杨腾飞 , 解吉波, 李振宇
, 解吉波, 李振宇
YANG Tengfei, XIE Jibo, LI Zhenyu
通讯作者:
收稿日期: 2018-01-18
修回日期: 2018-03-20
网络出版日期: 2018-07-20
版权声明: 2018 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:杨腾飞(1988-),男,博士生,研究方向为自然语言处理、灾害信息挖掘。E-mail: yangtf@radi.ac.cn
展开
摘要
社交媒体在灾害信息的实时发布与传播中发挥着越来越重要的作用。在灾害发生过程中,社交媒体中蕴含的实时灾损信息对灾情及时响应和评估有重要意义。然而,这些涉灾文本具有信息破碎度高、文本特征稀疏、标注语料库匮乏等缺点,使得传统的基于监督学习的方法难以有效提取其中的灾损信息。为此,本文提出了一种通过扩展上下文特征和匹配特征词的方法来快速识别和分类社交媒体中蕴含的不同类别的灾损信息。本方法首先基于中文语法规则,抽取小规模不同灾损类别下微博文本中的涉灾关键词构建特征词搭配对。然后,利用词向量模型和已有词库对这些特征词搭配对进行补充和扩展。同时,根据中文词语共现规则,引入外部语料库优化特征词间的语义搭配关系。最终,以此为基础构建台风灾损分类知识库对灾情文本中蕴含的不同类别灾损信息进行识别和分类。本文以2016年9月15日台风“莫兰蒂”登陆事件作为研究案例,以评估本文方法在灾损信息识别和分类上的效果。结果表明,本文方法对微博文本中蕴含的不同类别风灾损失信息的识别和分类效果显著(各类别综合评价指标都达到了0.74以上)。基于灾损信息分类结果,本文绘制了台风影响的时空分布图,从而进一步说明本文方法在灾害损失评估和减灾救灾方面的效用。
关键词:
Abstract
Social media plays a more and more important role in the real-time disaster information distribution and dissemination. During the disaster event, social media usually generates and contains a lot of real-time disaster loss information, which is very useful for the timely disaster response and disaster loss assessment. However, the social media data has many shortcomings, such as high fragmentation of the information, sparsity of the text features, and the lack of annotated corpus and so on, which makes the traditional supervised learning method difficult to be effectively used for disaster information extraction. This paper proposed a fast disaster loss identification and classification method to extract the disaster information from social media data by extending the context features and matching feature words. By this method, we firstly extracted the keywords from a small amount of sample micro-blog text of different disaster loss categories based on Chinese grammar rules and constructed the pairs of feature words collocation. Then, we used the word vector model and the existing lexicon to supplement and expand these pairs of feature words collocation. And the external corpus was introduced to optimize the semantic collocation relationship between feature words according to the rules of the concurrence of Chinese words. At last, we built a classification knowledgebase for identification and classification of disaster loss information related to typhoon disasters included in micro-blog. An experiment system was developed to evaluate the method introduced in the paper. Typhoon "Meranti" landed on 15th September, 2016 was selected as a case study. Results show that this method has a significant effect (each comprehensive evaluation index of different categories is greater than 0.74) on identifying and classifying different categories of disaster loss information from social media. We mapped the spatio-temporal distribution of typhoon influence based on the classification results of disaster loss from social media. The experiment shows that the classification output data and maps could be used for the disaster loss evaluation and mitigation.
Keywords:
近年来,全球自然灾害频繁发生,给人类的生命和财产安全带了严峻威胁。然而,传统的灾害信息收集手段存在着严重的滞后性,已无法满足政府部门及时开展救灾工作的需求。以Twitter[1]、Facebook[2]、微博数据[3]等为代表的社交媒体,其广泛的参与度、多源的传播渠道等特点[4],已成为政府部门及时了解灾情进展的一项有效手段。在灾害发生的第一时间,公众作为第一接触群体,扮演着动态传感器的角色[5],能够主动通过上传与灾害有关的事件信息[6],从而为政府部门提供第一手资料,辅助救灾决策的制定。目前,相关研究已取得显著进展,成果涉及灾情事件检测[7,8]、时空分析探究[9,10]、灾害下社会响应特征研究[11]、灾害发生趋势预测模拟[12,13]等方面,极大地提高了减灾救灾工作的效率。
但现有的研究方法更多的只是对灾害事件本身作识别分析,如仇培元等[14]基于语义相似度抽取微博客中蕴含的地理事件;Qu等[8]利用贝叶斯分类器从海量新浪微博文本中识别地震事件等。而对于灾害描述文本中蕴含的细粒度灾损信息的识别很少提及。这部分信息涉及灾害损失的各个方面且具有很强的时效性,对政府部门及时了解灾情进展并做出具有针对性的救灾行动意义重大。然而,微博文本中蕴含的这些灾损信息破碎程度高、文本特征稀疏,且可用的开放标注语料库匮乏,因此识别和分类难度也较大。
国内外针对短文本信息的识别和分类已开展了较多研究,方法通常包括基于触发词过滤和监督学习[14],前者是利用对触发词的判断来确定待分类文本是否与主题相关,后者则是通过人工标注的语料库来训练分类模型实现主题分类[15,16],常见的分类模型包括支持向量机[17,18]、K近邻[19,20]、朴素贝叶斯[21]、随机森林[22]、最大熵[23]等。基于触发词的方法通过提取文本中与主题相关的特征关键词,利用特征关键词来识别和分类目标文本,但该方法对非主题相关的文本分类效果较差[24]。基于监督学习的方法并不受主题相关性约束,但需要人工制备大规模标注语料,该过程费时费力,且各类别语料的数量和质量对于最终的分类结果影响较大。本文旨在从微博短文本中识别和分类不同类别的灾损事件信息,分类粒度较细,信息破碎度高,且同一条文本中通常包含多个灾损类别事件,各灾损事件上下文特征稀疏、表达形式复杂多样,难以建立大规模分类语料库,因此更适合采用基于触发词过滤的方法。例如,某一条微博文本“台风天气,断水停电,窗外一片狼藉,到处都是倒塌的树和砸坏的车”,其中包含了“断水”、“停电”、“倒塌的树”、“砸坏的车”等多个灾损类别事件。
通过上述分析,本文提出了一种基于特征语义扩展和中文词法搭配关系构建灾损分类知识库来识别和分类微博中蕴含的台风灾损信息的方法,并对台风受灾区的微博数据进行了分类测试和灾损评估,验证了本文方法在实际应用中的效果。
在中文文本分类领域,微博与传统的新闻文本有着显著差异[25]。以本文使用的新浪微博为例,其以短文本为主,最长不超过140个字符,语言表述口语化严重,且同一条微博中通常包含不同类别的灾损事件,信息破碎化程度较高。但分析发现,不同类别灾损信息的表达依然符合汉语的基本语法规则,如主谓、谓宾结构等[14],且与灾损文本的特征词一一对应。如“整个树被吹倒在地了”,根据语法规则抽取该文本中对应的词性搭配对“名词-动词”即“树-倒”,可很好地作为文本灾损类别的标识。因此,本文通过构建语法规则,抽取已知灾损类别微博文本中的特征词对作为种子词对。为满足灾损信息的多样性表达,利用词向量模型和《同义词词林》补充和扩展这些种子词对。同时,通过构建外部语料库,利用词频和词语间共现规则优化补充和扩展后的特征词。在此基础上,基于一定的规则构建台风灾损分类知识库对测试文本进行灾损事件的识别和归类。
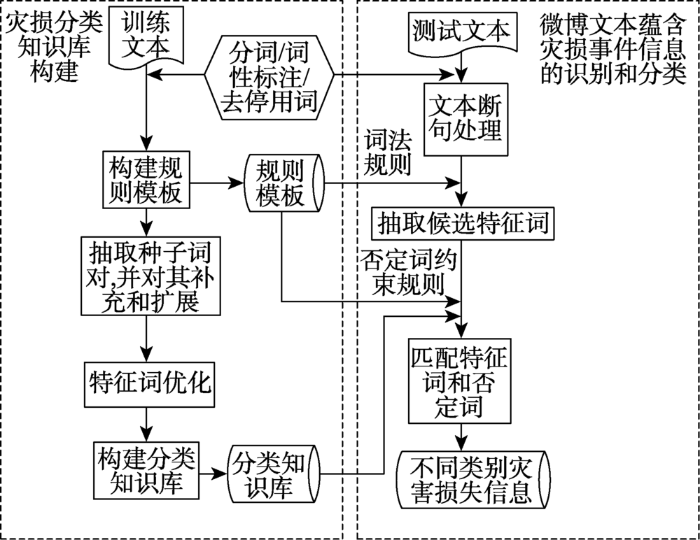
算法流程如图1所示,包括灾损分类知识库的构建和微博文本蕴含灾损事件信息的识别和分类2部分。具体步骤包括:① 基于训练语料构建规则模板,包括词法规则和否定词约束规则;② 利用词法规则抽取小规模不同灾损类别文本中的特征词搭配对作为种子词对,并利用词向量模型和《同义词词林》补充和扩展种子词对;③ 优化特征词,包括去除低频词和优化词语间搭配关系;④ 根据优化后的特征词对构建分类知识库;⑤ 对测试文本作断句处理,并根据词法规则抽取各个短句的候选特征词与分类知识库以及否定词表匹配,从而完成灾损事件信息抽取和分类。
2.1.1 词法规则
新浪微博文本包含的灾害损失信息破碎程度高、表达形式多样,且同一微博文本可能包含多种类别的风灾损失信息。利用汉语语法结构规则抽取灾情事件上下文特征词可很好的表达原文含义,如短文本“整个树被吹倒在地了”中的名词“树”和动词“倒”构成的特征词搭配对可作为该文本的分类依据。本文词法搭配模式的构建基于风灾事件微博文本的统计和归纳,数据来源于文献[26]所提供的“2017年台风灾害社交媒体数据集”,选取该数据集中5000条台风相关的新浪微博文本,分析其中灾损事件信息的词法特征,得到如表1所示的词法规则模式。
表1 词法规则模式
Tab. 1 Pattern of lexical rule
| 模式规则 | 文本样例 |
|---|---|
| v-n | 到处都是被打碎的玻璃 |
| n-v | 整个树被吹倒在地了 |
| a-n | 一地的碎窗玻璃 |
| n-a | 道路一直不畅通 |
| d-vi | 很快小区就不再供水了 |
| v-vi | 即将停止供电 |
| r-v | 看见他被树给砸了 |
| v-r | 树枝被风吹断刚好砸到他 |
| vi | 今天停电一天 |
2.1.2 否定词约束规则
根据词法规则抽取的灾损特征词可用于识别文本中包含的灾损信息,而特征词上下文中存在的否定词能够过滤候选文本中的非灾损信息。如“我家的玻璃还好没被吹破”,该文本中特征词对“玻璃-破”之间的否定词“没”标识了该文本的非灾损属性。通常,否定词多属副词,本文对“2017年台风灾害社交媒体数据集”中的9601条台风相关的新浪微博文本进行分词和词性标注,过滤出其中的副词,并提取这些副词中含有的否定词以构建否定词表。同时定义如下使用规则:
规则1:同一上下文中,当否定词位于任一特征词位置之前,则否定词对文本类别属性有反作用。如“树并没有被吹倒”,“台风天一直没有断水”等。
规则2:同一上下文中,当出现双重否定词时,则认为否定词对文本类别属性没有作用。如“台风天航班不会不被影响吧”。
基于词法规则抽取小规模标注语料中的特征词搭配对作为分类知识库构建的原始种子词对。以这些种子词对为基础,利用词向量模型和《同义词词林》扩展版丰富特征词搭配信息,以满足汉语表达方式多样性的需求。
2.2.1 基于词向量模型补充特征词
互联网文本蕴含着丰富的风灾损失事件核心词,可有效补充原有特征词,从而丰富灾损事件的语义表达。本文以抽取的种子词对为基础,从互联网文本中提取与种子词距离相近的词作为补充词。
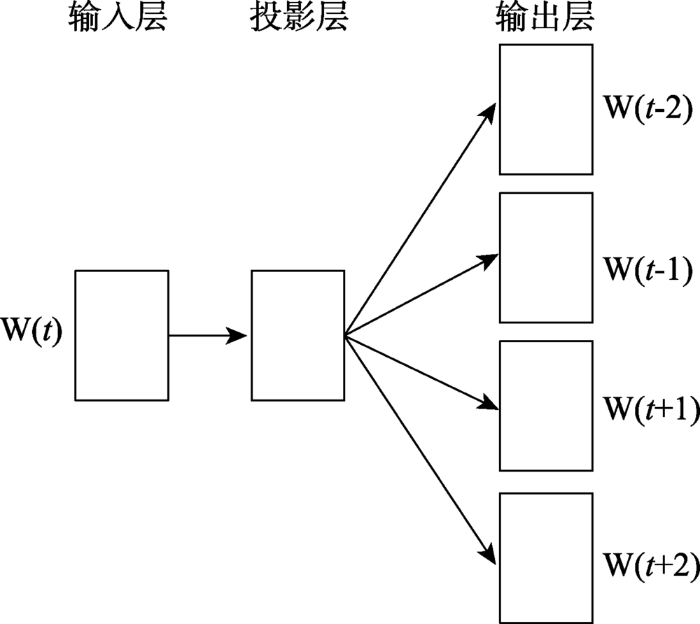
在自然语言处理领域,通常利用词向量模型计算词语间的距离,距离近的两个词相关度也高。常用的词向量模型包括CBOW和Skip-gram模型[27],它们是由Mikolov等[28]在神经网络语言模型NNLM(Neural Network Language Model)的基础上改进来的。文献[29]给出了CBOW和Skip-gram模型性能上的详细对比,结果表明Skip-gram模型总体效果要好于CBOW模型。因此,本文在计算词语间相关度上也采用Skip-gram模型。该模型结构包含输入层、投影层和输出层,其原理是通过当前词W(t)来预测该词所在的词组序列的上下文信息,模型结构如图2所示。
Skip-gram模型旨在使得目标函数G达到最大,如式(1)所示。
式中:wi表示当前词;C表示上下文窗口;Context(wi)表示与当前词wi距离小于窗口C大小的上下文信息,其条件概率计算如式(2)所示。
上述公式表明,Skip-gram模型通过引入上下文语境信息来计算词与词之间的相关度,语境相似的词语其相关度较高。因此,可根据计算所得的与当前词wi相关度最接近的词u作为该当前词的补充。例如,训练语料中出现了较多相似语境的文本如“路灯被台风刮倒了”、“电线杆被台风刮倒了”等,当以特征词“刮倒”作为模型的输入项时,“路灯”和“电线杆”与“刮倒”一词构成的条件概率会得到加强,二者可作为与“刮倒”相关度高的词被模型输出。同时,当以特征词“路灯”或“电线杆”作为输入项时,它们之间会因为和“刮倒”一词的共现关系,相关度也得到加强。表2为词汇相关度计算示例,将种子词对中的“树”和“倒”作为Skip-gram模型的输入项,模型从训练集中找出与“树”和“倒”相关度最高的前10个词。其中,“电线杆”一词作为原种子词对中没有出现过的新词被补充。
表2 词向量模型计算结果示例
Tab. 2 An example of the computational results of the word vector model
| 树 | 倒 |
|---|---|
| 大树 | 吹 |
| 整棵 | 大树 |
| 折断 | 断 |
| 应声 | 压垮 |
| 断 | 树干 |
| 倒 | 一棵 |
| 根 | 电线杆 |
| 一棵 | 棵 |
| 树枝 | 42棵 |
| 枝干 | 砸 |
2.2.2 基于《同义词词林》扩展特征词
词向量模型侧重于同语境新词的补充,而汉语对同一事件的描述用词多样,如“台风直接吹倒了一排树”和“我家楼下新种的小树直接被掀翻”,两文本都是描述台风对林木的影响,特征词搭配对分别为“树-倒”和“小树-掀翻”。其中“树”与“小树”、“倒”与“掀翻”分别构成同义关系。利用同义词在词向量模型的基础上进一步扩展特征词,可满足汉语表达多样化的需求。
一种有效、直接的同义词扩展方法则是利用新版《同义词词林》,该部词林包含了77 492条词语,共分为12个大类,94个中类以及1428个小类,小类下按照同义词划分了词群,词群下包含原子词群,《同义词词林》的结构与用法可参见相关文献[30,31]。本文利用《同义词词林》在补充后的种子词对的基础上作原子词群级别的同义扩展。
利用词向量模型和《同义词词林》补充和扩展特征词搭配对,丰富了短文本的语义信息。但在搭配词对生长过程中易出现较多的低频词和错误的搭配关系,这对识别效果影响较大,因此需要作优化处理。
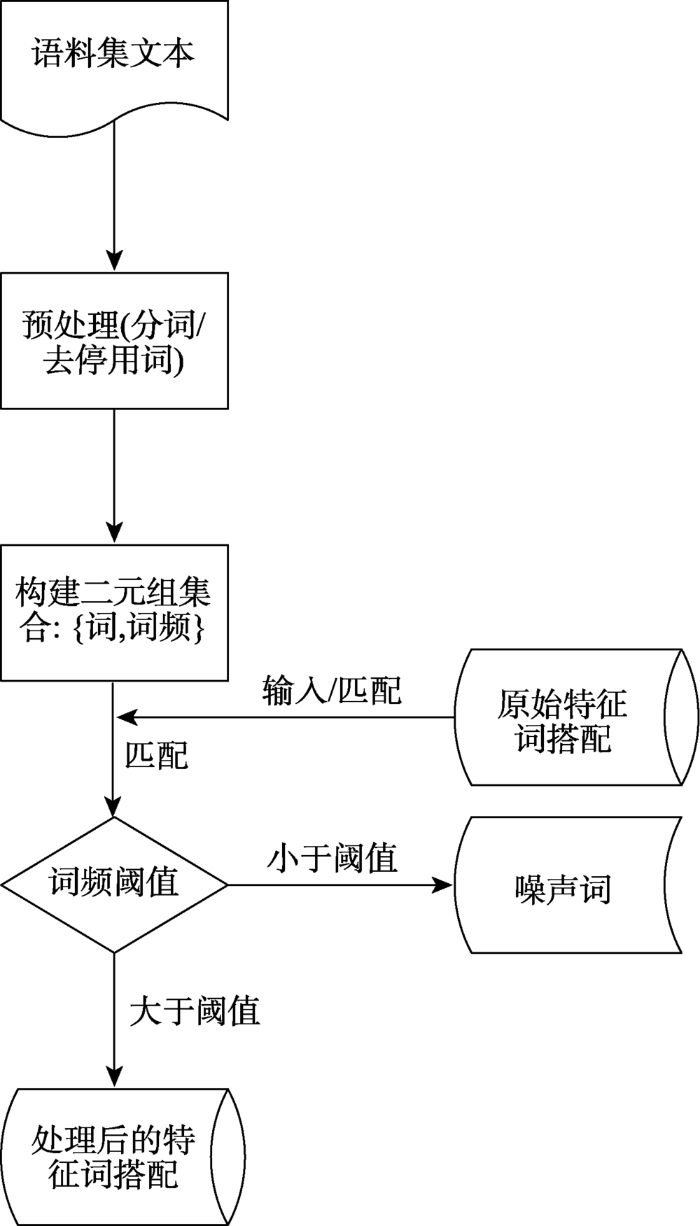
2.3.1 低频词去除在中文短文本分类中,高频词对于分类有较大的促进作用,而低频词易增加短文本的噪声,降低分类效率[32]。本文以“2017年台风灾害社交媒体数据集”为语料库,匹配特征词词频低于4的所有词并予以去除。图3为低频词处理流程。
2.3.2 词语搭配关系优化
在补充和扩展种子词对的过程中,难免会出现错误的搭配关系。如“树木”和“倒”可构成正确搭配,但“树木”的同义扩展词“树林”并不与“倒”构成正确搭配。
在中文自然语言处理中,两词在文本上下文中共现的次数越多,表明这两词相关度越强,越容易构成正确的搭配关系,因此可利用词语间的共现频率优化特征词搭配。词语间的共现频率通过搜狗实验室中文词语搭配库SogouR(http://www.sogou.com/labs/resource/w.php)和“2017年台风灾害社交媒体数据集”进行计算,其中搜狗实验室中文词语搭配库是搜狗搜索引擎基于全网文本建立的,其格式如下:
二元组1 同现次数1
二元组2 同现次数2
… …
二元组N 同现次数N
其中,二元组包含构成搭配的2个词语。
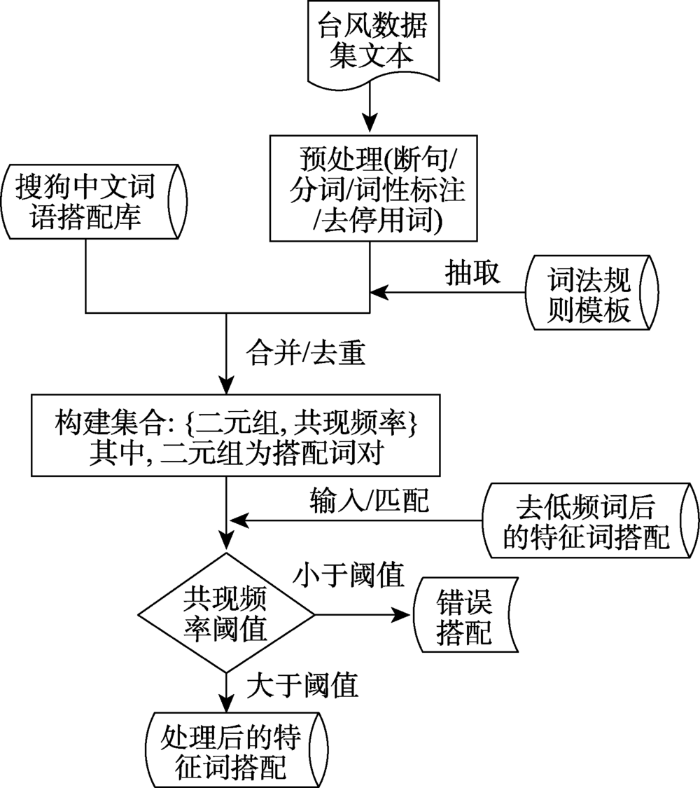
但该中文词语搭配库是2006年10月统计产生的,其中涉及台风灾害相关的词语搭配信息有限。为保证词语间搭配关系的优化效果,本文增加了“2017年台风灾害社交媒体数据集”中的文本信息,并对该数据集作如下处理:
(1)按照标点符号“,”、“。”、“!”、“?”、“;”对文本进行断句,形成短句s。
(2)对各短句进行分词、去停用词和词性标注。
(3)按照词法规则抽取各短句中的相关词语搭配对s=[w1,w2]。
(4)将词语搭配对按照搜狗实验室中文词语搭配库格式处理,形成新的词语搭配库。
将上述2个中文词语搭配库合并,并与特征词搭配对迭代匹配,清除特征词搭配关系中低于共现频率阈值的词对,从而消除词语间的不正确搭配关系。本文设置共现频率阈值为4。图4为词语搭配关系优化流程。
基于优化后的各灾损类别特征词搭配对构建分类知识库,该分类知识库的结构参考《同义词词林》。以编码的形式分为4位,第一位为大写字母,按字母表顺序分别代表灾损大类;第二位为小写字母,按字母表顺序代表大类下包含的子类;第三位为数字,按照同一类下词语搭配关系划分,用来表示词群;第四位以w1或w2表示搭配词,包含了各词群下的所有原子词。例如:
Ba01w1={“树木”,“树”,“果树”,“小树”,“大树”,…}
Ba01w2={“断”,“倒”,“倾倒”,“折断”,“遭殃”,…}
Ba02w1={“树林”、“林子”、“丛林”、“密林”,“园林”,…}
Ba02w2={“遭殃”、“摧残”、“损坏”、“毁坏”,“摧毁”,…}
其中,B代表林业影响;a代表林业影响下的子类;01和02代表2种不同的搭配关系;w1和w2表示搭配词群,w1通常表示实体名词,w2通常表示与之搭配的动词、形容词或副词等。特征词集Ba01w1与Ba01w2(或Ba02w1与Ba02w2)中的各原子词间可构成搭配关系用于识别和分类林业影响类下的各灾损事件,如Ba01w1中“树木”与Ba01w2中的各词构成搭配来匹配待分类文本中的“名词-动词”候选词对。知识库的结构形式如表3所示。
表3 分类知识库结构示例
Tab. 3 An example of the structure of classified knowledge base
| 编码位 | ||||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| 符号举例 | B | a | 01 | w1/w2 |
| 符号性质 | 大类 | 小类 | 词群 | 原子词群 |
| 级别 | 第1级 | 第2级 | 第3级 | 第4级 |
灾损事件通常包含于微博文本的短句中,因此,利用构建的分类知识库对微博文本中的各个短句作识别和分类,具体流程如下:
(1) 按照标点“,”、“。”、“!”、“?”、“;”将待分类文本拆为短句集合D=[s1,s2,…]。
(2) 对每个短句文本分词和词性标注,按照词法规则抽取候选特征词搭配对,并记录特征词在短句中的位置,构建四元组s=[w1,w2,i, j],其中w1,w2表示按照词法规则抽取的特征词,i和j表示特征词w1和w2在短句文本中的位置下标。同时根据否定词表匹配该短句文本中是否存在否定词,若存在,记录否定词的位置下标k。
(3) 将各四元组s中的特征词对“w1-w2”与分类知识库不同灾损类别下的特征词搭配对匹配,同时根据否定词约束规则比较特征词位置下标i、j与否定词位置下标k的关系,从而判断该短句的灾损类别,以确定待分类微博文本的类别属性。
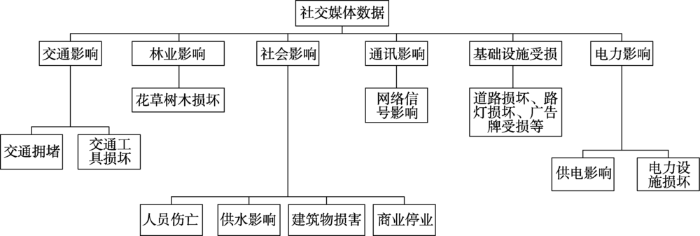
本文以“2017年台风灾害社交媒体数据集”中的分类样例作为抽取种子词对的基础语料,词向量模型的训练语料库以该数据集中其余的所有文本构建,并对其中的新闻和微信公众号原始语料进行正文抽取和文本清洗处理,以减少噪声文本对模型的干扰。本文待分类文本来自于2016年9月15日厦门“莫兰蒂”台风当天的新浪微博,共1821条数据。灾损分类标准参考《全国气象灾情收集上报技术规范》(下称《规范》),根据该《规范》对台风灾害损失信息分为6个大类和11个小类(图5),待分类文本各灾损类别的分布如表4所示。
表4 各类别语料分布
Tab. 4 Distribution of different categories of corpus
| 类别编号 | 灾损类别 | 数量/条 |
|---|---|---|
| 1 | 人员伤亡 | 34 |
| 2 | 供水影响 | 337 |
| 3 | 建筑物损伤 | 154 |
| 4 | 商业影响 | 63 |
| 5 | 林业影响 | 181 |
| 6 | 交通受阻 | 138 |
| 7 | 交通工具损坏 | 107 |
| 8 | 供电影响 | 402 |
| 9 | 电力设施受损 | 138 |
| 10 | 通讯影响 | 163 |
| 11 | 基础设施损坏 | 104 |
本文基于Java语言研发了“台风灾害损失信息自动识别和分类系统”,用来作为算法测试平台,系统集成了对微博数据实时获取、处理、识别和分类等模块。其中系统的分词和词性标注功能调用 NLPIR 2015工具包(http://ictclas.nlpir.org/),Skip-gram模型基于谷歌的词向量模型框架Word2vec实现。各分类结果的评测标准采用准确率(P)、召回率(R)和F-1值(综合评价指标),3个指标的计算公式如式(3)-(5)所示。
基于召回率、准确率和F-1值的评测标准识别和分类厦门“莫兰蒂”台风当天的新浪微博文本,结果如表5所示。
表5 实验结果对比
Tab. 5 Comparison of experimental results
| 类别 | 评测结果 | ||
|---|---|---|---|
| P/% | R/% | F-1值/% | |
| 第1类人员伤亡 | 68.00 | 89.47 | 77.27 |
| 第2类供水影响 | 87.32 | 95.48 | 91.22 |
| 第3类建筑物损伤 | 76.10 | 85.14 | 80.37 |
| 第4类商业影响 | 100.00 | 75.00 | 85.71 |
| 第5类林业影响 | 79.00 | 84.61 | 81.71 |
| 第6类交通受阻 | 78.74 | 87.71 | 82.98 |
| 第7类交通工具损坏 | 74.19 | 88.46 | 80.70 |
| 第8类供电影响 | 90.29 | 93.93 | 92.07 |
| 第9类电力设施损坏 | 78.54 | 70.53 | 74.32 |
| 第10类通讯影响 | 86.95 | 71.42 | 78.43 |
| 第11类基础设施受损 | 76.47 | 72.22 | 74.28 |
分类结果显示本文方法在准确率、召回率和 F-1值表现较好。与目前常见的短文本分类案例相比,本文涉及分类类别较多,不同类别间有一定的交叉重叠,且同一个短文本涉及多种类别标签,这一定程度上增加了分类难度[16]。同时,实验文本口语化严重、特征词复杂多样、语料信息不均衡等特点,也较大的限制了分类效果[33]。但从现有相关研究成果来看,基于社交媒体的短文本分类在不同背景下的分类效果差别较大,如文献[14]对微博文本中蕴含的地理事件进行提取和分类,并同传统的监督学习方法作了对比,综合评价指标提高了10%以上,但也只达到了71.41%。文献[34]人工标注了大规模分类语料训练SVM模型用于识别微博中的地震事件,虽然综合评价指标达到了89%,但其所涉及的类别单一,且粒度较粗,本文研究之初,也做过相关算法的尝试,效果并不理想。因此,综合来说,本文方法在当前背景下分类效果较好。
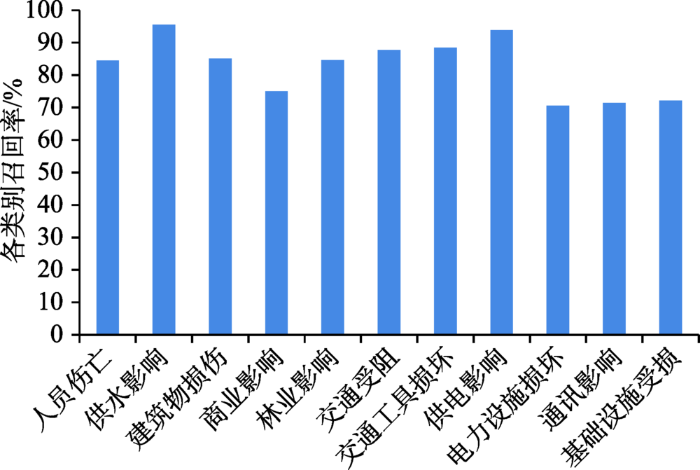
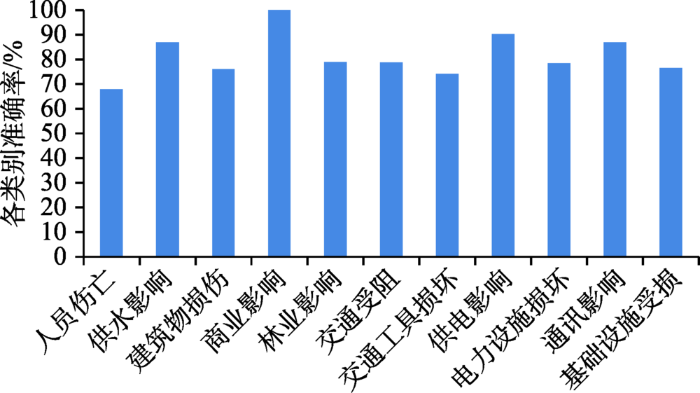
本文实验结果在不同类别下的召回率和准确率差别较大。
(1)如图6所示,“基础设施受损”、“电力设施损坏”和“通讯影响”三类的召回率较低,不足75%。分析发现,“基础设施受损”和“电力设施损坏”两类的实体名词包含种类较多,在补充和扩展这类特征词时,并不能完全覆盖。如“小区的小健身广场被毁的不成样了!!!!!!”、“高速路口的收费亭都被掀翻了…”等,其中“健身广场”、“收费亭”并没有在特征词补充与扩展中被收录进分类知识库中。“通讯影响”类中如“手机刚才满格的信号瞬间变成一格了”、“手机突然变成澳门讯号了……什么情况?台风把澳门的讯号刮过来了?”等语义隐含的文本和“4G秒变2G”等不规则特征词的情况,也使得算法很难对其有效。
(2)如图7所示,“人员伤亡”和“交通工具损坏”两类的准确率较低,不足75%,其中“人员伤亡”类的准确率甚至不足70%。本文分析了错误召回的文本,对于“人员伤亡”类别,考虑到在台风发生时,人员伤亡对于救援的重要性,因此,本文算法较多的考虑了“人员伤亡”的召回率,使得错误地召回了一些如“我幼小的心灵受到了伤害”等文本。对于“交通工具损坏”类,则由于一些文本的隐含语义造成错误的召回如“感觉友谊的小船翻了……”等。
为验证本文方法在灾害实际应用中的效果,本文对实验结果作进一步分析。实验所涉及的数据来源于2016年9月15日当天与厦门“莫兰蒂”台风相关的新浪微博。该数据源包含了15日凌晨3时5分台风登陆至16日凌晨“台风”过境过程中共1821条数据,数据形式包含文本、发布时间、发布位置等信息。
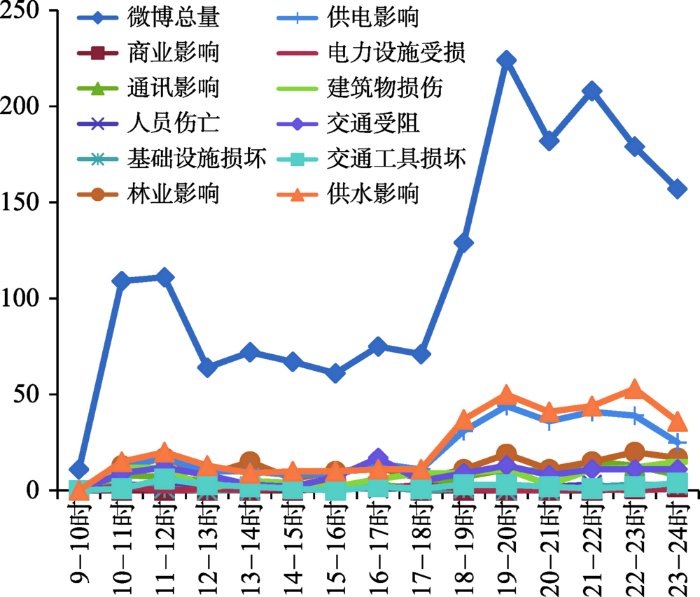
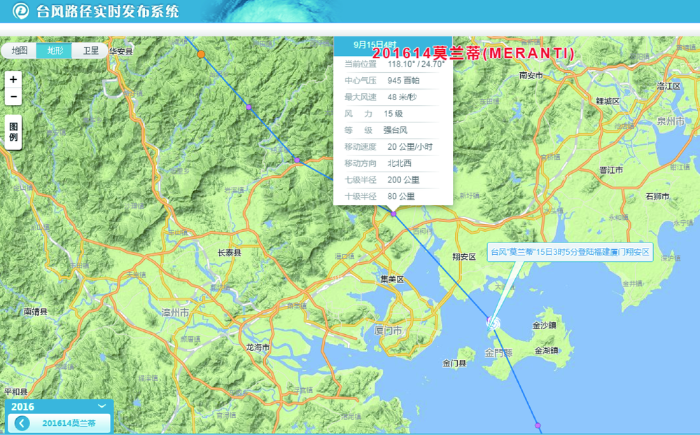
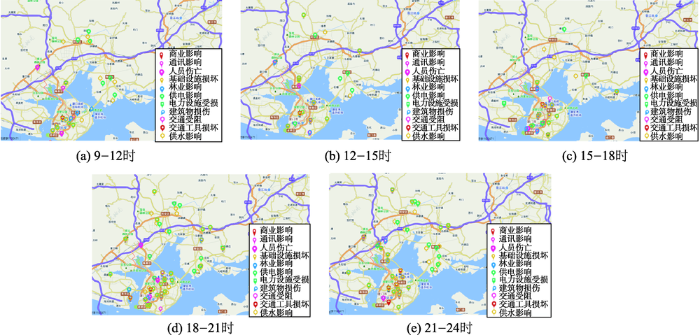
图8展示了本文方法所识别和分类的灾损事件信息与微博发布时间的变化关系。由图8可看出,不同灾损类别的微博数量与总微博数量增幅基本呈正相关,其中“林业影响”、“供电影响”以及“供水影响”3类随时间增幅较大,表明这3类灾损信息在本次“莫兰蒂”台风中受关注度较高,这与事后厦门市官方发布的讯息基本一致(http://www.xm.gov.cn/xmyw/201609/t20160917_1361266.htm)。此外,关系图中表明,从当日16时、17时起,各灾损数据量信息快速增加,根据浙江省水利信息管理中心台风信息发布系统(http://typhoon.zjwater.gov.cn/default.aspx)所显示的台风时间与路径数据可知该时刻台风正继续向西北方向移动并逐渐离开厦门,如图9所示。因此,从16时起,人类活动逐渐增加,使得微博数量曲线显著增长。伴随着人类活动的增加,对于交通状况的关注度也逐渐增强,关系图中“交通受阻”类别曲线在当日16时台风过境后呈现小波峰,表明该时段人类出行受阻严重,所识别的“交通受阻”类别的微博文本增多,同时根据这些微博所提供的位置信息,可呈现图10所示的空间分布。这为政府部门及时制定城市交通快速恢复决策提供了有力的数据支持。此外,随着时间的推移,图11展示了各类别灾损信息在各时间段内的空间位置分布,以可视化的形式向政府部门刻画灾情进展。
图9 台风“莫兰蒂”实时路径图
注:该图来自“台风信息发布系统”,网址是http://typhoon.zjwater.gov.cn/default.aspx
Fig. 9 Real-time path of typhoon "Meranti"
图10 “交通受阻”信息空间分布
注:底图来源于天地图
Fig. 10 Geospaital distribution of the "traffic obstruction" information
图11 各时间段灾损信息空间分布
注:底图来源于天地图
Fig. 11 Geospatial distribution of disaster loss in each time period
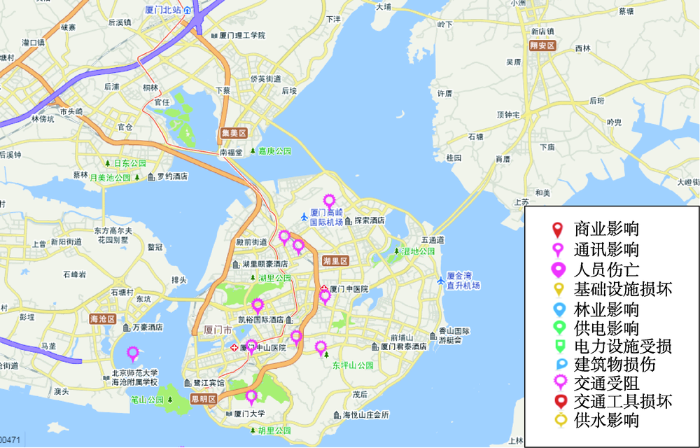
至23时,厦门市各类别灾损信息的空间分布情况如图12所示。图中各类别灾损标识信息均通过本文方法从当日厦门市各条新浪微博数据中提取得到。这在灾后第一时间向政府部门提供了受灾区域的整体损失信息。可见在本次台风过境中,厦门市思明区受灾最为严重,同安区和翔安区在供电供水方面受损较大,这些信息与灾后官方发布的灾损评估报告基本一致。
图12 灾损信息整体空间分布
Fig. 12 Overall geospatial distribution of disaster loss information
灾害发生时,基于社交媒体的灾情收集方式为政府部门提供了大量有价值的信息。利用短文本分类技术提取社交媒体文本中包含的灾损事件信息并近乎实时的反馈给相关部门,能够为有针对性的救灾决策的制定提供数据支持。本文基于此需求,以2016年厦门台风“莫兰蒂”过境时的微博数据为基础,针对短文本分类中上下文信息匮乏的缺点,利用词向量模型和《同义词词林》补充和扩展短文本特征词,并在此基础上构建了台风灾损分类知识库,同时基于该分类知识库对微博中包含的风灾损失信息进行识别和分类。最终各类别召回率、准确率和F-1均达到了满意的效果。为进一步验证本文方法在实际应用中的可靠性,本文对实验结果作了时空分析,最终结果同灾后官方发布的灾损评估信息基本一致,从而表明本文方法在灾害响应和应急分析上的有效性。但与此同时,社交媒体作为一种灾情获取的辅助手段,其提供的信息也存在一定的局限性,如本文实验所提取的各类别灾损事件的分布量与实际情况存在一定的偏差,这是由于一些公众未上传定位数据,导致一些微博数据地理位置信息缺失。但总体来讲,社交媒体作为新的辅助减灾救灾手段依然发挥着重要作用。
下一步,将尝试本文方法与传统的机器学习模型相结合,利用本文方法在文本特征扩展上的优势和传统机器学习模型上下文语义分析上的优势来进一步提高识别和分类的效果,同时考虑识别灾后各类基础设施的恢复信息从而为政府减灾救灾措施提供实时反馈。
The authors have declared that no competing interests exist.
| [1] |
Tweet analysis for real-time event detection and earthquake reporting system development [J].https://doi.org/10.1109/TKDE.2012.29 URL [本文引用: 1] 摘要
Twitter has received much attention recently. An important characteristic of Twitter is its real-time nature. We investigate the real-time interaction of events such as earthquakes in Twitter and propose an algorithm to monitor tweets and to detect a target event. To detect a target event, we devise a classifier of tweets based on features such as the keywords in a tweet, the number of words, and their context. Subsequently, we produce a probabilistic spatiotemporal model for the target event that can find the center of the event location. We regard each Twitter user as a sensor and apply particle filtering, which are widely used for location estimation. The particle filter works better than other comparable methods for estimating the locations of target events. As an application, we develop an earthquake reporting system for use in Japan. Because of the numerous earthquakes and the large number of Twitter users throughout the country, we can detect an earthquake with high probability (93 percent of earthquakes of Japan Meteorological Agency (JMA) seismic intensity scale 3 or more are detected) merely by monitoring tweets. Our system detects earthquakes promptly and notification is delivered much faster than JMA broadcast announcements.
|
| [2] |
Flooding facebook: The use of social media during the queensland and Victorian floods [J].
Community nitiated Facebook groups emerged during the 2010/11 Queensland and Victorian floods, gaining a near instant following from local residents within, and family and friends beyond, the impacted areas. Administrators of the groups sourced their data from agencies such as the Bureau of Meteorology, State Emergency Service, Queensland and Victorian Police Departments, local councils and news media. Even more importantly, administrators published near-real time information from the general public: Facebook members posted information and questions; local residents asked for and received help and advice; and, travellers driving through the area posted and received up-to-date information on road closures and flooding. During the floods in Queensland and Victoria, Risk Frontiers used Facebook to distribute a survey to members of community groups such as CQ Flood Update-version 2 and Victorian Floods. The results indicate that most respondents began using the community groups on the floods to get information about their community and almost all found the medium useful and an effective means of communicating with family or friends. In this paper, we discuss the results of this survey and consider the value of social media to the emergency services, not only as a tool to disseminate information but also as an important resource to tap into and review informal communications, something that was previously inaccessible.
|
| [3] |
基于社交媒体的突发事件应急信息挖掘与分析 [J].https://doi.org/10.13203/j.whugis20140804 URL [本文引用: 1] 摘要
社交媒体越来越多地被看作是随人们移动的传感器,感知周围发生的事件。当突发事件发生时,大量含有位置信息的文字迅速地充斥整个社交网络。本文探讨突发事件应急信息挖掘与分析的一种新思路。基于社交媒体,建立实时应急主题分类模型,从大量、实时的文本流中快速提取、定位应急信息;针对不同主题,利用统计分析和空间分析方法,探寻突发事件的时间趋势和空间分布,为应急响应提供决策支持。
Emergency information mining and analysis of emergency based on social media [J].https://doi.org/10.13203/j.whugis20140804 URL [本文引用: 1] 摘要
社交媒体越来越多地被看作是随人们移动的传感器,感知周围发生的事件。当突发事件发生时,大量含有位置信息的文字迅速地充斥整个社交网络。本文探讨突发事件应急信息挖掘与分析的一种新思路。基于社交媒体,建立实时应急主题分类模型,从大量、实时的文本流中快速提取、定位应急信息;针对不同主题,利用统计分析和空间分析方法,探寻突发事件的时间趋势和空间分布,为应急响应提供决策支持。
|
| [4] |
面向社交媒体文本的话题检测与追踪技术研究综述 [J]https://doi.org/10.14188/j.1671-8836.2016.03.001 URL [本文引用: 1] 摘要
以微博、论坛等为代表的社交媒体已逐渐发展成为网络用户表达和交流观点、获取和传播信息的重要平台.然而,社交媒体文本内容具有的规模庞大、形式多样、传播迅速等特点,对传统的应用在新闻报道、舆情监控、文本挖掘、信息咨询等方面的话题检测与追踪技术提出了新的要求.针对这一背景,本文分别从离线话题检测、在线话题检测和话题演化追踪这三个方面总结当前主要的话题检测与追踪方法,分析在该领域实验中被普遍使用的评估方式,最后提出当前面临的挑战和今后的研究方向.
A survey of topic detection and tracking technology for social media texts [J].https://doi.org/10.14188/j.1671-8836.2016.03.001 URL [本文引用: 1] 摘要
以微博、论坛等为代表的社交媒体已逐渐发展成为网络用户表达和交流观点、获取和传播信息的重要平台.然而,社交媒体文本内容具有的规模庞大、形式多样、传播迅速等特点,对传统的应用在新闻报道、舆情监控、文本挖掘、信息咨询等方面的话题检测与追踪技术提出了新的要求.针对这一背景,本文分别从离线话题检测、在线话题检测和话题演化追踪这三个方面总结当前主要的话题检测与追踪方法,分析在该领域实验中被普遍使用的评估方式,最后提出当前面临的挑战和今后的研究方向.
|
| [5] |
轨迹数据挖掘城市应用研究综述 [J].https://doi.org/10.3724/SP.J.1047.2015.01136 URL Magsci [本文引用: 1] 摘要
轨迹数据作为泛在地理信息环境中社会遥感数据的主要表现形式之一,为从个体的视角研究群体的空间移动规律,提供了新的数据支撑和研究思路。特别是在当前的大数据背景下,通过轨迹数据发掘人类的移动规律和活动模式,进而探求蕴含的深层次知识,是解决城市问题的重要途径,轨迹数据挖掘也由此成为地理信息科学及相关学科的研究热点。本文首先阐述了人类移动规律研究常用的轨迹数据集及在该数据集上开展的相关研究和典型应用;然后从城市空间结构功能单元的识别及城市韵律分析、人类活动模式的发现与空间移动行为预测、智能交通的时间估算与异常探测、城市计算的其他4个方面,综述了轨迹数据挖掘在城市中的应用;最后,指出了轨迹数据挖掘面临的挑战和进一步的发展方向。
A survey of urban application research on trajectory data mining [J].https://doi.org/10.3724/SP.J.1047.2015.01136 URL Magsci [本文引用: 1] 摘要
轨迹数据作为泛在地理信息环境中社会遥感数据的主要表现形式之一,为从个体的视角研究群体的空间移动规律,提供了新的数据支撑和研究思路。特别是在当前的大数据背景下,通过轨迹数据发掘人类的移动规律和活动模式,进而探求蕴含的深层次知识,是解决城市问题的重要途径,轨迹数据挖掘也由此成为地理信息科学及相关学科的研究热点。本文首先阐述了人类移动规律研究常用的轨迹数据集及在该数据集上开展的相关研究和典型应用;然后从城市空间结构功能单元的识别及城市韵律分析、人类活动模式的发现与空间移动行为预测、智能交通的时间估算与异常探测、城市计算的其他4个方面,综述了轨迹数据挖掘在城市中的应用;最后,指出了轨迹数据挖掘面临的挑战和进一步的发展方向。
|
| [6] |
|
| [7] |
Earthquake shakes Twitter users: rReal-time event detection by social sensors [C]. |
| [8] |
Microblogging after a major disaster in China: A case study of the 2010 Yushu earthquake [C]. |
| [9] |
Special section on visual analytics: Public behavior response analysis in disaster events utilizing visual analytics of microblog data [J]. |
| [10] |
反映自然灾害时空分布的社交媒体有效性探讨 [J].Social media effectiveness to reflect the spatial and temporal distribution of natural disasters [J]. |
| [11] |
基于社交媒体信息不同灾害的社会响应特征比较研究 [J].https://doi.org/10.3969/j.issn.1000-811X.2017.01.033 URL [本文引用: 1] 摘要
社交媒体作为政府应对突发事件中新的治理工具,以其信息的迅速、透明、参与度广的特点在灾害发生的各阶段发挥着重要作用,对我国应急管理体系信息化建设有重要价值。通过国内外文献阅读,基于百度指数反映天津大爆炸、深圳山体滑坡、丽水山体滑坡事件的社交媒体信息,通过对比分析不同灾害类型中社会响应阶段特征及差异性原因,探析灾害不同阶段社会对不同主题的关注热度,从而为我国政府应对不同类型灾害提供应对措施。研究表明:1不同类型灾害中社会响应阶段模式不同;2灾后社会响应特征受灾害影响程度及政府部门应急管理水平的影响;3灾害事件的不同阶段主题关注热度不同,自然灾害中,事故现场及过程、同类灾害搜索及灾后反思是主要关注点;人为灾害中除死亡人数、事故过程等,对事故原因和责任的关注贯穿整个事件中。
A comparative study of the social response characteristics of different disasters based on social media information [J].https://doi.org/10.3969/j.issn.1000-811X.2017.01.033 URL [本文引用: 1] 摘要
社交媒体作为政府应对突发事件中新的治理工具,以其信息的迅速、透明、参与度广的特点在灾害发生的各阶段发挥着重要作用,对我国应急管理体系信息化建设有重要价值。通过国内外文献阅读,基于百度指数反映天津大爆炸、深圳山体滑坡、丽水山体滑坡事件的社交媒体信息,通过对比分析不同灾害类型中社会响应阶段特征及差异性原因,探析灾害不同阶段社会对不同主题的关注热度,从而为我国政府应对不同类型灾害提供应对措施。研究表明:1不同类型灾害中社会响应阶段模式不同;2灾后社会响应特征受灾害影响程度及政府部门应急管理水平的影响;3灾害事件的不同阶段主题关注热度不同,自然灾害中,事故现场及过程、同类灾害搜索及灾后反思是主要关注点;人为灾害中除死亡人数、事故过程等,对事故原因和责任的关注贯穿整个事件中。
|
| [12] |
Pedrana. Making the most of a brave new world: Opportunities and considerations for using Twitter as a public health monitoring tool [J].https://doi.org/10.1016/j.ypmed.2014.03.008 URL PMID: 24632229 [本文引用: 1] 摘要
This paper outlines a commentary response to an article published by Young and colleagues in Preventive Medicine that evaluated the feasibility of using Twitter as a surveillance and monitoring took for HIV. We draw upon the broader literature on disease surveillance and public health prevention using social media and broader considerations of epidemiological and surveillance methods to provide readers with necessary considerations for using social media in epidemiology and surveillance.
|
| [13] |
Tozzi, et al. Twitter mining for fine-grained syndromic surveillance [J].https://doi.org/10.1016/j.artmed.2014.01.002 URL PMID: 24613716 [本文引用: 1] 摘要
Digital traces left on the Internet by web users, if properly aggregated and analyzed, can represent a huge information dataset able to inform syndromic surveillance systems in real time with data collected directly from individuals. Since people use everyday language rather than medical jargon (e.g. runny nose vs. respiratory distress), knowledge of patients’ terminology is essential for the mining of health related conversations on social networks. In this paper we present a methodology for early detection and analysis of epidemics based on mining Twitter messages. In order to reliably trace messages of patients that actually complain of a disease, first, we learn a model of na07ve medical language, second, we adopt a symptom-driven, rather than disease-driven, keyword analysis. This approach represents a major innovation compared to previous published work in the field. We first developed an algorithm to automatically learn a variety of expressions that people use to describe their health conditions, thus improving our ability to detect health-related “concepts” expressed in non-medical terms and, in the end, producing a larger body of evidence. We then implemented a Twitter monitoring instrument to finely analyze the presence and combinations of symptoms in tweets. We first evaluate the algorithm's performance on an available dataset of diverse medical condition synonyms, then, we assess its utility in a case study of five common syndromes for surveillance purposes. We show that, by exploiting physicians’ knowledge on symptoms positively or negatively related to a given disease, as well as the correspondence between patients’ “na07ve” terminology and medical jargon, not only can we analyze large volumes of Twitter messages related to that disease, but we can also mine micro-blogs with complex queries, performing fine-grained tweets classification (e.g. those reporting influenza-like illness (ILI) symptoms vs. common cold or allergy). Our approach yields a very high level of correlation with flu trends derived from traditional surveillance systems. Compared with Google Flu, another popular tool based on query search volumes, our method is more flexible and less sensitive to changes in web search behaviors.
|
| [14] |
蕴含地理事件微博客消息的自动识别方法 [J].https://doi.org/10.3724/SP.J.1047.2016.00886 URL Magsci [本文引用: 4] 摘要
微博客文本蕴含类型丰富的地理事件信息,能够弥补传统定点监测手段的不足,提高事件应急响应质量。然而,由于大规模标注语料的普遍匮乏,无法利用监督学习过程识别蕴含地理事件信息的微博客文本。为此,本文提出一种蕴含地理事件微博客消息的自动识别方法,通过快速获取的语料资源增强识别效果。该方法利用主题模型具有提取文档中主题集合的优势,通过主题过滤候选语料文本,实现地理事件语料的自动提取。同时,将分布式表达词向量模型引入事件相关性计算过程,借助词向量隐含的语义信息丰富微博客短文本的上下文内容,进一步增强事件消息的识别效果。通过以新浪微博为数据源开展的实验分析表明,本文提出的蕴含地理事件信息微博客消息识别方法,识别来自事件微博话题的消息文本的F-1值可达到71.41%,比经典的基于SVM模型的监督学习方法提高了10.79%。在模拟真实微博环境的500万微博客数据集上的识别准确率达到60%。
Zhang H C, at al. Containing automatic recognition methods for geo-event micro-blog messages [J].https://doi.org/10.3724/SP.J.1047.2016.00886 URL Magsci [本文引用: 4] 摘要
微博客文本蕴含类型丰富的地理事件信息,能够弥补传统定点监测手段的不足,提高事件应急响应质量。然而,由于大规模标注语料的普遍匮乏,无法利用监督学习过程识别蕴含地理事件信息的微博客文本。为此,本文提出一种蕴含地理事件微博客消息的自动识别方法,通过快速获取的语料资源增强识别效果。该方法利用主题模型具有提取文档中主题集合的优势,通过主题过滤候选语料文本,实现地理事件语料的自动提取。同时,将分布式表达词向量模型引入事件相关性计算过程,借助词向量隐含的语义信息丰富微博客短文本的上下文内容,进一步增强事件消息的识别效果。通过以新浪微博为数据源开展的实验分析表明,本文提出的蕴含地理事件信息微博客消息识别方法,识别来自事件微博话题的消息文本的F-1值可达到71.41%,比经典的基于SVM模型的监督学习方法提高了10.79%。在模拟真实微博环境的500万微博客数据集上的识别准确率达到60%。
|
| [15] |
面向中文文本的事件时空与属性信息解析方法研究 [J].https://doi.org/10.11947/j.AGCS.2015.20140657 URL Magsci [本文引用: 1] 摘要
正随着网络与信息技术的快速发展,人们作为"传感器"行走在真实社会中制造实时的、实地环境的、大范围的地理信息。互联网逐步发展为地理信息最大的收藏地。地理信息已步入大数据时代,其中80%的数据为非结构化数据(包括自然语言、图像、视频等)。文本是人们空间认知结果的自然语言表现形式,也是最重要的地理信息来源和最有潜力的人机交互手段。事件是人们认识
Research on the analysis method of event space-time and attribute information for Chinese texts [J].https://doi.org/10.11947/j.AGCS.2015.20140657 URL Magsci [本文引用: 1] 摘要
正随着网络与信息技术的快速发展,人们作为"传感器"行走在真实社会中制造实时的、实地环境的、大范围的地理信息。互联网逐步发展为地理信息最大的收藏地。地理信息已步入大数据时代,其中80%的数据为非结构化数据(包括自然语言、图像、视频等)。文本是人们空间认知结果的自然语言表现形式,也是最重要的地理信息来源和最有潜力的人机交互手段。事件是人们认识
|
| [16] |
基于机器学习的文本自动分类研究进展 [J].https://doi.org/10.3969/j.issn.1000-0135.2006.06.012 URL [本文引用: 2] 摘要
文本自动分类是目前最常用的文本信息自动处理技术,也是机器学习、自然语言处理和信息检索瓴域的研究热点之一。本文比较全面、深入地论述了基于机器学习的文本自动分类所涉及的相关问题及解决方法,并提出了当前该领域面临的主要研究问题。
Research progress of automatic text classification based on machine learning [J].https://doi.org/10.3969/j.issn.1000-0135.2006.06.012 URL [本文引用: 2] 摘要
文本自动分类是目前最常用的文本信息自动处理技术,也是机器学习、自然语言处理和信息检索瓴域的研究热点之一。本文比较全面、深入地论述了基于机器学习的文本自动分类所涉及的相关问题及解决方法,并提出了当前该领域面临的主要研究问题。
|
| [17] |
A comparison study on multiple binary-class SVM methods for unilabel text categorization [J].https://doi.org/10.1016/j.patrec.2010.02.015 URL [本文引用: 1] 摘要
Multiclass support vector machine (SVM) methods are well studied in recent literature. Comparison studies on UCI/statlog multiclass datasets suggest using one-against-one method for multiclass SVM classification. However, in unilabel (multiclass) text categorization with SVMs, no comparison studies exist with one-against-one and other methods, e.g. one-against-all and several well-known improvements to these approaches. In this paper, we bridge this gap by performing empirical comparison of standard one-against-all and one-against-one, together with three improvements to these standard approaches for unilabel text categorization with SVM as base binary learner. We performed all our experiments on three standard text corpuses using two types of document representation. Outcome of our experiments partly support Rifkin and Klautau (2004) statement that, for small scale unilabel text categorization tasks, if parameters of the classifiers are well tuned, one-against-all will have better performance than one-against-one and other methods.
|
| [18] |
Drug design by machine learning: Support vector machines for pharmaceutical data analysis [J].https://doi.org/10.1016/S0097-8485(01)00094-8 URL PMID: 11765851 [本文引用: 1] 摘要
We show that the support vector machine (SVM) classification algorithm, a recent development from the machine learning community, proves its potential for structure ctivity relationship analysis. In a benchmark test, the SVM is compared to several machine learning techniques currently used in the field. The classification task involves predicting the inhibition of dihydrofolate reductase by pyrimidines, using data obtained from the UCI machine learning repository. Three artificial neural networks, a radial basis function network, and a C5.0 decision tree are all outperformed by the SVM. The SVM is significantly better than all of these, bar a manually capacity-controlled neural network, which takes considerably longer to train.
|
| [19] |
When Is “Nearest Neighbor” Meaningful? [C]. |
| [20] |
An improved K-nearest-neighbor algorithm for text categorization [J].https://doi.org/10.1016/j.eswa.2011.08.040 URL [本文引用: 1] 摘要
k is the most important parameter in a text categorization system based on i-Nearest Neighbor algorithm (kNN).In the classification process,k nearest documents to the test one in the training set are determined firstly.Then,the predication can be made according to the category distribution among these k nearest neighbors.Generally speaking,the class distribution in the training set is uneven.Some classes may have more samples than others.Therefore,the system performance is very sensitive to the choice of the parameter k.And it is very likely that a fixed k value will result in a bias on large categories.To deal with these problems,we propose an improved kNN algorithm,which uses different numbers of nearest neighbors for different categories,rather than a fixed number across all categories.More samples (nearest neighbors) will be used for deciding whether a test document should be classified to a category,which has more samples in the training set.Preliminary experiments on Chinese text categorization show that our method is less sensitive to the parameter k than the traditional one,and it can properly classify documents belonging to smaller classes with a large k.The method is promising for some cases,where estimating the parameter k via cross-validation is not allowed.
|
| [21] |
TwitterStand: News in tweets [C]. |
| [22] |
An improved random forest classifier for text categorization [J].https://doi.org/10.4304/jcp.7.12.2913-2920 URL [本文引用: 1] 摘要
This paper proposes an improved random forest algorithm for classifying text data. This algorithm is particularly designed for analyzing very high dimensional data with multiple classes whose well-known representative data is text corpus. A novel feature weighting method and tree selection method are developed and synergistically served for making random forest framework well suited to categorize text documents with dozens of topics. With the new feature weighting method for subspace sampling and tree selection method, we can effectively reduce subspace size and improve classification performance without increasing error bound. We apply the proposed method on six text data sets with diverse characteristics. The results have demonstrated that this improved random forests outperformed the popular text classification methods in terms of classification performance.
|
| [23] |
Using maximum entropy model for Chinese text categorization [J].https://doi.org/10.1360/crad20050113 URL [本文引用: 1] 摘要
With the rapid development of World Wide Web, text classification has become the key technology in organizing and processing large amount of document data. Maximum entropy model is a probability estimation technique widely used for a variety of natural language tasks. It offers a clean and accommodable frame to combine diverse pieces of contextual information to estimate the probability of a certain linguistics phenomena. This approach for many tasks of NLP perform near state-of-the-art level, or outperform other competing probability methods when trained and tested under similar conditions. However, relatively little work has been done on applying maximum entropy model to text categorization problems. In addition, no previous work has focused on using maximum entropy model in classifying Chinese documents. Maximum entropy model is used for text categorization. Its categorization performance is compared and analyzed using different approaches for text feature generation, different number of feature and smoothing technique. Moreover, in experiments it is compared to Bayes, KNN and SVM, and it is shown that its performance is higher than Bayes and comparable with KNN and SVM. It is a promising technique for text categorization.
|
| [24] |
音乐领域典型事件抽取方法研究 [J].https://doi.org/10.3969/j.issn.1003-0077.2011.02.003 URL Magsci [本文引用: 1] 摘要
事件抽取是信息抽取领域一个重要的研究方向。该文从音乐领域的事件抽取出发,通过领域事件词聚类的方法自动发现音乐领域具有代表性的事件,然后采用基于关键词与触发词相结合的过滤方法简化了事件类型的识别过程。在事件元素识别中,该文采用了基于最大熵的事件元素识别方法。在该文构建的语料库下,最终事件类型识别的平均F值达到82.82%,事件元素识别的平均F值达到75.79%。
Qing B, at al. Research on typical event extraction method in music field [J].https://doi.org/10.3969/j.issn.1003-0077.2011.02.003 URL Magsci [本文引用: 1] 摘要
事件抽取是信息抽取领域一个重要的研究方向。该文从音乐领域的事件抽取出发,通过领域事件词聚类的方法自动发现音乐领域具有代表性的事件,然后采用基于关键词与触发词相结合的过滤方法简化了事件类型的识别过程。在事件元素识别中,该文采用了基于最大熵的事件元素识别方法。在该文构建的语料库下,最终事件类型识别的平均F值达到82.82%,事件元素识别的平均F值达到75.79%。
|
| [25] |
微博文本处理研究综述 [J].
微博是一个基于关系的信息分享、传播以及获取平台。用户可以通过WEB、WAP以及各种客户端组件,以140字左右的文字更新信息,并实现即时分享。由于微博发展迅猛,微博文本已经形成了大规模积累,针对微博文本的研究已经成为了一个十分重要的课题。该文对微博文本进行了定义,阐述了微博文本研究的重要性,并从微博文本的不同应用领域出发,对微博文本的研究现状进行了综述,介绍了目前已经存在的微博文本数据集和应用系统。
Weibo text processing research review [J].
微博是一个基于关系的信息分享、传播以及获取平台。用户可以通过WEB、WAP以及各种客户端组件,以140字左右的文字更新信息,并实现即时分享。由于微博发展迅猛,微博文本已经形成了大规模积累,针对微博文本的研究已经成为了一个十分重要的课题。该文对微博文本进行了定义,阐述了微博文本研究的重要性,并从微博文本的不同应用领域出发,对微博文本的研究现状进行了综述,介绍了目前已经存在的微博文本数据集和应用系统。
|
| [26] |
A social media based dataset of typhoon disasters [DB]. |
| [27] |
Efficient Estimation of Word Representations in Vector Space [J].
Abstract: We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
|
| [28] |
A neural probabilistic language model [J].https://doi.org/10.1007/3-540-33486-6_6 URL [本文引用: 1] 摘要
A central goal of statistical language modeling is to learn the joint probability function of sequences of words in a language. This is intrinsically difficult because of the curse of dimensionality : a word sequence on which the model will be tested is likely to be different from all the word sequences seen during training. Traditional but very successful approaches based on n-grams obtain generalization by concatenating very short overlapping sequences seen in the training set. We propose to fight the curse of dimensionality by learning a distributed representation for words which allows each training sentence to inform the model about an exponential number of semantically neighboring sentences. Generalization is obtained because a sequence of words that has never been seen before gets high probability if it is made of words that are similar (in the sense of having a nearby representation) to words forming an already seen sentence. Training such large models (with millions of parameters) within a reasonable time is itself a significant challenge. We report on several methods to speed-up both training and probability computation, as well as comparative experiments to evaluate the improvements brought by these techniques. We finally describe the incorporation of this new language model into a state-of-the-art speech recognizer of conversational speech.
|
| [29] |
Word2vec的核心架构及其应用 [J].https://doi.org/10.3969/j.issn.1672-1292.2015.01.008 URL [本文引用: 1] 摘要
神经网络概率语言模型是一种新兴的自然语言处理算法,该模型通过学习训练语料获得词向量和概率密度函数,词向量是多维实数向量,向量中包含了自然语言中的语义和语法关系,词向量之间余弦距离的大小代表了词语之间关系的远近,词向量的加减代数运算则是计算机在"遣词造句".近年来,神经网络概率语言模型发展迅速,Word2vec是最新技术理论的合集.首先,重点介绍Word2vec的核心架构CBOW及Skip-gram;接着,使用英文语料训练Word2vec模型,对比两种架构的异同;最后,探讨了Word2vec模型在中文语料处理中的应用.
Word2vec's core architecture and its application [J].https://doi.org/10.3969/j.issn.1672-1292.2015.01.008 URL [本文引用: 1] 摘要
神经网络概率语言模型是一种新兴的自然语言处理算法,该模型通过学习训练语料获得词向量和概率密度函数,词向量是多维实数向量,向量中包含了自然语言中的语义和语法关系,词向量之间余弦距离的大小代表了词语之间关系的远近,词向量的加减代数运算则是计算机在"遣词造句".近年来,神经网络概率语言模型发展迅速,Word2vec是最新技术理论的合集.首先,重点介绍Word2vec的核心架构CBOW及Skip-gram;接着,使用英文语料训练Word2vec模型,对比两种架构的异同;最后,探讨了Word2vec模型在中文语料处理中的应用.
|
| [30] |
彭成钱龙华,等.《同义词词林》在中文实体关系抽取中的作用 [J].
语义信息在命名实体间语义关系抽取中具有重要的作用。该文以《同义词词林》为例,系统全面地研究了词汇语义信息对基于树核函数的中文语义关系抽取的有效性,深入探讨了不同级别的语义信息和一词多义等现象对关系抽取的影响,详细分析了词汇语义信息和实体类型信息之间的冗余性。在ACE2005中文语料库上的关系抽取实验表明,在未知实体类型的前提下,语义信息能显著提高抽取性能;而在已知实体类型的情况下,语义信息也能明显提高某些关系类型的抽取性能,这说明《词林》语义信息和实体类型信息在中文语义关系抽取中具有一定的互补性。
Qian L H, at al. The role of synonym in the extraction of Chinese entity Relationships [J].
语义信息在命名实体间语义关系抽取中具有重要的作用。该文以《同义词词林》为例,系统全面地研究了词汇语义信息对基于树核函数的中文语义关系抽取的有效性,深入探讨了不同级别的语义信息和一词多义等现象对关系抽取的影响,详细分析了词汇语义信息和实体类型信息之间的冗余性。在ACE2005中文语料库上的关系抽取实验表明,在未知实体类型的前提下,语义信息能显著提高抽取性能;而在已知实体类型的情况下,语义信息也能明显提高某些关系类型的抽取性能,这说明《词林》语义信息和实体类型信息在中文语义关系抽取中具有一定的互补性。
|
| [31] |
基于同义词词林扩展的短文本分类 [J].Short text classification based on synonym word forest expansion [J]. |
| [32] |
基于LDA高频词扩展的中文短文本分类 [J].Chinese short text classification based on LDA high-frequency word expansion [J]. |
| [33] |
文本自动分类技术研究综述 [J].
文章从文本表示、特征选择、分类算法、常用基准语料以及评估指标等方面对近年来的研究成果进行综述并讨论。认为短文本分类和多语言文本分类管理是新出现的重要且紧迫的问题,并对这两个问题以及数据集偏斜、多层分类、标注瓶颈等几个关键问题进行重点讨论。最后总结并展望这些研究内容。
A survey of automatic text classification technology [J].
文章从文本表示、特征选择、分类算法、常用基准语料以及评估指标等方面对近年来的研究成果进行综述并讨论。认为短文本分类和多语言文本分类管理是新出现的重要且紧迫的问题,并对这两个问题以及数据集偏斜、多层分类、标注瓶颈等几个关键问题进行重点讨论。最后总结并展望这些研究内容。
|
| [34] |
基于中文短文本分类的社交媒体灾害事件检测系统研究 [J].Social media disaster event detection system based on Chinese short text classification [J]. |

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}