
基于Shark/Spark的分布式空间数据分析框架
作者简介:温馨(1989-),女,硕士生,研究方向为云环境下的空间数据管理。E-mail:wenx@lreis.ac.cn
收稿日期: 2014-10-11
要求修回日期: 2014-11-26
网络出版日期: 2015-04-10
基金资助
国家高技术发展研究计划“863”项目(2013AA12A204、2013AA122302)
A Framework of Distributed Spatial Data Analysis Based on Shark/Spark
Received date: 2014-10-11
Request revised date: 2014-11-26
Online published: 2015-04-10
Copyright
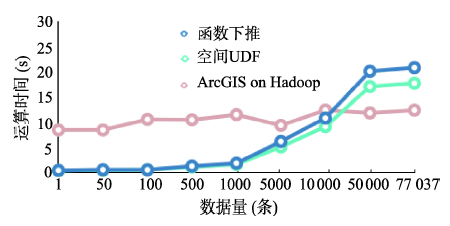
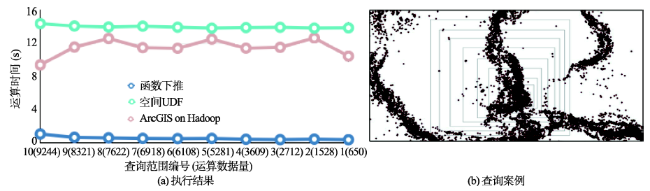
随着空间数据的与日俱增,传统依托于单节点的空间数据管理方法,已难以满足海量数据高并发的需求。云计算的兴起带来机遇与挑战,分布式技术与数据库技术的优势互补,为云计算下高效的数据管理提供了可能。本文提出一种在分布式计算引擎(Shark/Spark)中集合之关键技术(包括空间数据映射、空间数据加载、数据备份及空间查询等),将空间数据库对空间数据的高效存储、索引及查询优势与分布式计算引擎对复杂计算的优势相结合,实现一种基于Shark/Spark的分布式空间数据分析框架。在具体实现中,通过空间自定义函数和空间函数下推2种方式实现空间查询,结果表明,影响返回结果数据量的空间查询更适合下推给空间数据库完成,而不影响返回结果数据量的空间查询,利用分布式计算引擎直接运算更有优势。同时,通过与现有的一种分布式GIS方案(ArcGIS on Hadoop)对比发现,空间数据库的空间索引可有效提高查询效率,空间数据管理也更加独立。
温馨 , 罗侃 , 陈荣国 . 基于Shark/Spark的分布式空间数据分析框架[J]. 地球信息科学学报, 2015 , 17(4) : 401 -407 . DOI: 10.3724/SP.J.1047.2015.00401
With the development of technology, spatial datasets continue increasing in an incredible speed. Traditional data management based on single-node DBMS hardly meets the demands of high-concurrence in massive data. The rise of cloud computing brings brand new opportunities and challenges. Some researchers adopt a hybrid solution that combines the fault tolerance, heterogeneous cluster, and distributed computing framework together for efficient performances. Derived from the computing framework of Spark, Shark is a computing engine for fast data analysis. When a query is submitted, Shark compiles the query into an operator tree represented by RDDs, which will then be translated by Spark into a graph of tasks for execution. Shark does not support spatial query at the moment; therefore, we introduce an approach to enable Shark/Spark to support spatial query. With the APIs and UDFs that provided by Shark, Shark/Spark has the capability to process spatial data fetching from spatial databases and perform spatial queries according to the demands. Integrating Shark/Spark and relevant components which include mapping, loading, backup and querying of spatial data, and taking the advantages of the efficient spatial data management of spatial databases and high performance computing that involves the large-scale data processing of Spark, a framework of distributed spatial data analysis based on Shark/Spark has been implemented. During the implementation and testing process, we found that in order to achieve a better performance, some queries which had impacts on the returned dataset, should be pushed entirely into the database layer; while the other queries should be performed in Spark. In addition, we found that this system outperformed ArcGIS on Hadoop in some queries because the spatial index of spatial databases could improve its efficiency. Moreover, data management using a spatial database would be much more independent and convenient.
Key words: Shark; Spark; Hadoop; Spatial database; Spatial query
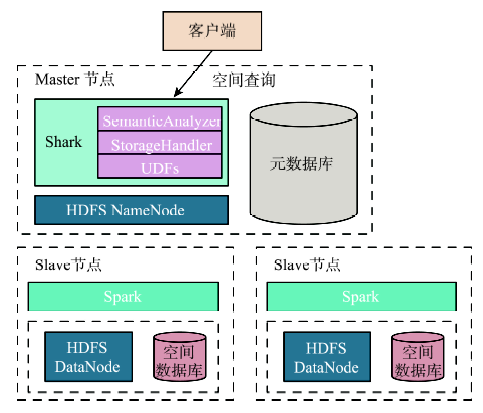
Fig. 1 The architecture of distributed spatial data analysis based on Shark/Spark图1 基于Shark/Spark的分布式空间数据分析框架 |
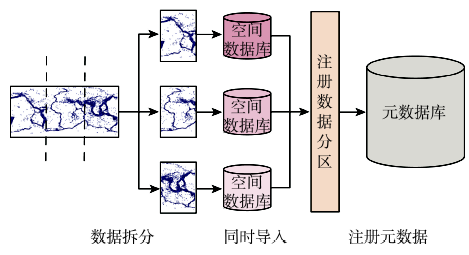
Fig. 2 Flow chart of spatial data loading图2 空间数据加载 |
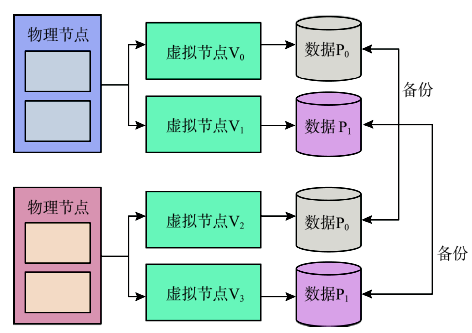
Fig. 3 Backup mechanism for spatial data图3 空间数据备份 |
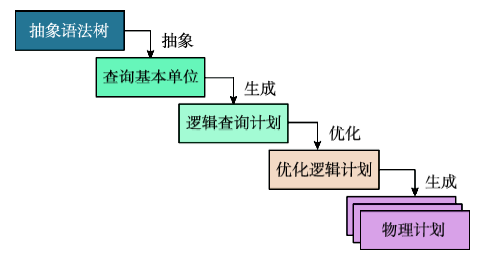
Fig. 4 Query and compiling process of spatial data object图4 空间数据对象查询解析流程 |

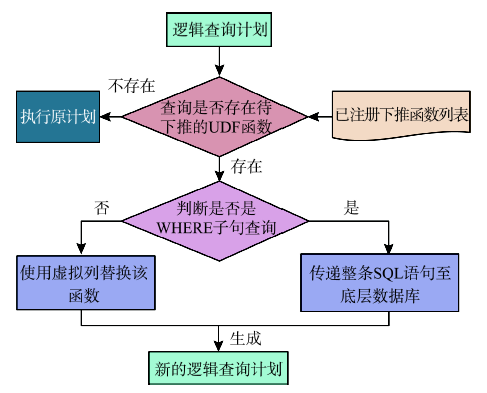
Fig. 5 Flow chart of the pushing function in spatial query图5 空间查询中函数下推流程 |
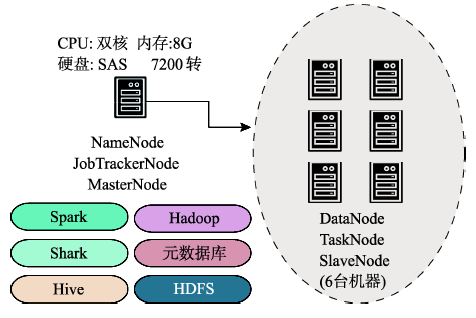
Fig. 6 Testing systems for the cluster图6 集群测试环境 |
Fig. 7 Example of the spatial query in SELECT clause图7 SELECT子句中空间查询示例 |
Fig. 8 Example of the spatial query in WHERE clause图8 WHERE子句中空间查询示例 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}