
匿名集序列规则与转移概率矩阵的空间预测和实验
作者简介:张海涛(1978-),男,博士,副教授,研究方向为移动GIS理论方法与关键技术、时空数据挖掘、LBS隐私保护。E-mail:zhanghaitao@njupt.edu.cn
收稿日期: 2014-10-11
要求修回日期: 2014-10-31
网络出版日期: 2015-04-10
基金资助
2010年度江苏政府留学奖学金项目
国家自然科学基金项目“基于大时空范围LBS匿名集的推理攻击及隐私保护”(41201465)
江苏省自然科学基金项目“对抗基于时空关联规则推理攻击的LBS隐私保护研究”(BK2012439)
A Method of Spatial Prediction Based on Transition Probability Matrix and Sequential Rules of Spatial-temporal K-anonymity Datasets
Received date: 2014-10-11
Request revised date: 2014-10-31
Online published: 2015-04-10
Copyright
随着位置服务(Location Based Service,LBS)的广泛应用,隐私保护成为LBS进一步深入发展亟待解决的问题,时空K-匿名成为一个主流方向。LBS应用服务器存储用户执行连续查询生成的历史匿名数据集,分析大时空尺度历史的匿名数据集,空间预测可以实现LBS应用的个性化服务。本文提出了一种融合概率统计与数据挖掘2种典型技术——马尔科夫链与序列规则,对匿名数据集中包含的特定空间区域进行预测的方法。方法包括4个过程:(1)分析序列规则、马尔科夫过程进行预测的特点;(2)以匿名数据集序列规则的均一化置信度为初始转移概率,构建n步转移概率矩阵;(3)设计以n步转移概率矩阵进行概略空间预测的方法,以及改进的指定精确路径的空间预测方法;(4)实验验证方法的性能。结果证明,该方法具有模型结构建立速度快、精确空间预测概率与真实概率的近似度可灵活调节等优点,具有可用性。
张海涛 , 葛国栋 , 黄慧慧 , 徐亮 . 匿名集序列规则与转移概率矩阵的空间预测和实验[J]. 地球信息科学学报, 2015 , 17(4) : 391 -400 . DOI: 10.3724/SP.J.1047.2015.00391
Recently, spatial-temporal K-anonymity has become a prominent method among a series of techniques for user privacy protection in Location Based Services (LBS) applications, because of its easy implementation and broad applicability. Analyzing spatial prediction scenarios based on spatial-temporal K-anonymity datasets is important in improving the utilization of LBS anonymity datasets for individualized services. In this paper, we present a spatial prediction method by combining the advantages of probabilistic statistics techniques and data mining techniques. The detailed process is divided into four phases: Phase 1, the predictive characteristics based on sequential rules and Markova chain are studied, and then an algorithm is designed to compute the n-step transition probability matrices of normalized sequential rules mined from sequences of spatial-temporal K-anonymity datasets; Phase 2, directly adopting the n-step transition probability matrices of example datasets, the simple predictions are performed; however, the drawback of this method is also found: the full path of the simple predictions cannot be learned, which is very important to the analysis of behavior patterns of LBS users; therefore in Phase 3, a precise predictive algorithm is designed, which recursively discovers the detailed k step path, its transition probability from the detailed k-1 step, and the simple k step that includes the start and the stop node only; and in Phase 4, simulation experiments are conducted, while the experimental results demonstrate that the proposed approach can build the predictive model faster than traditional methods, and can also adjust the accuracy of the predictions flexibly by setting different confidence thresholds for sequential rules of datasets.
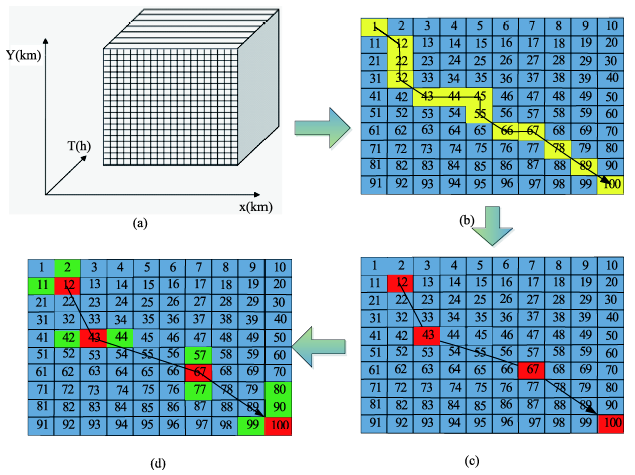
Fig. 1 The workflow of generating location anonymity in LBS continuous queries图1 LBS连续查询的匿名执行过程 |
Tab. 1 Sample datasets of anonymity sequential rules表1 匿名集序列规则的示例数据 |
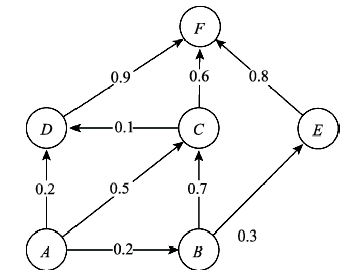
| 序号 | 序列规则 | 置信度 |
|---|---|---|
| 1 | A→B | 0.2 |
| 2 | A→C | 0.5 |
| 3 | A→D | 0.2 |
| 4 | B→C | 0.7 |
| 5 | B→E | 0.3 |
| 6 | C→D | 0.1 |
| 7 | C→F | 0.6 |
| 8 | D→F | 0.9 |
| 9 | E→F | 0.8 |
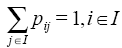 ,则称P(1)为1步转移概率矩阵。
,则称P(1)为1步转移概率矩阵。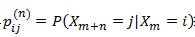 组成的矩阵,且具有性质:①
组成的矩阵,且具有性质:① 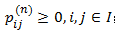 ;②
;② 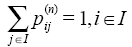 ,则称P(n)为n步转移概率矩阵。
,则称P(n)为n步转移概率矩阵。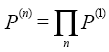 (结束n步转移概率矩阵计算的条件是:转移概率矩阵包含的所有元素值(即概率值)都低于设定的阈值精度)。
(结束n步转移概率矩阵计算的条件是:转移概率矩阵包含的所有元素值(即概率值)都低于设定的阈值精度)。Fig. 2 State diagram of one-step transition probability from original sequential rules图2 原始序列规则数据的1步转移概率 |
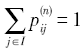 的性质,匿名集序列规则数据得到的1步转移概率,并不能直接生成齐次马尔科夫链的1步转移矩阵。例如,图2中从A出发的1步转移概率之和就不为1:
的性质,匿名集序列规则数据得到的1步转移概率,并不能直接生成齐次马尔科夫链的1步转移矩阵。例如,图2中从A出发的1步转移概率之和就不为1: 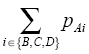 = pAB+pAC+pAD=0.9。为此,必须进行归一化操作,处理过程如式(3)所示。
= pAB+pAC+pAD=0.9。为此,必须进行归一化操作,处理过程如式(3)所示。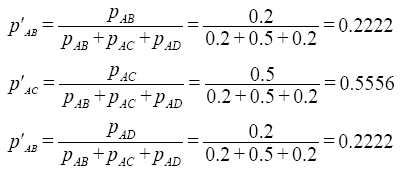
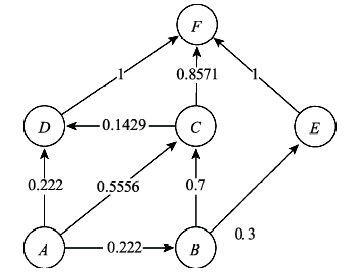
Fig. 3 State diagram of one-step transition probability matrix from normalized sequential rules图3 归一化序列规则数据的1步转移概率 |
Tab. 2 Simple predictions to arrive at target area F表2 到达目标区域F的概略预测 |
| 类型 | 目标区域 | 步数 | 概略路径 | 概率 |
|---|---|---|---|---|
| 到达 | F | 1 | C→F | 0.2222 |
| D→F | 0.5556 | |||
| E→F | 0.2222 | |||
| 2 | A→F | 0.6984 | ||
| B→F | 0.89997 | |||
| C→F | 0.1429 | |||
| 3 | A→F | 0.2794 | ||
| B→F | 0.10003 | |||
| 4 | A→F | 0.0222 |
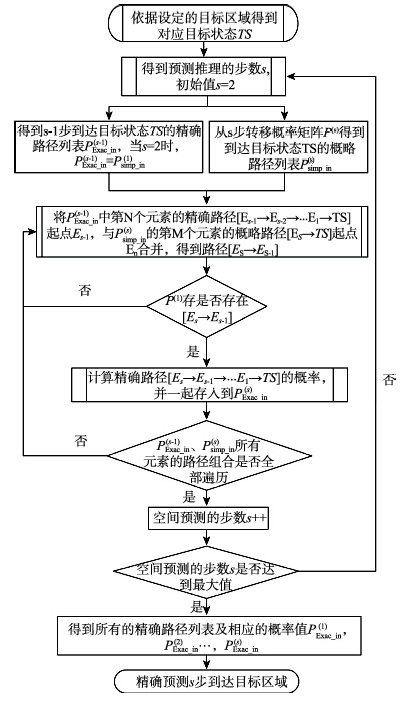
Fig. 4 Flowchart of the precise prediction to arrive at the target area图4 精确预测到达目标状态的算法实现流程 |
Tab. 3 Precise predictions to arrive at target area F表3 到达目标区域F的精确预测 |
| 类型 | 目标区域 | 步数 | 精确路径 | 概率 |
|---|---|---|---|---|
| 到达 | F | 2 | A→C→F | 0.4762 |
| A→D→F | 0.2222 | |||
| B→C→F | 0.59997 | |||
| B→E→F | 0.3 | |||
| C→D→F | 0.1429 | |||
| 3 | A→B→C→F | 0.1333 | ||
| A→B→E→F | 0.0666 | |||
| A→C→D→F | 0.0794 | |||
| B→C→D→F | 0.10003 | |||
| 4 | A→B→C→D→F | 0.0222 |
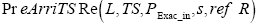
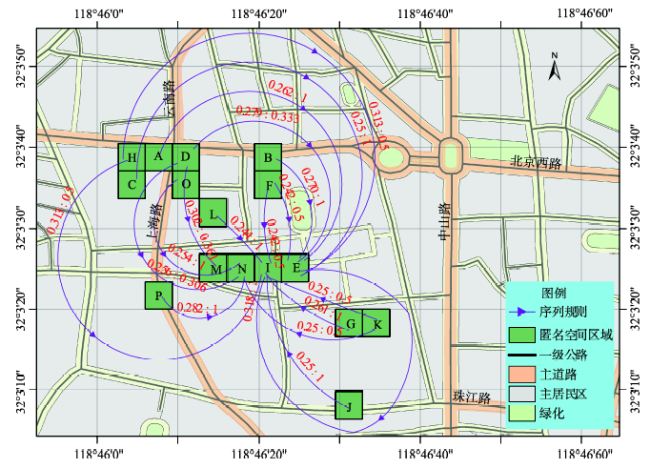
Fig. 5 Map of anonymity sequential rules图5 匿名集序列规则的地图表示 |
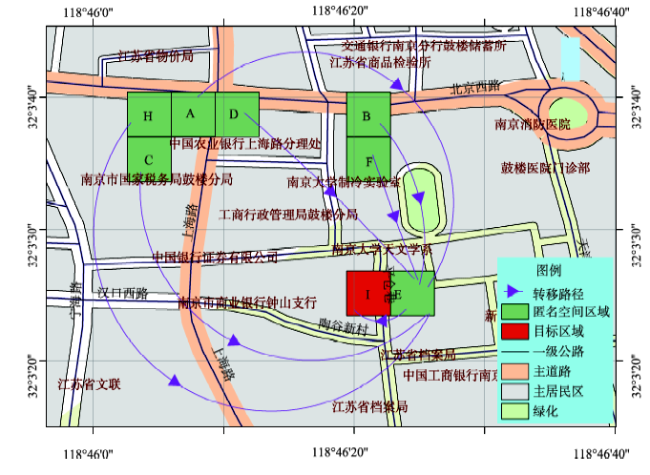
Fig. 6 Map of the precise prediction path to arrive at target area I图6 精确预测到达目标区域I路径的地图表示 |
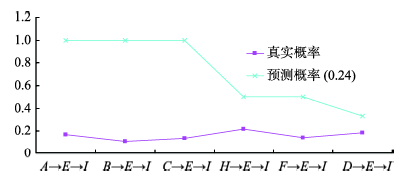
Fig. 7 Comparison between the real probability and the predicted probability图7 精确预测概率与真实概率的对比 |
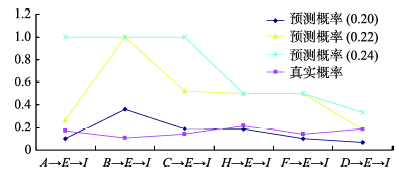
Fig. 8 Comparison between several predicted probability with different confidence thresholds and the real probability图8 不同置信度阈值的精确预测概率与真实概率的对比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}