
基于N-KD树的空间点数据分组算法
作者简介:魏海涛(1979-),女,博士生,研究方向为海洋数据并行计算。E-mail:Weiht@lresi.ac.cn
收稿日期: 2014-02-14
要求修回日期: 2014-07-19
网络出版日期: 2015-01-05
基金资助
海洋公益性专项“海洋环境信息云计算与云服务体系框架应用研究(201105033)
海洋预报综合信息系统(MiFSIS)研究应用(201105017)
A Spatial Point Data Grouping Algorithm Based on the N-KD Tree
Received date: 2014-02-14
Request revised date: 2014-07-19
Online published: 2015-01-05
Copyright
随着科学技术的进步,地理空间数据的分析处理面临着数据量膨胀和计算量高速增长的双重挑战,为了解决海量数据处理速度慢的问题,本文针对空间分布不均匀的点数据,从数据并行的角度,以保持数据的空间邻近性及保证数据分组后各组数据量负载均衡为目标,提出基于N-KD树(Number-K Dimension Tree)数据动态分组的方法,其是一种面向实时变化(数据量和数据空间范围变化)的空间数据动态分组方法。该方法借鉴K-D树的创建和最临近点搜索的思想,通过方差判断数据分布稀疏程度,利用最临近点搜索方法处理边界点,实现空间范围的不均等切分,保证数据分组后各组数据量基本均衡。试验表明,该方法具有较好的动态分组效果与较高的计算效率;支持各种分布状态的空间点数据的分组;分组后各组数据量负载均衡;分组算法本身有支持并行、支持分布式协同工作模式的特点。
魏海涛 , 杜云艳 , 任浩玮 , 刘张 , 易嘉伟 , 许开辉 . 基于N-KD树的空间点数据分组算法[J]. 地球信息科学学报, 2015 , 17(1) : 1 -7 . DOI: 10.3724/SP.J.1047.2015.00001
The large amount of calculations with a continuously high-speed growth required in current development of computational technology presents a great challenge to the research of spatial data processing in geography. To accelerate the processing speed of constantly updated real-time data that distributed unevenly, this study developed a dynamic grouping method based on the Number-K Dimension (N-KD) Tree technique. The method employs a data parallel algorithm to preserve spatial proximity and balance the data loads after grouping the real-time data that vary both in quantity and spatial domain. Based on the KD Tree creation, the algorithm measures the data sparsity according to the mathematic variance, addresses the point data near boundaries according to the nearest searching approach, and achieve an unequal data partition with respect to space while having balanced data loads. Experiments reveal that the method is capable of efficiently grouping the point data that have various spatial distributions and balancing the data amount among these groups. The algorithm also supports parallel computing and distributed collaborative working model, which highlights the practical values in its applications.
Key words: point data; discreteness; N-KD Tree; K-D Tree; dynamic grouping; data parallel
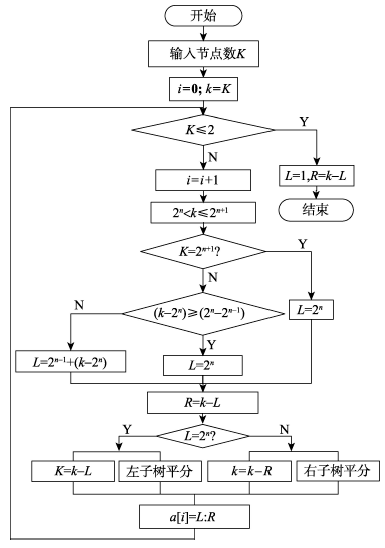
Fig. 1 Flow chart of spatial data partition图1 空间数据分割算法流程图 |
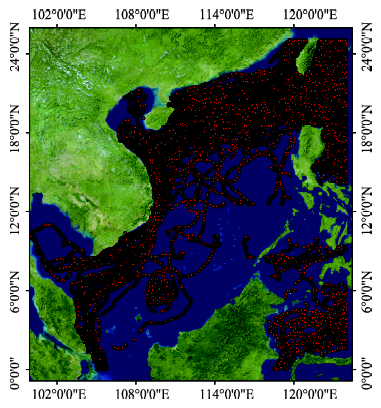
Fig. 2 Multi-source ocean buoy data visualization of the South China Sea图2 中国南海多源海洋浮标数据可视化图 |
Tab. 1 Test sample plots表 1 测试实例图组表 |
 |
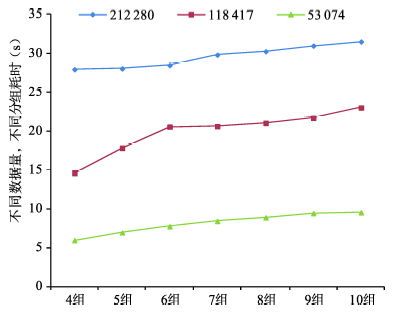
Tab. 2 Time consuming and number of data points in each group regarding to different data quantity and different partition number表 2 不同数据量、不同分组的用时及数据均衡情况 |
| 点集数据量(个) | 不同数据量在各分组情况下的耗时(s)及数据量(个) | ||||||
|---|---|---|---|---|---|---|---|
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 212 280 | 27.97 (53 074) | 28.07 (42 447) | 28.49 (35 389) | 29.84 (30 319) | 30.29 (26 530) | 31.01 (23 586) | 31.54 (21 229) |
| 118 417 | 14.58 (29 595) | 17.84 (23 677) | 20.57 (19 728) | 21.06 (16 908) | 21.06 (14 795) | 21.72 (13 136) | 23.04 (11 839) |
| 53 074 | 5.94 (13 257) | 6.94 (10 607) | 7.74 (8 841) | 8.42 (7 570) | 8.88 (6 625) | 9.42 (5 891) | 9.54 (5 298) |
Fig. 3 Time consuming in different data quantity and different partition number图3 不同数据量、不同分组的用时折线图 |
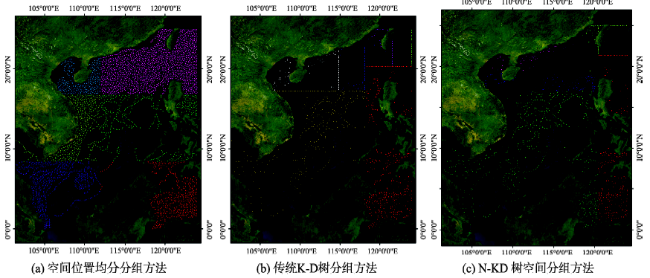
Fig. 4 Test sample comparison图4 测试对比图 |
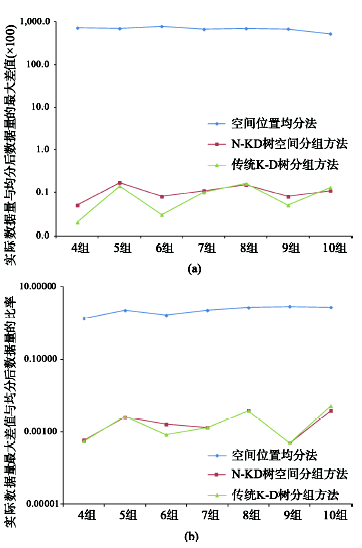
Tab. 3 The number of data in each group表3 3种方法在不同的分组数下各个分组对应的数据量 |
| 组号 | 分为4组 | 分为6组 | ||||
|---|---|---|---|---|---|---|
| 空间位置均分法 | 传统K-D树分组方法 | N-KD树空间分组方法 | 空间位置均分法 | 传统K-D树分组方法 | N-KD树空间分组方法 | |
| 1 | 30 058 | 53 070 | 53 069 | 25 028 | 35 380 | 35 382 |
| 2 | 21 370 | 53 071 | 53 067 | 114 207 | 35 379 | 35 376 |
| 3 | 36 046 | 53 070 | 53 074 | 21 976 | 35 382 | 35 374 |
| 4 | 124 805 | 53 073 | 53 074 | 17 052 | 35 380 | 35 388 |
| 5 | 19 103 | 35 383 | 35 373 | |||
| 6 | 14 914 | 35 383 | 35 393 | |||
Fig. 5 The comparison figure of data load balance图5 数据负载均衡对比图 |
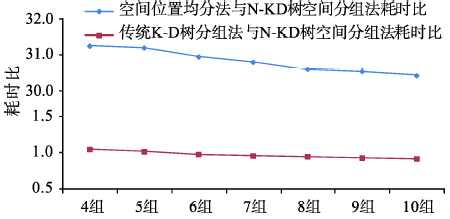
Fig. 6 Time consuming comparisons among the three algorithms图6 3种方法的耗时对比图 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}