最后一次出行并未返回当天的起点;③ 用户在换乘时使用其他交通方式,但最后一次出行返回当天的起点。所有的非连续性公交出行均由这3种基本情形自由组合而成。
在获取乘客上车站点的基础上,本文基于连续性公交出行链方法和历史相似出行行为规律并行推算公交乘客下车站点。乘客的上车站点数据存储于HDFS,被分割成多个Block存储于不同节点上,基于HDFS的MapReduce并行计算时一个map任务对应一个Block数据。本文根据Block数量将乘客上车站点数据分成多个map任务并行计算下车站点,在Map函数中实现公交乘客下车站点的推算,而Reduce函数负责归并每个乘客完整的OD记录并存储到HDFS,具体推算过程如图5所示。
图5 公交乘客下车站点并行推算过程
Fig. 5 The parrallel estimating flow of bus passengers destination station
在Map函数中基于连续性出行链推算下车站点的流程如图6所示,主要有以下4步:
(1)读取一个IC卡用户的所有上车记录。如果该用户只有一条上车记录,则将该用户添加到Sa,(Sa是未能按照连续性出行链推算下车站点的上车记录集合)。如果该用户有多条上车记录,则读取第i条和第i+1条上车记录(初始i=1)。
图6 Map函数中基于连续性公交出行链下车站点推算流程
Fig. 6 The destination station inference flow for continuous public transit trip chain in Map function
(2)比较这2条上车记录的日期,如果在同一天,计算2次乘车的时间差的绝对值Δt并与时间阈值α比较,若Δt<α,则可认为是代刷情况,将第i条上车记录添加至Sa,否则计算两条记录的乘车线路编号,若乘车线路编号相等,则符合连续性公交出行链,将第i+1条上车记录的上车站点视为第i条上车记录的下车站点,将第i条OD记录添加到Sb(Sb是基于连续出行链方法推算出完整OD记录的集合);若不相等,则计算第i+1条记录的上车站点与第i条上车记录所有可能下车站点的距离,获得其最小距离dmin,如果dmin<β(β为距离阈值,代表换乘中可接受的最大步行距离),则符合连续性出行链(换乘),dmin所对应的公交站点为第i条上车记录的下车站点,将第i条OD记录添加到Sb,否则将第i条上车记录添加到Sa。
(3)若第i条上车记录和第i+1条上车记录不在同一天时间内,则第i条为前一天的最后一条乘车记录,而第i+1条为次日第一条乘车记录(上车记录已按刷卡时间排序)。根据第i条上车记录的线路编号、线路方向、站点编号信息获取该次乘车的可能下车站点。将这些可能的下车站点与当日第一次乘车的上车站点进行比较,如果2个公交站点相等或者相近(相等:站点名称一样,相近:2个站点距离<β),则该公交站点为第i条上车记录的下车站点,并将第i条OD记录添加到Sb。否则将这些可能的下车站点与次日第一条乘车记录(即第i+1条记录)的上车站点进行比较,如果2个站点相等或相近,则该站点为第i条上车记录的下车站点,并将第i条OD记录添加到集合Sb,都不符合条件,将第i条上车记录添加到集合Sa。
(4)输出集合Sa和集合Sb。
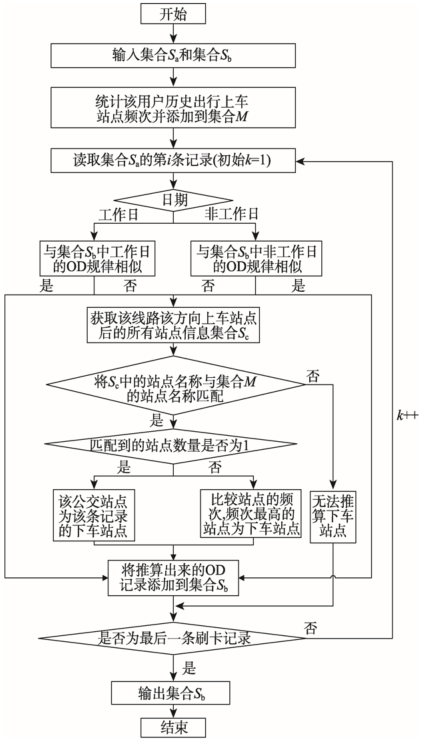
在上节中Sa是不符合连续性公交出行链推算下车站点的上车记录集合,针对这一部分用户上车记录,本文根据居民工作日和非工作日的出行特征,结合历史出行站点频次来推算下车站点。这部分的下车推算同样是在上节的Map函数中执行,具体推算流程如图7所示。从图7中可以看出对非连续性公交出行推算下车站点主要包含以下4步:
(1)输入上节的集合Sa和集合Sb,读取Sa的第k条记录(初始k=1),判断第k条记录的刷卡时间是否属于工作日。若是,则在集合Sb中寻找相似的工作日D点作为该条上车记录的D点,将OD记录添加到Sb;如果未找到相应的D点则将该条上车记录添加到集合Sc。
(2)若刷卡时间属于非工作日,则在集合Sb中寻找相似非工作日的D点作为该条上车记录的D点,将OD记录添加到Sb;如果未找到相应的D点 则将该条上车记录添加到集合Sc。
(3)统计该用户历史出行的上车站点频次,按频次排序并存入一个Map集合M。读取集合Sc的第j条上车记录(初始j=1),根据线路编号、行驶方向、站点编号获取该次乘车所有可能的下车站点,添加到集合Sd。将Sd的站点名称和集合M中的站点名称进行匹配,若匹配到的站点数为1,则该站点就是第j条上车记录的下车站点,将第j条OD记录添加到Sb;若匹配的站点数大于1,则比较匹配结果中每个站点的频次,频次最高的站点为第j条记录的下车站点,将第j条OD记录添加到Sb。
(4)若第j条上车记录未匹配到相应的D点,则该条记录无法推算到下车站点,若该条记录不是该用户最后一条上车记录,则读取下一条上车记录,否则就结束该用户的下车站点推算工作,输出集合Sb。
图7 Map函数中非连续性公交出行链下车站点推算流程
Fig. 7 The destination station inference flow for discontinuous public transit trip chain in Map function
本文以厦门市2015年6月13日至26日的公交数据为例进行研究,原始数据包括:3337辆公交车,39 306 315条车辆GPS记录,295条公交线路, 21 112 499条IC卡刷卡记录。经筛选和数据预处理,得到18 268 031条有效IC卡刷卡记录,IC卡刷卡数据和公交车辆GPS数据如表3、4所示。
表3 厦门市公交IC卡数据示例
Tab. 3 Sample of IC card data in Xiamen
| IC卡编号 | 刷卡时间 | 线路编号 | 公交车辆编号 |
|---|---|---|---|
| 5238111601 0878416539 | 2015-06-13 00:01:42 2015-06-12 18:18:52 | 000099 000129 | 8986 9318 |
本实验平台为Hadoop平台,该平台具有4个节点,每个节点为两核处理器,4 G内存和500 G磁盘空间,通过实现MapReduce并行推算厦门公交乘客OD点。按照调查及经验值,在上车站点的推算中,a取值3 min,b取值7 min,获取刷卡时间前3 min,后7 min的所有车辆进出站记录。推算出1 280 607个IC卡用户,16 879 661条上车记录,占IC卡刷卡记录的92.4%,有7.6%的IC卡记录因为进出站时间的丢失和异常未能成功推算出上车站点。按照图6和图7所示的下车站点并行推算流程进行下车站点推算,其中刷卡时间间隔阈值α取值1 min,是为了区分代刷情况,β取值500 m,是由站点间距及乘客换乘步行最大接受范围确定的。共推算出1 085 853个IC卡用户,14 410 058条完整OD记录,占上车记录的85.3%,IC卡刷卡记录的78.9%。其余的14.7%的上车记录未能推算出下车站点原因有以下几点:① 用户一天只有一次公交出行并且总体公交出行记录少。② 用户一天公交出行两次,但第二次是公交换乘,无法推算第二次公交出行的下车站点。 ③ 部分用户两周时间内只有一次公交刷卡记录。表5为某个乘客OD推算结果,从中可以看出本文所提出的方法能够较为准确的推算公交乘客的上下车站点。
表4 厦门市公交车辆GPS数据示例
Tab. 4 Sample of GPS bus data in Xiamen
| GPS设备编号 | GPS时间 | 纬度/° | 经度/° | 行驶方向 | 进出站标志 | 站点编号 | 线路编号 |
|---|---|---|---|---|---|---|---|
| 550001313902 | 2015-06-12 18:18:52 | 24.489145 | 118.072485 | 4 | 1 | 12 | 122 |
表5 OD推算结果
Tab. 5 The result of origin and destination inference
| IC卡编号 | 刷卡时间 | 线路编号 | 线路方向 | 上车站点 | 下车站点 | 推算依据 |
|---|---|---|---|---|---|---|
| 4078181794 | 2015-06-13 16:07:31 | 24 | 4 | 中医院 | 岳阳小区 | 历史站点频次 |
| 4078181794 | 2015-06-15 07:24:23 | 31 | 4 | 岳阳小区 | 江头市场 | 连续出行链 |
| 4078181794 | 2015-06-15 16:23:44 | 31 | 5 | 江头市场 | 岳阳小区 | 连续出行链 |
| 4078181794 | 2015-06-17 07:43:44 | 859 | 5 | 岳阳小区 | 莲花路口东 | 相似出行规律 |
| 4078181794 | 2015-06-17 07:43:46 | 859 | 5 | 岳阳小区 | 莲花路口东 | 连续出行链 |
| 4078181794 | 2015-06-17 15:39:32 | 42 | 4 | 莲花路口东 | 市行政中心 | 相似出行规律 |
| 4078181794 | 2015-06-17 15:39:33 | 42 | 4 | 莲花路口东 | 市行政中心 | 连续出行链 |
| 4078181794 | 2015-06-17 17:00:12 | 18 | 4 | 市行政中心 | 枋湖车站 | 相似出行规律 |
| 4078181794 | 2015-06-17 17:00:14 | 18 | 4 | 市行政中心 | 枋湖车站 | 连续出行链 |
| 4078181794 | 2015-06-17 17:11:25 | 45 | 5 | 枋湖车站 | 岳阳小区 | 相似出行规律 |
| 4078181794 | 2015-06-17 17:11:26 | 45 | 5 | 枋湖车站 | 岳阳小区 | 连续出行链 |
| 4078181794 | 2015-06-18 09:04:16 | 15 | 4 | 岳阳小区 | 叉车厂 | 连续出行链 |
| 4078181794 | 2015-06-18 09:25:52 | 86 | 4 | 禾山路 | 未推算出 | 无 |
为更好地体现本文所提方法能够快速准确提取海量公交乘客OD的优势,将本文推算公交OD的方法与传统推算公交OD方法分别从上车站点推算和下车站点推算2个方面进行对比分析。
目前基于单一公交数据源推算公交乘客上车站点均是通过IC卡数据和公交车辆GPS数据相匹配计算,与本文上车站点计算方法一致。基于这同一方法,本文从传统的基于关系型数据库(如Oracle)计算、基于HBase数据的非并行计算和基于HBase数据库的MapReduce并行计算3个方面进行计算效率的对比分析,其结果如图8所示。从图8中可以看出,在公交乘客上车站点计算效率方面,基于HBase的MapReduce并行计算要高于其余2种计算方法,并且数据量越大,并行计算的优势越明显。
图8 上车站点计算效率对比图
Fig. 8 The comparison of computation efficiency of calculating boarding station
在下车站点推算方面,目前常见的方法是连续出行链方法、站点吸引权重方法以及这两种方法的结合使用。站点吸引权重法是根据站点概率来推算乘客下车站点,可信度不高,因而本文将与传统的连续出行链方法进行对比分析。使用传统的连续性公交出行链方法推算本文公交数据的下车站点,得到完整的公交OD记录11 380 983条,占IC卡数据总量的62.3%,低于本文公交乘客下车站点的提取率78.9%。从而可以看出本文使用连续出行链结合乘客历史出行规律及其出行特征方法推算公交乘客下车站点的提取率要高于传统基于连续出行链的方法。
准确快速推算出海量公交乘客OD是及时获取全面真实城市公交客流信息的重要前提。面对海量的公交数据,本文提出一种基于MapReduce并行推算海量公交乘客OD的方法。该方法充分利用MapReduce并行计算的优势和乘客历史出行规律相似性的特点,准确快速地提取海量公交乘客OD信息,其优点在于:① 结合乘客历史出行记录的站点出现频次推算下车站点,与以往研究相比,具有更高的公交乘客OD提取率;② 面对海量的公交数据,可以快速计算出乘客OD信息,计算效率高,及时反映出全面真实的城市公交OD客流信息,对公交线路的优化和城市规划具有重要的实用价值。同时本文对公交数据的挖掘还有进一步待提高,如对于未能推算出OD点的数据,可以考虑结合其他数据源(地铁、出租)推算乘客出行OD点,获得更加完善的公交客流OD信息,对于此类数据还有待于进一步深入研究。
The authors have declared that no competing interests exist.
| [1] |
基于云计算的公交OD矩阵构建方法 [J].https://doi.org/10.3969/j.issn.1671-7775.2016.04.014 URL [本文引用: 1] 摘要
OD矩阵作为交通客流数据可视化的重要方法,是公交系统评价和优化的重要依据.提出了一种基于云计算的OD矩阵构建框架,在此框架下利用云计算优异的存取速度及计算性能,实现了对公交历史数据的筛选、预处理、变换、数据挖掘、解释评价等操作.此外,还提出一种综合了追踪乘客出行行为规律和估计站点热度的OD矩阵构建模型来实现对乘客下车站点较为精确的估计.算例分析表明,根据该模型计算得到的各站点下车人数结果能较好地拟合实际出行OD矩阵.
Estimation of bus origin-destination matrix based on cloud computing [J].https://doi.org/10.3969/j.issn.1671-7775.2016.04.014 URL [本文引用: 1] 摘要
OD矩阵作为交通客流数据可视化的重要方法,是公交系统评价和优化的重要依据.提出了一种基于云计算的OD矩阵构建框架,在此框架下利用云计算优异的存取速度及计算性能,实现了对公交历史数据的筛选、预处理、变换、数据挖掘、解释评价等操作.此外,还提出一种综合了追踪乘客出行行为规律和估计站点热度的OD矩阵构建模型来实现对乘客下车站点较为精确的估计.算例分析表明,根据该模型计算得到的各站点下车人数结果能较好地拟合实际出行OD矩阵.
|
| [2] |
基于IC卡数据的公交客流特征分析——以北京市为例 [J].https://doi.org/10.13813/j.cn11-5141/u.2016.0108 URL [本文引用: 1] 摘要
公交客流特征分析是公共汽(电)车线网规划和优化布局的基础。首先简要介绍基于公交IC卡数据分析公交客流特征的技术。进而以北京市为例,对公交客流的时空特征进行宏观、中观分析,对公交服务水平与城市发展的协调适配性做出评估,指出公共汽(电)车系统面临的挑战。最后,结合公交线网布局、运力配置不合理等问题,提出实现公共交通可持续发展的相关建议。
Characteristics of bus passenger flow based on IC card data: A case study in Beijing [J].https://doi.org/10.13813/j.cn11-5141/u.2016.0108 URL [本文引用: 1] 摘要
公交客流特征分析是公共汽(电)车线网规划和优化布局的基础。首先简要介绍基于公交IC卡数据分析公交客流特征的技术。进而以北京市为例,对公交客流的时空特征进行宏观、中观分析,对公交服务水平与城市发展的协调适配性做出评估,指出公共汽(电)车系统面临的挑战。最后,结合公交线网布局、运力配置不合理等问题,提出实现公共交通可持续发展的相关建议。
|
| [3] |
IC信息的公交数据分析方法研究[D] .Approach on the information analysis of urban public traffic base on the data of bus intelligent card[D] . |
| [4] |
一种新的公交乘客上车站点确定方法 [J].https://doi.org/10.3969/j.issn.1674-0696.2009.01.31 URL [本文引用: 1] 摘要
公交IC卡是一种新的客流信息采集手段,它的广泛使用为公交管理者进行客流分析提供了新的数据源。充分利用公交IC卡刷卡时间信息,根据相邻两站点间的最短刷卡间隔,通过系统聚类法对IC卡刷卡数据按照时间顺序进行聚类分析。在此基础上,将聚类分析的结果与公交运营资料所推算出的车辆到站时间进行时间匹配,确定持卡乘客的上车站点。最后,通过实例验证了该方法的可行性与实用性。
A novel method of confirming the boarding station of bus holders [J].https://doi.org/10.3969/j.issn.1674-0696.2009.01.31 URL [本文引用: 1] 摘要
公交IC卡是一种新的客流信息采集手段,它的广泛使用为公交管理者进行客流分析提供了新的数据源。充分利用公交IC卡刷卡时间信息,根据相邻两站点间的最短刷卡间隔,通过系统聚类法对IC卡刷卡数据按照时间顺序进行聚类分析。在此基础上,将聚类分析的结果与公交运营资料所推算出的车辆到站时间进行时间匹配,确定持卡乘客的上车站点。最后,通过实例验证了该方法的可行性与实用性。
|
| [5] |
基于聚类分析方法的公交站点客流匹配方法研究 [J].https://doi.org/10.3963/j.ISSN1674-4861.2010.03.005 URL [本文引用: 1] 摘要
对公交IC卡数据收集、处理和分析得到的结果可以为公交客流分析 提供重要依据.文中针对一票制IC卡数据信息不完善的缺陷,结合公交其他运营信息,利用聚类分析方法,研究基于公交IC卡数据的匹配技术,并给出应用于匹 配技术的实例计算结果.结果表明,提出的方法有很强的实用性,为得到准确、实时且连续的公交客流信息提供良好的平台.
Bus station passenger matching method based on cluster analysis method [J].https://doi.org/10.3963/j.ISSN1674-4861.2010.03.005 URL [本文引用: 1] 摘要
对公交IC卡数据收集、处理和分析得到的结果可以为公交客流分析 提供重要依据.文中针对一票制IC卡数据信息不完善的缺陷,结合公交其他运营信息,利用聚类分析方法,研究基于公交IC卡数据的匹配技术,并给出应用于匹 配技术的实例计算结果.结果表明,提出的方法有很强的实用性,为得到准确、实时且连续的公交客流信息提供良好的平台.
|
| [6] |
基于公交IC卡刷卡记录的居民出行OD推算方法研究 [J].Origin-destination matrix estimation method based on bus smart card records [J]. |
| [7] |
基于公交IC卡数据的公交站点OD矩阵推导方法 [J].A method of deriving bus stops O-D matrix based on bus IC card data [J]. |
| [8] |
基于IC卡综合换乘信息的公交乘客上车站点推算 [J].https://doi.org/10.3724/SP.J.1047.2016.01060 URL Magsci [本文引用: 1] 摘要
现有研究在缺少公交车运营信息的情况下,利用公交线间正交换乘信息的方法来识别公交车持卡乘客的上车站点,但在实际运用中很多班次无正交换乘的乘客,容易导致公交乘客上车站点匹配困难。因此,本文提出了一种基于IC卡综合换乘信息的公交乘客上车站点推算方法,该方法充分利用IC卡数据中的综合换乘信息(公交线间的正交和非正交换乘信息、地铁和公交线间的换乘信息)与公交网数据确定班次行驶方向,对班次内的乘客进行分组,充分利用综合换乘信息确定基准组及其对应的上车站点;然后,通过最小偏差规则匹配待定组的上车站点,实现公交乘客上车站点的推估。利用换乘信息确定班次行驶方向弥补了现有研究无法确定班次行驶方向的不足,使公交乘客上车站点推算方法更科学;最后,基于2011年8月的“深圳通”IC卡数据进行实例分析,对比只利用正交换乘信息确定的基准组数量和利用综合换乘信息确定的基准组数量,结果表明:该方法可使确定上车站点的组数占总组数的比值提高,克服了只利用正交换乘信息推算上车站点方法中存在的单个班次无基准组从而无法进行站点匹配的困难。本文方法比只利用正交换乘信息匹配站点,具有更高的可行性与准确率。
A method of deriving the boarding station information of bus passengers based on comprehensive transfer information mined from IC card data [J].https://doi.org/10.3724/SP.J.1047.2016.01060 URL Magsci [本文引用: 1] 摘要
现有研究在缺少公交车运营信息的情况下,利用公交线间正交换乘信息的方法来识别公交车持卡乘客的上车站点,但在实际运用中很多班次无正交换乘的乘客,容易导致公交乘客上车站点匹配困难。因此,本文提出了一种基于IC卡综合换乘信息的公交乘客上车站点推算方法,该方法充分利用IC卡数据中的综合换乘信息(公交线间的正交和非正交换乘信息、地铁和公交线间的换乘信息)与公交网数据确定班次行驶方向,对班次内的乘客进行分组,充分利用综合换乘信息确定基准组及其对应的上车站点;然后,通过最小偏差规则匹配待定组的上车站点,实现公交乘客上车站点的推估。利用换乘信息确定班次行驶方向弥补了现有研究无法确定班次行驶方向的不足,使公交乘客上车站点推算方法更科学;最后,基于2011年8月的“深圳通”IC卡数据进行实例分析,对比只利用正交换乘信息确定的基准组数量和利用综合换乘信息确定的基准组数量,结果表明:该方法可使确定上车站点的组数占总组数的比值提高,克服了只利用正交换乘信息推算上车站点方法中存在的单个班次无基准组从而无法进行站点匹配的困难。本文方法比只利用正交换乘信息匹配站点,具有更高的可行性与准确率。
|
| [9] |
基于IC卡的北京市公交出行特征分析[D] .Analysis of bus trip characteristics in Beijing based on IC card[D] . |
| [10] |
Statistical inference for time varying origin-destination matrices [J].https://doi.org/10.1016/j.trb.2007.11.003 URL [本文引用: 1] 摘要
We consider the problem of estimating a sequence of origin–destination matrices from link count data collected on a daily basis. We recommend a parsimonious parameterization for the time varying matrices so as to permit application of standard statistical estimation theory. A number of examples of suitably parameterized matrices are provided. We propose a multivariate normal model for the link counts, based on an underlying overdispersed Poisson process. While likelihood based inference is feasible given information from sufficiently many network links, we focus on Bayesian methods of estimation because of their ability to incorporate prior information in a natural manner. We derive the Bayesian posterior distribution, but note that its normalizing constant is not available in closed form. A Markov chain Monte Carlo algorithm for generating posterior samples is therefore developed. From this we can obtain point estimates, and corresponding measures of precision, for parameters of the origin–destination matrix. The methodology is illustrated by an example involving OD matrix estimation for a section of the road network in the English city of Leicester.
|
| [11] |
Use of smart card fare data to estimate public transport origin-destination matrix [J].https://doi.org/10.3141/2535-10 URL [本文引用: 1] 摘要
Over the past few years, several techniques have been developed for using smart card fare data to estimate origin-揹estination (O-D) matrices for public transport. In the past, different walking distance and allowable transfer time assumptions had been applied because of a lack of information about the alighting stop for a trip. Such assumptions can significantly affect the accuracy of the estimated O-D matrices. Little evidence demonstrates the accuracy of O-D pairs estimated with smart card fare data. Unique smart card fare data from Brisbane, Queensland, Australia, offered an opportunity to assess previous methods and their assumptions. South East Queensland data were used to study the effects of different assumptions on estimated O-D matrices and to conduct a sensitivity analysis for different parameters. In addition, an algorithm was proposed for generating an O-D matrix from individual user transactions (trip legs). About 85% of the transfer time was nonwalking time (wait and short activity time). More than 90% of passengers walked less than 10 min to transfer between alighting and the next boarding stop; this time represented about 10% of the allowable transfer time. A change in the assumed allowable transfer time from 15 to 90 min had a minor effect on the estimated O-D matrices. Most passengers returned to within 800 m of their first origin on the same day.
|
| [12] |
Estimation of a disaggregate multimodal public transport Origin-Destination matrix from passive smart card data from Santiago, Chile [J].https://doi.org/10.1016/j.trc.2012.01.007 URL [本文引用: 1] 摘要
A high-quality Origin-揇estination (OD) matrix is a fundamental prerequisite for any serious transport system analysis. However, it is not always easy to obtain it because OD surveys are expensive and difficult to implement. This is particularly relevant in large cities with congested networks, where detailed zonification and time disaggregation require large sample sizes and complicated survey methods. Therefore, the incorporation of information technology in some public transport systems around the world is an excellent opportunity for passive data collection. In this paper, we present a methodology for estimating a public transport OD matrix from smartcard and GPS data for Santiago, Chile. The proposed method is applied to two 1-week datasets obtained for different time periods. From the data available, we obtain detailed information about the time and position of boarding public transportation and generate an estimation of time and position of alighting for over 80% of the boarding transactions. The results are available at any desired time-搒pace disaggregation. After some post-processing and after incorporating expansion factors to account for unobserved trips, we build public transport OD matrices.
|
| [13] |
Evaluation of effects from sample-size origin-destination estimation using smart card fare data [J].https://doi.org/10.1061/JTEPBS.0000016 URL [本文引用: 1] 摘要
Public transport planners are required to make decisions on transport infrastructure and services worth billions of dollars. The decision-making process for transport planning needs to be informed, accountable, and founded on comprehensive, current, and reliable data. One of the major issues affecting the accuracy of the estimated origin-destination (O-D) matrices is sample size. Cost, time, precision, and biases are some issues associated with sample size. Smart card data can potentially provide much information based on better understanding and assessment of the sample size impact on the estimated O-D matrices. This paper uses South East Queensland (SEQ) data to study the effect of different data sample sizes on the accuracy level of the generated public transport O-D matrices and to quantify the sample size required for a certain level of accuracy. As a result, the total number of O-D trips for the whole network can be accurately estimated at all levels of sample sizes. However, a wide distribution of O-D trips appeared at different sample sizes. The large difference from the actual distribution at 100% sample size was readily captured at small sample sizes where more O-D pairs were not representative. The wide distribution of O-D trips at different levels of sample sizes caused significant errors even at large sample sizes. The variation of the errors within the same sample was also captured as a result of the 80 iterations for each sample size. It is concluded that three major parameters (distribution, number, and sample size of selected stations) have a significant impact on the estimated O-D matrices. These results can be also reflected on the sample size of the traditional O-D estimation methods, such household travel surveys.
|
| [14] |
基于公交IC卡数据的上车站点推算研究 [J].
为了分析城市公交乘客的出行特征,本文利用公交IC卡及GPS数据对公交IC卡乘客上车站点推算进行研究.针对安装车载GPS设备的车辆,运用GPS数据与IC卡数据融合算法进行推算;对于无车载GPS设备的情况,为适应一票制IC卡数据挖掘,对贝叶斯决策树算法进行改进,允许节点跳跃,推算上车站点,并且利用Markov链特性降低算法的运算复杂度.同时,本文以北京公交数据为例,对提出的两种方法进行验证.结果表明,利用本文提出的方法推算上车站点,3站之内误差的准确率达到90%以上,算法在兼顾算法精度的同时合理地控制了运算复杂度,可以实际运用于城市公交系统.
Boarding stop inference based on transit IC card data [J].
为了分析城市公交乘客的出行特征,本文利用公交IC卡及GPS数据对公交IC卡乘客上车站点推算进行研究.针对安装车载GPS设备的车辆,运用GPS数据与IC卡数据融合算法进行推算;对于无车载GPS设备的情况,为适应一票制IC卡数据挖掘,对贝叶斯决策树算法进行改进,允许节点跳跃,推算上车站点,并且利用Markov链特性降低算法的运算复杂度.同时,本文以北京公交数据为例,对提出的两种方法进行验证.结果表明,利用本文提出的方法推算上车站点,3站之内误差的准确率达到90%以上,算法在兼顾算法精度的同时合理地控制了运算复杂度,可以实际运用于城市公交系统.
|
| [15] |
基于公交IC卡和GPS数据的居民公交出行OD矩阵推导与应用[D] .Urban public transportation trip OD matrix inference and application based on bus IC card data and GPS data[D] . |
| [16] |
基于IC卡数据挖掘获取公交OD矩阵的方法 [J].A way to get bus regional OD matrix based on mining IC card information [J]. |
| [17] |
基于公交IC卡和AVL数据的客流OD推导方法 [J].https://doi.org/10.3963/j.issn 1674-4861.2015.06.005 URL [本文引用: 1] 摘要
公交IC卡收费系统和车辆定位系统的广泛应用,为获取公交客流OD提供了新的途径。针对现有公交客流OD推导算法的不足,从上车站点识别和下车站点推导两方面入手,对公交客流OD推导算法进行了改进。为了修正公交IC卡数据时间偏差,提高上车站点识别的准确性,在分析公交乘客上车刷卡行为的基础上,提出了基于AVL数据的公交IC卡数据时间修正方法。根据公交出行链的特性差异,将公交出行链划分为连续链和非连续链两大类,在此基础上,建立了不同公交出行链的下车站点推导模型,优化了下车站点推导流程。以苏州市的公交IC卡和AVL数据为例进行实例研究,通过对推导结果合理性的讨论分析,论证了改进算法的可行性和有效性。实践表明,改进后的公交客流OD推导算法流程清晰,易于程序实现,可以用于公交客流的自动分析。
A method for estimating origin-destination matrix of public transit based on smart card and AVL data [J].https://doi.org/10.3963/j.issn 1674-4861.2015.06.005 URL [本文引用: 1] 摘要
公交IC卡收费系统和车辆定位系统的广泛应用,为获取公交客流OD提供了新的途径。针对现有公交客流OD推导算法的不足,从上车站点识别和下车站点推导两方面入手,对公交客流OD推导算法进行了改进。为了修正公交IC卡数据时间偏差,提高上车站点识别的准确性,在分析公交乘客上车刷卡行为的基础上,提出了基于AVL数据的公交IC卡数据时间修正方法。根据公交出行链的特性差异,将公交出行链划分为连续链和非连续链两大类,在此基础上,建立了不同公交出行链的下车站点推导模型,优化了下车站点推导流程。以苏州市的公交IC卡和AVL数据为例进行实例研究,通过对推导结果合理性的讨论分析,论证了改进算法的可行性和有效性。实践表明,改进后的公交客流OD推导算法流程清晰,易于程序实现,可以用于公交客流的自动分析。
|
| [18] |
Validating travel behavior estimated from smartcard data [J].https://doi.org/10.1016/j.trc.2014.03.008 URL [本文引用: 1] 摘要
In this paper, we present a validation of public transport origin–destination (OD) matrices obtained from smartcard and GPS data. These matrices are very valuable for management and planning but have not been validated until now. In this work, we verify the assumptions and results of the method using three sources of information: the same database used to make the estimations, a Metro OD survey in which the card numbers are registered for a group of users, and a sample of volunteers. The results are very positive, as the percentages of correct estimation are approximately 90% in all cases.
|
| [19] |
Cunha J F E. Passenger journey destination estimation from automated fare collection system data using spatial validation [J].https://doi.org/10.1109/TITS.2015.2464335 URL [本文引用: 1] 摘要
A methodology for estimating the destination of passenger journeys from automated fare collection (AFC) system data is described. It proposes new spatial validation features to increase the accuracy of destination inference results and to verify key assumptions present in previous origin-destination estimation literature. The methodology applies to entry-only system configurations combined with distance-based fare structures, and it aims to enhance raw AFC system data with the destination of individual journeys. This paper describes an algorithm developed to implement the methodology and the results from its application to bus service data from Porto. The data relate to an AFC system integrated with an automatic vehicle location system that records a transaction for each passenger boarding a bus, containing attributes regarding the route, the vehicle, and the travel card used, along with the time and the location where the journey began. Some of these are recorded for the purpose of allowing onboard ticket inspection but additionally enable innovative spatial validation features introduced by the methodology. The results led to the conclusion that the methodology is effective for estimating journey destinations at the disaggregate level and identifies false positives reliably.
|
| [20] |
基于GPS和IC卡数据的公交出行OD推算方法 [J].https://doi.org/10.3969/j.issn.1674-0696.2015.03.24 URL [本文引用: 1] 摘要
主要基于GPS和公交IC卡数据研究推算交通小区公交出行OD的一种方法.将居民公交出行分为闭合型出行链和非连续型公交出行链,通过数据的挖掘融合技术,结合居民公交出行规律推算交通小区的公交OD矩阵,利用站点吸引强度对无明显规律的紊乱出行数据进行修正,提出了基于GPS和公交IC卡数据推算公交出行交通小区OD的方法,并以佛山市中心城区为例验证推算方法的可靠性.研究表明:所得公交出行OD矩阵精度较高.
OD matrix inference for urban public transportation trip based on GPS and IC card data [J].https://doi.org/10.3969/j.issn.1674-0696.2015.03.24 URL [本文引用: 1] 摘要
主要基于GPS和公交IC卡数据研究推算交通小区公交出行OD的一种方法.将居民公交出行分为闭合型出行链和非连续型公交出行链,通过数据的挖掘融合技术,结合居民公交出行规律推算交通小区的公交OD矩阵,利用站点吸引强度对无明显规律的紊乱出行数据进行修正,提出了基于GPS和公交IC卡数据推算公交出行交通小区OD的方法,并以佛山市中心城区为例验证推算方法的可靠性.研究表明:所得公交出行OD矩阵精度较高.
|
| [21] |
基于公交IC卡数据的大规模OD矩阵推导算法研究 [J].https://doi.org/10.3969/j.issn.1001-3695.2016.07.019 URL [本文引用: 1] 摘要
为实现基于公交IC卡数据的大规模OD(origination-destination)矩阵推导,提出了一种不关联公交调度信息和GPS数据的OD矩阵推导算法。提出了站点序号标注算法,通过时间聚类思想设计了自适应调整的时间间隔阈值以判断公交车的行驶状态,将公交站点序列与刷卡记录进行匹配;在此基础上,提出了单个公交车的行驶方向标注算法,通过从已知行驶方向的公交车推导未知方向公交车的方向标注算法。为了最大化解决公交数据的上车站点信息补全问题,将全局公交车行驶方向标注问题映射为图论中的节点遍历问题,利用贪心生长算法和广度优先策略实现了局部最优。最后该算法处理某市的公交IC卡数据,得到了公交出行链假设下的城市居民大规模OD矩阵。结果显示算法可有效推导大规模OD矩阵。
Research on large-scale OD matrix estimation method based on bus IC card data [J].https://doi.org/10.3969/j.issn.1001-3695.2016.07.019 URL [本文引用: 1] 摘要
为实现基于公交IC卡数据的大规模OD(origination-destination)矩阵推导,提出了一种不关联公交调度信息和GPS数据的OD矩阵推导算法。提出了站点序号标注算法,通过时间聚类思想设计了自适应调整的时间间隔阈值以判断公交车的行驶状态,将公交站点序列与刷卡记录进行匹配;在此基础上,提出了单个公交车的行驶方向标注算法,通过从已知行驶方向的公交车推导未知方向公交车的方向标注算法。为了最大化解决公交数据的上车站点信息补全问题,将全局公交车行驶方向标注问题映射为图论中的节点遍历问题,利用贪心生长算法和广度优先策略实现了局部最优。最后该算法处理某市的公交IC卡数据,得到了公交出行链假设下的城市居民大规模OD矩阵。结果显示算法可有效推导大规模OD矩阵。
|
| [22] |
结合出行链的公交 IC 卡乘客下车站点判断概率模型 [J].Trip-chain based probability model for identifying alighting stations of smart card passengers [J]. |
| [23] |
基于交通大数据的公交线路OD矩阵推断方法 [J].
随着交通大数据的普及与广泛应用,提出了一种推断多模式交通网络线路OD矩阵的方法。首先,通过匹配乘客的刷卡数据和公交车辆报站数据获得乘客的上车站点,其次结合地铁刷卡数据准确分析乘客的下车站点,最后根据乘客的出行信息获得线路OD矩阵。利用广州一天近800万刷卡数据和600万公交报站数据进行了上车站点、下车站点以及OD矩阵的推断,结果表明:早高峰与全日出行规律一致;广州交通方式呈现多样化等。提出的方法可以更为准确地获得线路OD矩阵,揭示城市交通特点,具有较高的实用价值。
An inference method of public transit OD matrix based on traffic big data [J].
随着交通大数据的普及与广泛应用,提出了一种推断多模式交通网络线路OD矩阵的方法。首先,通过匹配乘客的刷卡数据和公交车辆报站数据获得乘客的上车站点,其次结合地铁刷卡数据准确分析乘客的下车站点,最后根据乘客的出行信息获得线路OD矩阵。利用广州一天近800万刷卡数据和600万公交报站数据进行了上车站点、下车站点以及OD矩阵的推断,结果表明:早高峰与全日出行规律一致;广州交通方式呈现多样化等。提出的方法可以更为准确地获得线路OD矩阵,揭示城市交通特点,具有较高的实用价值。
|
| [24] |
Spatio-temporal analysis of passenger travel patterns in massive smart card data [J].https://doi.org/10.1109/TITS.2017.2679179 URL [本文引用: 1] 摘要
Metro systems have become one of the most important public transit services in cities. It is important to understand individual metro passengers' spatio-temporal travel patterns. More specifically, for a specific passenger: what are the temporal patterns? what are the spatial patterns? is there any relationship between the temporal and spatial patterns? are the passenger's travel patterns normal or special? Answering all these questions can help to improve metro services, such as evacuation policy making and marketing. Given a set of massive smart card data over a long period, how to effectively and systematically identify and understand the travel patterns of individual passengers in terms of space and time is a very challenging task. This paper proposes an effective data-mining procedure to better understand the travel patterns of individual metro passengers in Shenzhen, a modern and big city in China. First, we investigate the travel patterns in individual level and devise the method to retrieve them based on raw smart card transaction data, then use statistical-based and unsupervised clustering-based methods, to understand the hidden regularities and anomalies of the travel patterns. From a statistical-based point of view, we look into the passenger travel distribution patterns and find out the abnormal passengers based on the empirical knowledge. From unsupervised clustering point of view, we classify passengers in terms of the similarity of their travel patterns. To interpret the group behaviors, we also employ the bus transaction data. Moreover, the abnormal passengers are detected based on the clustering results. At last, we provide case studies and findings to demonstrate the effectiveness of the proposed scheme.
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}