汪伟 , 陶海燕, 卓莉, 李敏, 李旭亮, 汪珂丽, 史清丽
, 陶海燕, 卓莉, 李敏, 李旭亮, 汪珂丽, 史清丽
中山大学地理科学与规划学院 广东省城市化与地理环境空间模拟重点实验室/综合地理信息研究中心, 广州 510275
WANG Wei, TAO Haiyan, ZHUO Li, LI Min, LI Xuliang, WANG Keli, SHI Qingli
通讯作者:
收稿日期: 2017-09-17
修回日期: 2018-01-22
网络出版日期: 2018-07-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:汪 伟(1996-),男,安徽安庆人,本科生,主要从事时空数据挖掘。E-mail: wangw227@mail2.sysu.edu.cn
展开
摘要
随着公众移动通信的快速发展,伪基站的泛滥不仅破坏正常电信秩序,危害公共安全,而且严重损害群众财产权益,侵犯公民个人隐私,已成为社会一大公害。如何从垃圾短信大数据中挖掘出伪基站活动的时空规律,寻找有效的防控方案,从源头上进行打击和治理成为管理部门和研究者共同关注的焦点。本文基于北京市垃圾短信数据,利用非负矩阵分解的方法分析伪基站的时空分布规律;并利用TF-IDF构建垃圾短信分类模型,对垃圾短信进行分类,结合土地利用数据,分析伪基站在发送不同类型垃圾短信时的时空分布规律。结果显示:北京市垃圾短信多分布于路网和中心城区;白天垃圾短信数量远远多于晚上;垃圾短信的分布随时间的推移沿着路网逐渐向内收缩;发送不同类型垃圾短信的伪基站的时空分布具有一定的差异;通过非负矩阵分解得到的结果,与垃圾短信分类后得到的结果有很好的匹配。研究表明,非负矩阵分解具有实现上的简便性、分解形式和分解结果上的可解释性等优点,可以有针对性的为有关部门建言打击伪基站的有效方案,对于伪基站违法行为的治理具有一定的意义。
关键词:
Abstract
The rampant pseudo base stations have become a major public hazard. They undermine the normal telecommunications order, endanger public safety, seriously infringe the property rights of the masses, and violate citizen privacy. How to dig out the spatio-temporal patterns of the pseudo base stations’ activities from massive spam messages, design effective prevention and control programs, and fight against the crime from the source, has become the focus of government agencies and researchers. The traditional methods for identifying pseudo base stations through the user terminal, however, face great challenges in terms of accuracy, comprehensiveness, and analytical ability, which no longer meet the requirements of identifying small-scale and mobile pseudo base stations. Utilizing data on the spam messages from February 23rd, 2017 to April 26th, 2017 in Beijing, this paper analyzes the spatio-temporal distribution of pseudo base stations through non-negative matrix factorization. We also constructed a classification model through TF-IDF (Term Frequency-Inverse Document Frequency) which compares types from different classifiers (k-Nearest Neighbors / K-Support Vector Machine /Random Forest/ Single-Layer Neural Network) and selects the most accurate random forest classification method. Combined with the land use data, we analyzed the spatio-temporal distribution of pseudo base stations that send different types of spam messages. The results of non-negative matrix factorization and spam message classification were analyzed in detail. The results show that most of the spam messages in Beijing are sent along the road network and in the central city. The number of spam messages during the day is much more than that during the evening. As time goes by in the day, the distribution of spam messages along the road network gradually shrinks inward. The pseudo base stations that send different types of spam messages differ in the spatio-temporal distribution, but all of them favor the traffic facilities and residential area within the Fourth Ring. The non-negative matrix factorization, which provides reliable results that match with traditional spam message classification, has shown simplicity in performing the analysis and interpretability in the form and result of the decomposition. It can help understand the spatio-temporal patterns of different types of spam messages and provide evident-based suggestions for government agencies to fight against the pseudo base stations effectively. By targeting the source of the spam messages, it is also beneficial for governments to combat the illegal behaviors based on pseudo base stations.
Keywords:
伪基站是由无线电收发设备和笔记本电脑组成的一种移动无线电通讯设备,能够搜集一定半径范围内的手机卡信息,利用GSM(Global System for Mobile Communication)验证漏洞伪装成运营商的基站,冒用银行、运营商、国家机关或他人号码,强行向用户发送诈骗、色情、赌博、广告等垃圾短信[1]。非法伪基站的出现不仅破坏正常电信秩序,危害公共安全,而且严重侵害群众财产权益,侵犯公民个人隐私,已成为社会一大公害。
随着伪基站设备的多样化,传统的伪基站排查识别手段在准确性、全面性、分析能力等方面遇到较大挑战,已不能满足小型化、易移动伪基站的排查识别要求[2]。伪基站有非常强的流动性,依据近似位置和传统数据分析方法,很难准确把握伪基站的活动规律,而且单独地从时间或者空间维度加以讨论,也往往会忽略时空的交互性,无法得到全面、有价值的结论。
目前伪基站防控的研究重点,是根据伪基站发送的短信内容,通过各种文本识别算法,对短信进行识别、分类,从而构建用户端的垃圾短信过滤系统。垃圾短信过滤方法主要有:安全认证法、基于统计的方法和基于规则的方法[3]3大类:①安全认证法主要通过客户端设置黑、白名单、关键字等过滤条件达到过滤效果;②基于统计的方法则是从统计学的角度探究垃圾短信的规律从而确定规则达到过滤目的。如竺吴辉等[4]基于某省的2000多万条短信记录,根据出入比、有效交互周期等特征建立垃圾短信的过滤算法。该算法针对垃圾短信的查全率达到99.51%,查准率为49.90%;③基于规则的方法则是通过文本识别算法构建过滤系统,主要使用的算法有SVM算法、KNN算法、贝叶斯分类方法等。如邓维维等[5]根据短信分词特征利用贝叶斯分类方法设计出一种移动环境下的垃圾短信过滤系统,综合考虑规则和长度信息,利用互信息减小单词属性的个数。颜世莹[6]则基于行为和内容协作分析,构建垃圾短信过滤系统。徐英慧等[7]基于统计学习理论,根据短信内容提出手机端的垃圾短信过滤策略。目前,国内鲜有学者从源头上研究和分析伪基站的时空分布规律。
传统的从客户端对垃圾短信进行过滤拦截这种被动式的治理,缺乏对伪基站移动规律的基本认知,无法从源头上对此类违法行为进行主动式防治。本文拟利用手机卫士应用软件收集的北京市垃圾短信样本数据,首先,利用非负矩阵分解得到伪基站总体时空规律;再基于TF-IDF(Term Frequency-Inverse Document Frequency)构建垃圾短信分类模型,根据垃圾短信的文本内容对其进行分类;然后,利用非负矩阵分解结果与分类结果分析伪基站发送不同类型垃圾短信的时空分布规律以及伪基站的行为模式,为有效的打击伪基站的违法行为提供科学的决策依据。
本研究所使用的垃圾短信数据是来自QHNet公司的手机卫士应用软件收集的北京市被标记为垃圾短信的样本数据,时间跨度为2个月,从2017年2月23日到2017年4月26日,经过预处理后,共有3 341 678条记录。样本数据包含伪基站伪装的发送方电话号码、短信具体正文、垃圾短信接收时间戳、与伪基站的连接时间戳、伪基站发送此条短信时的近似位置经度和纬度等共7个字段,具体字段名称与含义如表1所示。
表1 原始数据字段名称与含义
Tab. 1 The field name and definition of the raw data
| 字段名称 | 字段含义 |
|---|---|
| phone | 伪基站伪装的发送方电话号码 |
| content | 短信具体正文 |
| md5 | 短信正文MD5 |
| recitime | 垃圾短信接收时间戳 |
| conntime | 与伪基站的连接时间戳 |
| lng | 伪基站发送短信时的近似位置经度 |
| lat | 伪基站发送短信时的近似位置纬度 |
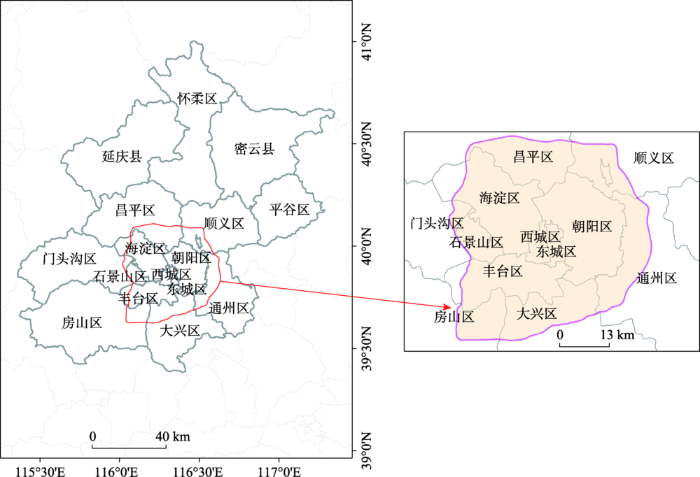
经分析,原始垃圾短信的97%分布在北京六环以内,而北京六环内的面积只占整个北京的14%,因此,本文将北京六环以内区域作为研究区,如图1所示。
传统的矩阵分解方法,例如主成分分析(PCA)、独立成分分析(ICA)、奇异值分析(SVD)等,其共同的缺点是分解后结果会出现负值,虽然从理论上分析其结果是正确的,但是在实际应用研究中无论是时间分量还是空间分量,负数均没有实际意义。
非负矩阵分解算法(Non-negative Matrix Factorization,NMF)是Lee和Seung的研究成果[8],为处理大规模数据提供一种新的途径,具有实现上的简便性、分解形式和分解结果的可解释性,以及占用存储空间少等诸多优点[9],可使数据的某种潜在结构变得清晰。其基本思想如下:
假设处理n个m维空间的样本数据,用矩阵
NMF将一个非负矩阵分解成2个非负矩阵的乘积,
式中:
NMF基于向量组合的形式具有很直观的解释,可以得到原始数据的潜在结构规律。该算法得到的基非负向量组
在现有研究[12]的基础上,将垃圾短信分为欺诈(银行名义、运营商名义、其他)、非法广告(违禁物品买卖、色情服务类、办假证假发票类)、骚扰(恶意骚扰、轻度打扰)和普通广告(房产中介类、金融理财类、其他广告)共4大类11小类,具体分类标准如表2所示。
表2 垃圾短信分类
Tab. 2 The classification of spam messages
| 大类名称 | 大类编号 | 小类名称 | 小类编号 |
|---|---|---|---|
| 欺诈类 | 1 | 银行名义 | 1 |
| 运营商名义 | 2 | ||
| 其他 | 3 | ||
| 非法广告 | 2 | 违禁物品买卖 | 4 |
| 色情服务类 | 5 | ||
| 办假证假发票类 | 6 | ||
| 骚扰 | 3 | 恶意骚扰 | 7 |
| 轻度打扰 | 8 | ||
| 普通广告 | 4 | 房产中介类 | 9 |
| 金融理财 | 10 | ||
| 其他广告 | 11 |
本研究首先使用R语言的Rwordseg包对训练集中短信文本进行分词,去掉标点符号、停用词、助词等得到词条4858个。根据IT-IDF确定单词的权重,提取短信文本的特征。根据特征使用分类器对测试集中短信进行分类。
其中,TF-IDF是一种关键词自动提取算法,在计算词语的权值中应用较多且效果较好[13,14],其主要的思想是某个词或词组的TF 值在一个文档中高并且在其他文档中较小,那么就认为该词或者词组的类别区分能力强,和其他的词或词组相比,其更适宜用于分类[15]。词频TF(Term Frequency )表示某一给定的词语i在文档d中出现的次数。反文档频率IDF(Inverse Document Frequency)是一个词或者词组的普遍重要性的度量。常用的计算公式如(3)、(4)所示[14]:
式中:t表示特征词在文档e中出现的次数;s表示文档e在出现的总词条数目。
式中:D表示总文档数目;d表示包含特征词的文档总数。
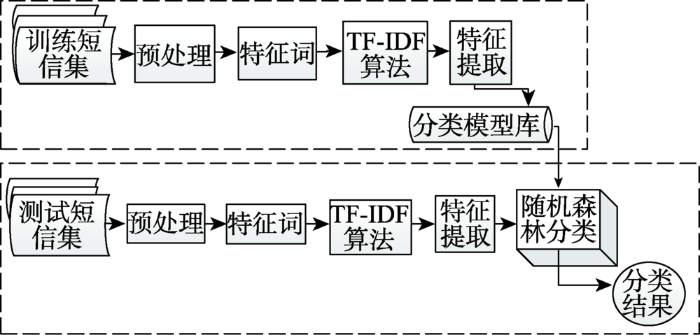
模型分类流程如图2所示。所有实验采用五分交叉验证,即把数据集随机划分成5份,每次取其中4份进行训练,剩下1份进行测试,然后把5次分类结果的平均值作为结果,再整体迭代5次取平均值作为最终结果。本研究使用KNN(k=1)(k-Nearest Neighbors)、线性k-SVM(K- Support Vector Machine)、随机森林RF(Random Forest)和单层神经网络nnet(Single-Layer Neural Network)4种分类器[16,17,18,19,20],得到11类短信分类结果的正确率p、召回率r、F1,并将准确率、kappa系数和p值作为整体评价指标,如表3与表4所示。通过比较不同分类器的分类精度,本研究最终选用了模型准确率95%和kappa系数93%的RF模型构建分类器进行分类。
表3 分类结果及精度
Tab. 3 The classification result and its accuracy
| 分类器 | 指标 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RF | p | 0.98 | 0.95 | 0.12 | 1 | 0.98 | 0.99 | 0.98 | 0.5 | 0.97 | 0.98 | 0.91 | 0.85 |
| r | 1 | 0.77 | 0.06 | 0.69 | 0.91 | 0.99 | 0.85 | 0.98 | 0.96 | 0.93 | 0.69 | 0.8 | |
| F1 | 0.99 | 0.84 | 0.08 | 0.8 | 0.94 | 0.99 | 0.91 | 0.66 | 0.97 | 0.96 | 0.78 | 0.81 | |
| KNN | p | 0.99 | 0.9 | 0.58 | 0.83 | 0.99 | 0.98 | 0.96 | 0.16 | 1 | 0.95 | 0.99 | 0.85 |
| r | 0.98 | 0.51 | 0.3 | 0.27 | 0.88 | 0.98 | 0.7 | 0.67 | 0.73 | 0.68 | 0.36 | 0.64 | |
| F1 | 0.98 | 0.65 | 0.39 | 0.39 | 0.93 | 0.98 | 0.8 | 0.25 | 0.84 | 0.79 | 0.52 | 0.69 | |
| KSVM-linear | p | 0.99 | 0.92 | 0.52 | 0.99 | 0.98 | 0.98 | 1 | 0.41 | 0.98 | 0.99 | 0.89 | 0.88 |
| r | 1 | 0.83 | 0.3 | 0.73 | 0.91 | 1 | 0.85 | 0.74 | 0.96 | 0.94 | 0.61 | 0.81 | |
| F1 | 1 | 0.86 | 0.37 | 0.83 | 0.94 | 0.99 | 0.92 | 0.52 | 0.97 | 0.96 | 0.72 | 0.83 | |
| nnet | p | 0.98 | 0.77 | 0.13 | 0.87 | 0.92 | 0.98 | 0.96 | 0.49 | 0.91 | 0.94 | 0.87 | 0.8 |
| r | 0.99 | 0.79 | 0.1 | 0.68 | 0.89 | 0.99 | 0.89 | 0.59 | 0.97 | 0.95 | 0.6 | 0.77 | |
| F1 | 0.99 | 0.77 | 0.11 | 0.74 | 0.9 | 0.99 | 0.92 | 0.47 | 0.94 | 0.94 | 0.7 | 0.77 |
表4 分类评价指标精度
Tab. 4 The accuracy index of the classification
| RF | KNN | KSVM-linear | nnet | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 准确率 | Kappa | P值 | 准确率 | Kappa | P值 | 准确率 | Kappa | P值 | 准确率 | Kappa | P值 | |||
| 0.95 | 0.93 | 0 | 0.86 | 0.82 | 0 | 0.94 | 0.92 | 0 | 0.93 | 0.91 | 0 | |||
图2 垃圾短信分类模型流程图
Fig. 2 The flow chart for the spam messages classification model
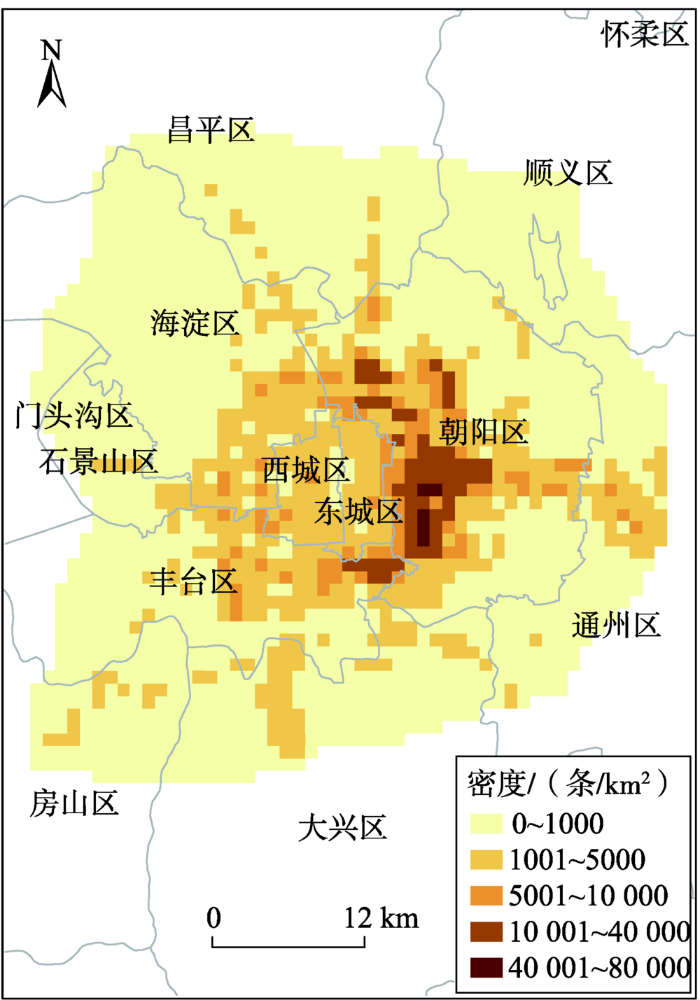
根据预处理后每条短信记录所代表的伪基站近似经纬度,计算北京六环内每个网格的垃圾短信发送量,生成垃圾短信分布密度图,如图3所示。从图中可以看出,伪基站主要集中在中心城区,距中心城区越远,伪基站分布越稀疏,其中朝阳区西部伪基站分布密度最大。密度较高的地区有沿着路网分布的趋势,四环路、京通快速公路、京开高速等公路覆盖区短信密度均较高,一定程度上说明垃圾短信较多是利用车载伪基站进行发送的。
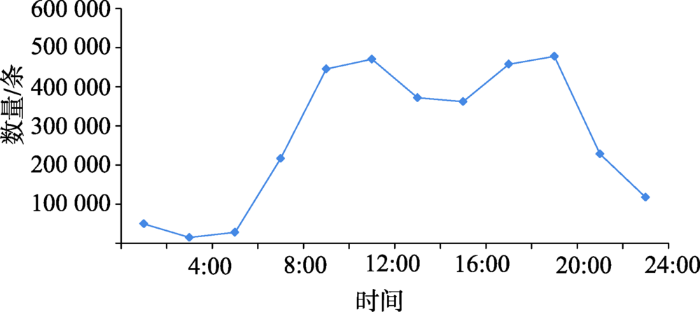
将一天划分成12个时间段,统计每个时间段的短信数量,得到如图4所示的垃圾短信随时间的分布图。从图4可以看出,从第一天晚上20:00到第二天8:00,是垃圾短信发送最少的几个时间段。从 8:00-20:00,垃圾短信的数量都比较多,尤其在 8:00-12:00与16:00-20:00,垃圾短信的数量最多。这也比较符合人们作息的实际情况。
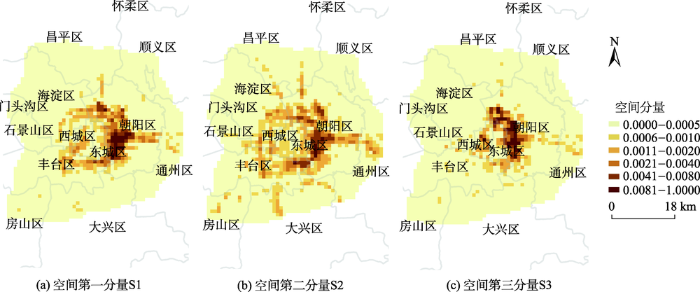
非负矩阵分解结果的时间分量如图5所示,其中,横轴表示时间,纵轴表示对应时间的概率p,对应的空间分量如图6所示。从时间分量看,r=3时可以将一天分出3个不同的时间段,分别对应工作、傍晚、夜间模式。从不同时间分量分析对应的空间分量的分布情况:T2对应的S2,是工作模式(6:00- 16:00)下对应的垃圾短信分布情况,可以看出此时垃圾短信是沿着路网分布的,四环路是分布密度最高的区域,在北京-拉萨高速公路、京通快速公路、北京-塘沽公路、京开高速等公路均分布较多。因东城区与朝阳区西靠近北京商务中心区,人流量较大,这些区域的垃圾短信密度最高;T1对应的S1,表示的是傍晚模式(16:00-20:00)下的分布情况,与之前的分布相比,短信分布更加集中,沿着四环路的内部密度更高,而外部沿着路网的分布更少,即呈现向内收缩的趋势。T3对应的S3,表示的是夜间模式(20:00-24:00, 0:00-2:00)下的短信分布情况,垃圾短信数量明显下降,主要分布在朝阳区西以及四环路附近区域。
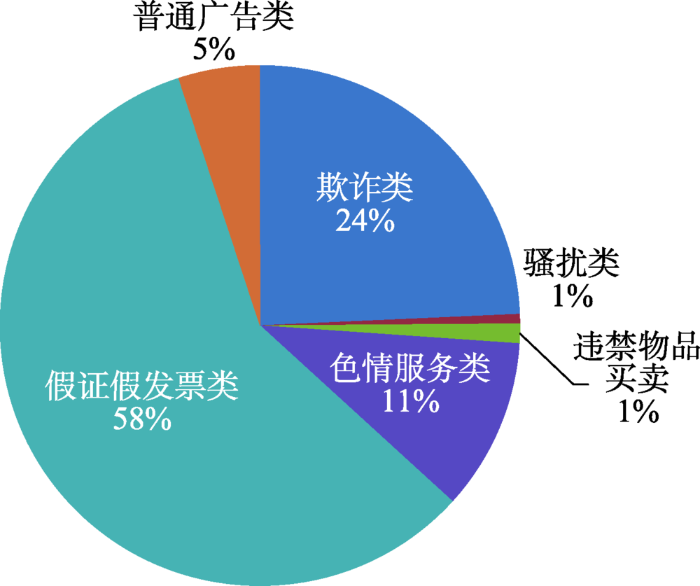
考虑到不同类型短信的数量差异较大,本研究仅仅针对数量较多的假证假发票类、欺诈类、色情服务类、普通广告类、违禁物品买卖类以及骚扰类这6类垃圾短信,其比例分布如图7所示。其中,假证假发票类信息数最多,占总数的58.1%;其次是欺诈类和色情服务类,分别占比24.2%和10.0%。这3类占整个垃圾短信的92.3%。另外,普通广告类占总数的6.0%;违禁物品买卖类占总数的1.2%;骚扰类占总数的0.5%。这3类共计只占整个垃圾短信的7.7%。
(1)不同类型垃圾短信的空间分布特征
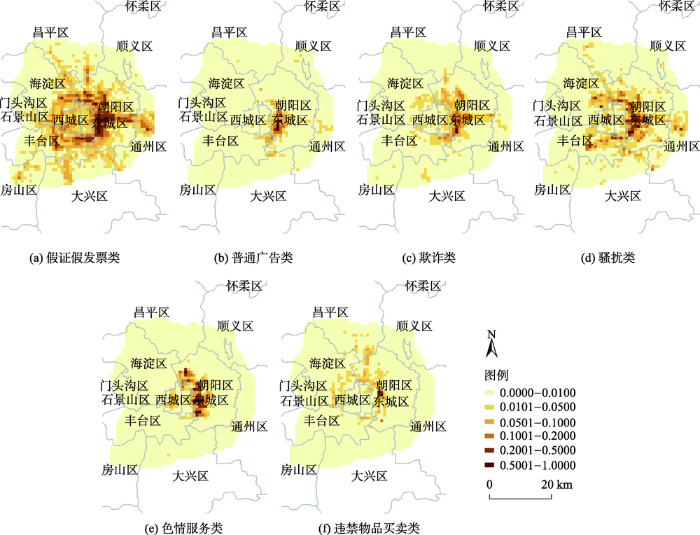
每种类型短信空间分布特征(图8)不同。各种类型的垃圾短信都是在中心城区的密度最大,有沿着路网向外分布的趋势。其中,朝阳区西和西城区是密度最大的区域。
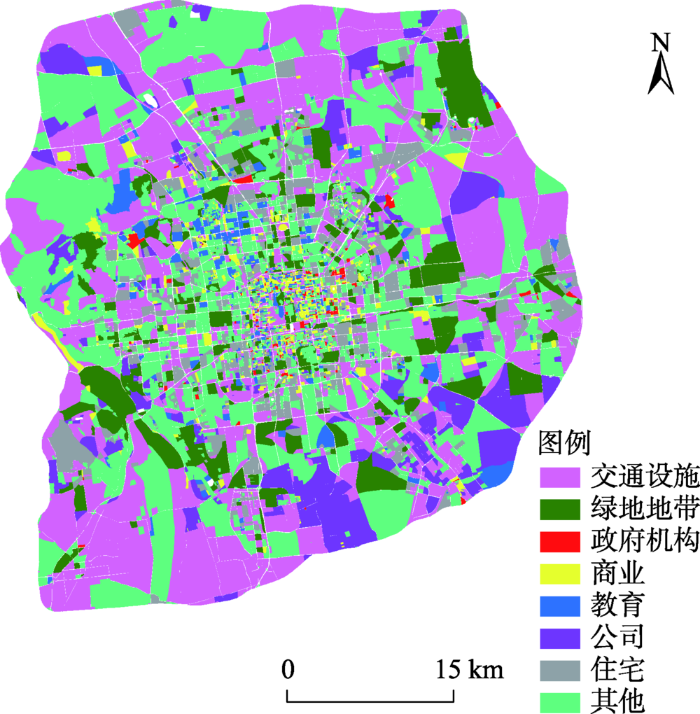
利用北京六环内土地利用数据[21]来探究不同类型的垃圾短信在空间分布特征不完全相同的原因,数据主要包括交通设施、绿色地带、政府机构、商业用地、教育用地、公司、住宅以及其他共8类土地利用信息(图9)。试图解释不同类型垃圾短信空间分布的成因。
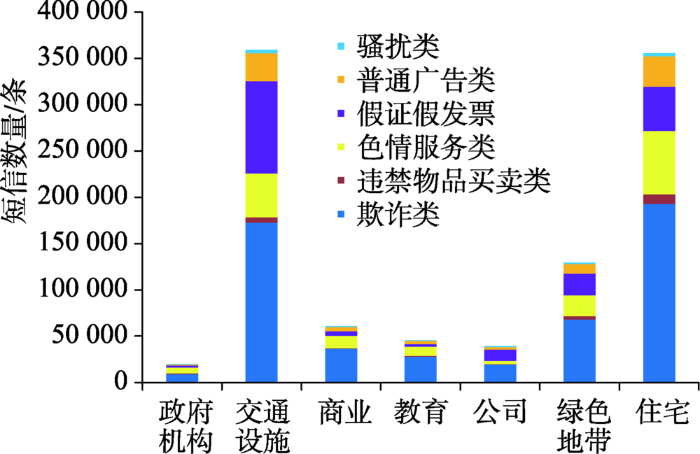
从各土地利用类型中各类垃圾短信数量上可以看出(图10),伪基站偏好在交通设施与住宅区发送垃圾短信,在这两种用地类型中,欺诈类与假证假发票类垃圾短信占最大的比例,色情服务也占较大的一部分。另外,可以看出在政府机构,垃圾短信的发送数量是最少的,一定程度上说明伪基站更加惧怕在此类型的用地发送垃圾短信。
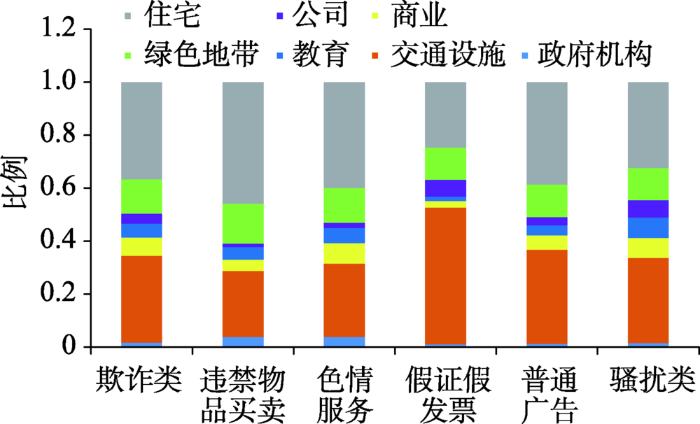
从各土地利用类型中各类垃圾短信发送比例来看(图11),欺诈类、色情服务类及普通广告3类在各功能区发送比例基本相似,即大约30%的短信来源于交通设施地区,40%左右的短信在住宅区发送。违禁物品类短信在住宅发送量较高,而假证假发票类短信更偏爱在交通设施的地方发送,骚扰类在交通设施与住宅发送量基本持平。
图11 各类型垃圾短信发送地区统计
Fig. 11 The sending area statistics by types of spam messages
(2)不同类型垃圾短信的时间分布特征
不同类型垃圾短信随时间分布如图12所示,根据曲线的形状,将6类垃圾短信大致分成4类:第1类是假证假发票类,每天有2个峰值(8:00-10:00与18:00-20:00),在从早上6:00到晚上20:00的时间段内均有较高的分布;第2类是欺诈类,主要集中在每天的10:00至20:00,虽然数量比假证假发票类要少,但是也占有很大的一部分比例;第3类是色情服务类,主要集中在每天的20:00-24:00与0:00-2:00;剩下的是第4类,这类短信数量相对其他的较少,主要集中在每天的10:00-20:00。
(3)不同类型垃圾短信的时空分布特征
针对不同类型垃圾短信的时空分布情况,探究每类垃圾短信的时空规律。对于假证假发票类,主要集中在每天的6:00-20:00,在中心城区密度最大,沿着路网向外扩散。该类短信更偏向于在交通设施区发送;对于骚扰类,主要集中在每天的10:00-20:00沿着四环线分布。在交通设施与住宅区发送最多;对于欺诈类,主要集中在10:00-20:00城中心及周边地区。大约30%的短信来源于交通设施地区,40%左右的短信在住宅区发送;对于色情服务类,主要集中在每天的20:00-24:00与0:00-2:00的朝阳区西部以及西城区。大约30%的短信来源于交通设施地区,40%左右的短信在住宅区发送;对于违禁物品类,主要集中在每天的10:00-20:00沿着四环线分布。多在住宅区发送此类短信;对于普通广告类,主要集中在10:00-20:00朝阳区西部。大约30%的短信来源于交通设施地区,40%左右的短信在住宅区发送。
(4)结合非负矩阵分解结果分析
对比图5所示的非负矩阵分解时间分量与图12 所示的不同类型短信随时间分布图,可以发现,T1、T2主要由假证假发票类贡献而来,假证假发票类的两个峰值8:00-10:00和18:00-20:00与T1、T2对应,在这段时间,其他类型短信的数量很少(含有部分的欺诈类);同理,可以看出T3主要由色情服务类贡献而来。
因此,非负矩阵分解得到的T1、T2以及对应的S1、S2,主要是假证假发票类的时空分布(包含小部分的欺诈类)。T3以及对应的S3,主要是色情服务类的时空分布特征。本研究非负矩阵分解的结果是在3个时间模式下的空间分布,即是在该时间段对应的垃圾短信类型的空间分布,也就是说,非负矩阵分解得到的结果与IT-IDF分类模型得到的结果能够很好的结合与匹配。
本文以北京2个月的垃圾短信为例,首先构建时间乘以空间矩阵,利用非负矩阵分解分别得到时间与空间维度的分量;再通过IT-IDF提取短信文本的特征,利用随机森林算法对垃圾短信进行分类;对非负矩阵分解结果与垃圾短信分类结果进行具体分析。
研究发现,伪基站在空间上主要沿着路网发送垃圾短信,且越靠近北京中心城区,伪基站分布越密集。从时间上看,垃圾短信主要集中在白天 8:00-20:00发送,晚上发送量较少。从空间上看,伪基站每天随着时间的推移沿着路网逐渐向内收缩;从不同类型垃圾短信来看,假证假发票类、欺诈类、色情服务类、普通广告类、违禁物品买卖类以及骚扰类这六类垃圾短信的时空特征均不相同。但是在空间上都偏向于在四环内的交通设施与住宅区发送,时间上则主要分布在每天的0:00-18:00。在这两种用地类型中,欺诈类与假证假发票类垃圾短信占最大的比例,色情服务也占较大的一部分。在政府机构,垃圾短信的发送数量是最少的,一定程度上说明伪基站更加惧怕在此类型的用地发送垃圾短信。从分类结果与非负矩阵分解结果结合来看,得到的非负矩阵的曲线T1、T2主要是假证假发票类,S1、S2可以看作主要是假证假发票类的分布。T3主要是色情服务类,S3可以看作主要是色情服务类的分布。了解每种类型的垃圾短信时空规律后,有关部门可以有针对性的制定政策从源头上打击发送某种垃圾短信的行为。
伪基站使用者会根据发送短信的内容选择合适的目标人群,并结合目标人群活动规律,城市交通状况,警方打击形势等选择合适的时间和位置发送相应的短信。从伪基站的移动发送垃圾短信过程中发现其行为规律面临海量数据、空间、时间、类型等多因素的综合作用以及因素之间复杂依赖、随机噪声大等巨大挑战。同时,通过大数据挖掘得到的特征和规律,难以进行定量化的验证,今后拟通过多源数据的集成开展进一步研究。
The authors have declared that no competing interests exist.
| [1] |
使用伪基站群发短信的司法认定 [J].
近年来,手机的普及在给人们生活带来便捷的同时,也为伪基站违法犯罪活动创造了有利条件,电信诈骗、虚假广告、非法经营等违法犯罪行为频发。据奇虎360发布的《2016年第一季度伪基站短信治理报告》显示:
Judicial recognition of sending short messages using pseudo base stations [J].
近年来,手机的普及在给人们生活带来便捷的同时,也为伪基站违法犯罪活动创造了有利条件,电信诈骗、虚假广告、非法经营等违法犯罪行为频发。据奇虎360发布的《2016年第一季度伪基站短信治理报告》显示:
|
| [2] |
Lin-Zhou X U, Shi Z F, et al. A method for illegal pseudo base station site fast measuring and positioning [J]. |
| [3] |
基于内容的垃圾短信过滤 [J].https://doi.org/10.3969/j.issn.1000-3428.2008.12.054 URL Magsci [本文引用: 1] 摘要
研究一种基于最小风险贝叶斯决策的垃圾短信过滤方法。对于以文本信息为主的短信,采用信息增益的方法进行特征选择,使用基于最小风险贝叶斯决策方法进行分类。通过自建短信语料库对该方法进行了实验。实验结果表明,该方法能够准确地对短信进行分类,降低合法短信的分类错误率,分类正确率达到99.3%,符合了短信分类要求。 <BR><BR>
Junk SMS filtering based on context [J].https://doi.org/10.3969/j.issn.1000-3428.2008.12.054 URL Magsci [本文引用: 1] 摘要
研究一种基于最小风险贝叶斯决策的垃圾短信过滤方法。对于以文本信息为主的短信,采用信息增益的方法进行特征选择,使用基于最小风险贝叶斯决策方法进行分类。通过自建短信语料库对该方法进行了实验。实验结果表明,该方法能够准确地对短信进行分类,降低合法短信的分类错误率,分类正确率达到99.3%,符合了短信分类要求。 <BR><BR>
|
| [4] |
基于短信发送模式的垃圾号码过滤算法 [J].https://doi.org/10.3724/SP.J.1087.2012.03565 URL Magsci [本文引用: 1] 摘要
在一个垃圾短信泛滥的时代,清除垃圾短信将耗费大量的时间和精力,挖掘垃圾短信的发送特征是解决这一问题的关键。在分析现有的短信过滤机制(算法)的基础上,根据中值滤波的思想,将短信发送者离散的交互单元合并成一个连续的交互单元,进而提出有效交互周期的概念,以入出比、有效交互周期等特征建立垃圾短信的综合过滤算法。通过对2000万条真实短信记录进行实验,统计得到过滤算法针对垃圾短信的查全率达到99.51%,查准率为49.90%。实验结果表明,算法提高了垃圾短信检测的效率和速度,可适用于垃圾短信实时拦截技术。
Span phone number method based on SMS sumission pattern [J].https://doi.org/10.3724/SP.J.1087.2012.03565 URL Magsci [本文引用: 1] 摘要
在一个垃圾短信泛滥的时代,清除垃圾短信将耗费大量的时间和精力,挖掘垃圾短信的发送特征是解决这一问题的关键。在分析现有的短信过滤机制(算法)的基础上,根据中值滤波的思想,将短信发送者离散的交互单元合并成一个连续的交互单元,进而提出有效交互周期的概念,以入出比、有效交互周期等特征建立垃圾短信的综合过滤算法。通过对2000万条真实短信记录进行实验,统计得到过滤算法针对垃圾短信的查全率达到99.51%,查准率为49.90%。实验结果表明,算法提高了垃圾短信检测的效率和速度,可适用于垃圾短信实时拦截技术。
|
| [5] |
移动环境下的垃圾短信过滤系统的研究 [J].
提出了一种分布式的垃圾短信过滤系统,它适合于移动网络,具有自学习能力,能够及时发现垃圾信息源,有效的过滤垃圾短信。在传统以词为属性的贝叶斯过滤算法的基础上,加入了规则和长度信息,利用互信息减小单词属性的个数。实验表明,它在短信过滤方面具有空间占用小和性能更好的特点,适合在移动电话上使用。同时还提出了一种垃圾短信发送者的可能性排名的方法。
Research on junk SMS filtering system on mobile environment [J].
提出了一种分布式的垃圾短信过滤系统,它适合于移动网络,具有自学习能力,能够及时发现垃圾信息源,有效的过滤垃圾短信。在传统以词为属性的贝叶斯过滤算法的基础上,加入了规则和长度信息,利用互信息减小单词属性的个数。实验表明,它在短信过滤方面具有空间占用小和性能更好的特点,适合在移动电话上使用。同时还提出了一种垃圾短信发送者的可能性排名的方法。
|
| [6] |
基于行为和内容协作分析的垃圾短信过滤系统 [J].https://doi.org/10.3969/j.issn.1008-5599.2011.09.012 URL [本文引用: 1] 摘要
随着移动网络的发展,垃圾短信已经成为亟需解决的重要课题.当前的垃圾短信过滤技术在应用于大规模垃圾短信过滤时,很难兼顾过滤的准确性和实时性要求.本文针对垃圾短信的特点,提出一种基于行为和内容协作分析的垃圾短信过滤机制并构建了原型系统.为了提升过滤及时性和过滤效果,采用行为分析为主、内容分析为辅的策略,并引入概率理论对归一化中文短信进行分析建模.该系统克服了当前垃圾短信过滤方法的不足,完善了垃圾短信过滤机制.通过真实垃圾短信数据对该原型系统进行验证,表明其可以大幅提高大规模垃圾短信的过滤效率和效果.
New applications of IMS network in the future [J].https://doi.org/10.3969/j.issn.1008-5599.2011.09.012 URL [本文引用: 1] 摘要
随着移动网络的发展,垃圾短信已经成为亟需解决的重要课题.当前的垃圾短信过滤技术在应用于大规模垃圾短信过滤时,很难兼顾过滤的准确性和实时性要求.本文针对垃圾短信的特点,提出一种基于行为和内容协作分析的垃圾短信过滤机制并构建了原型系统.为了提升过滤及时性和过滤效果,采用行为分析为主、内容分析为辅的策略,并引入概率理论对归一化中文短信进行分析建模.该系统克服了当前垃圾短信过滤方法的不足,完善了垃圾短信过滤机制.通过真实垃圾短信数据对该原型系统进行验证,表明其可以大幅提高大规模垃圾短信的过滤效率和效果.
|
| [7] |
基于内容的手机端垃圾短信过滤策略研究 [J].Content-based junk short message filtering for mobile phone [J]. |
| [8] |
Learning the parts of objects by non-negative matrix factorization [J].https://doi.org/10.1038/44565 URL PMID: 10548103 [本文引用: 1] 摘要
Abstract Is perception of the whole based on perception of its parts? There is psychological and physiological evidence for parts-based representations in the brain, and certain computational theories of object recognition rely on such representations. But little is known about how brains or computers might learn the parts of objects. Here we demonstrate an algorithm for non-negative matrix factorization that is able to learn parts of faces and semantic features of text. This is in contrast to other methods, such as principal components analysis and vector quantization, that learn holistic, not parts-based, representations. Non-negative matrix factorization is distinguished from the other methods by its use of non-negativity constraints. These constraints lead to a parts-based representation because they allow only additive, not subtractive, combinations. When non-negative matrix factorization is implemented as a neural network, parts-based representations emerge by virtue of two properties: the firing rates of neurons are never negative and synaptic strengths do not change sign.
|
| [9] |
非负矩阵分解融合高光谱和多光谱数据 [J].https://doi.org/10.11873/j.issn.1004-0323.2015.1.0082 URL Magsci [本文引用: 1] 摘要
<p>由于光谱分辨率和空间分辨率的制约以及物理条件的限制,高光谱数据具有很高的光谱分辨率而其空间分辨率却很低。因此,一般高光谱数据的空间分辨率往往低于仅有几个波段的多光谱数据的空间分辨率。高光谱数据和多光谱数据的融合可以得到同时具有高空间分辨率和高光谱分辨率的数据,进而应用于更高空间分辨率下地物的识别和分类。非负矩阵分解(Nonnegative Matrix Factorization)算法用于实现低空间分辨率高光谱数据和高空间分辨率多光谱数据的融合。首先利用顶点成分分析法VCA(Vertex Component Analysis)分解高光谱数据,得到初始的端元波谱矩阵和端元丰度矩阵;然后用非负矩阵分解算法交替地对高光谱数据和多光谱数据进行分解,得到高光谱分辨率的端元波谱矩阵和高空间分辨率的丰度矩阵;最后两个矩阵相乘得到高空间分辨率和高光谱分辨率的融合结果。在每一步非负矩阵分解过程中,数据之间的传感器观测模型用于分解矩阵的初始化。AVIRIS和HJ-1A数据实验结果分析表明:非负矩阵分解算法有效提高了高光谱数据的所有波长范围内波段数据的空间分辨率,而高精度的融合结果可用于地物的目标识别和分类。</p>
Fusion of hyperspectral and multispectal data using nonnegative matrix factorization [J].https://doi.org/10.11873/j.issn.1004-0323.2015.1.0082 URL Magsci [本文引用: 1] 摘要
<p>由于光谱分辨率和空间分辨率的制约以及物理条件的限制,高光谱数据具有很高的光谱分辨率而其空间分辨率却很低。因此,一般高光谱数据的空间分辨率往往低于仅有几个波段的多光谱数据的空间分辨率。高光谱数据和多光谱数据的融合可以得到同时具有高空间分辨率和高光谱分辨率的数据,进而应用于更高空间分辨率下地物的识别和分类。非负矩阵分解(Nonnegative Matrix Factorization)算法用于实现低空间分辨率高光谱数据和高空间分辨率多光谱数据的融合。首先利用顶点成分分析法VCA(Vertex Component Analysis)分解高光谱数据,得到初始的端元波谱矩阵和端元丰度矩阵;然后用非负矩阵分解算法交替地对高光谱数据和多光谱数据进行分解,得到高光谱分辨率的端元波谱矩阵和高空间分辨率的丰度矩阵;最后两个矩阵相乘得到高空间分辨率和高光谱分辨率的融合结果。在每一步非负矩阵分解过程中,数据之间的传感器观测模型用于分解矩阵的初始化。AVIRIS和HJ-1A数据实验结果分析表明:非负矩阵分解算法有效提高了高光谱数据的所有波长范围内波段数据的空间分辨率,而高精度的融合结果可用于地物的目标识别和分类。</p>
|
| [10] |
加权端元约束非负矩阵分解的高光谱解混算法 [J].https://doi.org/10.14188/j.2095-6045.2016.02.014 URL [本文引用: 1] 摘要
混合像元普遍存在于高光谱影像中,因此在影像使用过程中有效地进行混合像元分解是非常关键的。针对常规端元约束非负矩阵分解的解混方法对异常较敏感的现象,提出了一种利用加权端元约束的非负矩阵分解的方法。模拟实验证明了方法的可行性和有效性。
Weighted Endmember Constrained non-negative matrix factorization method for hyperspectral unmixing [J].https://doi.org/10.14188/j.2095-6045.2016.02.014 URL [本文引用: 1] 摘要
混合像元普遍存在于高光谱影像中,因此在影像使用过程中有效地进行混合像元分解是非常关键的。针对常规端元约束非负矩阵分解的解混方法对异常较敏感的现象,提出了一种利用加权端元约束的非负矩阵分解的方法。模拟实验证明了方法的可行性和有效性。
|
| [11] |
Decoding the encoding of functional brain networks: An fMRI classification comparison of non-negative matrix factorization (NMF), independent component analysis (ICA), and sparse coding algorithms [J].URL PMID: 28322859 [本文引用: 1] 摘要
The success of sparse coding algorithms suggests that algorithms which enforce sparsity, discourage multitasking, and promote local specialization may capture better the underlying source processes than those which allow inexhaustible local processes such as ICA. Negative BOLD signal may capture task-related activations.
|
| [12] |
垃圾短信分类治理对策研究 [J].
<p>以垃圾短信治理问题为切入点,以供需分析为理论基础,从短信内容与短信发送渠道两个维度分别提出非对称二维评判矩阵和分层分级治理策略。通过分析发现,目前治理重点转向“端口”类垃圾短信,广告类垃圾短信数量占比最大,而诈骗、色情等违法类短信社会危害最大,因而提出垃圾短信分类治理的相关建议。从新的视角研究垃圾短信治理问题,给监管部门及电信运营企业提供理论及方法借鉴,并促进短信业务的健康发展。</p>
Span SMS classification governance strategies [J].
<p>以垃圾短信治理问题为切入点,以供需分析为理论基础,从短信内容与短信发送渠道两个维度分别提出非对称二维评判矩阵和分层分级治理策略。通过分析发现,目前治理重点转向“端口”类垃圾短信,广告类垃圾短信数量占比最大,而诈骗、色情等违法类短信社会危害最大,因而提出垃圾短信分类治理的相关建议。从新的视角研究垃圾短信治理问题,给监管部门及电信运营企业提供理论及方法借鉴,并促进短信业务的健康发展。</p>
|
| [13] |
水稻冠层氮素含量光谱反演的随机森林算法及区域应用 [J].https://doi.org/10.11834/jrs.20142329 URL Magsci [本文引用: 1] 摘要
利用地面实测数据构建高精度的水稻冠层氮素含量光谱反演点模型并将其进行尺度转换,实现了水稻冠层氮素含量准实时、大区域监测。以氮素光谱敏感指数作为输入变量,冠层氮素含量数据为输出变量,利用随机森林算法构建水稻冠层氮素含量高光谱反演模型,并用苏州市水稻农田验证区数据,检验模型的普适性和有效性;利用准同步的Hyperion数据,采用对输入、输出变量进行线性变换的简单尺度转换方法实现了点模型的区域应用。结果表明:基于随机森林算法的水稻冠层氮素含量高光谱反演模型可解释、所需样本少、不会过拟合、精度高(模型在实验区的预测精度为R=0.82,验证区检验精度为R=0.73)且具有普适性;点模型基于高光谱遥感卫星影像和尺度转换进行区域应用,精度较高(R=0.81)。
Random forest algorithm and regional applications of spectral inversion model for estimating canopy concentration in rice [J].https://doi.org/10.11834/jrs.20142329 URL Magsci [本文引用: 1] 摘要
利用地面实测数据构建高精度的水稻冠层氮素含量光谱反演点模型并将其进行尺度转换,实现了水稻冠层氮素含量准实时、大区域监测。以氮素光谱敏感指数作为输入变量,冠层氮素含量数据为输出变量,利用随机森林算法构建水稻冠层氮素含量高光谱反演模型,并用苏州市水稻农田验证区数据,检验模型的普适性和有效性;利用准同步的Hyperion数据,采用对输入、输出变量进行线性变换的简单尺度转换方法实现了点模型的区域应用。结果表明:基于随机森林算法的水稻冠层氮素含量高光谱反演模型可解释、所需样本少、不会过拟合、精度高(模型在实验区的预测精度为R=0.82,验证区检验精度为R=0.73)且具有普适性;点模型基于高光谱遥感卫星影像和尺度转换进行区域应用,精度较高(R=0.81)。
|
| [14] |
Mapping Leaf Area Index in subtropical upland ecosystems using rapideye imagery and the randomforest algorithm [J].https://doi.org/10.3832/ifor0968-006 URL [本文引用: 2] 摘要
Canopy leaf area, frequently quantified by the Leaf Area Index (LAI), serves as the dominant control over primary production, energy exchange, transpiration, and other physiological attributes related to ecosystem processes. Maps depicting the spatial distribution of LAI across the landscape are of particularly high value for a better understanding of ecosystem dynamics and processes, especially over large and remote areas. Moreover, LAI maps have the potential to be used by process models describing energy and mass exchanges in the biosphere/atmosphere system. In this article we assess the applicability of the RapidEye satellite system, whose sensor is optimized towards vegetation analyses, for mapping LAI along a disturbance gradient, ranging from heavily disturbed shrub land to mature mountain rainforest. By incorporating image texture features into the analysis, we aim at assessing the potential quality improvement of LAI maps and the reduction of uncertainties associated with LAI maps compared to maps based on Vegetation Indexes (VI) solely. We identified 22 out of the 59 image features as being relevant for predicting LAI. Among these, especially VIs were ranked high. In particular, the two VIs using RapidEye RED-EDGE band stand out as the top two predictor variables. Nevertheless, map accuracy as quantified by the mean absolute error obtained from a 10-fold cross validation (MAE_CV) increased significantly if VIs and texture features are combined (MAE_CV = 0.56), compared to maps based on VIs only (MAE_CV = 0.62). We placed special emphasis on the uncertainties associated with the resulting map addressing that map users often treat uncertainty statements only in a pro-forma manner. Therefore, the LAI map was complemented with a map depicting the spatial distribution of the goodness-of-fit of the model, quantified by the mean absolute error (MAE), used for predictive mapping. From this an area weighted MAE (= 0.35) was calculated and compared to the unweighted MAE of 0.29. Mapping was done using randomForest, a widely used statistical modeling technique for predictive biological mapping.
|
| [15] |
A comprehensive comparison of random forests and support vector machines for microarray-based cancer classification [J].https://doi.org/10.1186/1471-2105-9-1 URL PMID: 2265676 [本文引用: 1] 摘要
pAbstract/p pBackground/p pAs an alternative to the frequently used reference design for two-channel microarrays, other designs have been proposed. These designs have been shown to be more profitable from a theoretical point of view (more replicates of the conditions of interest for the same number of arrays). However, the interpretation of the measurements is less straightforward and a reconstruction method is needed to convert the observed ratios into the genuine profile of interest (e.g. a time profile). The potential advantages of using these alternative designs thus largely depend on the success of the profile reconstruction. Therefore, we compared to what extent different linear models agree with each other in reconstructing expression ratios and corresponding time profiles from a complex design./p pResults/p pOn average the correlation between the estimated ratios was high, and all methods agreed with each other in predicting the same profile, especially for genes of which the expression profile showed a large variance across the different time points. Assessing the similarity in profile shape, it appears that, the more similar the underlying principles of the methods (model and input data), the more similar their results. Methods with a dye effect seemed more robust against array failure. The influence of a different normalization was not drastic and independent of the method used./p pConclusion/p pIncluding a dye effect such as in the methods lmbr_dye, anovaFix and anovaMix compensates for residual dye related inconsistencies in the data and renders the results more robust against array failure. Including random effects requires more parameters to be estimated and is only advised when a design is used with a sufficient number of replicates. Because of this, we believe lmbr_dye, anovaFix and anovaMix are most appropriate for practical use./p
|
| [16] |
An improved TF-IDF approach for text classification [J].https://doi.org/10.1007/BF02842477 URL [本文引用: 1] 摘要
This paper presents a new improved term frequency/inverse document frequency (TF-IDF) approach which uses confidence, support and characteristic words to enhance the recall and precision of text classification. Synonyms defined by a lexicon are processed in the improved TF-IDF approach. We detailedly discuss and analyze the relationship among confidence,recall and precision. The experiments based on science and technology gave promising results that the new TF-IDF approach improves the precision and recall of text classification compared with the conventional TF-IDF approach.
|
| [17] |
Mining microblog user interests based on TextRank with TF-IDF factor [J]. |
| [18] |
参数优化随机森林算法的土地覆盖分类 [J].https://doi.org/10.16251/j.cnki.1009-2307.2017.02.017 URL [本文引用: 1] 摘要
针对随机森林算法进行土地覆盖分类时无法确定参数组合以得到最优分类结果的问题,该文提出了两种随机森林算法的参数优化方法。以北京市昌平区为研究区,应用Landsat TM影像,实现了基于光谱值、纹理特征和专题特征的随机森林土地覆盖分类。采用改进网格法和遗传算法对随机森林算法的参数进行选择与优化,比较了改进的网格法和遗传算法方法找到的参数组合最优解,并将优化参数后的随机森林算法与传统的最大似然法及未经参数优化的随机森林算法对比。实验结果验证了随机森林算法在土地覆盖分类上的适用性和稳定性,且该文提出的基于参数优化的随机森林算法能得到更高的分类精度。
Land cover classification based on algorithm of parameter optimization randon forests [J].https://doi.org/10.16251/j.cnki.1009-2307.2017.02.017 URL [本文引用: 1] 摘要
针对随机森林算法进行土地覆盖分类时无法确定参数组合以得到最优分类结果的问题,该文提出了两种随机森林算法的参数优化方法。以北京市昌平区为研究区,应用Landsat TM影像,实现了基于光谱值、纹理特征和专题特征的随机森林土地覆盖分类。采用改进网格法和遗传算法对随机森林算法的参数进行选择与优化,比较了改进的网格法和遗传算法方法找到的参数组合最优解,并将优化参数后的随机森林算法与传统的最大似然法及未经参数优化的随机森林算法对比。实验结果验证了随机森林算法在土地覆盖分类上的适用性和稳定性,且该文提出的基于参数优化的随机森林算法能得到更高的分类精度。
|
| [19] |
基于随机森林的元胞自动机城市扩展模拟——以佛山市为例 [J].Urban expansion simulation by random-forest-based cellular automata: a case study of Foshan City [J]. |
| [20] |
一种结合词项语义信息和TF-IDF方法的文本相似度量方法 [J].https://doi.org/10.3724/SP.J.1016.2011.00856 URL [本文引用: 1] 摘要
传统的文本相似度量方法大多采用TF-IDF方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度.这些方法忽略了文本中词项的语义信息.改进的基于语义的文本相似度量方法在传统词频向量中扩充了语义相似的词项,进一步增加了文本表示向量的维度,但不能很好地反映两篇文本之间的相似程度.文中在TF-IDF模型基础上分析文本中重要词汇的语义信息,提出了一种新的文本相似度量方法.该方法首先应用自然语言处理技术对文本进行预处理,然后利用TF-IDF方法寻找文本中具有较高TF-IDF值的重要词项.借助外部词典分析词项之间的语义相似度,结合该文提出的词项相似度加权树以及文本语义相似度定义计算两篇文本之间的相似度.最后利用文本相似度在基准文本数据集合上进行聚类实验.实验结果表明文中提出的方法在基于F-度量值标准上优于TF-IDF以及另一种基于词项语义相似性的方法.
A Text similarity measurement combining word semantic information with TF-IDF Method [J].https://doi.org/10.3724/SP.J.1016.2011.00856 URL [本文引用: 1] 摘要
传统的文本相似度量方法大多采用TF-IDF方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度.这些方法忽略了文本中词项的语义信息.改进的基于语义的文本相似度量方法在传统词频向量中扩充了语义相似的词项,进一步增加了文本表示向量的维度,但不能很好地反映两篇文本之间的相似程度.文中在TF-IDF模型基础上分析文本中重要词汇的语义信息,提出了一种新的文本相似度量方法.该方法首先应用自然语言处理技术对文本进行预处理,然后利用TF-IDF方法寻找文本中具有较高TF-IDF值的重要词项.借助外部词典分析词项之间的语义相似度,结合该文提出的词项相似度加权树以及文本语义相似度定义计算两篇文本之间的相似度.最后利用文本相似度在基准文本数据集合上进行聚类实验.实验结果表明文中提出的方法在基于F-度量值标准上优于TF-IDF以及另一种基于词项语义相似性的方法.
|
| [21] |
Automated identification and characterization of parcels (AICP) with OpenStreetMap and Points of Interest [J].https://doi.org/10.1177/0265813515604767 URL [本文引用: 1] 摘要
Abstract: Against the paucity of urban parcels in China, this paper proposes a method to automatically identify and characterize parcels (AICP) with OpenStreetMap (OSM) and Points of Interest (POI) data. Parcels are the basic spatial units for fine-scale urban modeling, urban studies, as well as spatial planning. Conventional ways of identification and characterization of parcels rely on remote sensing and field surveys, which are labor intensive and resource-consuming. Poorly developed digital infrastructure, limited resources, and institutional barriers have all hampered the gathering and application of parcel data in developing countries. Against this backdrop, we employ OSM road networks to identify parcel geometries and POI data to infer parcel characteristics. A vector-based CA model is adopted to select urban parcels. The method is applied to the entire state of China and identifies 82,645 urban parcels in 297 cities. Notwithstanding all the caveats of open and/or crowd-sourced data, our approach could produce reasonably good approximation of parcels identified from conventional methods, thus having the potential to become a useful supplement.
|

/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}