徐晓宇 , 李梅
, 李梅
北京大学地球与空间科学学院 遥感与地理信息系统研究所,北京 100871
XU Xiaoyu, LI Mei
通讯作者:
收稿日期: 2018-09-4
修回日期: 2018-11-29
网络出版日期: 2019-02-20
版权声明: 2019 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:徐晓宇(1995-),女,辽宁营口人,硕士生,主要从事地学信息可视化与数据挖掘研究。E-mail: xuxiaoyu@pku.edu.cn
展开
摘要
基于大数据进行城市服务设施空间格局分析已成为一种新的研究热点,而餐饮业是城市服务业的典型代表,因此通过开源大数据对城市餐饮业的空间布局进行研究具有重要的意义。本文以北京地区作为研究区,采用网络爬虫技术获取大众点评上153 895家餐饮店数据,引入基于密度的CFSFDP聚类算法从空间分布密集度和人均消费等级方面对餐饮业背后蕴含的地理聚集特征进行分析。研究发现:① 北京地区餐饮店总体呈现多中心的空间分布特征,其集聚程度以主城区为核心向外逐级递减,并明显表现出围绕重要商圈、旅游景点和住宅区进行布局以及沿交通轴线扩展的趋势;② 不同人均消费水平的餐饮店呈现等级体系特征,即高档餐馆少而集聚,中低档餐馆多而散的分布特点;③ 餐馆分布密集程度和定价表现出接近市场和消费者的特征。同时,本文综合空间集聚特征和消费水平2项指标对影响餐饮店集群空间分布格局的因素进行了分析,以期为政府规划部门进行城市商业空间布局研究提供借鉴。
关键词:
Abstract
Using big data to analyze the spatial pattern of urban service facilities has become a new research hotspot, and catering industry is a typical representative of urban service industry. Therefore, it is of great significance to study the spatial layout of urban catering industry through open source big data. The restaurants in a city can be abstracted as point objects in the geographical study , and clustering analysis is a classical data mining method that quantificationally identifies geographical clustering among objects. In this paper, Beijing is selected as the research area, and the data of 153 895 restaurants in Dianping.com are obtained by using web crawler technology. The density-based CFSFDP clustering algorithm (clustering by fast search and find of density peaks) is adopted here to analyze the geographical clustering characteristics of catering industry in terms of spatial distribution density and per capita consumption level. This approach, which is based on the idea that cluster centers are characterized by a higher density than their neighbors and by a relatively larger distance from points with higher densities, can recognize clusters regardless of their shape and the dimensionality of the space in which they are embedded, so more accurate spatial analysis results can be obtained. The results show that: (1) the spatial pattern of Beijing restaurants is imbalanced, which generally presents the characteristics of multi-center spatial distribution, and the agglomeration degree of restaurants decreases with the distance increase from the main urban area which are regarded as the core. Besides, the restaurants hot spots mainly circles around important business centers, tourist attractions as well as residential areas, and extends along the traffic line evidently. (2) The catering stores with different per capita consumption levels have the characteristics of hierarchical system. That is to say, there are the number of high-grade restaurants is few, and mainly concentrated in the commercial centers, financial centers and famous tourist attractions in Dongcheng district, Xicheng district, Chaoyang district and Haidian district, while the number of middle and low-grade restaurants is much more and their spatial distribution are more scattered. (3) The density and price of restaurants accords with consumption level of consumers. At the same time, this paper also analyses the factors influencing the spatial distribution pattern of catering clusters by combining the two indicators of spatial agglomeration characteristics and consumption level, in order to provide useful reference of urban commercial spatial layout for the government planning departments.
Keywords:
城市空间结构一直是城市地理学及城市规划的重点研究内容,而餐饮业作为城市系统的重要组成部分,其区位特征和空间分布格局一直是学者们关注的焦点。国外学者很早就从旅游的角度来分析饭店的分布特征,主要集中在空间布局和影响因素方面,如Roehl等[1]和Urtasun等[2]发现城市旅游热门景点对于饭店空间布局具有重大影响;Wall等[3]和Ritter[4]研究表明饭店空间分布与交通便捷性有关,在交通便利的机场附近,饭店出现了明显的集聚性。随着研究内容的不断深化,一些学者开始研究饭店空间集聚性与城市发展的关系。如Cró等[5]研究了葡萄牙里斯本市酒店位置的影响因素,发现高档宾馆更接近经济繁荣的商业区,而低档宾馆则倾向于积极寻求集聚效应的收益。而Lee等[6]的研究表明,随着人类生活水平的逐步提升,饭店在城市艺术和娱乐场所周围也逐渐表现出了集聚特征。国内有关餐饮业空间布局的研究起步相对较晚,最早学者们主要研究饮食的地域差异[7]和饮食口味受地理因素和文化传统的影响[8],多为定性分析。随着计算机技术和数据分析软件的普及,研究逐渐转向定量分析,如梁璐[9]、张旭等[10]分别基于西安和南京的统计数据来分析餐饮店的空间分布,结果表明由于受到经济发展程度、人口及交通等因素的影响,城市餐饮业的发展存在着在档次、密度、种类等空间格局上的不平衡性。邬伦等[11]采用网络K函数法分析香港岛餐饮店的空间分布模式,揭示出餐饮业选址实际更加倾向于靠近交通网络中的交通站点。总之,传统研究多基于官方统计数据或实地调研数据对餐饮业空间布局进行探讨,对城市规划与发展具有一定的指导意义。但受限于海量数据采集困难且时效性差等问题,往往只能局限在宏观尺度上对城市空间进行研究,缺乏精细化研究[12]。因此,有必要基于大量样本数据点来识别和提取城市餐饮业空间集群,从而更准确地描述餐饮业在城市不同区域的空间分异特点。
近年来,随着互联网技术和移动终端技术的飞速发展,蕴含地理位置信息的网络数据呈现大规模的爆炸式增长,这为城市空间结构这一基础性研究提供了新的研究机会和挑战[13]。大数据时代的到来,在一定程度上解决了传统城市空间研究中耗时费力的数据采集问题。在这一背景下,融合开源大数据进行城市空间结构的分析已经成为当下城市空间研究中的热点[14]。而餐饮业作为城市服务业的一大重要分支,是城市空间组织的重要环节。因此,用餐饮大数据研究其空间集聚特征及影响其布局的社会、经济、文化等因素,可以辅助政府部门和规划部门审视和剖析处于快速发展中的城市空间结构,指导城市规划建设和产业选择,具有十分重要的研究意义。
Prayag等[15]运用ArcGIS技术对新西兰Hamilton城市1996-2008年的餐饮业进行了动态研究,发现CBD附近餐饮店存在明显集群,且由于酒吧、购物中心和电影院等其他互补性商业的存在,使该区域对顾客更具吸引力。Yang等[16]基于Logit模型研究了北京市酒店的分布格局,发现其明显受到公共服务设施、地铁可达性和旅游景点可达性的影响,且高档酒店对可达性更加敏感。秦萧等[17]基于大众点评数据得到南京市餐饮业集聚于主城区典型商圈的结论。谭欣等[18]基于互联网餐饮数据,采用核密度分析法从空间分布、人均消费和网络口碑 3个视角来分析北京主城区餐馆的空间分布,结果表明北京主城区内餐馆呈现从城市中心向外围递减的空间格局。杨帆等[19]基于DBSCAN空间聚类来提取广州市的餐饮集群,得到高等级餐饮集群集中于中心城区且不同等级的集群在数量上符合中心地理论模型的结论。曾璇等[20]利用网络核密度估计来分析广州市海珠区餐饮店POI的空间分布特性,结果表明餐饮业总体呈现多中心的分布特征,且在较小尺度下餐饮店的分布与公交站具有显著的集聚关系。
总的来看,在大数据逐渐引领城市空间研究的背景下,学者们开始利用数据挖掘技术从POI、大众点评和美团等网站上获取大量数据,数据来源趋于多样化。研究方法也从基于ArcGIS、GeoDa等软件的热点分析[15]、核密度分析[17-18,20]等逐步扩展到用空间聚类如基于密度的DBSCAN算法[19,21]进行城市餐饮业空间布局的系统分析。但是还存在数据量相对不完整,如文献[18]中仅包括北京主城区17 512家餐饮店,文献[19]中包含广州市27 037家餐饮兴趣点,以及当数据集密度变化较大时,传统聚类方法失效等问题。
针对这些问题,本文以北京地区为研究对象,从互联网上实时获取大量餐饮店位置、价格信息,引入基于密度的CFSFDP(Clustering by Fast Search and Find of Density Peaks)聚类算法[22]来探究北京地区餐饮业空间分布的规律特征。与传统聚类算法不同,CFSFDP算法的优势在于聚类中心为附近区域内餐饮店分布最密集的点,并利用距离属性避免在某一热门区域内存在多个密度相近的聚类中心,错把原本属于一类的数据变成了多类的情况,从而确保聚类结果的合理性,且该算法可以处理任意形状的簇。此外,本文还根据人均消费对北京地区餐饮店的空间分布做了进一步的细化分级研究,结果发现基于密度计算得到的聚类中心和基于人均消费分级得到的中心在某些区域存在非一致性,本文进一步的探究了高密度聚类中心和高消费区域之间的关系,对影响餐饮店分布的因素进行了合理推断和解释,以期为政府城市规划和商业地理的研究提供有益借鉴。
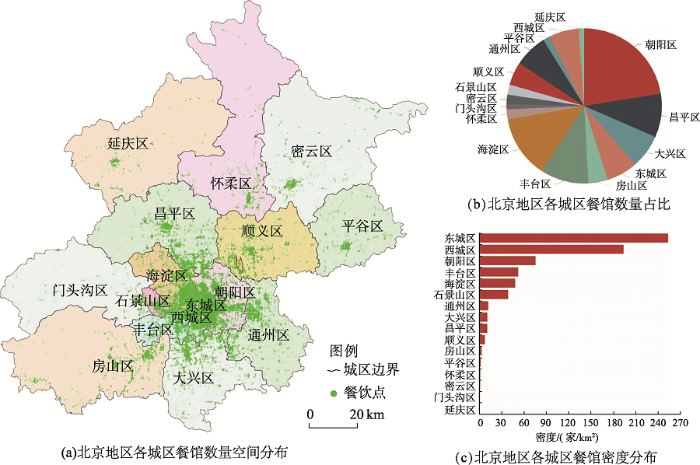
本文以北京地区为研究对象,利用网络爬虫技术获取大众点评上的餐饮店数据,包括名称、经纬度、详细地址、人均消费等属性信息,数据获取时间为2018年7月1-30日,原始数据共计178 585家餐饮店铺。为了确保结果的有效性和真实性,首先进行了数据清洗和预处理,去掉了重复和位置有误的数据,然后采用空间坐标转换技术将其经纬度转换为百度坐标,最终筛选出153 895家餐饮店用于本文研究,在百度地图上可视化后如图1所示。在数量分布特征上,朝阳区餐馆数量最多,共35 612家;海淀区餐馆数量位居第二,共20 719家;丰台区、昌平区、大兴区、东城区、西城区次之;餐馆数量最少的城区是门头沟区,仅有1539家。进一步计算各城区餐馆分布密度,得到东城区餐馆密度最高,为253家/km2;其次为西城区,密度为194家/km2;接下来依次为朝阳区76家/km2,丰台区52家/km2,海淀区48家/km2;餐馆密度最低的是延庆区,约为1家/km2。研究发现,北京中心城区餐馆数量多且分布密集,而四周城区餐馆数量明显少于中心城区,地理位置也相对分散,呈现出以中心城区为核心向外聚集程度逐级递减的特征。
地理集聚是识别餐饮业空间分布集群的主要依据,即在地理空间上显著临近的餐饮店可归属为一个集群,而空间聚类是定量识别对象间地理集聚性的经典数据挖掘方法。聚类算法大致可分为5类:① 基于划分的方法,如经典聚类算法K-means;② 基于层次的方法,如CURE、Chameleon算法;③ 基于密度的方法,如DBSCAN算法;④ 基于网格的方法,如CLIQUE、STING、Wave-Cluster算法;⑤ 基于模型的算法,如Gaussian Mixed Model算法。现有针对城市服务业的聚类分析,多采用经典K-means聚类算法[23]或基于密度的DBSCAN算法[19,21]。然而,北京地区餐饮店数量多、空间分布复杂、类簇形状多样且餐饮店密集程度变化较大,而K-means算法处理大量数据点时间开销过大,DBSCAN算法对密度变化较大的数据集聚类效果不理想。可见,传统聚类方法在处理密度分布不均的大量点时都存在不足。
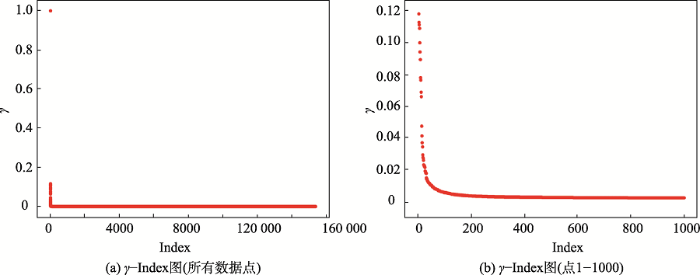
针对上述问题,本文采用Alex Rodriguez等[22]提出的一种快速搜索寻找高密度区的CFSFDP算法来提取餐饮店的聚类中心。该算法原理简单,运行效率高,可以处理任意形状的簇。由于此算法只考虑点与点之间的距离,因此不需要将点映射到一个向量空间中,大大提升了计算效率,适用于大量数据点的处理。此外,该算法在选取聚类中心时结合了密度和距离的双重信息,从而克服了传统DBSCAN算法由于高密度区域间有粘连而错把原本属于一类的数据变成了多类的缺点,确保了聚类结果的合理 性[24]。同时,针对原始CFSFDP算法需要人工辅助确定聚类中心的不足,本文借助归一化后的密度与距离的乘积排序图斜率变化趋势实现聚类中心的自动选择,避免了主观臆断对聚类结果的影响。
CFSFDP算法[22]核心是对聚类中心的刻画。聚类中心具有2个特点:① 聚类中心周围都是密度比其低的点;② 这些点距离该聚类中心的距离相比于其他聚类中心来说是最近的。基于聚类中心的上述特征,每一个数据点都要计算2个属性值:点的局部密度
式中:
将所有数据点按局部密度值降序排列,对于局部密度值
而对于其他非局部密度最大点,
文献[22]给出可根据
显然,
然而,当数据量较大时,
寻找斜率差值不低于均值
找到聚类中心后,剩余点依次被归属到它的具有更高密度的最近邻聚类中心。该算法剩余点归类简单,无需对目标函数进行迭代优化,大大提高了计算效率。
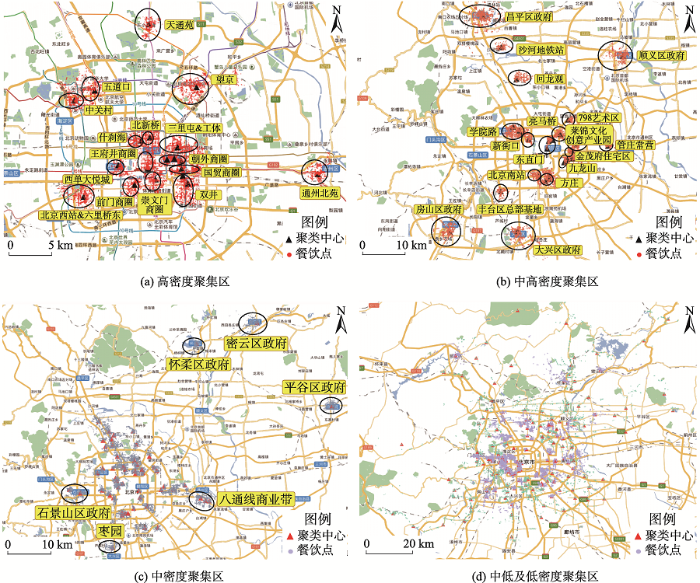
用CFSFDP算法对北京地区餐饮店进行聚类分析,结果如图3所示。可以发现,聚类中心点多集中于东城区、西城区、朝阳区及海淀区,呈圈层式分布,具有从中心城区向外密集程度逐级递减的趋势。本文按聚类中心的点密度将聚集区分为4类:① 高密度区域主要集中于三里屯、工人体育场、朝外商圈、王府井商圈、西单大悦城、通州北苑等地;② 中高密度聚类区域逐步向外扩展到学院路、新街口、亮马桥、燕莎、昌平区政府、沙河地铁站、回龙观、顺义区政府、大兴区政府等地;③ 中密度聚类区域则进一步延伸到怀柔区政府、平谷区政府、石景山区政府、八通线商业带(果园-梨园)等地;④ 中低及低密度聚集区更多更分散,除部分位于中心城区外,大多分散在各周边郊县城区。可以发现,餐饮店密度分布受到其周围经济繁华程度、是否靠近热门商圈、是否靠近住宅区以及交通便捷性的影响。繁华的商业区附近餐馆数量最多;交通便利的位置人流量较大,所以餐馆的分布较密集。朝阳区因地域面积优势和繁华程度高,包含更多的聚类中心,其他非中心城区餐饮店多集中在其区中心附近。
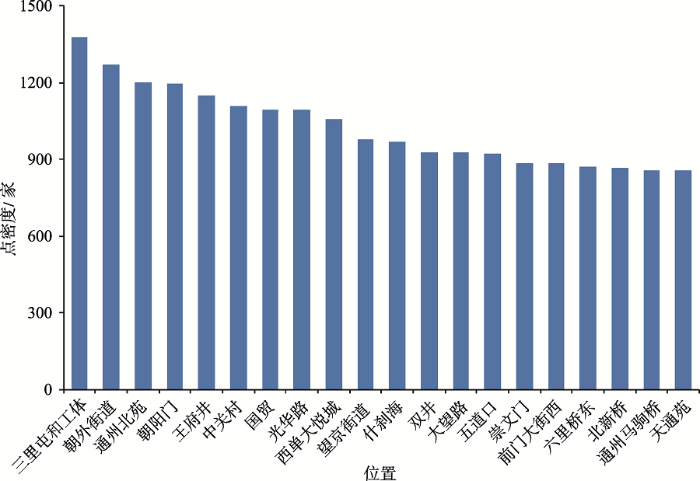
点密度排名前20的聚类中心如图4所示。餐饮店分布密集的区域可分为以下4类:
图4 点密度TOP20的餐饮服务业聚类中心
Fig. 4 The cluster centers whose local density is on TOP20
(1)热门商圈附近,如三里屯&工体、王府井、朝外街道、光华路、西单大悦城、国贸、望京、中关村、五道口等。北京地区餐饮店高密度区域大多位于热门商圈附近,且围绕商圈形成了不同等级的集聚区,一般情况下,商圈等级越高,餐饮店分布越密集。
(2)热门旅游景点附近,如天安门、崇文门、前门大街、北新桥簋街、什刹海公园等。旅游热门景点客流量大,密集的流动人口带动了餐饮业的繁荣。
(3)大型住宅区附近,如通州北苑、天通苑、双井青年公寓等。通州北苑附近社区众多,且东侧万达项目的落成带来了大量的居住人口,因此,通州北苑成为仅次于三里屯和朝外街道的餐饮店高密度区域。天通苑是北京地区大型经济适用房居住区,作为典型的近郊城乡结合部地区,吸引了大量中心城区的务工人员居住于此,因此餐饮店分布十分密集。
(4)交通线附近,如六里桥客运站东等,六里桥客运主枢纽是全国一级客运枢纽,出京去往北京房山区和石家庄沿途的车辆都经由此地。交通的便利性为其带来了大量的流动人口,一般越靠近交通枢纽的地方,餐馆分布越密集。
总体来看,北京地区餐饮服务业空间格局整体分布较为均衡,大多数商铺都处于北京的主城区,呈现出从主城区中心向外聚集度圈层递减特征和沿交通线扩散的布局特征。据官方统计资料,北京地区2017年朝阳区常住人口密度为8415人/km2;海淀区常住人口密度为8575人/km2;西城区常住人口密度为25 602人/km2;东城区常住人口密度为 22 073人/km2。将餐饮服务业空间分布与各城区常住人口的分布进行对比,发现二者有较高的一致性,这表明餐馆在空间分布上具有明显的接近市场和消费者的特征。餐饮服务业明显表现出围绕主城区重要的商圈进行布局的趋势,并受商圈规模的影响;此外,交通条件也是影响餐馆空间分布的重要因素。
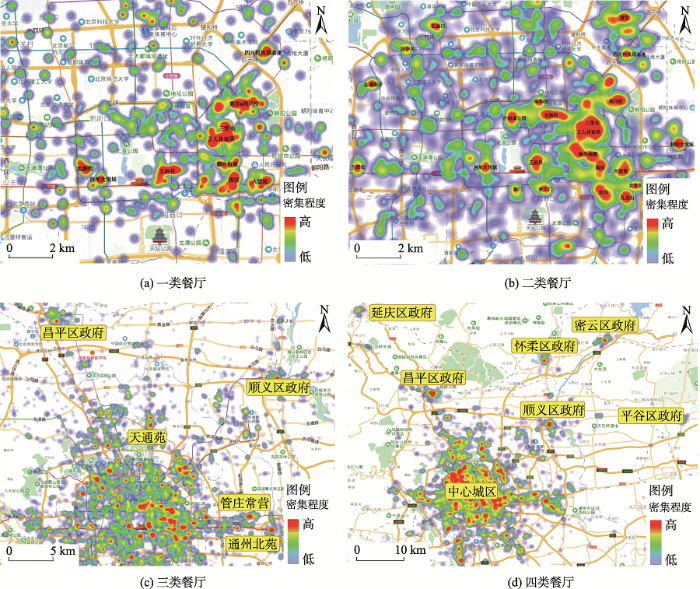
餐饮店人均消费一定程度上能够代表该地区的消费水平。经统计发现,大众点评上餐饮店的人均消费多集中在20~500元区间内。为了更好地区分餐饮店的空间分布特征,本文将人均消费额划分为4个等级:人均消费200元以上的为一类餐厅;100~200元的为二类餐厅;30~100元的为三类餐厅;人均消费30元以下为四类餐厅。对原始数据进行进一步的清洗,去掉了价格为缺省值的商铺,共余46 659家商铺数据,餐馆价格热力图如图5所示。
图5 北京地区餐厅价格热力图
Fig. 5 Thermodynamic chart of restaurants' prices in Beijing area
人均消费不低于200元的一类餐厅共计1391家,约占总数的2.98%,如图5(a)所示。从图上可知,一类餐厅仅集聚在朝阳区、东城区、西城区以及海淀区内,呈现东多西少的空间特征,且明显表现出围绕城市中重要商圈进行布局的趋势。根据一类餐厅的集聚地可得到北京地区消费水平较高的商圈主要有三里屯、工人体育场、朝外街道、国贸、大望路、亮马桥;王府井世纪大厦和新天地、东单附近;西单大悦城和金融街等。
人均消费位于100~200元的二类餐厅共计5289家,约占总数的11.34%。由图5(b)可看到,二类餐厅数量明显增多,其分布聚集地由一类餐厅聚集地逐步扩展到了朝阳区的望京、四元桥、机场高速、朝阳大悦城;东城区的前门、崇文门、东直门东四十条及北新桥附近;西城区的什刹海公园、宣武门、地铁三号线附近;海淀区的新中关、五道口、五棵松以及学校等地,但主要还是集聚在中心城区中,呈现东多西少的分布特征,而在其它城区数量则较少。
人均消费位于30~100元的三类餐厅共计25 029家,占比53.64%。三类餐馆小尺度集聚区更多更分散,逐渐到了四环以外,除了在东西城区及朝阳区出现了更多的聚集地,范围也逐步扩展到了天通苑、管庄常营、通州北苑、昌平区政府、顺义区政府附近,且表现出了沿交通线扩展的集聚特征。
人均消费不高于30元的四类餐厅则有14 950家,约占总数的32.04%。四类餐厅分布基本覆盖北京地区所有中心城区,在怀柔区、密云区、延庆区等周边城区的区中心也出现了集聚中心。
总的来说,不同消费档次餐馆的空间分布特征明显存在差异,且表现出一定的中心地等级分布特征。北京地区中低档餐馆数量占总数的绝大部分,而高档餐馆数量则较少,且多集中在东西城区CBD周边和朝阳区热门商圈和旅游景点附近。随着档次降低,餐馆的集聚特性呈现出均匀、分散的特点,且更易受交通便捷性的影响。
从上述分析可知,某地区餐厅密集程度和人均消费等级都可以作为衡量该地区繁华程度的指标。一般来说,餐厅数量越多,空间分布越密集,人均消费越高,该地区就越繁华,越有可能位于繁华商圈或热门旅游景点附近。但第4.1、4.2节的分析结果却出现了非一致性,如通州北苑及中关村等地的餐厅分布虽十分密集,但其人均消费却并不高,而金融街等虽然餐厅数量相对不多,但是其人均消费等级却很高。为了探究这种现象出现的原因,本文以所有聚类中心点的点密度为横坐标,归属于该聚类中心类别的餐饮店均价为纵坐标,绘制散点图如图6所示。同时,为了更好地解释基于餐饮店分布密集程度和人均消费得到的结果的差异性,本文选取了散点图中具有代表性的区域将其划分为4类:高密度、高消费区域;高密度、低消费区域;低密度、高消费区域;低密度、低消费区域。在地图上找到该集群所处的位置和空间区位特征,进而得到产生这种差异性的原因,详细如表1所示。
表1 北京地区典型集聚区等级体系
Tab. 1 Hierarchical system of typical gathering areas in Beijing
| 等级 | 集聚区代表 | 空间区位特征 |
|---|---|---|
| 高密度、高消费区域 | 三里屯、朝外街道、王府井大街、国贸、天安门广场、 大望路等 | 繁华商圈/热门旅游地点,人流量大;周围包括大量企业、外国商社和高端楼盘,汇集了大批高收入、高消费的白领群体 |
| 高密度、低消费区域 | 通州北苑、中关村、五道口、六里桥东、西直门等 | 辖内社区众多/邻近高等院校;具备地理优势和便利的交通条件 |
| 低密度、高消费区域 | 朝阳区裕京花园别墅附近、顺义区龙安别墅附近等 | 别墅区 |
| 低密度、低消费区域 | 大兴安定镇、房山琉璃河镇、顺义区河南村等 | 周边城区分散的居民区等 |
第一类中的三里屯是北京地区最繁华的商圈之一,汇集了大批高收入、高消费的白领群体,同时也是热门的旅游休闲场地。王府井大街作为北京最著名的商业街,俨然已成为国内外游客和中高收入白领阶层的休闲娱乐购物场所。朝外街道作为北京CBD的“西大门”,包括朝外SOHO、SOHO尚都、光华路SOHO等办公场所,同时,世贸天阶、悠唐生活广场等购物中心也吸引了更多人在朝外休闲消费。高密度的人流量导致该类地区餐饮服务业集聚,且目标客群的高消费力导致这类区域餐饮店的定价也较高。
第二类主要以通州北苑,中关村,五道口为代表。通州北苑辖内社区众多,密集的社区人口推动了餐饮业行业的飞速发展。同时,地铁通州北苑站也吸引了部分朝阳、望京周边客流,便利的交通条件进一步加快了附近餐饮业的繁荣,因此该地区餐饮业分布十分密集。但通州北苑附近多为社区住民和务工人员,因此这一地区餐饮店的定价并不高,符合目标客群的实际购买力。中关村和五道口周围是鳞次栉比的IT电子卖场和海淀高教园区,因此餐饮店分布密集,同时人均消费不高,符合IT从业者、高校等消费理念。而在北京城市发展与CBD东扩的双重压力下,越来越多的人口不断的沿着朝阳北路、朝阳路以及南面的京通快速逐步向东部扩张。管庄就位于这样的一个地理位置上,因此管庄作为未来CBD的产业功能补充区,餐饮店在这一地区慢慢出现了集聚性,由于该地区正在发展中,因此均价相对也并不高,属于餐饮店密度高,但消费相对较低的地区。
第三类是以朝阳区裕京花园别墅区为代表的餐饮店分布稀疏,但人均消费较高的区域。北京地区一些繁华的别墅区汇集了大量高收入人群,其餐饮店分布虽不密集,但却是典型的高消费地区。
第四类是大兴安定镇为代表的低密度、低消费区域,其多为北京地区经济水平相对不发达的城区中的村庄等。综上可得出餐饮店空间集聚程度和定价明显表现出接近市场和消费者的特征。
本文通过数据挖掘技术获取互联网上北京地区大量餐饮店信息,采用快速搜索发现高密度区的思想提取餐饮店聚类中心,之后对无类别剩余点进行归类从而实现聚类。与传统算法相比,本文采用的算法不仅计算效率高,适用于大量数据点的处理,且通过密度和距离的双重信息来选取聚类中心,克服传统算法高密度区域间有粘连的缺陷。最后,从其空间分布密集程度和人均消费方面对其蕴含的地理特征和规律进行了分析探讨。研究发现:
(1)北京地区餐饮店整体空间分布格局为东多西少,呈现出以主城区为核心向外聚集程度逐级递减的特征和沿交通线扩展的特点,并明显表现出围绕重要商圈、旅游热门景点和住宅区进行布局的趋势。同时,餐馆的空间分布受城市商圈规模,人口密度和交通便捷性影响较大。
(2)北京地区呈现等级体系特征,高档餐厅少,中低档餐厅多,且高档餐厅在东西城区、朝阳区及海淀区出现小范围内大规模的聚集分布,而中低档等餐饮店集聚区更多更分散,并受交通便利性的影响。
(3)餐馆分布密集程度和定价表现出接近市场和消费者的特征。繁华商圈和旅游热门地主要面向商务活动、高收入人群和游客,餐饮业呈现出高密度高消费的特点。而居住区、交通沿线、学校附近等的餐饮店则多呈现高密度低消费的特征,以契合大众百姓的消费水平。
互联网上的餐饮业信息具备数据量大、时效性强的特点,在一定程度上能够完整准确地反映出城市餐饮店分布的空间规律。但本研究还存在一定的局限性:① 原始数据集的偏差性,如大众点评上餐饮店的消费水平偏低且部分小型餐饮店并未在大众点评上注册商户等,今后的研究可以通过融合多源数据来弥补单一数据源所产生的偏差;② 由于城市的餐饮店更新速度快,因此本文只能针对近一段时间内的餐馆数据进行探索和分析,今后可通过长时间追踪城市餐饮业信息,以期从不同时空尺度来探究餐饮业空间分布的变化规律,从而为餐饮经营者选址和定价提供一定的指导和借鉴。
The authors have declared that no competing interests exist.
| [1] |
Locational characteristics of American resort hotels [J].https://doi.org/10.1080/08873639009478438 URL [本文引用: 1] 摘要
ABSTRACT Resort-hotel location has diffused from the Northeast and Midwest to the Sunbelt and West. In 1985 there were approximately 834 resort hotels and 295,617 resort-hotel rooms in the United States. More than half of these rooms were located in just three states: Florida, Nevada, and Hawaii. The present distribution of resort-hotel rooms has been influenced by three periods in resort-hotel evolution. Until the early 20th century, resort hotels were in the tradition of the 淕rand Hotel, oriented toward natural resources in the East and Midwest and serving an elite clientele. Later in this period, elite resorts were also developed in the coastal Southeast and in the Southwest. A second, transitional period beginning in the 1920s accelerated construction of resort hotels in the Southwest and along the Southeastern coast. In the third period, post World War II mobility and affluence led to a revolution in resorthotel location and function. Resort hotels are now found in urban and suburban locations and have expanded the resort concept by linking it to meetings, conventions, and business travel. This has allowed resort hotels to adapt to changing market conditions and to achieve economies of scale by spreading demand throughout the year.
|
| [2] |
Hotel location in tourism cities-Madrid 1936-1998 [J].https://doi.org/10.1016/j.annals.2005.12.008 URL [本文引用: 1] |
| [3] |
Point pattern analyses of accommodation in Toronto [J].https://doi.org/10.1016/0160-7383(85)90080-5 URL [本文引用: 1] 摘要
This paper draws attention to the significance of large cities as tourist destinations and to the importance of accomodation establishments as a component of the urban fabric. Using accomodation directories as the major source of information, the changing numbers and types of accomodation are described and the spatial distribution of accomodation is analyzed using three methods of point pattern analysis. An increase in the number of establishments has been replaced by a more recent decline. There has also been a decline in the relative importance of motels. The average size of establishments has increased markedly and the very large hotels, which are less constrained spatially than the smaller units, nevertheless are concentrated in the downtown area and the airport environ.
|
| [4] |
Hotel location in big cities. In Big City Tourism [M]. |
| [5] |
Hotel and hostel location in Lisbon: looking for their determinants [J].https://doi.org/10.1080/14616688.2017.1360386 URL [本文引用: 1] 摘要
(2017). Hotel and hostel location in Lisbon: looking for their determinants. Tourism Geographies. Ahead of Print. doi: 10.1080/14616688.2017.1360386
|
| [6] |
A spatial relationship between the distribution patterns of hotels and amenities in the United States [J].
Expanding cross-sectional survey research into a longitudinal context allows more in-depth analysis of user trends and uncovers the dynamics of recreation behaviors. Yet, with few exceptions, longitudinal analysis in recreation research is rare. Research has shown national declines in the angler population. However, less is known about whether anglers’ motivation and behavior have changed... [Show full abstract]
|
| [7] |
中国饮食文化的区域分化和发展趋势 [J].https://doi.org/10.11821/xb199403004 URL [本文引用: 1] 摘要
现代地理学主要研究地球表层的“地体”与“地象”的区域特征和地域分异的时空发展规律。以食品和菜肴为“地体”,与餐饮有关的文化作为“地象”出发,本文通过饮食文化的地域分异、菜系的形成,中国四大菜系的比较研究,阐述中国饮食文化的区域特征和地域分化的时空发展规律,并预测其发展趋势。
The culture of Chinese diet: Regional differentiation and developing trends [J].https://doi.org/10.11821/xb199403004 URL [本文引用: 1] 摘要
现代地理学主要研究地球表层的“地体”与“地象”的区域特征和地域分异的时空发展规律。以食品和菜肴为“地体”,与餐饮有关的文化作为“地象”出发,本文通过饮食文化的地域分异、菜系的形成,中国四大菜系的比较研究,阐述中国饮食文化的区域特征和地域分化的时空发展规律,并预测其发展趋势。
|
| [8] |
中国饮食辛辣口味的地理分布及其成因研究 [J].https://doi.org/10.3321/j.issn:1000-0585.2001.02.014 URL [本文引用: 1] 摘要
以往对中国饮食食辣区域的分析还完全是一种纯感性的认识 ,如简单地认为南辣北淡 ,对各个食辣区的食辣程度也是众说纷纭。本文将统计分析、实地考察、文献记载结合起来研究 ,认为经过历史时期的发展 ,现代中国在饮食口味上形成了三个辛辣口味层次地区 :即长江上中游重辛辣区 ,包括四川 (含今重庆 )、湖南、湖北、贵州、陕西南部等地 ,辛辣指数在 151至 2 5左右 ;北方微辣区 ,东及辽东半岛、北京、山东等地 ,西经山西、陕北关中及以北、甘肃大部、青海到新疆 ,是另外一个相对辛辣区 ,辛辣指数在 2 6至 15之间 ;东南沿海淡味区 ,在山东以南的东南沿海江苏、上海、浙江、福建、广东为忌辛辣的淡味区 ,辛辣指数在 17至 8间 ,其趋势是越往南辛辣指数越低。传统认为食辣仅主要是去湿驱寒 ,而本文研究表明冬季日照数少、湿润而寒冷是形成辛辣重区的主要环境因素 ,同时也分析了形成辛辣重区的社会因素如移民迁移等因素作用
The reasons and distribution of pungent flavour districts in China's dietetics [J].https://doi.org/10.3321/j.issn:1000-0585.2001.02.014 URL [本文引用: 1] 摘要
以往对中国饮食食辣区域的分析还完全是一种纯感性的认识 ,如简单地认为南辣北淡 ,对各个食辣区的食辣程度也是众说纷纭。本文将统计分析、实地考察、文献记载结合起来研究 ,认为经过历史时期的发展 ,现代中国在饮食口味上形成了三个辛辣口味层次地区 :即长江上中游重辛辣区 ,包括四川 (含今重庆 )、湖南、湖北、贵州、陕西南部等地 ,辛辣指数在 151至 2 5左右 ;北方微辣区 ,东及辽东半岛、北京、山东等地 ,西经山西、陕北关中及以北、甘肃大部、青海到新疆 ,是另外一个相对辛辣区 ,辛辣指数在 2 6至 15之间 ;东南沿海淡味区 ,在山东以南的东南沿海江苏、上海、浙江、福建、广东为忌辛辣的淡味区 ,辛辣指数在 17至 8间 ,其趋势是越往南辛辣指数越低。传统认为食辣仅主要是去湿驱寒 ,而本文研究表明冬季日照数少、湿润而寒冷是形成辛辣重区的主要环境因素 ,同时也分析了形成辛辣重区的社会因素如移民迁移等因素作用
|
| [9] |
城市餐饮业的空间格局及其影响因素分析——以西安市为例 [J].
目的通过分析西安市餐饮业的空间分布格局与空间差异,总结城市餐饮业空间分布的一般规律,为西安市和其他地区餐饮业的发展及研究提供理论依据。方法在调查西安市各类餐饮业的基础上,从文化地理学角度,运用空间分析、比较分析和因素分析的方法总结餐饮业的空间特征。结果从餐馆的密度、级别和菜系的空间分布的分析,明确了餐饮业的发展呈现出地域不平衡,并根据餐饮业空间分布的影响因素、旅游发展及城市拓展的状况来分析西安餐饮业的发展趋势。结论西安市餐饮业的空间分布明显不平衡,表现出“带核片”的空间格局,呈由中心区向四周递减的趋势,并沿主要交通干线呈串珠状分布。餐饮业的空间布局与区域经济发展水平、人口因素、文化传统、旅游活动以及城市发展格局等诸多因素有关。其中,区域经济条件对餐饮业的档次分布有决定性作用;文化传统在一定程度上决定了餐饮业的种类与数量,但随着多种文化的交融与强势文化的浸入,这一影响因素会相对淡化;人口密度对中档餐饮的分布有决定性作用;旅游活动对本土餐饮的发展与分布表现出强势影响;而城市发展格局则直接影响了餐饮业的空间特征并制约着餐饮业的未来发展趋势。
The distribution in space of urban catering and its factors: Xi’an as an example [J].
目的通过分析西安市餐饮业的空间分布格局与空间差异,总结城市餐饮业空间分布的一般规律,为西安市和其他地区餐饮业的发展及研究提供理论依据。方法在调查西安市各类餐饮业的基础上,从文化地理学角度,运用空间分析、比较分析和因素分析的方法总结餐饮业的空间特征。结果从餐馆的密度、级别和菜系的空间分布的分析,明确了餐饮业的发展呈现出地域不平衡,并根据餐饮业空间分布的影响因素、旅游发展及城市拓展的状况来分析西安餐饮业的发展趋势。结论西安市餐饮业的空间分布明显不平衡,表现出“带核片”的空间格局,呈由中心区向四周递减的趋势,并沿主要交通干线呈串珠状分布。餐饮业的空间布局与区域经济发展水平、人口因素、文化传统、旅游活动以及城市发展格局等诸多因素有关。其中,区域经济条件对餐饮业的档次分布有决定性作用;文化传统在一定程度上决定了餐饮业的种类与数量,但随着多种文化的交融与强势文化的浸入,这一影响因素会相对淡化;人口密度对中档餐饮的分布有决定性作用;旅游活动对本土餐饮的发展与分布表现出强势影响;而城市发展格局则直接影响了餐饮业的空间特征并制约着餐饮业的未来发展趋势。
|
| [10] |
南京市餐饮设施空间分布及其影响因素研究 [J].https://doi.org/10.3969/j.issn.1001-5221.2009.04.011 URL Magsci [本文引用: 1] 摘要
在网上搜索与实地调研各类餐饮设施的基础上,运用.Arcgis空间分析、比较分析和因素分析的方法总结南京市餐饮业发展的空间特征.从餐饮设施的密度、等级和经营种类空间分布的分析,结果认为,餐饮设施的发展具有地域不均衡性,数量总体上由中心向外围递减,呈圈层式发展;餐饮设施的空间分布与区域经济水平、人口分布因素、交通便捷程度、城市文化传统、空间结构演替等诸多因素有关.
Study on the distribution in space of urban caterings and its influencing factors: A case study of Nanjing [J].https://doi.org/10.3969/j.issn.1001-5221.2009.04.011 URL Magsci [本文引用: 1] 摘要
在网上搜索与实地调研各类餐饮设施的基础上,运用.Arcgis空间分析、比较分析和因素分析的方法总结南京市餐饮业发展的空间特征.从餐饮设施的密度、等级和经营种类空间分布的分析,结果认为,餐饮设施的发展具有地域不均衡性,数量总体上由中心向外围递减,呈圈层式发展;餐饮设施的空间分布与区域经济水平、人口分布因素、交通便捷程度、城市文化传统、空间结构演替等诸多因素有关.
|
| [11] |
基于网络K函数法的地理对象分布模式分析——以香港岛餐饮业空间格局为例 [J].https://doi.org/10.7702/dlydlxxkx20130502 URL [本文引用: 1] 摘要
很多地理对象的空间分布与空间上呈现网状结构的地理现象高度相关,分析这些地理对象的分布模式,在地理研究中有重要意义。该文采用由平面空间扩展到网状结构空间的网络K函数法,以香港岛餐饮业地理空间格局为例开展研究。应用单变量K函数法分析餐饮店在网状结构空间中的分布模式,应用双变量交叉K函数法分析餐饮店分布是否受交通站点及旅游景点影响,并对不同尺度下餐饮店地理选址和空间分布规律进行探索与分析。
Spatial pattern analysis of geographic features using network K-Function methods with a case study of restaurant distribution in Hong Kong Island [J].https://doi.org/10.7702/dlydlxxkx20130502 URL [本文引用: 1] 摘要
很多地理对象的空间分布与空间上呈现网状结构的地理现象高度相关,分析这些地理对象的分布模式,在地理研究中有重要意义。该文采用由平面空间扩展到网状结构空间的网络K函数法,以香港岛餐饮业地理空间格局为例开展研究。应用单变量K函数法分析餐饮店在网状结构空间中的分布模式,应用双变量交叉K函数法分析餐饮店分布是否受交通站点及旅游景点影响,并对不同尺度下餐饮店地理选址和空间分布规律进行探索与分析。
|
| [12] |
融合多源地理大数据的杭州市功能区识别和空间优化研究[D] .Discovering zones of different functions and research on spatial optimization based on multisource big data fusion in Hangzhou City[D] . |
| [13] |
基于互联网大数据的区域多层次空间结构分析研究 [J].https://doi.org/10.3724/SP.J.1047.2016.00719 URL Magsci [本文引用: 1] 摘要
<p>大数据逐渐成为各领域学者开展研究的重要途径,目前在人文-经济地理学界逐渐得到重视,并进行了初步应用,相关研究依据尺度不同可以分为居民出行和消费、城市空间结构、区域社会经济联系等。但目前大数据在人文-经济学的应用研究还属起步阶段,少有研究基于大数据对区域多层级空间结构进行系统甄别分析。本文在采集互联网大数据的基础上,结合统计数据、交通路网等传统数据评价城市综合实力、城际联系强度,并基于此构建区域空间结构计算机算法分析区域多层级空间结构。京津冀案例应用揭示了京津冀多层级体系结构,确定了各城市辐射范围、城际相互作用关系。本文初步探索使用互联网大数据甄别区域空间结构,希望能为人文-经济地理领域开展大数据应用研究提供参考。</p>
Identifying the hierarchical regional spatial structure using Internet big data [J].https://doi.org/10.3724/SP.J.1047.2016.00719 URL Magsci [本文引用: 1] 摘要
<p>大数据逐渐成为各领域学者开展研究的重要途径,目前在人文-经济地理学界逐渐得到重视,并进行了初步应用,相关研究依据尺度不同可以分为居民出行和消费、城市空间结构、区域社会经济联系等。但目前大数据在人文-经济学的应用研究还属起步阶段,少有研究基于大数据对区域多层级空间结构进行系统甄别分析。本文在采集互联网大数据的基础上,结合统计数据、交通路网等传统数据评价城市综合实力、城际联系强度,并基于此构建区域空间结构计算机算法分析区域多层级空间结构。京津冀案例应用揭示了京津冀多层级体系结构,确定了各城市辐射范围、城际相互作用关系。本文初步探索使用互联网大数据甄别区域空间结构,希望能为人文-经济地理领域开展大数据应用研究提供参考。</p>
|
| [14] |
基于百度地图热力图的城市空间结构研究——以上海中心城区为例 [J].https://doi.org/10.11819/cpr20160407a URL [本文引用: 1] 摘要
在百度地图热力图工具所提供的动态大数据基础上,尝试利用数据的实时优势建立基于空间使用强度的城市空间研究方法。并以上海中心城区为例,对人群的集聚度、集聚位置、人口重心等指标在连续一周中随时间的变化情况进行了考察和分析,发现在工作日时段内上海中心城区的人群集聚在时间上比周末持久而在空间上比周末分散,同时中心城区的人口重心移动在工作日呈现出逆时针的周期特征,而在周末则没有明显的规律。研究表明百度地图热力图数据在经过适当的挖掘和处理后能够为城市空间研究提供更为动态的视角和方法。
Research on urban spatial structure based on Baidu heat map: a case study on the central city of Shanghai [J].https://doi.org/10.11819/cpr20160407a URL [本文引用: 1] 摘要
在百度地图热力图工具所提供的动态大数据基础上,尝试利用数据的实时优势建立基于空间使用强度的城市空间研究方法。并以上海中心城区为例,对人群的集聚度、集聚位置、人口重心等指标在连续一周中随时间的变化情况进行了考察和分析,发现在工作日时段内上海中心城区的人群集聚在时间上比周末持久而在空间上比周末分散,同时中心城区的人口重心移动在工作日呈现出逆时针的周期特征,而在周末则没有明显的规律。研究表明百度地图热力图数据在经过适当的挖掘和处理后能够为城市空间研究提供更为动态的视角和方法。
|
| [15] |
Restaurant location in Hamilton, New Zealand: clustering patterns from 1996 to 2008 [J].https://doi.org/10.1108/09596111211217897 URL [本文引用: 2] 摘要
Purpose – The purpose of this study is to assess the evolution of restaurant locations in the city of Hamilton over a 12-year period (1996 to 2008) using GIS techniques. Retail theories such as central place, spatial interaction and principle of minimum differentiation are applied to the restaurant setting. Design/methodology/approach – A database of restaurants was compiled using the NZ yellow pages and contained 981 entries that consisted mainly of location addresses and types of cuisine. This paper focuses on locational patterns only. Findings – A process of geo-coding and clustering enabled the identification of two clustering periods over 12 years for city restaurants, indicating locational patterns of agglomeration within a short walking distance of the CBD and spill over effects to the north of the city. Research limitations/implications – The data do not allow statistical analysis of the variables causing the clustering but offer a visual description of the evolution. Explanations are offered on the possible planning regimes, retail provision and population changes that may explain this evolution. Practical implications – The findings allow identification of land use patterns in Hamilton city and potential areas where new restaurants could be developed. Also, the usefulness of geo-coded data in identifying clustering effects is highlighted. Originality/value – Existing location studies relate mostly to site selection criteria in the retailing industry while few have considered the evolution of restaurant locations in a specific geographic area. This paper offers a case study of Hamilton city and highlights the usefulness of GIS techniques in understanding locational patterns.
|
| [16] |
How do hotels choose their location? Evidence from hotels in Beijing [J].https://doi.org/10.1016/j.ijhm.2011.09.003 URL [本文引用: 1] 摘要
This study aims to investigate potential factors contributing to the hotel location choice by an ordered logit model incorporating both hotel and location characteristics. The results suggest that, star rating, years after opening, service diversification, ownership, agglomeration effect, public service infrastructure, road accessibility, subway accessibility, and accessibility to tourism sites are important determinants. By examining location models for different periods, different star rating levels, and different ownership, we show that, downscale hotels tend not to actively seek the benefits of agglomeration effects while upscale ones are more sensitive to accessibility. Finally, agglomeration effects are further investigated by looking into agglomeration heterogeneity, agglomeration scope, scale related and ownership related agglomeration, and agglomeration zoning.
|
| [17] |
基于网络口碑度的南京城区餐饮业空间分布格局研究——以大众点评网为例 [J].
<p>运用大众点评网(南京站)餐饮商户的点评数据,在建立口碑评价指标体系的基础上,计算各商户的口碑综合得分和排名,并对城市餐饮业的空间分布格局进行核密度分析和综合评价。研究发现,南京城区餐饮商户大致分为4 个等级,呈现“头小底大”的金字塔形状,口碑较差的商户占据绝大多数,中等口碑的商户较为缺乏,餐饮业发展综合水平较低;餐饮业的空间分布主要呈现出以新街口为服务核心,其他多个次级服务中心共生发展的格局;高等级餐饮服务中心仍旧集中在主城区范围内,发展较为孤立,大致表现为服务质量圈层递减或沿交通线路轴向扩展特征;城市商圈业态也会影响传统和休闲类餐饮商户的空间分布趋势。</p>
Spatial pattern of catering industry in Nanjing urban area based on the degree of public praise from Internet: a case study of Dianping.com [J].
<p>运用大众点评网(南京站)餐饮商户的点评数据,在建立口碑评价指标体系的基础上,计算各商户的口碑综合得分和排名,并对城市餐饮业的空间分布格局进行核密度分析和综合评价。研究发现,南京城区餐饮商户大致分为4 个等级,呈现“头小底大”的金字塔形状,口碑较差的商户占据绝大多数,中等口碑的商户较为缺乏,餐饮业发展综合水平较低;餐饮业的空间分布主要呈现出以新街口为服务核心,其他多个次级服务中心共生发展的格局;高等级餐饮服务中心仍旧集中在主城区范围内,发展较为孤立,大致表现为服务质量圈层递减或沿交通线路轴向扩展特征;城市商圈业态也会影响传统和休闲类餐饮商户的空间分布趋势。</p>
|
| [18] |
北京市主城区餐馆空间分布格局研究 [J].https://doi.org/10.3969/j.issn.1002-5006.2016.02.013 URL Magsci [本文引用: 3] 摘要
文章通过数据挖掘技术从互联网获取到北京市主城区的餐馆数据及其属性信息,运用GIS空间分析方法,从空间分布、人均消费等级和网络口碑等级3个方面对北京市主城区餐馆的空间分布格局进行了详细地描述和分析。研究发现,餐馆整体上呈现“一主两副多中心”,从城市中心向外围递减的分布格局,不同人均消费等级和网络口碑等级的餐馆呈现“中间多两头少”的纺锤形分布特征。同时,构建了17个指标,从人口分布因素、区域经济水平、交通便捷度、公共服务设施便捷度、旅游资源、互联网用户情感这6个方面对餐馆空间分布格局的影响因素进行了梳理。文章从互联网获取相关数据及居民情感信息,并将其应用到了城市规划实例中,为商业地理和城市地理的研究提供了有益借鉴。同时,文章对餐馆空间分布格局和影响因素的研究,也对城市规划、旅游行业、餐馆经营和互联网电子商务行业的发展起到积极作用。
A study on the spatial distribution pattern of restaurants in Beijing's main urban area [J].https://doi.org/10.3969/j.issn.1002-5006.2016.02.013 URL Magsci [本文引用: 3] 摘要
文章通过数据挖掘技术从互联网获取到北京市主城区的餐馆数据及其属性信息,运用GIS空间分析方法,从空间分布、人均消费等级和网络口碑等级3个方面对北京市主城区餐馆的空间分布格局进行了详细地描述和分析。研究发现,餐馆整体上呈现“一主两副多中心”,从城市中心向外围递减的分布格局,不同人均消费等级和网络口碑等级的餐馆呈现“中间多两头少”的纺锤形分布特征。同时,构建了17个指标,从人口分布因素、区域经济水平、交通便捷度、公共服务设施便捷度、旅游资源、互联网用户情感这6个方面对餐馆空间分布格局的影响因素进行了梳理。文章从互联网获取相关数据及居民情感信息,并将其应用到了城市规划实例中,为商业地理和城市地理的研究提供了有益借鉴。同时,文章对餐馆空间分布格局和影响因素的研究,也对城市规划、旅游行业、餐馆经营和互联网电子商务行业的发展起到积极作用。
|
| [19] |
基于DBSCAN空间聚类的广州市区餐饮集群识别及空间特征分析 [J].https://doi.org/10.15957/j.cnki.jjdl.2016.10.015 URL [本文引用: 4] 摘要
选取广州作为研究案例地,通过百度地图API获取广州市区27 037个餐饮类POI点的空间数据,在此基础上引入DBSCAN空间聚类算法,将其识别为397个集群,其在空间特征上呈现以天河南集群为主中心、以北京路及江南西两个集群为副中心的“一主两副”空间结构.根据集群的规模划分为6个等级,发现不同等级的集群在数量上符合中心地理论模型,并随宏观至微观呈现由基于K=3的市场原则向基于K=4的交通原则的转变.根据紧凑率、延伸度、密度及集中度等空间形态指标,将集群划分为街道型、片区型、单体—片区型、单体型四类.本研究有助于更好地认识城市餐饮业集聚特征规律,为深入认识城市实体空间提供支撑.
Cluster identification and spatial characteristics of catering in Guangzhou based on DBSCAN spatial clustering [J].https://doi.org/10.15957/j.cnki.jjdl.2016.10.015 URL [本文引用: 4] 摘要
选取广州作为研究案例地,通过百度地图API获取广州市区27 037个餐饮类POI点的空间数据,在此基础上引入DBSCAN空间聚类算法,将其识别为397个集群,其在空间特征上呈现以天河南集群为主中心、以北京路及江南西两个集群为副中心的“一主两副”空间结构.根据集群的规模划分为6个等级,发现不同等级的集群在数量上符合中心地理论模型,并随宏观至微观呈现由基于K=3的市场原则向基于K=4的交通原则的转变.根据紧凑率、延伸度、密度及集中度等空间形态指标,将集群划分为街道型、片区型、单体—片区型、单体型四类.本研究有助于更好地认识城市餐饮业集聚特征规律,为深入认识城市实体空间提供支撑.
|
| [20] |
基于网络空间点模式的餐饮店空间格局分析 [J].
餐饮业是城市经济发展的重要指标,运用合适的方法来研究城市餐饮业的空间格局特征,对城市规划、商业选址和经济发展等具有重要意义。本文以广州市海珠区为例,基于餐饮店POI(兴趣点)数据,利用核密度估计法分析餐饮店的空间分布特性,采用网络核密度法探究其热点路段的分布情况,并利用网络双变量K函数法,分析餐饮店分布与公交站和居民小区的相关性。结果表明:海珠区餐饮店总体分布呈现"西密东疏"的空间格局,具有多中心的空间分布特征;江南中街道餐饮店分布的热点路段主要集中在江南西路和江南大道中沿线,其密度随着与该沿线的距离增加而衰减;在较小范围内,餐饮店的分布与公交站具有显著的聚集关系,而与居民小区不具有显著的聚集关系。对于沿道路分布的空间地理点对象,利用网络空间点模式分析可得到较好结果。
Analysis on spatial distribution characteristics of restaurant based on network spatial point model [J].
餐饮业是城市经济发展的重要指标,运用合适的方法来研究城市餐饮业的空间格局特征,对城市规划、商业选址和经济发展等具有重要意义。本文以广州市海珠区为例,基于餐饮店POI(兴趣点)数据,利用核密度估计法分析餐饮店的空间分布特性,采用网络核密度法探究其热点路段的分布情况,并利用网络双变量K函数法,分析餐饮店分布与公交站和居民小区的相关性。结果表明:海珠区餐饮店总体分布呈现"西密东疏"的空间格局,具有多中心的空间分布特征;江南中街道餐饮店分布的热点路段主要集中在江南西路和江南大道中沿线,其密度随着与该沿线的距离增加而衰减;在较小范围内,餐饮店的分布与公交站具有显著的聚集关系,而与居民小区不具有显著的聚集关系。对于沿道路分布的空间地理点对象,利用网络空间点模式分析可得到较好结果。
|
| [21] |
基于POI数据的郑东新区服务业空间聚类研究 [J].Spatial clustering analysis of service industries in Zhengdong New District based on POI data [J]. |
| [22] |
Clustering by fast search and find of density peaks [J].https://doi.org/10.1126/science.1242072 URL [本文引用: 4] |
| [23] |
基于空间聚类分析的杭州市生产性服务业集聚区分布特征研究 [J].https://doi.org/10.16361/j.upf.201604006 URL [本文引用: 1] 摘要
运用空间数据挖掘技术中的空间聚类分析法,以商务办公楼宇为空间对象,以其地理位置为空间数据、建筑面积为属性数据进行空间聚类计算,对杭州市中心城区生产性服务业集聚区进行划分和判定。以这些集聚区为基本空间分析单元,杭州市生产性服务业的整体空间发展表现出向心集聚的特征,并且向集聚区集中的态势不断强化,生产性服务业集聚区的规模构成、功能特征与空间分布之间存在着某种关联性。分析结果表明,生产性服务业集聚区所在的或邻近的地域所承担的城市功能等级越高,集聚区的规模越大;生产性服务业集聚区的产业功能不同,空间区位分布也会不同,并在一定程度上受到地方劳动力市场空间分布的影响。在生产性服务业空间集聚发展过程中,产业自身发展与城市空间开发之间产生的矛盾,导致了生产性服务业总体上仍处于相对分散的布局,建议在空间开发模式、区位选址以及开发容量三个方面进行合理的规划引导。
Spatial distribution of producer services in Hangzhou central city based on spatial clustering analysis [J].https://doi.org/10.16361/j.upf.201604006 URL [本文引用: 1] 摘要
运用空间数据挖掘技术中的空间聚类分析法,以商务办公楼宇为空间对象,以其地理位置为空间数据、建筑面积为属性数据进行空间聚类计算,对杭州市中心城区生产性服务业集聚区进行划分和判定。以这些集聚区为基本空间分析单元,杭州市生产性服务业的整体空间发展表现出向心集聚的特征,并且向集聚区集中的态势不断强化,生产性服务业集聚区的规模构成、功能特征与空间分布之间存在着某种关联性。分析结果表明,生产性服务业集聚区所在的或邻近的地域所承担的城市功能等级越高,集聚区的规模越大;生产性服务业集聚区的产业功能不同,空间区位分布也会不同,并在一定程度上受到地方劳动力市场空间分布的影响。在生产性服务业空间集聚发展过程中,产业自身发展与城市空间开发之间产生的矛盾,导致了生产性服务业总体上仍处于相对分散的布局,建议在空间开发模式、区位选址以及开发容量三个方面进行合理的规划引导。
|
| [24] |
社交媒体地理大数据的旅游景点热度分析 [J].https://doi.org/10.16251/j.cnki.1009-2307.2016.12.034 URL [本文引用: 1] 摘要
针对大数据时代,蕴含地理位置信息的社交媒体(Social Media)数据规模正呈爆炸性增长,通过对这类时空数据的挖掘可以整合用户的群体智慧,发现热门景点或线路,为用户提供更加精细的旅行服务。该文基于2005—2016年Flickr图片分享网站中用户分享的带地理标签的图片信息,通过空间聚类以及文本语义挖掘的方法对北京市的热门景点进行了提取。此外,本文还利用北京市的历史天气信息与用户图片信息进行融合,分析在不同时间、不同天气情景下,不同景点的热度分布规律,可以为旅行爱好者提供热门景点在多种视角下的游览规律。
Popularity analysis of tourist attraction based on geotagged social media big data [J].https://doi.org/10.16251/j.cnki.1009-2307.2016.12.034 URL [本文引用: 1] 摘要
针对大数据时代,蕴含地理位置信息的社交媒体(Social Media)数据规模正呈爆炸性增长,通过对这类时空数据的挖掘可以整合用户的群体智慧,发现热门景点或线路,为用户提供更加精细的旅行服务。该文基于2005—2016年Flickr图片分享网站中用户分享的带地理标签的图片信息,通过空间聚类以及文本语义挖掘的方法对北京市的热门景点进行了提取。此外,本文还利用北京市的历史天气信息与用户图片信息进行融合,分析在不同时间、不同天气情景下,不同景点的热度分布规律,可以为旅行爱好者提供热门景点在多种视角下的游览规律。
|
| [25] |
自动确定聚类中心的密度峰值算法 [J].https://doi.org/10.3778/j.issn.1002-8331.1611-0483 URL [本文引用: 1] 摘要
密度峰值聚类算法(Density Peaks Clustering,DPC),是一种基于密度的聚类算法,该算法具有不需要指定聚类参数,能够发现非球状簇等优点.针对密度峰值算法凭借经验计算截断距离dc无法有效应对各个场景并且密度峰值算法人工选取聚类中心的方式难以准确获取实际聚类中心的缺陷,提出了一种基于基尼指数的自适应截断距离和自动获取聚类中心的方法,可以有效解决传统的DPC算法无法处理复杂数据集的缺点.该算法首先通过基尼指数自适应截断距离dc,然后计算各点的簇中心权值,再用斜率的变化找出临界点,这一策略有效避免了通过决策图人工选取聚类中心所带来的误差.实验表明,新算法不仅能够自动确定聚类中心,而且比原算法准确率更高.
Automatically determine density of cluster center of peak algorithm [J].https://doi.org/10.3778/j.issn.1002-8331.1611-0483 URL [本文引用: 1] 摘要
密度峰值聚类算法(Density Peaks Clustering,DPC),是一种基于密度的聚类算法,该算法具有不需要指定聚类参数,能够发现非球状簇等优点.针对密度峰值算法凭借经验计算截断距离dc无法有效应对各个场景并且密度峰值算法人工选取聚类中心的方式难以准确获取实际聚类中心的缺陷,提出了一种基于基尼指数的自适应截断距离和自动获取聚类中心的方法,可以有效解决传统的DPC算法无法处理复杂数据集的缺点.该算法首先通过基尼指数自适应截断距离dc,然后计算各点的簇中心权值,再用斜率的变化找出临界点,这一策略有效避免了通过决策图人工选取聚类中心所带来的误差.实验表明,新算法不仅能够自动确定聚类中心,而且比原算法准确率更高.
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}