颜金彪 , 郑文武, 邓运员
, 郑文武, 邓运员
YAN Jinbiao, ZHENG Wenwu, DENG Yunyuan
通讯作者:
收稿日期: 2018-01-30
修回日期: 2018-04-15
网络出版日期: 2018-07-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:颜金彪(1987-),男,湖南衡阳人,硕士生,主要从事时空数据挖掘研究。E-mail: 715829216@qq.com
展开
摘要
针对传统的最小生成树聚类算法存在使用全局不变阈值确定噪声边,聚类需要用户根据经验确定初始化聚类参数,如“边权值倍数容差”,“边长变化因子”等,聚类不能发现局部噪声的问题,本文提出了一种改进的最小生成树自适应空间点聚类算法。该算法在无需用户输入参数的前提下,克服主观因素的影响,根据最小生成树边长的数理统计特征定义裁剪因子。算法首先从宏观层面对最小生成树进行首轮删枝操作,消除全局环境下的噪声边,进而根据各子树的边长统计情况,自适应设定局部裁剪因子,进行第二轮删枝操作,消除局部环境下的噪声边。最后,采用1个模拟数据和1个实际应用验证算法的有效性,结果表明本文提出的改进算法在无需人为提供经验参数的环境下能够发现任意形状、不同密度的簇,能够准确的识别出空间点中的噪声数据,从而能够实现空间点数据背后隐藏信息的自动挖掘。
关键词:
Abstract
In this paper, we proposed an improved adaptive spatial point clustering algorithm based on minimum spanning tree (MSTAA in abbreviation) to solve the problems existed in the traditional clustering algorithms. The first problem of these classical clustering algorithms is that the noise edges are determined using the global invariant. Another one is that the initial clustering parameters such as edge weight tolerance, edge variation factor, the number of clusters and initial clustering centers are determined by the users empirically. Furthermore, these algorithms can't find the noise edges at the local level. Based on these problems mentioned above, the algorithm put forward in this article aims to overcome the influence of subjective factors by defining two clipping factors. These trimming factors do not need to be determined by the users and can be automatically obtained according to the statistical features of the side length in the minimum spanning tree. The detailed realization process is as follows. In the first place, the pruning operation on the minimum spanning tree from the global level is carried out, which can eliminate the noises in the global environment. After the first round of tailoring, the initial minimum spanning tree becomes sub-tree collections. In the second place, in order to eliminate the noises at the local level, the algorithm performs the second round of pruning operation by setting the adaptive local cutting factor in the light of the side length statistics of each sub-tree. After the above two rounds of cutting, the MSTAA algorithm will get the final clustering result. In order to validate the effectiveness of the algorithm, both a simulated data and a practical application are adopted. By comparing with 4 classical clustering algorithms (k-means, DBSCAN, SEMST, HEMST), we find that the improved algorithm presented in this paper could find clusters of arbitrary shape and density in the environment where no one provides experience parameters. At the same time, not only does the MSTAA algorithm eliminate the obvious global noise points, but also it can distinguish noise points at the local environment so as to ensure a high similarity degree of cluster point set. All of the features of the MSTAA algorithm mentioned above make it possible to automatically mine hidden information behind spatial point data.
Keywords:
作为空间数据挖掘、知识发现的重要研究内容,聚类分析已经应用在国计民生的各个方面,如交通事故热点分析[1]、生物种群分布[2]、医疗卫生[3]、犯罪热点分析[4]、地震监测分析[5]等。现有的空间聚类算法主要可以分为5类[6]:① 基于划分的算法,如K-means[7], AP(Affinity Propagation) [8,9];② 基于层次的算法,如CURE[10];③ 基于密度的算法,如DBSCAN[11];④ 基于图论的算法,如MST;⑤ 基于格网的算法,如STING[12]。在众多的聚类算法当中,基于最小生成树的聚类算法已经被广泛的研究。
汪闽等[13]提出了一种带控制节点的最小生成树聚类算法,通过添加控制点与设定优先级的方法来优化聚类结果,但是需要用户设定控制点的个数及位置;Grygorash等[14]在使用全局不变阈值确定最小生成树的噪声边,但当簇密度相差较大时,该算法聚类结果不理想;王小乐等[15]采用图论和层次聚类算法的思想,从最小生成树中的一条边开始,通过一个控制参数,逐步合并该边连接的两个部分,该算法能够发现任意形状,不同密度的聚类,但是需要用户根据经验确定“边权值倍数容差”;邓敏等[6]提出了MSTLSC算法,该算法针对不同的空间局部分布密度,分别生成一系列子树,但需要用户设定“边长变化因子”。
上述基于最小生成树的聚类算法大都需要一定数量的初始化参数,徐晨铠等[16]提出了改进的最小生成树自适应分层聚类算法,该算法根据最近邻关系,自动为每个簇设定独立的裁剪阈值,使之适应分布密度相差较大的情况,并能够自动确定聚类数目,但是该算法不能保证所选链路是最小开销的链路[17];贾瑞玉等[18]提出了一种基于最小生成树的层次K-means算法,该算法改进了K-means初始聚类中心选择和聚类数目确定的问题,但是该算法在确定聚类数目的时候,采用了与经验阈值比较的方法,影响了聚类的准确率,同时该算法不能发现噪声点;朱利等[19]基于最小生成树提出一种自适应确定聚类数目的算法,但实际是利用边阈值代替聚类个数的人为输入。
针对上述问题,本文提出了一种改进的最小生成树自适应聚类算法(Adaptive Clustering algorithm based on Minimum Spanning Tree,MSTAA)。一方面,该算法要解决聚类需要输入初始化参数的问题,如初始聚类数目、聚类中心、“边权值倍数容差”、“边长变化因子”;另一方面,要求该算法能够发现任意形状,在包含大量噪声的空间点中识别出不同密度的簇。
根据视觉认知的Gestalt规则[20,21],人们在认识事物的过程中总是先从事物的整体进行认知,而后才从事物的部分进行认知。基于这种朴素的认知思想,本文首先从宏观层面,根据最小生成树边长的统计特征,定义宏观裁剪因子对最小生成树进行首轮删枝操作,继而从局部出发,定义局部裁剪因子,在首轮删枝操作后的基础上进行第二轮删枝操作,从而获得最终的聚类结果。为便于描述,下面给出一些必要的定义:
定义1:设G={V,E}表示最小生成树,V代表顶点,E代表边。当存在图subG={subV,subE},其中
定义2:对于最小生成树G,求取其平均边长mstMeanE,如式(1)所示。
式中:edgei为最小生成树G中第i条边长(本文采用欧氏距离,下同);N为最小生成树G中顶点数(下同)。
定义3:对于最小生成树G,求取边长的中误差mstVarE,如式(2)所示:
$mstVarE=\sqrt{\frac{\sum\limits_{i=1}^{N-1}(edge_{i}-mstMeanE)^{2}}{N-2}}$ (2)
定义4:对于子树subGq,定义子树subGq的平均边长为sonMstMeanEq,如式(3)所示。
式中:m为子树subGq中顶点数(下同);edgej表示子树subGq中边长(下同);q表示子树的编号(下同)。
定义5:对于子树subGq,求取子树subGq的边长中误差sonMstVarEq,如式(4)所示。
$sonMstVarE_{q}=\sqrt{\frac{\sum\limits_{j=1}^{m-1}(edge_{j}-sonMstMeanE_{q})^{2}}{m-2}}$ (4)
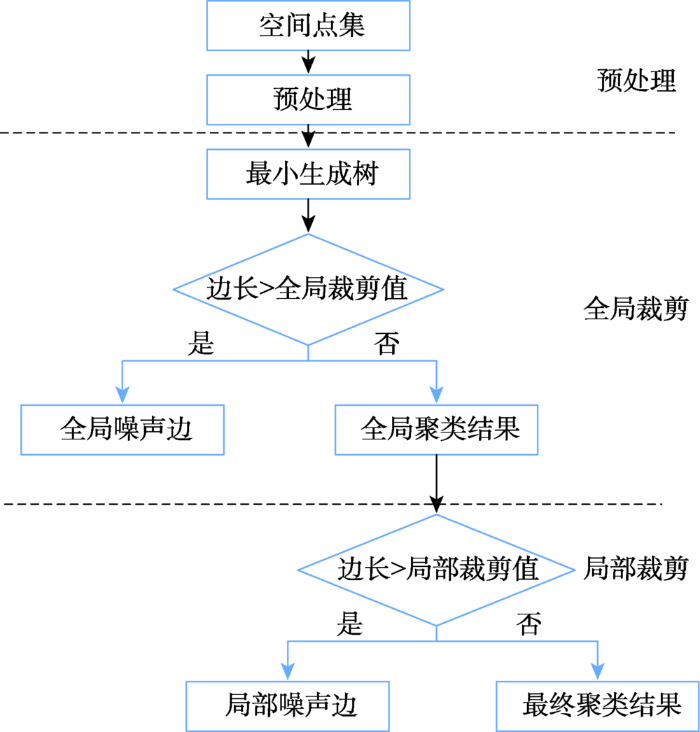
MSTAA算法使用逐步标记和分而治之的策略实现空间点的聚类,从宏观到局部两个层次逐步打断最小生成树中的长边,整个流程如图1所示。
3.2.1 数据预处理
该过程的主要任务是由空间点集得到最小生成树G,主要过程如下所述:① 数据清理。由于空间点可能存在压盖的情况,影响后续Delaunay三角网的生成,因此将压盖位置的空间点保留其中任意一个;② 将清理后的空间点生成Delaunay三角网;③ 根据步骤②生成的Delaunay三角网,利用prime算法生成最小生成树G。
3.2.2 全局裁剪
根据数据预处理得到的最小生成树G,计算出平均边长及边长中误差,从而计算出全局裁剪值 mstCutVi,将其作为全局裁剪阈值,如式(5)所示。
式中:α称为调和因子,值愈低对长边愈加敏锐,反之愈加迟钝,具体计算如式(6)所示,这保证了 mstCutVi不至于太大,也不至于太小,经后续实例验证,比较符合实际。
从式(5)-(6)可以看出,mstCutVi具备自适应特征,对于长边,则阈值愈低,那么该边更易断链,反之对于短边,阈值将变大,断链的可能性降低。
算法具体步骤如下:
(1)计算最小生成树G的平均边长mstMeanE与中误差mstVarE;
(2)选取最小生成树G中一条边edgei;
(3)计算边edgei对应的全局裁剪阈值mstCutVi;
(4)if edgei>mstCutVi,则将edgei断开,标记edgei;
(5)if edgei≤mstCutVi,则edgei保持不变,标记edgei,继续执行;
(6)重复步骤(2)-(5),直至最小生成树G中每条边均被标记;
(7)经过步骤(1)-(6),最小生成树G将被剖分成多棵子树。
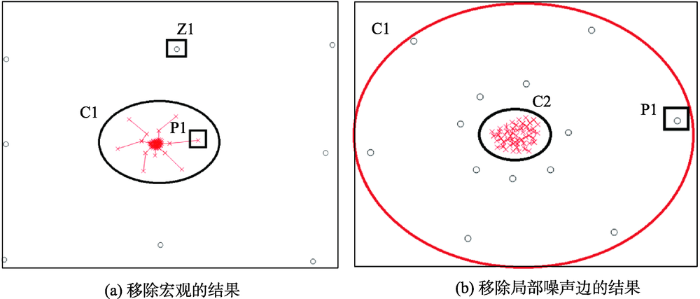
通过移除宏观噪声点,如图2(a)中的Z1点等,得到图2(a)中的C1簇。经过全局裁剪之后,可以发现C1簇内部仍然存在不一致点,如图2(a)中P1点等。由此可以发现,仅通过移除全局噪声边,仍不能精确识别空间点簇,需要在此基础进一步裁剪,消除局部噪声边对聚类结果的影响。
3.2.3 局部裁剪
经过全局裁剪之后,原始的最小生成树G变成子树集合sonMst。算法首先从子树集合中找到最长边,同时搜索出最长边所在的子树sonMstq,计算子树sonMstq中边长的均值与中误差,从而得到针对子树sonMstq对应的局部裁剪阈值sonMstCutVq,具体如式(7)所示。
式中:sonMstMeanEq与sonMstVarEq分别对应子树sonMstq的边长平均值和中误差。
β称为聚类敏感因子,值愈低对噪声愈加敏锐,越大对噪声反应愈加迟钝,β取值一般介于(2-3)之间,本文实验中取值为3。尽管MSTAA对于聚类敏感因子β的选取凭借的是经验,但是实际是借用了统计学上的显著性概念,因此具有一定的数学意义。当子树sonMstq的边长值满足正态分布,聚类敏感因子取值为3时,如果子树集合中最长边大于其所属子树sonMstq的局部裁剪阈值时,将以近99.7%的概率认为该最长边属于局部噪声边。
由上可见,sonMstCutVq同样具备自适应特征,将其作为最长边是否断链的判断标准。局部裁剪的具体实现如下步骤所述:
(1)从子树集合sonMst中找出最长边max,得到最长边max所属的子树sonMstq,然后用式(3)-(4)计算出子树sonMstq的平均边长与中误差;
(2)用式(7)计算出sonMstCutVq值;
(3)if max>sonMstCutVq,则将最长边所在的链断开,在子树集合sonMst中标记最长边的长度为0,同时将该棵子树在断链的位置进一步剖分为2棵子树,并将剖分结果更新到子树集合sonMst当中;
(4)if max≤sonMstCutVq,即最长边短于局部裁剪阈值,则可认为该棵子树中已不存在局部噪声边,该棵子树不需要进一步的剖分,将其作为最终聚类结果的一个子簇Cq,同时在子树集合sonMst中标记sonMstq子树中所有边长值为0;
(5)重复执行步骤(1)-(4),直至子树集合sonMst中所有边长全标记为0;
(6)输出最终聚类结果。
通过移除局部噪声点,如图2(b)中的P1点等,C1簇精简为图2(b)中的C2簇。可以明显发现C2簇点密度高,将其作为最终聚类结果的一个子簇较为合理。
本文中MSTAA算法在没有建立索引的前提下分析其时间复杂度。设空间点的数目为n,算法的时间主要集中在文中3.2节中的过程。其中,数据预处理中Delaunay三角网的建立采用分治算法,极端情况下需要花费o(nlgn)[22],最小生成树采用prime算法需要消耗o(n2)[23],全局裁剪需要花费 o(n-1),局部裁剪在极端情况下(即n个点呈现均匀分布)需要花费o(n2·(n-1)/2),因此在最为极端的情况下,MSTAA算法的时间复杂度为o(nlgn+n2+n-1+ n2·(n-1)/2)≈o(n3)。
本文设计了2个实验,其中包含1个模拟数据集[21]及1个真实的空间数据集,图3采用不同颜色来区分不同的点簇。为了验证MSTAA算法的有效性,将本文算法与K-means、DBSCAN、传统的最小生成树聚类算法进行对比分析。
如图3(a)的数据集,理想聚类结果分为6个簇,该数据包含不同密度、不同形状的簇,且点簇的周边存在不同层次下的噪声点,聚类结果采用“o”表示噪声点,“×”表示聚类点。
K-means需要初始化聚类数目k及初始化聚类中心,通过不断优化平方误差准则,获得对数据集的k个划分。本实验中将k设定为6,同时人工获取6个理想的点作为其初始聚类中心,聚类效果如图3(b)。
DBSCAN聚类算法基本思想在于采用一定邻域范围内包含的空间实体的最小数目定义空间密度的概念,并通过不断生长的高密度区进行空间聚类操作,本实验中通过人工探索,将DBSCAN算法的邻域半径eps设置为6,密度阈值minpts设置为4,聚类效果如图3(c)所示。
SEMST[24]算法首先将最小生成树的边长按照从大到小排列,根据用户设定的初始化聚类数目k,从中剔除k-1条长度排在前列的边。本文中将k值设定为6,聚类效果如图3(d)所示。
HEMST[14]算法属于层次聚类算法的一种,算法首先计算最小生成树的平均边长与中误差,得到裁剪阈值ω,如式(8)所示。
式中:
当最小生成树中边长大于ω时,将该边打断。如果此时生成的簇数量大于用户设定的簇数k,算法将距离较近的点簇合并,直至最终簇数等于设定值;如果此时簇数少于用户设定的数量k,算法将最小生成树中长边依次打断,直至簇的数量满足用户设定值,算法停止。本实验中将HEMST算法的初始化聚类数目也设定为6,聚类结果如图3(e)所示。MSTAA算法聚类结果如图3(f)所示。
通过分析图3可知:
(1)经典的K-means聚类算法不能发现噪声点(图3(b)中k1等),只能够发现凸形的簇,难以发现条带状的簇(图3(b)中k2、k3)。这是由于该算法核心在于通过一定的划分准则将整个数据集分成k个划分,同时将空间距离作为评判点集之间空间相似度的唯一指标,因此该算法不能发现噪声点且难以发现条带形状的簇。
(2)经典的DBSCAN算法在整个聚类过程中保持恒定的邻域半径及密度阈值,尽管DBSCAN算法能够识别出噪声点,但对于空间点分布密度存在变化的情况,算法容易发生误判,如此例中将部分密度稍低的空间点识别为噪声(如图3(c)k2等),同时将局部噪声点归并到聚类结果中(如图3(c)k1等);
(3)从图3(d)中可以看出,SEMST算法得到的6类结果与理想聚类结果相差甚大,完全不能满足需求。这是由于该算法仅从最小生成树中依次裁剪了k-1条最长边,针对最小生成树中噪声边的数量远大于k-1的情况(图3(a)),将导致该算法完全失效。
(4)HEMST算法能够识别出噪声点,能够发现不同密度、不同形状的簇,但由于该算法整个聚类的过程中保持相同的裁剪阈值(均值+中误差),而局部环境下的噪声边长易低于全局裁剪阈值,因此难以发现局部环境下的噪声边,如图3(e)中的k1、k2区域。
(5)MSTAA算法首先采用全局裁剪将明显的噪声点全部予以剔除,之后根据子树边长的数理统计特征自适应设定针对当前子树的局部裁剪阈值,从而能够剔除局部环境下的噪声点。从图3(f)中可以发现,得到的聚类结果与理想聚类结果吻合得较好。
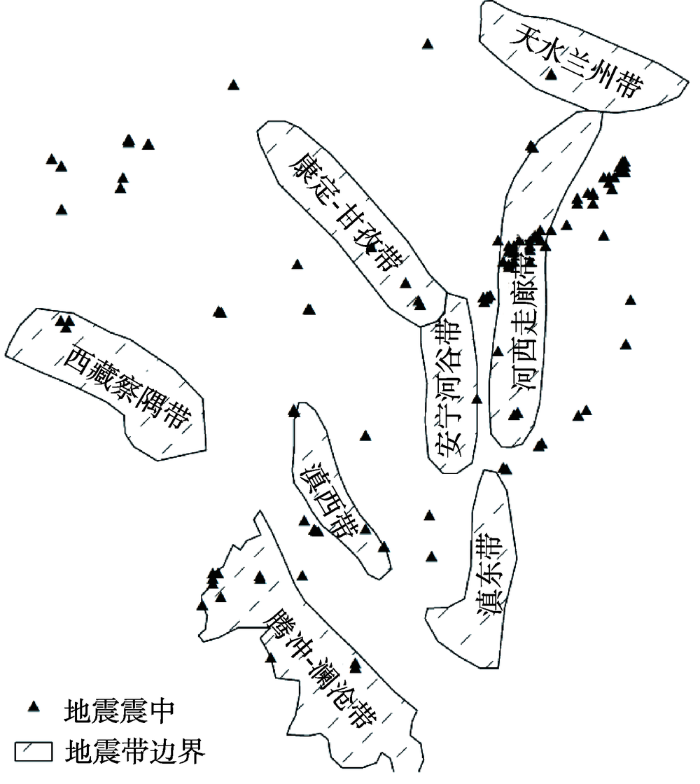
为了验证MSTAA算法的实用性,将其应用于地震活跃带的识别研究。本例中数据介于21°~35 °N,94°~107 °E之间,研究区域内由北往南分布着天水兰州、河西走廊、康定甘孜、安宁河谷、西藏察隅、滇西、滇东、腾冲-廊沧8个地震带。实验选取2008-2017年间震级M≥5的地震,共计111个震中点,如图4所示,数据均来源于中国地震信息网。
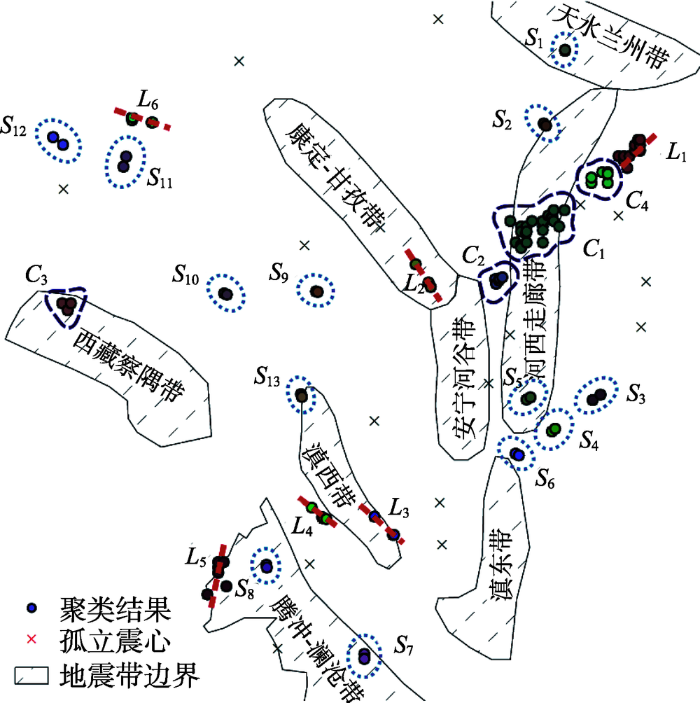
MSTAA算法的聚类结果如图4所示,采用“o”表示聚类结果,“×”表示孤立的地震震中,数据共分成23个簇,其中包括6个线形簇(L1-L6),4个圆形簇(C1-C4),13个小簇(S1-S13),同时算法识别出17个孤立震中,表明该算法在无需用户提供初始聚类数目、初始聚类中心等参数的情况下能够发现任意形状(线形、圆形)、不同密度(如C1、C2)的簇,且能准确识别出噪声点。
地震震中通常沿着活跃断层发生[25],观测的震中位置一般沿着这些断层聚集起来。从图5可以看出:① 河西走廊地震带周边由北往南共计分布着8个簇,表明该地震带在过去十年之间非常活跃。其中7个簇为西南至东北方向,与河西走廊地震带的方向基本保持一致;② 滇西、腾冲廊沧地震带周边各分布着3个簇,表明其于过去十年之内较为活跃。其中L3、L4线形簇的方向为西北至东南,与滇西地震带的方向较为一致;③ 天水兰州、康定甘孜、西藏察隅、滇东地震带周边各分布着1个簇,意味该地震带在2008-2017年为一般活跃。其中L2簇与康定甘孜地震带的方向保持一致,均为西北至东南方向,天水兰州与西藏察隅地震带近十年发生的地震震中聚类结果不具有明显的方向性;④ 安宁河谷地震带在近10年没有发现带有聚集特征的地震震中簇发生,表明该地震带在近10年处于不活跃状态;⑤ 在康定甘孜与西藏察隅地震带之间分布着 1个线形簇与4个小簇,其中线形簇L6与S9、S10、S12的方向均为西北至东南方向,与康定甘孜、西藏察隅地震带的方向吻合得较好,具体原因有待进一步的调查研究。
本文提出了一种改进的最小生成树自适应空间点聚类算法,从整体到局部2个层次实现空间点的聚类,以期能够在无人工干预的影响下得到准确的聚类结果,通过与4种经典的聚类算法对比和实际应用后发现:① MSTAA算法具备良好的自适应特征,用户不需指定初始聚类数目、初始聚类中心、搜索邻域范围大小、“边长变化因子”,“边权值倍数容差”,降低用户使用聚类算法的知识储备要求;② 算法不仅能剔除宏观层面的噪声点,同时可以识别子树的局部噪声点,从而确保簇内点集的高度相似性;③ 在局部裁剪时,如果子树的边长近似于正态分布,那么MSTAA对于聚类敏感因子β的选取实际借用了统计学上的显著性概念,具有一定的数学 意义[26],但反之则聚类结果的准确性将受到影响;④ 算法能够进行不同密度、任意形状及任意聚类数目的聚类。
研究空间点群的聚类方法,不仅为知识发现、模式识别提供技术支持,还可以为数据挖掘的发展提供重要参考。本文主要是以点目标的空间位置进行研究,未涉及到其它属性信息,在后续的研究中,将考虑融合空间位置与其它非空间的属性数据,以便于发现更深层次的信息;同时,建立空间索引,提高算法的执行效率,降低算法的时间复杂度;扩大实验范围,将改进后的算法应用于中国传统村落的分类研究当中。
The authors have declared that no competing interests exist.
| [1] |
Evaluating the spatiotemporal clustering of traffic incidents [J].https://doi.org/10.1016/j.compenvurbsys.2012.06.004 URL [本文引用: 1] 摘要
This research presents both theoretical results regarding the nature of spatiotemporal clustering on a network, and applied outcomes from examining such clustering with regard to traffic incidents. The analysis considers fatal traffic incidents in eastern Fairfax County, Virginia and injury incidents in Franklin County, Ohio. The spatiotemporal analytical methods of Knox and subsequent researchers are reviewed. Specific methods for performing spatiotemporal analysis are outlined, with special attention given to the interpretation of the results for traffic incidents. An argument is made for conducting spatial and temporal cluster analyses independently, in addition to spatiotemporal cluster analysis, a comparative analysis of methods for testing for the significance of spatiotemporal clusters is presented, and suggestions for delineating critical parameters for the Knox statistic are provided.
|
| [2] |
|
| [3] |
|
| [4] |
Spatio-temporal interaction of urban crime [J].https://doi.org/10.1007/s10940-008-9047-5 URL [本文引用: 1] 摘要
Over the past decade, a renewed interest in the analysis of crime hot-spots has emerged in the social and behavioral sciences. Spurred by improvements in computing power, data visualization and geographic information systems, numerous innovative approaches have materialized for identifying areas of elevated crime in urban environments. Unfortunately, many hot-spot analysis techniques treat the spatial and temporal aspects of crime as distinct entities, thus ignoring the necessary interaction of space and time to produce criminal opportunities. The purpose of this paper is to explore the utility of statistical measures for identifying and comparing the spatio-temporal footprints of robbery, burglary and assault. Functional and visual comparisons for spatio-temporal clusters are analyzed across a range of space ime values using a comprehensive database of crime events for Cincinnati, Ohio. Empirical results suggest that robbery, burglary and assault have dramatically different spatio-temporal signatures.
|
| [5] |
Mining spatial-temporal clusters from geo-databases [J].https://doi.org/10.1007/11811305_29 URL [本文引用: 1] 摘要
In order to mine spatial-temporal clusters from geo-databases, two clustering methods with close relationships are proposed, which are both based on neighborhood searching strategy, and rely on the sorted k -dist graph to automatically specify their respective algorithm arguments. We declare the most distinguishing advantage of our clustering methods is they avoid calculating the spatial-temporal distance between patterns which is a tough job. Our methods are validated with the successful extraction of seismic sequence from seismic databases, which is a typical example of spatial emporal clusters.
|
| [6] |
一种基于似最小生成树的空间聚类算法 [J].A spatial clustering algorithm based on minimum spanning tree-like [J]. |
| [7] |
Some methods for classification and analysis of multivariate observations [C]. |
| [8] |
Clustering by passing messages between data points [J].https://doi.org/10.1126/science.1136800 URL [本文引用: 1] |
| [9] |
|
| [10] |
Cure: An efficient clustering algorithm for large databases [J].https://doi.org/10.1016/S0306-4379(01)00008-4 URL [本文引用: 1] 摘要
Clustering, in data mining, is useful for discovering groups and identifying interesting distributions in the underlying data. Traditional clustering algorithms either favor clusters with spherical shapes and similar sizes, or are very fragile in the presence of outliers. We propose a new clustering algorithm called CURE that is more robust to outliers, and identifies clusters having non-spherical shapes and wide variances in size. CURE achieves this by representing each cluster by a certain fixed number of points that are generated by selecting well scattered points from the cluster and then shrinking them toward the center of the cluster by a specified fraction. Having more than one representative point per cluster allows CURE to adjust well to the geometry of non-spherical shapes and the shrinking helps to dampen the effects of outliers. To handle large databases, CURE employs a combination of random sampling and partitioning. A random sample drawn from the data set is first partitioned and each partition is partially clustered. The partial clusters are then clustered in a second pass to yield the desired clusters. Our experimental results confirm that the quality of clusters produced by CURE is much better than those found by existing algorithms. Furthermore, they demonstrate that random sampling and partitioning enable CURE to not only outperform existing algorithms but also to scale well for large databases without sacrificing clustering quality.
|
| [11] |
A density-based algorithm for discovering clusters in large spatial databases with noise [C]. |
| [12] |
STING: A statistical information grid approach to spatial data mining [C]. |
| [13] |
一种带控制节点的最小生成树聚类方法 [J].https://doi.org/10.11834/jig.200208249 URL Magsci [本文引用: 1] 摘要
综合考虑对象间相对距离和高等级对象对低等级对象的集聚效应这两种聚类影响因素,提出了一种带控制节点的最小生成树聚类方法。该方法用聚类对象间距离为权构建一棵最小生成树,将树中高等级节点作为分割最小树时选取被打断边的控制因素,使本次分割而成的两子树都包含控制节点,且被打断的边是在此条件下的最长边,最终使每棵子树包含且仅包含一个控制节点。检验自构建数据和地震数据的聚类结果证明,该方法在某些情况下能够较好地揭示数据分布的真实规律。
A MST based clustering method with controlling vertexes [J].https://doi.org/10.11834/jig.200208249 URL Magsci [本文引用: 1] 摘要
综合考虑对象间相对距离和高等级对象对低等级对象的集聚效应这两种聚类影响因素,提出了一种带控制节点的最小生成树聚类方法。该方法用聚类对象间距离为权构建一棵最小生成树,将树中高等级节点作为分割最小树时选取被打断边的控制因素,使本次分割而成的两子树都包含控制节点,且被打断的边是在此条件下的最长边,最终使每棵子树包含且仅包含一个控制节点。检验自构建数据和地震数据的聚类结果证明,该方法在某些情况下能够较好地揭示数据分布的真实规律。
|
| [14] |
Minimum Spanning Tree based clustering algorithms [C]. |
| [15] |
一种最小生成树聚类算法 [J].
现有的聚类算法都不能在输入较少参数的情况下得到任意形状任意密度的类.提出一种最小生成树 的聚类算法,该算法不但能解决上述问题,还能处理高维数据,发现异常点,且具有扩展性.针对该算法提出一个目标函数,该函数根据对象的类属情况和相似度统 计信息来判别聚类效果的质量.最后,通过实验验证了该算法的聚类质量很好,目标函数具有良好的收敛性.
Minimum Spanning Tree clustering algorithm [J].
现有的聚类算法都不能在输入较少参数的情况下得到任意形状任意密度的类.提出一种最小生成树 的聚类算法,该算法不但能解决上述问题,还能处理高维数据,发现异常点,且具有扩展性.针对该算法提出一个目标函数,该函数根据对象的类属情况和相似度统 计信息来判别聚类效果的质量.最后,通过实验验证了该算法的聚类质量很好,目标函数具有良好的收敛性.
|
| [16] |
改进的最小生成树自适应分层聚类算法 [J].
针对传统最小生成树聚类算法需要事先知道聚类数目和使用静态全局分类依据,导致聚类密度相差较大时,算法有效性下降,计算复杂度大等问题,提出一种改进的最小生成树自适应分层聚类算法,根据最近邻关系,自动为每个聚类簇设定独立的阈值,使之适应分布密度相差较大的情况,并能自动确定聚类数目。实验表明,算法具有较好的性能,尤其对数据密度分布不均匀的情况也能得到较好的聚类结果。
Improved adaptive hierarchical clustering algorithm based on minimum spanning tree [J].
针对传统最小生成树聚类算法需要事先知道聚类数目和使用静态全局分类依据,导致聚类密度相差较大时,算法有效性下降,计算复杂度大等问题,提出一种改进的最小生成树自适应分层聚类算法,根据最近邻关系,自动为每个聚类簇设定独立的阈值,使之适应分布密度相差较大的情况,并能自动确定聚类数目。实验表明,算法具有较好的性能,尤其对数据密度分布不均匀的情况也能得到较好的聚类结果。
|
| [17] |
一种面向智能电网数据采集的传感器聚合布局构造算法 [J].https://doi.org/10.11999/JEIT150231 URL Magsci [本文引用: 1] 摘要
<p>智能电网中分布着大量的无线传感器用于监测智能电网设备和用户的运营状态信息,原始监测数据都采集到数据处理中心会给数据采集通信网络带来极大的数据流量压力。采用在数据采集过程中进行数据聚合的策略,将极大地缩减数据流量,降低通信网络的开销。因此聚合节点的选择以及聚合拓扑的构造成为智能电网数据采集的关键问题。该文提出一种基于层次聚类的异步分布式聚合布局构造算法。该算法首先按照层次聚类把所有节点按照距离的远近聚合构造出一棵采集树。随后计算出最佳分组数,按照该分组数进行分组。然后按照异步分布式策略进行最佳聚合节点的选择以及最佳传输拓扑的构造。仿真实验表明,该算法可以快速找到具有最小开销的数据聚合方式,提高智能电网数据采集网络的效率。</p>
Sensor aggregation distribution construction algorithm for smart grid data collection system [J].https://doi.org/10.11999/JEIT150231 URL Magsci [本文引用: 1] 摘要
<p>智能电网中分布着大量的无线传感器用于监测智能电网设备和用户的运营状态信息,原始监测数据都采集到数据处理中心会给数据采集通信网络带来极大的数据流量压力。采用在数据采集过程中进行数据聚合的策略,将极大地缩减数据流量,降低通信网络的开销。因此聚合节点的选择以及聚合拓扑的构造成为智能电网数据采集的关键问题。该文提出一种基于层次聚类的异步分布式聚合布局构造算法。该算法首先按照层次聚类把所有节点按照距离的远近聚合构造出一棵采集树。随后计算出最佳分组数,按照该分组数进行分组。然后按照异步分布式策略进行最佳聚合节点的选择以及最佳传输拓扑的构造。仿真实验表明,该算法可以快速找到具有最小开销的数据聚合方式,提高智能电网数据采集网络的效率。</p>
|
| [18] |
基于最小生成树的层次K-means聚类算法 [J].
针对K-means算法初始化时需要指定聚类数目,和随机选择初始聚类中心对聚类结果产生不稳定的问题,结合图论中最小生成树和层次算法的分裂、凝聚思想,提出一种基于最小生成树的层次K-means算法.该算法初始时根据数据样本生成一颗最小生成树,然后利用层次分裂思想把数据分成多个较小的簇,通过K-means算法迭代操作得到每次操作的评价函数值来判断是否进行簇的合并,进一步确定聚类簇数目.实验结果证明,该算法能够较准确地判断聚类数目,并且聚类结果的稳定性比基本K-means算法要好.
The level of K-means clustering algorithm based on the Minimum Spanning Tree [J].
针对K-means算法初始化时需要指定聚类数目,和随机选择初始聚类中心对聚类结果产生不稳定的问题,结合图论中最小生成树和层次算法的分裂、凝聚思想,提出一种基于最小生成树的层次K-means算法.该算法初始时根据数据样本生成一颗最小生成树,然后利用层次分裂思想把数据分成多个较小的簇,通过K-means算法迭代操作得到每次操作的评价函数值来判断是否进行簇的合并,进一步确定聚类簇数目.实验结果证明,该算法能够较准确地判断聚类数目,并且聚类结果的稳定性比基本K-means算法要好.
|
| [19] |
一种基于快速k-近邻的最小生成树离群检测方法 [J].A fast kNN-Based MST outlier detection method [J]. |
| [20] |
The psychology of the gestalt [J].https://doi.org/10.1037/h0070207 URL [本文引用: 1] 摘要
Abstract The Gestalt theory as given is, very briefly, that psychology should be the study of whole processes and their interactions, which we experience, rather than of simple sensations and other artificial units which we never experience. Thus is established a new kind of psychological unit, one which further division alters, though artificially it may be subdivided. Wertheimer, K hler, and Koffma are named as the chief exponents of the system which Humphrey estimates to be of established though unmeasured value. The Gestalt theory springs directly from experimental work and has proved very fruitful in presenting hypotheses for further experimentation. In educational psychology it promises to throw light on such problems as reading, transfer of training, maze learning, etc. It has already aroused considerable speculation in the general theory. Humphrey gives a thorough, brief criticism which is worth reading. From Psych Bulletin 22:07:00540. (PsycINFO Database Record (c) 2012 APA, all rights reserved)
|
| [21] |
An adaptive spatial clustering algorithm based on delaunay triangulation [J].https://doi.org/10.1016/j.compenvurbsys.2011.02.003 URL [本文引用: 2] 摘要
In this paper, an adaptive spatial clustering algorithm based on Delaunay triangulation (ASCDT for short) is proposed. The ASCDT algorithm employs both statistical features of the edges of Delaunay triangulation and a novel spatial proximity definition based upon Delaunay triangulation to detect spatial clusters. Normally, this algorithm can automatically discover clusters of complicated shapes, and non-homogeneous densities in a spatial database, without the need to set parameters or prior knowledge. The user can also modify the parameter to fit with special applications. In addition, the algorithm is robust to noise. Experiments on both simulated and real-world spatial databases (i.e. an earthquake dataset in China) are utilized to demonstrate the effectiveness and advantages of the ASCDT algorithm.
|
| [22] |
Delaunay三角网构建方法比较研究 [J].https://doi.org/10.11834/jig.20100804 URL Magsci [本文引用: 1] 摘要
Delaunay三角网构建是3维场景可视化领域的一个热点也是难点问题。归纳总结了现有Delaunay三角网构建研究中的3类方法――逐点插入法、三角网生长法和分治法,以及在各自原理框架下的不同实现算法;比较分析了3种不同方法的优缺点和各自代表性算法的时间复杂度,并详细讨论了Delaunay三角网构建方法在大规模场景渲染和地形可视化领域中未来3个研究方向:混合算法研究、算法支撑技术研究和分布式并行算法研究。
A comparative research on methods of Delaunay triangulation [J].https://doi.org/10.11834/jig.20100804 URL Magsci [本文引用: 1] 摘要
Delaunay三角网构建是3维场景可视化领域的一个热点也是难点问题。归纳总结了现有Delaunay三角网构建研究中的3类方法――逐点插入法、三角网生长法和分治法,以及在各自原理框架下的不同实现算法;比较分析了3种不同方法的优缺点和各自代表性算法的时间复杂度,并详细讨论了Delaunay三角网构建方法在大规模场景渲染和地形可视化领域中未来3个研究方向:混合算法研究、算法支撑技术研究和分布式并行算法研究。
|
| [23] |
On the history of the minimum Sspanning tree problem [J].https://doi.org/10.1109/MAHC.1985.10011 URL [本文引用: 1] |
| [24] |
Clustering algorithms based on minimum and maximum spanning trees [C]. |
| [25] |
A Distribution-Based clustering algorithm for mining in large spatial databases [C]. |
| [26] |
Graph-theoretical methods for detecting and describing gestalt clusters [J].https://doi.org/10.1109/T-C.1971.223083 URL [本文引用: 1] 摘要
A family of graph-theoretical algorithms based on the minimal spanning tree are capable of detecting several kinds of cluster structure in arbitrary point sets; description of the detected clusters is possible in some cases by extensions of the method. Development of these clustering algorithms was based on examples from two-dimensional space because we wanted to copy the human perception of gestalts or point groupings. On the other hand, all the methods considered apply to higher dimensional spaces and even to general metric spaces. Advantages of these methods include determinacy, easy interpretation of the resulting clusters, conformity to gestalt principles of perceptual organization, and invariance of results under monotone transformations of interpoint distance. Brief discussion is made of the application of cluster detection to taxonomy and the selection of good feature spaces for pattern recognition. Detailed analyses of several planar cluster detection problems are illustrated by text and figures. The well-known Fisher iris data, in four-dimensional space, have been analyzed by these methods also. PL/1 programs to implement the minimal spanning tree methods have been fully debugged.
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}