
一种主动发现网络地理信息服务的主题爬虫
作者简介:沈 平(1991-),女,湖北人,硕士生,研究方向为地理信息资源的在线搜索以及地理信息服务。E-mail:shenping@whu.edu.cn
收稿日期: 2014-11-14
要求修回日期: 2014-12-21
网络出版日期: 2015-02-10
基金资助
国家自然科学基金面上项目(41371372)
武汉大学遥感信息工程学院探索性研发基金“基于时空计算特征挖掘的空间信息云计算优化方法研究”
A Topic Crawler for Discovering Geospatial Web Services
Received date: 2014-11-14
Request revised date: 2014-12-21
Online published: 2015-02-10
Copyright
地理信息服务已成为分布式环境下获取地理数据的重要来源,从海量的网络资源中找到地理信息服务,是共享与互操作地理数据的基础。目前,地理信息服务主动搜索主要采用通用搜索引擎的接口或者通用爬虫的抓取方式,但这2种方式存在搜索效率低、搜索结果可用性差等不足。针对这一问题,本文设计了一种搜索地理信息服务的主题爬虫。该算法在最佳优先搜索的基础上进行了改进,综合考虑网页内容的主题相关度和链接文本的主题相关度确定链接优先级,优先爬取与地理信息服务相关的链接,并通过舍弃无关网页中的无关链接,减少无效爬取,进而提高搜索效率。此外,本文采用关键词匹配结合能力文档探测的方式识别地理信息服务,有效筛选出可用的地理信息服务,提高了服务搜索结果的可利用率。最后,本文以OGC WMS为实例,实现爬虫算法的原型系统并进行实验,实验证明该算法有效可行。
沈平 , 桂志鹏 , 游兰 , 胡凯 , 吴华意 . 一种主动发现网络地理信息服务的主题爬虫[J]. 地球信息科学学报, 2015 , 17(2) : 185 -190 . DOI: 10.3724/SP.J.1047.2015.00185
In Internet era, geospatial web services (GWSs) are the primary approaches to share and interoperate geographical data. After more than ten years of development and the widely adoption on specifications, an increased number of geospatial web services have been published and are available for online public access. To obtain those geographical data, it is necessary to find an effective approach to locate and discover GWSs among massive web resources. Currently, the most widely used methods in practical for GWSs discovering are either based on Google Search API or based on generic web crawler. But the aforementioned approaches have some shortages, such as relatively inefficient search performance, irrelevant results, and low precision on GWS identification. To partially address the above issues, this paper developed a topic crawler to harvest GWSs based on the modified Best First Search strategy. The core of the proposed algorithm is that through combining the topic relevance of the link text and the topic relevance of the webpage text synthetically to predict the crawling priority of the unvisited URL. Then, we can utilize the priority thresholds to filter out the irrelevant URLs and narrow the search range at the same time. Moreover, a capabilities document detecting operation is added to GWSs recognition process to improve the search precision. Finally, we use the most widely adopted GWS specification: Web Map Service (WMS), which is proposed by Open Geospatial Consortium (OGC), as a case study. Two groups of experiments were conducted to compare the proposed method and a generic web crawler. The experimental results verified the feasibility of the proposed algorithm.
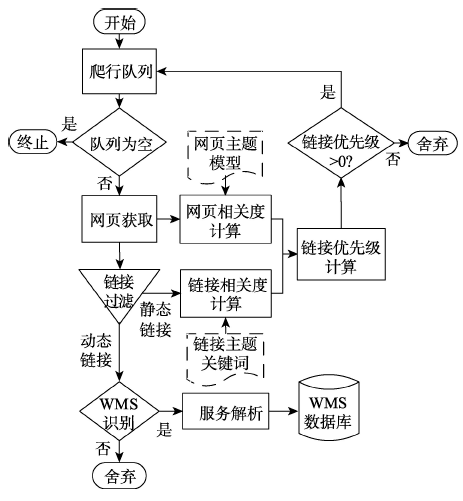
Fig. 1 Workflow of the proposed crawler algorithm图1 本文爬虫算法的工作流程图 |
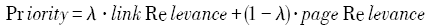
Tab. 1 The experimental results of the generic web crawler and the proposed crawler表1 两种爬虫的搜索WMS的结果对比 |
| 种子点 | 算法 | 已下载的网页总数 | WMS数量 | 精确率(%) |
|---|---|---|---|---|
| 种子点1 | 通用爬虫 | 1 820 | 888 | 48.68 |
| 本文爬虫 | 1 373 | 886 | 64.53 | |
| 种子点2 | 通用爬虫 | 18 955 | 153 | 0.81 |
| 本文爬虫 | 2 201 | 153 | 6.95 |
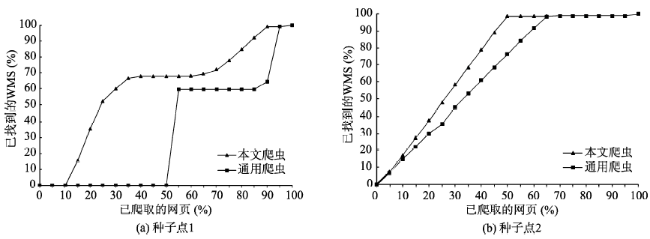
Fig. 2 Performance comparison between the proposed crawler and the generic web crawler using entry1 and entry2图2 本文爬虫和通用爬虫的性能对比(种子点1和种子点2) |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}