杨明远 , 刘海砚
, 刘海砚
YANG Mingyuan, LIU Haiyan
通讯作者:
收稿日期: 2017-08-31
修回日期: 2018-02-28
网络出版日期: 2018-05-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:杨明远(1992-),男,硕士生,地图制图学与地理信息系统专业,主要研究方向为数字地图制图。E-mail: 18695800631@163.com
展开
摘要
针对Argo海洋浮标数据的准实时性、海量性、时空异变性等特点和多种查询应用需求,分析了当前时空索引方法的优势与不足,提出了一种多频率STR-tree索引与格网索引的混合索引结构MFSTR-tree。该方法在首先轨迹束层利用动态轨迹束作为叶节点生成STR-tree结构,将STR-tree索引结构灵活、数据冗余少的优势进一步扩大;接着通过轨迹束的多种频率在采样点层构建格网索引,实现在查询效率上的提升;同时给出了该结构插入算法和查询算法的具体描述。本文以中国Argo实时资料中心提供的2015年海洋浮标数据为例,将该方法与HR-tree和STR-tree方法进行了构建效率和查询效率的对比实验,结果表明该方法在保证了构建存储效率和时间效率的同时,有效改善了原有STR-tree应用于Argo数据中的查询效率问题。
关键词:
Abstract
Management mode of relational database and file type database is difficult to support the data of Argo floats data. Because Argo buoy floats freely with sea current and data volume is huge in scale as the mobile object. In view of the quasi-real-time, massive nature, spatio-temporal variation and other characteristics of Argo ocean buoy data, as well as multiple query application requirements, the advantages and disadvantages of the current space-time indexing method are analyzed. The deficiencies of current spatio-temporal indexing method include: (1) The Argo buoy data has large volume and are observed over a long time span. When a STR-tree index is established on the trajectory of a buoy, the over-long trajectory tends to lead to a high overlap ratio between the MBB of the STR-tree, which further leads to the reduction of search efficiency. (2) The Argo floats data are sampled at different frequencies and with relatively stable frequency, but the influence of the update frequency on index structure optimization is often ignored. Therefore, a hybrid index structure called MFSTR-tree with multi-frequency STR-tree index and grid index is proposed. First, the dynamic trajectory beam is used as the leaf node to generate the STR-tree structure in the trajectory beam layer, taking advantage of the flexibility and the less data redundancy of the STR-tree index structure. Then, the improvement of query efficiency is realized by use of the multiple frequencies of the track beam at the sampling point layer according to the construction grid index. The corresponding interpolation algorithm and query algorithm are described in this paper. To verify the construction and query efficiency of MFSTR-tree, a comparison experiment was conducted with HR-tree and STR-tree for Argo floats in 2015 from China Argo real-time data center. The experimental results show that under the premise of guaranteeing construction time efficiency and storage efficiency, HR-tree still maintains natural advantages in single-time query and is much more efficient than the other two. After optimization, the MFSTR-tree had efficiency of 40% higher than the general STR-tree. The query efficiency of the HR-tree decreases significantly with the query window size expanded to 4% of the total range. MFSTR-tree is further optimized on the basis of the original STR-tree, which improves the efficiency of the sampling point selection process in the trajectory bundle. Therefore, the advantage is more obvious, and the verification of the algorithm is realized.
Keywords:
Argo海洋浮标作为移动对象随海流自由漂浮,位置频繁更新且规模空前。目前,国内外建立的资料中心主要以关系型数据库[1,2]和文件型数据库对Argo浮标数据文件进行管理[3,4],如法国海洋开发研究院、美国全球海洋数据同化实验数据中心以及我国的Argo实时资料中心。但随着浮标时空数据的爆发式增长,这种管理方式效率低下的弊端逐渐暴露出来,传统的数据库索引方式无法满足查询效率上的需求[5]。同时,由于投放批次不同,导致获取信息的频率不一致(取决于传感器类型)和获取时刻不同步(取决于投放时间)[6,7],Argo浮标数据总体上呈现间隔更新(准实时性)、全球海域持续观测(海量性)、时空异变(时空随机性)等不同于一般时空数据的特征,致使现有的时空索引结构也难以适应实际应用。因此,必须针对数据建立专门的时空数据索引,以提高海洋环境重构与分析过程中所需的检索效率并解决数据实时更新的代价问题。
为了满足对时空数据的时空查询的需求,实现有效存取和快速分析,在空间索引和时间索引基础上提出了时空索引[8,9]。目前已有的时空索引技术研究主要是基于空间索引实施改进。
近年来,随着应用的综合性要求日益突出,全时段的移动对象数据模型及其时空索引方法被深入研究[10,11],国内学者利用上述基础时空索引方法针对不同应用的改进方法也层出不穷。基于R*-tree将空间与时间统一构造的VC-tree(Virtual Column-tree)[12],将空间物体用生成时刻的最小外包围矩形表示,同时树的节点中保存生成时间的值和矩形框扩展的速度,随着时间的增长,存活的物体在时间维上增长,满足了时间片和时间段的查询效率要求。该方法假设对象移动的速度和方向保持不变,而在实际情况中难以达到条件。丁治明[13]针对移动对象更新频率快,索引更新代价高的问题,提出了DSTR-Tree(Dynamic Sketched Trajectory R-tree)索引方法,将索引空间划分成等距栅格,通过栅格单元对每一条时空轨迹进行概略化,并以概略化轨迹单元为基本索引记录单位建立R树索引。通过对移动对象轨迹的粗化,判断轨迹变化是否跨越栅格来决定对索引的更新。该方法在时间维上处理不足,时空范围查询的效率不佳。陈静等[14]对HR-tree(Historical R-tree)[15]进行扩展,将存储对象的响应时间段的状态存储到一个时间片内形成时间块,在一定程度上解决了HR-tree结构时间切片过多的问题,但索引消耗空间过大且维护成本高。彭召军等[16]面向频繁更新的位置数据,提出了一种基于延迟更新和备忘录更新/插入相结合的移动对象索引结构LUMR*-tree(Lazy Update Memo R*-tree),在不改变索引结构的前提下快速完成更新操作,获得较好的更新性能的同时也牺牲了部分查询性能。龚俊等[17]兼顾了时空索引的存储效率、查询效率和查询类型,提出了HBSTR-tree(Hash & B combined Spatio-Temporal R-tree)索引结构,以STR-tree(Spatio-Temporal R-tree)[18,19]作为主体结构实现时空范围查询功能,结合Hash表和B*-tree分别用于维护索引结构和目标对象的轨迹查询的优化。该方法充分利用了以上3种结构的优势,在索引创建效率和多种方式查询效率之间找到了较好的平衡点。
索引设计既要了解数据特点,还要考虑创建 效率、存储利用率、查询效率、查询种类等需求的影响[20]。从现有的研究成果来看,应用于海洋浮标数据的管理或多或少存在缺陷,主要体现在以下2个方面:① Argo浮标数据海量且观测时间跨度较长,采用时空格网类型索引冗余过大;而针对同一浮标的轨迹建立STR-tree索引,过长的轨迹容易造成STR-tree的外包矩形之间重叠率过高,进一步导致搜索效率的降低。② Argo浮标采用准实时观测的方式以不同的频率进行采样且频率相对稳定,观测数据时间粒度相比较一般的轨迹数据较大,更新频率一般以天为单位,现有的方法忽视了更新频率对索引结构优化带来的影响。基于上述情况,本文提出了一种多频率STR-tree索引与格网索引的混合索引方法,简称MFSTR-tree(Multi-Frequency Spatio-Temporal R-tree)。
MFSTR-tree采用轨迹束层索引和采样点层索引上下2个层级嵌套组合,结构如图1所示。
同一个移动对象的连续采样点本身具有邻接关系,为了尽可能的保存轨迹信息,第一层级以轨迹束(Trajectory Bundle)作为存储单元构建STR-tree索引结构。采用最小外包矩形MBB(Minimal Bounding Box) 进行时空迭代划分。本文首先借鉴影像分层的思想,在时间维上根据移动对象的更新频率对时空数据实施抽析,形成不同时间分辨率的采样点数据层。根据高低频率设置不同参数p形成动态轨迹束,p为轨迹束储存的采样点数量,将动态轨迹束作为单独的叶子节点插入到STR-tree中的对应最小外包矩形中。目的是保持STR-tree索引算法结构灵活、数据冗余少等优点的同时,使轨迹束的形态更加均匀,避免轨迹过长导致的MBB 重叠过多或轨迹过短导致的MBB数量过多,从而 引起的索引效率降低。通常浮标在采样过程受 天气或其他外因影响会发生频率跳变形成粗差,对于这种情况一般采用在跳变位置切割为2条轨迹来处理。
MFSTR-tree索引继承了STR-tree索引的优势,在采样点层下进一步优化,利用时间维的连续性和同一浮标采样更新频率基本稳定的特点,对每一条轨迹束内的采样点层根据时间维建立二次格网索引。目的是通过对时间维约束,减少对符合查询条件的轨迹束内的采样点的判断次数。利用轨迹束节点中的频率信息和起始时刻通过计算快速定位符合查询条件的采样点,过滤掉大部分不满足时间约束条件的点,避免了对符合条件的轨迹束内全部采样点的遍历,减少了候选采样点判断的时间。
本节将对MFSTR-tree的主要的插入和查询算法进行介绍。对涉及的参数作以下几点说明:轨迹束层的非叶节点为TNode={MBB, father, child},叶节点LeafNode={MBB, father, startTime, freq, data },其中,MBB为该轨迹的最小包围盒,child是包含的孩子节点,father是包含该节点的父节点。待插入的轨迹采样点Point={oid, cycle, time, loc, freq},其中oid为浮标标识符;cycle是采样航次;time是采样时间;loc是采样坐标;freq是该浮标的采样频率;轨迹束Path={oid, Point1, Point2,…, Pointn}。
算法描述:MFSTR-tree索引的插入算法
算法输入:浮标采样点数据集Points,每个叶节点LeafNode的轨迹采样点系数β,用于确定不同频率的轨迹束采样点数量阈值p。
算法输出:更新后的MRSTR-tree索引结构。
算法流程:
(1)频率分层。将数据集Points按采样频率Point.freq进行横向分层,若不存在该频率分组则为其创建新分层,转入步骤(2)。
(2)分组排序。将每个频率分层内的采样点依据浮标标识符Point.oid进行分组,并依据采样点的时间Point.time顺序进行排序,形成以浮标为单元的完整轨迹序列Path。
(3)未满轨迹束插补。搜索每个轨迹序列Path前序采样点所在的叶节点LeafNode,利用oid和第一个采样点Point1的采样时刻进行判断。判断该叶节点上的已有的采样点个数n是否达到该子树叶节点的采样点阈值p,如果n<p,说明该叶节点未满,则将Path中的前p-n个采样点直接补充到LeafNode,同时更新Path,将已插入的采样点删除,转入步骤(4);否则,说明该浮标的前序采样点所在叶节点已满,无需插补,直接转入步骤(4)。
(4)剩余轨迹序列切割。对剩余轨迹序列Path根据时间范围TRange进行切割,形成若干段轨迹子序列Path[i]作为待插入的新轨迹束(其中TRange由采样点阈值和采样频率共同决定),切割后的子序列数量为:
式中:
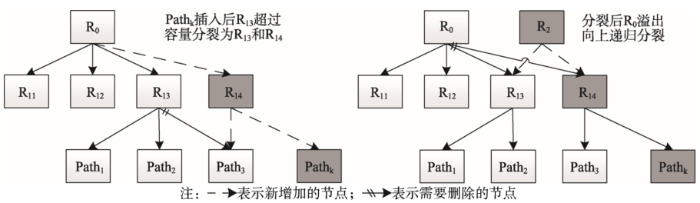
(5)新轨迹束插入。对步骤(4)中的待插入轨迹束依次采用ChooseLeaf子算法来选择STR-tree中合适位置的叶节点LeafNode插入轨迹束path[i],如果非叶节点TNode内保存的叶节点超过了参数p,则TNode分裂为2个节点TNode1和TNode2,这两个节点包含了原来TNode内中所有的轨迹和新插入的Path[i]。如果叶节点分裂后其父节点没有上溢,转入步骤(6),否则采用AdjustTree子算法对STR-tree做向上递归分裂处理,直至根节点后转入步骤(6),如图2所示。子算法ChooseLeaf和AdjustTree的作为本算法的核心部分,这里采用伪代码进行介绍如下。
(6)算法结束。
| 算法1伪代码:ChooseLeaf(叶节点选择) |
|---|
| Input:Path,STR-tree Output:InsertNode Begin TNode←Root :目标节点TNode初始化为根节点 minExtChild.Clear( ) :minExtChild清空,minExtChild为TNode的子节点中插入轨迹束后MBB扩展最小的子节点 while TNode.child != NULL do:TNode有子节点时执行下列操作 minExtChild←TNode:minExtChild初始化为当前操作节点 for each (child in TNode ):对TNode的子节点进行遍历 if (minExtChild.Add(Path).MBB-minExtChild.MBB)> (child.Add(Path).MBB - child.MBB) :选择扩张最小的子节点child minExtChild←child:child赋值给minExtChild TNode←minExtChild:目标节点TNode更新为minExtChild,实现向下的遍历 return TNode:返回TNode得到最终扩张最小的叶节点 End |
| 算法2伪代码:AdjustTree(树结构调整) |
|---|
| Input:STR-tree, InsertNode, p Output:STR-tree Begin TNode←InsertNode:TNode为目标节点,初始化为插入节点InsertNode while TNode.father != NULL do:TNode父节点不为空时,执行下列操作 TNode.father.ExtensionMBB( ):调整TNode父节点的外界矩形MBB if TNode.child>p:如果TNode插入轨迹束后子节点数量大于阈值p TNode.SplitNode( ):TNode分裂 TNode←TNode.father:TNode更新为TNode的父节点,实现向上的递归 End |
算法描述:2种不同类别时空查询算法
算法输入:已构建的MFSTR-tree结构,查询条件
算法输出:满足查询条件的采样点集
算法流程:
查询算法整体流程主要分为2个阶段:
(1)叶节点搜索过程
根据查询的时空范围对MFSTR-tree采用自上而下进行检索,得到满足条件的所有叶节点(即MBB与查询范围有重叠)得到一次查询结果,过程如下:
① 以根节点作为目标节点TNode,查找最小外包矩形MBB与查询范围相交的子节点。
② 若子节点非叶节点,则上一步中得到的子节点依次作为目标节点TNode,向下遍历查找最小外包矩形MBB与查询范围相交的子节点。
③ 若子节点为叶节点,则标记为符合查询条件的叶节点直至找到全部符合条件的叶节点。
(2)采样点筛选过程
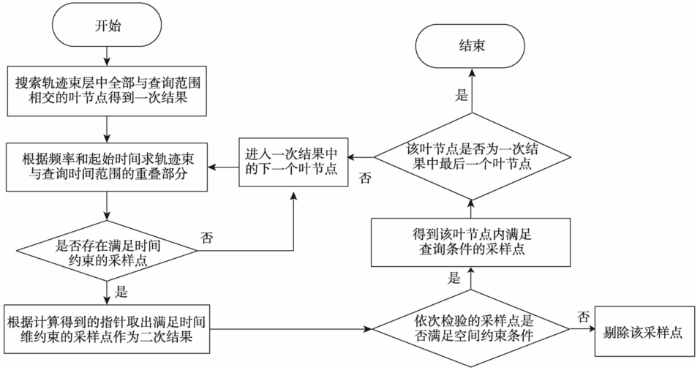
对一次结果中每个叶节点中的采样点进行筛选,利用轨迹束的频率和起始时间在时间维度上约束得到二次结果,最后在进行空间约束的检验得到最终满足条件的所有采样点,流程如图3所示。查询算法根据条件又细分为单时间切片查询和时空范围查询,二者的区别主要体现在利用时间约束条件对采样点进行筛选求二次结果过程中。
① 单时间切片查询
对一次结果的叶节点内采样点进行筛选时,无需进入节点内对轨迹束的每一个采样点进行判断,利用频率和叶节点的startTime判断该叶节点内的Path中是否存在t时刻的采样点。判断方法依据 式(2),rem等于0则取出该采样点作为候选;否则不存在。直至找到所有满足时间约束的候选采样点输出二次结果。
式中:t为查询时刻;f为频率;mod表示取余数运算。
② 时空范围查询
计算一次结果中的叶节点轨迹束的时间跨度[ta,tb],逐个求该节点的时间跨度与查询条件中的时间段[ti,tj]的重合部分[tm,tn](式(3)):若[tm,tn]为空,则跳过该叶节点;若[tm,tn]= [ta,tb],则输出该叶节点内全部候选采样点;否则,根据[tm,tn]筛选输出所有满足时间约束的候选采样点。
实验硬件环境为Intel Core i7-6700HQ 2.60 GHz CPU,16.0GB内存。软件环境为Microsoft Windows 10操作系统(64位),Visual C++开发语言,编译环境为Visual Studio 2015(社区版)。实验采用全球2015年1-12月的Argo浮标历史数据,包括4299个浮标共126 844个采样点,数据集来自中国Argo实时资料中心。用于对比的3种索引中3DR-tree主体的扇叶(fans)的最大和最小参数分别为8和4,STR-tree和MFSTR-tree的叶节点中的轨迹束层的轨迹时间跨度为50 d。
对HR-tree、STR-tree与本文的MFSTR-tree构建效率的对比实验包括存储空间效率和构建时间效率2方面。
表1是3种索引构建效率的多项指标对比结果其中,采样点插补访问节点数表示查找对应的未满前序轨迹束插补采样点时访问的节点数;新轨迹束插入访问节点数表示没有找到未满的前序轨迹束时创建新的轨迹束插入时访问的节点数。具体分析情况如下:
(1)构建存储效率
3种索引的主体框架均采用3DR-tree,所占存储空间主要包括采样点数据本身和3DR-tree的体积2部分。由于每个采样点数据的大小为2 KB且数目相同,因此,所占存储空间大小的差异主要由3DR-tree部分的结构大小引起。表1中3DR-tree节点数目中可以看出,由于采用了轨迹束的思想,将属于同一移动目标的采样点序列按时间序列分段作为3DR-tree的叶节点进行存储,相比较HR-tree的序列快照模型,STR-tree和MFSTR-tree的3DR-tree部分的节点数目要缩小了约n/p(n为HR-tree时间切片的厚度,p为轨迹束中的平均点个数),部分降低了存储空间大小。在此基础上,本文提出的MFSTR-tree中的动态轨迹束能够根据移动目标的更新频率调整单条轨迹束采样点的数量,进一步将3DR-tree的节点数目和存储空间压缩。
(2)构建时间效率
表1中采样点插补访问节点数可以看出,HR-tree索引构建时采用直接插入采样点的方式,因此在时间效率上具有绝对优势。而STR-tree和MFSTR-tree的的插入过程包括已有空缺轨迹束的插补和新轨迹束插入2部分组成,这2部分都需要对符合要求的叶节点进行搜索,因此效率不及HR-tree,本文方法构建的动态轨迹束数量上少于一般STR-tree,同样在时间效率上略占优势。
表1 索引构建效率对比结果
Tab. 1 Efficiency comparison of index generation
| 索引类型 | 3DR-tree节点数目 | 存储空间/KB | 采样点插补访问节点数 | 新轨迹束插入访问节点数 | 节点分裂次数 | 构建用时/s |
|---|---|---|---|---|---|---|
| HR-tree | 165 247 | 280 883 | 0 | 890 168 | 29 241 | 2.031 |
| STR-tree | 29 707 | 276 437 | 4 621 861 | 167 889 | 6529 | 3.122 |
| MFSTR-tree | 25 991 | 276 279 | 3 910 859 | 145 595 | 5678 | 2.783 |
本节进行单时间切片查询和时空范围查询性能两方面的对比和分析。时空查询窗口的大小分别为实验区域内各维度轴向区间的1%,10%,20%(时间切片查询效率的时间维大小为0),查询位置随机生成,取10 000次查询平均值作为结果。其中,访问节点数为查询过程中需要访问的节点数目,MBB求交次数为时空查询范围与待判断节点的最小外包矩形的浮点计算次数。
(1)单时间切片查询效率
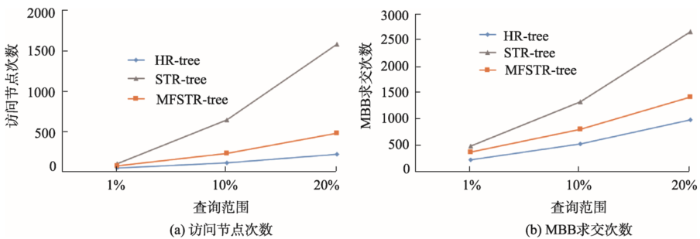
实验结果如表2所示,从图4的对比结果不难发现,随着查询窗口的不断增大,STR-tree和MFSTR-tree索引无论是在访问节点数还是MBB求交次数均大于HR-tree索引,因此查询效率低于HR-tree,其中STR-tree索引效率降低尤为突出,经过改进的MFSTR-tree在时间切片查询中的效率虽仍不及HR-tree,但已经得到了较大改善。主要原因在于:① STR-tree和MFSTR-tree以一条轨迹束作为3DR-tree节点上的基本存储单元,二者相比于HR-tree本身存在节点MBB重叠率高的缺陷,特别是在维度增加的情况下对效率的影响极为显著;② MFSTR-tree在轨迹长度上基于频率的动态控制手段有效降低了轨迹节点的重叠率,同时在命中目标轨迹节点后利用频率和起始时间筛选轨迹中满足条件采样点的方式减少了采样点的访问数量,虽然效率仍不及HR-tree,但已部分弥补了STR-tree在时间切片查询效率中的严重不足。
表2 单时间切片查询实验结果
Tab. 2 Efficiency comparison of time slices queries
| 索引类型 | 查询空间范围/% | 访问节点次数 | MBB求交次数 |
|---|---|---|---|
| HR-tree | 1 | 37 | 207 |
| 10 | 104 | 511 | |
| 20 | 207 | 966 | |
| STR-tree | 1 | 93 | 464 |
| 10 | 635 | 1311 | |
| 20 | 1569 | 2645 | |
| MFSTR-tree | 1 | 64 | 354 |
| 10 | 221 | 791 | |
| 20 | 469 | 1405 |
(2)时空范围查询效率
表3是3种索引时空范围查询效率实验结果。从图5的对比中不难发现当查询范围扩展到时空,随着查询窗口的增大,HR-tree的效率明显降低,无论是访问节点数还是MBB求交次数都先后超越了STR-tree和MFSTR-tree。访问节点数分别在查询窗口大约为2%和4%超过MTSTR-tree和STR-tree;MBB求交次数在3%和7%超过,其中MFSTR-tree相比于普通STR-tree在时空范围查询效率上依然保持一定优势。分析原因在于:① HR-tree的序列快照模型将时间和空间信息分别维护,造成了索引本身体积较大,随着时间跨度增加,访问的节点数成倍增加,导致其效率急剧降低。另外2种索引由于同时保留了部分轨迹和轨迹间的空间邻近关系,搜索到达轨迹束层时,仅通过存储位置的计算可过滤掉大量无关的轨迹束节点,因此优势得以体现。② MFSTR-tree索引方法基于轨迹束的更新频率根据式(3)通过求交计算的方式筛选掉大量的无效采样点,因此效率得以提升,而STR-tree仍需要对轨迹束内的采样点逐个进行判断。
表3 时空范围查询实验结果
Tab. 3 Efficiency comparison of spatio-temporal range queries
| 索引类型 | 查询时空范围/% | 访问节点次数 | MBB求交次数 |
|---|---|---|---|
| HR-tree | 1 | 39 | 216 |
| 10 | 811 | 1458 | |
| 20 | 3687 | 4989 | |
| STR-tree | 1 | 96 | 474 |
| 10 | 650 | 1332 | |
| 20 | 1874 | 3475 | |
| MFSTR-tree | 1 | 67 | 370 |
| 10 | 349 | 1107 | |
| 20 | 1076 | 2694 |
本文概述了当前面向移动对象的2类时空索引方法以及其改进方法,分析对比了多种方法的优缺点。结合海洋浮标数据的特点,基于STR-tree建立了多频率下的混合索引结构MFSTR-tree。本文将轨迹数据的更新频率和STR-tree在搜索效率上的优势相结合实现算法的改进,并描述了相应的操作算法。实验结果表明:该方法在保证构建时间效率和存储效率的前提下,查询效率方面,HR-tree在单时间片查询中仍保持天然的优势效率远大于另外两种,优化后MFSTR-tree的相比于一般STR-tree提升近40%;而在时空范围查询效率对比中,随着查询窗口大小扩展至总体范围4%以后,HR-tree的查询效率下降明显,其中MFSTR-tree在原有STR-tree基础上进一步优化,提升了轨迹束中采样点筛选过程中的效率,因此优势更为明显,实现了对本文算法的验证。
The authors have declared that no competing interests exist.
| [1] |
Argo资料协同管理方法研究 [J].Research on collaborative management method of Argo data [J]. |
| [2] |
Two databases derived from BGC-Argo float measurements for biogeochemical and bio-optical applications at the global scale [J].https://doi.org/10.5194/essd-2016-34 URL [本文引用: 1] 摘要
The aim of the World Soil Information Service (WoSIS) is to serve quality-assessed, georeferenced soil data (point, polygon, and grid) to the international community upon their standardisation and harmonisation. So far, the focus has been on developing procedures for legacy point data with special attention to the selection of soil analytical and physical properties considered in the GlobalSoilMap specifications (e.g. organic carbon, soil pH, soil texture (sand, silt, and clay), coarse fragments (65<6562262mm), cation exchange capacity, electrical conductivity, bulk density, and water holding capacity). Profile data managed in WoSIS were contributed by a wide range of soil data providers; the data have been described, sampled, and analysed according to methods and standards in use in the originating countries. Hence, special attention was paid to measures for soil data quality and the standardisation of soil property definitions, soil property values, and soil analytical method descriptions. At the time of writing, the full WoSIS database contained some 11862400 unique “shared” soil profiles, of which some 9662000 are georeferenced within defined limits. In total, this corresponds with over 31 million soil records, of which some 2062% have so far been quality-assessed and standardised using the sequential procedure discussed in this paper. The number of measured data for each property varies between profiles and with depth, generally depending on the purpose of the initial studies. Overall, the data lineage strongly determined which data could be standardised with acceptable confidence in accord with WoSIS procedures, corresponding to over 4 million records for 9462441 profiles. The publicly available data – WoSIS snapshot of July 2016 – are persistently accessible from ISRIC WDC-Soils through doi:10.17027/isric-wdcsoils.20160003.
|
| [3] |
Distributed monitoring and management of exascale systems in the argo project [C]// |
| [4] |
Argo Data Management [C]// |
| [5] |
Argo数据研究应用现状与发展趋势 [J].https://doi.org/10.3969/j.issn.1004-2490.2007.04.012 URL [本文引用: 1] 摘要
海洋在调节大气环流和气候变化中起着非常重要的作用,但是受到技术条件和观测资料的限制,人 们对广阔海洋垂直剖面上的温、盐度和海流资料则获之很少,不能满足气候预测的需求。国际Argo计划的实施,提供了大量、密集的和准同步、准实时的海洋要 素资料。有助于准确、全面地了解全球气候的变化;对分析大洋渔场的形成、渔业资源的分布有重大意义。目前,Argo数据已经被广泛地应用于很多领域,取得 了不少研究和应用的成果。
The application area and products of the Argo profile floats data [J].https://doi.org/10.3969/j.issn.1004-2490.2007.04.012 URL [本文引用: 1] 摘要
海洋在调节大气环流和气候变化中起着非常重要的作用,但是受到技术条件和观测资料的限制,人 们对广阔海洋垂直剖面上的温、盐度和海流资料则获之很少,不能满足气候预测的需求。国际Argo计划的实施,提供了大量、密集的和准同步、准实时的海洋要 素资料。有助于准确、全面地了解全球气候的变化;对分析大洋渔场的形成、渔业资源的分布有重大意义。目前,Argo数据已经被广泛地应用于很多领域,取得 了不少研究和应用的成果。
|
| [6] |
Argo浮标温盐剖面观测资料的质量控制技术 [J].https://doi.org/10.6038/j.issn.0001-5733.2012.02.020 Magsci [本文引用: 1] 摘要
Argo浮标可用来监测全球大洋从海表到2000 m深层的变化,鉴于Argo浮标的剖面观测数据存在位置错误、可疑剖面、异常数据以及盐度漂移等诸多问题,必须对Argo浮标资料进行有效的质量控制.本文基于Argo观测剖面资料与法国海洋开发研究院(IFREMER)提供的可靠历史观测数据集,提出了一种Argo资料质量控制的新途径.该方法通过寻找Argo浮标不同剖面位置与其"最佳匹配"历史剖面资料对比判别的途径,可以有效地识别Argo观测误差,特别是能够将由于Argo位置环境变化引起和由Argo浮标自身漂移引起的两类Argo浮标盐度偏移现象进行有效甄别,减少了对Argo浮标盐度剖面偏移的误判,有效节约了Argo浮标质量控制时间.本文还提出基于"三倍标准差"的异常数据检测方法,并将其与传统异常数据检测法相结合进行剖面异常数据剔除,有效实现了对异常数据的剔除.基于本文提出的Argo资料质量控制方法,对中国Argo实时资料中心网站提供的全球Argo浮标剖面进行了质量控制再分析,进一步剔除和订正了其中的一些数据误差,生成了经新的质量再控制后的全球Argo浮标剖面资料集.通过将质量再控制处理前后的数据与Ishii资料进行比较发现,处理后的数据比处理前的数据误差减小,表明本文提出的方法合理有效.
Quality control of Argo temperature and salinity observation profiles [J].https://doi.org/10.6038/j.issn.0001-5733.2012.02.020 Magsci [本文引用: 1] 摘要
Argo浮标可用来监测全球大洋从海表到2000 m深层的变化,鉴于Argo浮标的剖面观测数据存在位置错误、可疑剖面、异常数据以及盐度漂移等诸多问题,必须对Argo浮标资料进行有效的质量控制.本文基于Argo观测剖面资料与法国海洋开发研究院(IFREMER)提供的可靠历史观测数据集,提出了一种Argo资料质量控制的新途径.该方法通过寻找Argo浮标不同剖面位置与其"最佳匹配"历史剖面资料对比判别的途径,可以有效地识别Argo观测误差,特别是能够将由于Argo位置环境变化引起和由Argo浮标自身漂移引起的两类Argo浮标盐度偏移现象进行有效甄别,减少了对Argo浮标盐度剖面偏移的误判,有效节约了Argo浮标质量控制时间.本文还提出基于"三倍标准差"的异常数据检测方法,并将其与传统异常数据检测法相结合进行剖面异常数据剔除,有效实现了对异常数据的剔除.基于本文提出的Argo资料质量控制方法,对中国Argo实时资料中心网站提供的全球Argo浮标剖面进行了质量控制再分析,进一步剔除和订正了其中的一些数据误差,生成了经新的质量再控制后的全球Argo浮标剖面资料集.通过将质量再控制处理前后的数据与Ishii资料进行比较发现,处理后的数据比处理前的数据误差减小,表明本文提出的方法合理有效.
|
| [7] |
基于Argo资料的三维盐度场网格化产品重构 [J].https://doi.org/10.3969/j.issn.1009-3443.2012.03.020 URL [本文引用: 1] 摘要
针对标准化海洋盐度场产品较为匮乏的事实,利用Argo温盐观测剖面与卫星遥感海表温度资料,采用时空权重插值和多变量DINEOF方法,对太平洋区域2000年1月至2008年12月的三维逐周盐度场进行重构。提出的重构方法有2个明显特色,一是采用时空权重插值与多变量DINEOF相结合的方法,弥补了时空权重插值结果中包含缺失数据的不足;二是引入卫星遥感海表温度,弥补了Argo可靠海表数据的缺乏。重构再分析产品与其他观测和数据产品的对比结果表明,重构产品不但能够抓住盐度分布的主要模态特征,而且可表现盐度不同时间尺度的变化特征,为海洋和气候研究提供了一种有用的标准化数据新产品。
Reconstruction of three-dimensional gridded salinity product based on Argo data [J].https://doi.org/10.3969/j.issn.1009-3443.2012.03.020 URL [本文引用: 1] 摘要
针对标准化海洋盐度场产品较为匮乏的事实,利用Argo温盐观测剖面与卫星遥感海表温度资料,采用时空权重插值和多变量DINEOF方法,对太平洋区域2000年1月至2008年12月的三维逐周盐度场进行重构。提出的重构方法有2个明显特色,一是采用时空权重插值与多变量DINEOF相结合的方法,弥补了时空权重插值结果中包含缺失数据的不足;二是引入卫星遥感海表温度,弥补了Argo可靠海表数据的缺乏。重构再分析产品与其他观测和数据产品的对比结果表明,重构产品不但能够抓住盐度分布的主要模态特征,而且可表现盐度不同时间尺度的变化特征,为海洋和气候研究提供了一种有用的标准化数据新产品。
|
| [8] |
Spatio-temporal Access Methods [J]. |
| [9] |
时空索引的演变与发展 [J].https://doi.org/10.3969/j.issn.1002-137X.2010.04.004 URL [本文引用: 1] 摘要
近年来,随着移动计算和无线通信等技术的发展,时空数据库广泛应用于交通控制和全球定位等领域.为了支持时空查询和有效地管理时空数据库中海量的时空对象,专家学者提出了大量的时空索引方法.首先对时空索引进行归纳总结,描绘了时空索引演化历史图;接着对时空查询类型进行介绍;根据时间维将时空索引分为索引过去、当前、将来和全时态4美,根据空间雏将时空索引分为移动点和移动区域两类,在此分类基础上对各种时空索引方法进行了阐述;最后对时空索引的研究方向进行了展望.
Evolvement and progress of spatio-temporal Index [J].https://doi.org/10.3969/j.issn.1002-137X.2010.04.004 URL [本文引用: 1] 摘要
近年来,随着移动计算和无线通信等技术的发展,时空数据库广泛应用于交通控制和全球定位等领域.为了支持时空查询和有效地管理时空数据库中海量的时空对象,专家学者提出了大量的时空索引方法.首先对时空索引进行归纳总结,描绘了时空索引演化历史图;接着对时空查询类型进行介绍;根据时间维将时空索引分为索引过去、当前、将来和全时态4美,根据空间雏将时空索引分为移动点和移动区域两类,在此分类基础上对各种时空索引方法进行了阐述;最后对时空索引的研究方向进行了展望.
|
| [10] |
基于3D+-TPR-tree的点目标全时段移动索引设计 [J].A whole-time index design based on 3D+-TPR-tree for moving point targets [J]. |
| [11] |
面向全时段查询的移动对象时空数据模型研究 [J].
大量移动对象时空数据的有效管理是移动空间信息服务的一个新兴的研究内容。本文提出一个面向全时段查询的移动对象时空数据模型,并给出基本的模型定义;探讨移动对象过去、现在和将来的运动位置估算方法,这些方法包括延时法、滑动平均法、三次指数法等;研究了移动对象的状态更新策略,提出一个适应于更新时间间隔的变动阈值法的移动对象的状态更新策略,该策略采用时间滑动窗口形式建立移动对象状态更新间隔的一元指数回归方程,通过求取回归参数获得移动对象状态更新趋势,利用该参数动态调整状态更新闽值。最后,给出实验模拟结果,并对今后的研究工作进行了展望。
Research on full-period query oriented moving objects spatio-temporal model [J].
大量移动对象时空数据的有效管理是移动空间信息服务的一个新兴的研究内容。本文提出一个面向全时段查询的移动对象时空数据模型,并给出基本的模型定义;探讨移动对象过去、现在和将来的运动位置估算方法,这些方法包括延时法、滑动平均法、三次指数法等;研究了移动对象的状态更新策略,提出一个适应于更新时间间隔的变动阈值法的移动对象的状态更新策略,该策略采用时间滑动窗口形式建立移动对象状态更新间隔的一元指数回归方程,通过求取回归参数获得移动对象状态更新趋势,利用该参数动态调整状态更新闽值。最后,给出实验模拟结果,并对今后的研究工作进行了展望。
|
| [12] |
基于R*-tree的时空数据库索引VC-tree [J].
在时空数据的索引结构中,HR-tree可以高效处理时间片查询,但对时间段查询效率低下,同时存在存储冗余。3D-tree索引的效率较低,双树结构使索引维护较为困难,且磁盘访问开销大。该文提出一种新的基于R*-tree的索引结构VC-tree,便于管理维护,可以高效满足时空查询,并满足有效时间内的未来查询。 <BR>
VC-tree: Spatial-temporal database index based on R*-tree [J].
在时空数据的索引结构中,HR-tree可以高效处理时间片查询,但对时间段查询效率低下,同时存在存储冗余。3D-tree索引的效率较低,双树结构使索引维护较为困难,且磁盘访问开销大。该文提出一种新的基于R*-tree的索引结构VC-tree,便于管理维护,可以高效满足时空查询,并满足有效时间内的未来查询。 <BR>
|
| [13] |
一种适合于频繁位置更新的网络受限移动对象轨迹索引 [J].An index structure for frequently updated network-constrained moving object trajectories [J]. |
| [14] |
三维虚拟地球中移动对象的时空数据组织方法 [J].https://doi.org/10.13203/j.whugis20140519 URL [本文引用: 1] 摘要
针对三维虚拟地球中实时GIS数据组织、管理与动态可视化的要求,设计了三维虚拟地球中移动对象的时空数据组织方法。提出了基于HR-tree扩展的时空索引方法,实现了对虚拟地球中移动对象的检索与查询,并基于三维虚拟地球平台对本文方法进行了实验,结果验证了本文方法的有效性和可行性。
Spatio-temporal data organization method of moving objects in 3D virtual globes [J].https://doi.org/10.13203/j.whugis20140519 URL [本文引用: 1] 摘要
针对三维虚拟地球中实时GIS数据组织、管理与动态可视化的要求,设计了三维虚拟地球中移动对象的时空数据组织方法。提出了基于HR-tree扩展的时空索引方法,实现了对虚拟地球中移动对象的检索与查询,并基于三维虚拟地球平台对本文方法进行了实验,结果验证了本文方法的有效性和可行性。
|
| [15] |
Silva J R O. Towards historical R-trees [C]// |
| [16] |
支持频繁位置更新的移动对象索引方法 [J].https://doi.org/10.3724/SP.J.1047.2017.00152 URL [本文引用: 1] 摘要
传统R-tree及其变种难以满足移动对象频繁更新位置的需求。本文通过在R*-tree中引入多种移动对象索引策略,提出一种基于延迟更新和备忘录更新/插入相结合的移动对象索引结构LUMR*-tree(Lazy Update Memo R*-tree)。利用延迟更新策略,LUMR*-tree能够在几乎不改变索引结构的前提下快速完成更新操作;通过引入更新备忘录(Update Memo, UM),LUMR*-tree将复杂的更新操作简化为插入操作,避免了从索引树中频繁删除旧记录的过程;借助垃圾清理器定期清理索引树和UM中的旧记录,动态维护UM中的数据项和内存大小,保证了LUMR*-tree的稳定性和高效性。实验结果表明,LUMR*-tree通过牺牲少量查询性能获得了优良的更新性能,能够满足移动对象频繁位置更新的需求,具有较好的实用价值和广泛的应用前景。
A moving object indexing method for point data based on Octree and 3DR-tree updating [J].https://doi.org/10.3724/SP.J.1047.2017.00152 URL [本文引用: 1] 摘要
传统R-tree及其变种难以满足移动对象频繁更新位置的需求。本文通过在R*-tree中引入多种移动对象索引策略,提出一种基于延迟更新和备忘录更新/插入相结合的移动对象索引结构LUMR*-tree(Lazy Update Memo R*-tree)。利用延迟更新策略,LUMR*-tree能够在几乎不改变索引结构的前提下快速完成更新操作;通过引入更新备忘录(Update Memo, UM),LUMR*-tree将复杂的更新操作简化为插入操作,避免了从索引树中频繁删除旧记录的过程;借助垃圾清理器定期清理索引树和UM中的旧记录,动态维护UM中的数据项和内存大小,保证了LUMR*-tree的稳定性和高效性。实验结果表明,LUMR*-tree通过牺牲少量查询性能获得了优良的更新性能,能够满足移动对象频繁位置更新的需求,具有较好的实用价值和广泛的应用前景。
|
| [17] |
一种集成R树、哈希表和B树的高效轨迹数据索引方法 [J].https://doi.org/10.11947/j.AGCS.2015.20130520 Magsci [本文引用: 1] 摘要
为兼顾时空索引方法的空间利用率、时间效率和查询种类,提出了一种新的轨迹数据索引方法——HBSTR树。其基本思想是:轨迹采样点以轨迹节点的形式成组集中管理,哈希表用于维护移动目标的最新轨迹节点,轨迹节点满后作为叶节点插入时空R树,另外采用B<sup>*</sup>树对轨迹节点构建一维索引,既有利于提升索引创建效率,又同时满足时空条件搜索和特定目标轨迹搜索等多种查询类型。为提升时空查询效率,提出了新的时空R树评价指标和节点选择子算法改进时空R树插入算法,同时提出了一种时空R树的数据库存储方案。试验结果表明,HBSTR树在创建效率、查询效率和支持查询类型等方面综合性能优于现有方法,支持大规模实时轨迹数据库的动态更新和高效访问。
An efficient trajectory data index integrating R-tree, Hash and B-tree [J].https://doi.org/10.11947/j.AGCS.2015.20130520 Magsci [本文引用: 1] 摘要
为兼顾时空索引方法的空间利用率、时间效率和查询种类,提出了一种新的轨迹数据索引方法——HBSTR树。其基本思想是:轨迹采样点以轨迹节点的形式成组集中管理,哈希表用于维护移动目标的最新轨迹节点,轨迹节点满后作为叶节点插入时空R树,另外采用B<sup>*</sup>树对轨迹节点构建一维索引,既有利于提升索引创建效率,又同时满足时空条件搜索和特定目标轨迹搜索等多种查询类型。为提升时空查询效率,提出了新的时空R树评价指标和节点选择子算法改进时空R树插入算法,同时提出了一种时空R树的数据库存储方案。试验结果表明,HBSTR树在创建效率、查询效率和支持查询类型等方面综合性能优于现有方法,支持大规模实时轨迹数据库的动态更新和高效访问。
|
| [18] |
Novel approaches in query processing for moving object trajectories .[C]// |
| [19] |
A grid-aided and STR-Tree-based algorithm for partitioning vector data [C]// |
| [20] |
一种八叉树和三维R树集成的激光点云数据管理方法 [J].https://doi.org/10.3963/j.issn.2095-3844.2014.04.046 URL [本文引用: 1] 摘要
车载激光扫描点云数据已经成为数字城市和危机管理等领域越来越重要的三维空间信息源,针对大规模点云数据高效管理的技术瓶颈,提出一种八叉树和三维R树集成的空间索引方法——3DOR树,充分利用八叉树的良好收敛性创建R树叶节点,避免逐点插入费时过程,同时R树平衡结构保证良好的数据检索效率。并还扩展R树结构生成多细节层次(LOD)点云模型,提出一种支持缓存的多细节层次点云数据组织方法。试验证明,该方法具有良好的空间利用率和空间查询效率,支持多细节层次描述能力和数据缓存机制,可应用于大规模点云数据的后处理与综合应用。
An efficient management method index integrating R-tree, Hash and B-tree [J].https://doi.org/10.3963/j.issn.2095-3844.2014.04.046 URL [本文引用: 1] 摘要
车载激光扫描点云数据已经成为数字城市和危机管理等领域越来越重要的三维空间信息源,针对大规模点云数据高效管理的技术瓶颈,提出一种八叉树和三维R树集成的空间索引方法——3DOR树,充分利用八叉树的良好收敛性创建R树叶节点,避免逐点插入费时过程,同时R树平衡结构保证良好的数据检索效率。并还扩展R树结构生成多细节层次(LOD)点云模型,提出一种支持缓存的多细节层次点云数据组织方法。试验证明,该方法具有良好的空间利用率和空间查询效率,支持多细节层次描述能力和数据缓存机制,可应用于大规模点云数据的后处理与综合应用。
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}