
基于MapReduce的空间敏感性分析并行算法设计
作者简介:李 帆(1987-),男,山西太原人,硕士生,研究方向为生态信息学。E-mail:davidlee0408@gmail.com
收稿日期: 2013-12-28
要求修回日期: 2014-02-24
网络出版日期: 2014-11-01
基金资助
科学院先导专项“应对气候变化的碳收支认证及相关问题”(XDA05050600)
国家生态系统观测评估技术系统集成研究与示范(2013BAC03B00)
MSR-CNIC Windows Azure 合作计划项目“基于Windows Azure的陆地生态系统碳水通量估算与不确定性研究”
国家科技部环保公益性行业科研专项(gyh5031103)
Research on Spatial Sensitivity Analysis Using Parallel Algorithm Based on MapReduce
Received date: 2013-12-28
Request revised date: 2014-02-24
Online published: 2014-11-01
Copyright
近年来,随着遥感空间数据广泛应用于生态系统,推动了区域尺度生态遥感参数模型的发展。敏感性分析对识别模型关键参数,降低模型不确定性和完善模型具有重要作用。区域尺度的生态遥感参数模型,在进行模型参数敏感性分析时,由于涉及到空间数据的复杂运算,单机环境无法满足快速分析的要求。为了提高生态遥感参数模型空间敏感性分析效率,本文以青藏高原为研究区域,利用植被光合模型VPM(Vegetation Photosynthesis Model)和开源云计算平台Hadoop,设计和实现了基于Sobol′的生态遥感参数模型空间敏感性分析并行算法,并在实验室集群环境下进行算法分析,验证了算法的有效性和适用性。该算法的核心是利用MapReduce并行编程技术,对空间敏感性分析中的地图抽样和模型迭代过程进行任务分割,将分割后的子任务分配至不同的计算节点进行并行计算。实验表明,本文提出的并行策略,能有效缩短地图抽样和模型迭代计算时间,相比于单机算法,并行算法的运行速度提高了14倍左右。
李帆 , 何洪林 , 任小丽 , 张黎 , 路倩倩 , 于贵瑞 . 基于MapReduce的空间敏感性分析并行算法设计[J]. 地球信息科学学报, 2014 , 16(6) : 874 -881 . DOI: 10.3724/SP.J.1047.2014.00874
In recent years, with the rapid development of remote sensing technology, the spatial data represented by remote sensing images is widely used in ecosystem modeling, which promoted the development of ecological remote sensing parametric model in the regional scale. Sensitivity analysis is a key step for ecosystem model uncertainty quantification. It can identify the dominant parameters, reduce the model calibration uncertainty, and enhance the model optimization efficiency. Due to the intensive computation of spatial data during the sensitivity analysis, the traditional stand-alone environment cannot meet the requirements of rapid analysis for the regional scale remote sensing parametric model. This study designed and realized a parallel algorithm of Sobol′ spatial sensitivity analysis utilizing Hadoop, which is an open source cloud computing platform, based on VPM (Vegetation Photosynthesis Model). In order to verify the efficiency of the algorithm, we designed a comparison experiment to compare the efficiency differences of the traditional serial algorithm and the parallel algorithm. The parallel programming technology we used in this research was MapReduce, which divided the processes of map sampling and the iterative calculation during the spatial sensitivity analysis into subtasks, and assigned them to multiple computing nodes for parallel computing. The numerical experiment showed that the parallel strategy proposed in this study effectively shortened the time of model iterative calculations and significantly improved the efficiency of spatial sensitivity analysis for ecological remote sensing parametric model. Compared with the serial algorithm, the computing efficiency of the parallel algorithm was enhanced by 14 times.
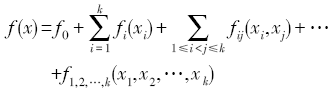
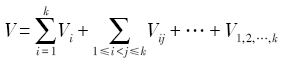
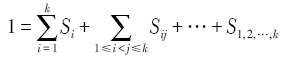
Fig. 1 Flow chart of serial spatial sensitivity analysis algorithm based on Sobol′图1 基于Sobol′的空间敏感性分析串行算法流程 |
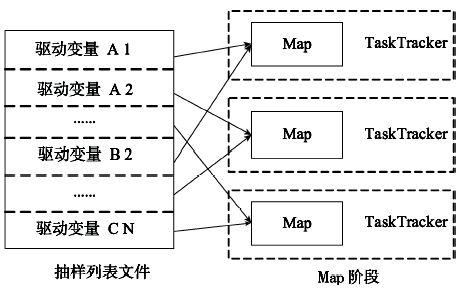
Fig. 2 Schematic diagram of map sampling parallelization for driving variables图2 驱动变量地图抽样任务并行示意图 |
Tab. 1 The input and output data of Map phase表1 Map阶段输入输出数据项 |
| 数据项 | 键(key) | 值(value) |
|---|---|---|
| 输入 | 驱动变量名 | 抽样结果编号 |
| 输出 | 空值(NullValue) | 二进制抽样结果文件 |
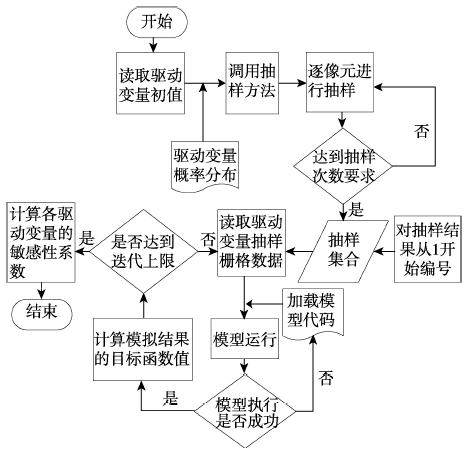
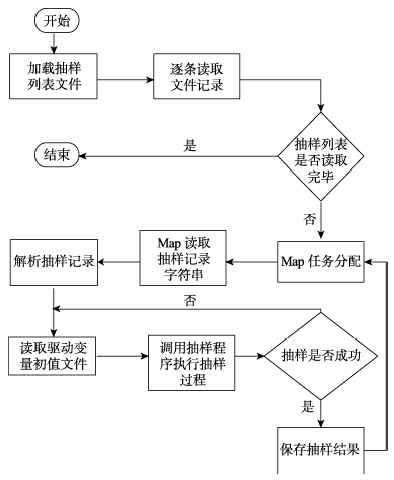
Fig. 3 Flow chart of map sampling parallel algorithm for driving variables图3 驱动变量地图抽样并行算法流程图 |
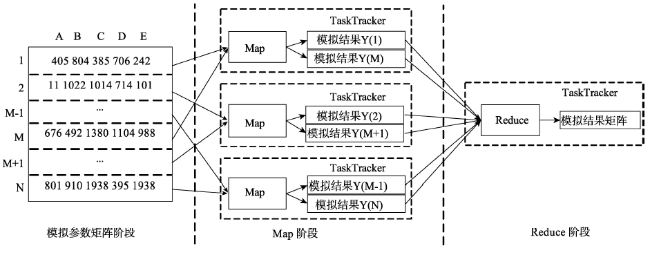
Fig. 4 Schematic diagram of the parallel algorithm of model iterative simulation图4 模型并行迭代计算示意图 |
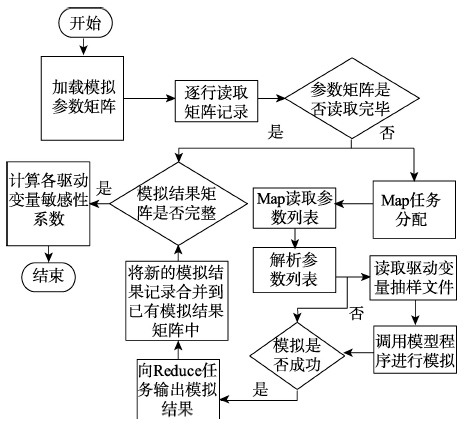
Fig. 5 Flow chart of parallel algorithm of model iterative simulation图5 模型迭代计算并行算法流程图 |
Tab. 2 The input and output data of Map and Reduce phases表2 Map和Reduce阶段输入输出数据项 |
| 数据项 | 键(Key) | 值(Value) |
|---|---|---|
| Map输入 | 矩阵行索引 | 各驱动变量抽样编号列表 |
| Map输出 | 矩阵行索引 | 模拟结果Y |
| Reduce输入 | 矩阵行索引 | 模拟结果Y |
| Reduce输出 | 空值(NullValue) | 模拟结果矩阵 |
Tab. 3 First order sensitivity indices and total order sensitivity indices of VPM model inputs表3 VPM模型参数的一阶敏感度系数和总敏感度系数 |
| 输入变量 | 一阶敏感度系数(Si) | 总敏感度系数(STi) |
|---|---|---|
| ε0 | 0.92270 | 1.00414 |
| T | 0.00508 | 0.04957 |
| PAR | 0.00042 | 0.00563 |
| EVI | 0.00184 | 0.02241 |
| LSWI | 0.00005 | 0.00070 |
| 总和 | 0.93009 | 1.08245 |
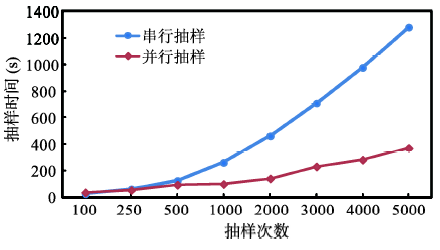
Fig. 6 Efficiency comparison between serial and parallel sampling algorithm图6 单机和并行抽样算法的运行效率对比图 |
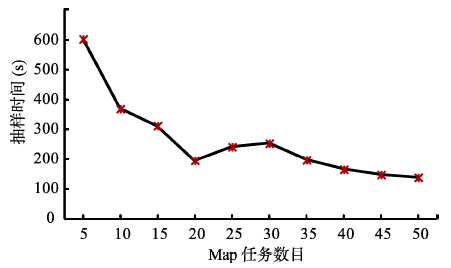
Fig. 7 Sampling efficiency comparison chart of 5000 samples using different amounts of Maps图7 抽样次数为5000时不同Map任务数目抽样效率对比图 |
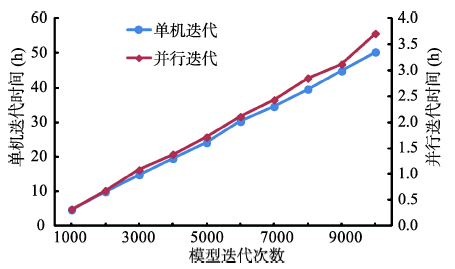
Fig. 8 Efficiency comparison chart of serial and parallel algorithms for model iterative simulation图8 单机和并行模型迭代算法的运行效率对比图 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
Apache Hadoop. Hadoop[EB/OL].
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}