
互联网文本蕴含道路交通信息抽取的模式匹配方法
作者简介:仇培元(1986-),男,山东青岛人,博士生,研究方向为互联网空间信息搜索。E-mail:qiupy@lreis.ac.cn
收稿日期: 2014-05-04
要求修回日期: 2014-06-25
网络出版日期: 2015-04-10
基金资助
国家“863”计划课题(2012AA12A211、2013AA120305)
A Pattern Matching Method for Extracting Road Traffic Information from Internet Texts
Received date: 2014-05-04
Request revised date: 2014-06-25
Online published: 2015-04-10
Copyright
互联网页面和社交网络文本中蕴含丰富的道路交通信息,是其他交通信息采集平台的有效补充。然而,自然语言文本形式的交通信息多以线性参考或地标方位描述交通事件空间位置,且大量存在事件元素缺失或隐含现象,对交通信息的自动化抽取有着较大影响。考虑到交通信息的自然语言表达方式虽然自由随意,但表达模式相对固定,提出一种从互联网文本中抽取道路交通信息的模式匹配方法。首先,基于道路交通事件描述的语言特征构建模式库;然后,以特征词词性序列的形式表达互联网文本和抽取模式,利用DTW距离度量序列相似度,实现抽取模式匹配;最后,在匹配抽取模式和填补规则指导下获取结构化的道路交通信息。由上海市城市交通相关门户网站和微博客平台的实验过程显示,本文所提出的模式匹配方法,抽取道路交通信息的准确率和召回率分别达到90%和80%以上,表明该方法能有效抽取互联网文本蕴含的道路交通信息,且实现过程相对简单,易于扩展,具有可用性。
仇培元 , 张恒才 , 陆锋 . 互联网文本蕴含道路交通信息抽取的模式匹配方法[J]. 地球信息科学学报, 2015 , 17(4) : 416 -422 . DOI: 10.3724/SP.J.1047.2015.00416
Internet pages and microblog messages usually contain a great amount of road traffic information that can become an important data source for city road traffic collection. However, current information extraction technology for Chinese natural language text is not applicable to extract road traffic information from Internet texts for two reasons: (1) the location descriptions in these texts are usually in the form of linear reference methods; and (2) some information elements are missing or ignored in the expressions. In this paper, we propose a pattern matching method for extracting road traffic information from Internet texts. This method focuses on obtaining the location element and event element of road traffic information, due to the fact that these elements are often associated with the above issues. Firstly, extraction pattern is defined as a sequence in which each item contains two parts: part of speech (POS) of the road traffic feature words, and information attribute type. Then an extraction pattern library is established based on the linguistic features of the road traffic event description. Secondly, the Internet text after pre-progressing and the extraction patterns are both represented by POS sequences. Thirdly, the method of measuring similarity between sequences with dynamic time warping (DTW) theory is used in pattern matching to look for the most suitable extraction pattern for this text from the library. Finally, the elements and attributes of traffic information are extracted from the text under the guidance of the matching pattern. To add the missing or ignored elements, special filling rules based on the syntactic structure of information expression are introduced into this extraction process. In an experiment that takes relevant Internet texts for road traffic in Shanghai as the test data, whose sources are mainly from the official traffic information websites and Sina microblog platform, the precision and recall rate of road traffic information extraction is analyzed to be over 90% and 80% respectively. The result verifies the effectiveness of the presented approach. This method satisfies the requirement since the data accuracy is higher than average in real world public traffic service, and could effectively exact structure road traffic information from texts in any websites of different cities, by using the corresponding road lexicons.
Tab. 1 Attributes of road traffic information表1 道路交通信息属性 |
| 信息类型 | 属性名称 | 属性代码 |
|---|---|---|
| 定位信息 | 所在道路 | rm |
| 定位起点 | rs | |
| 定位终点 | re | |
| 起始方向 | fs | |
| 终止方向 | fe | |
| 偏移量 | os | |
| 时间信息 | 事件发生时间 | ts |
| 事件结束时间 | te | |
| 事件信息 | 事件类型 | ty |
| 事件状态 | sts |
Tab. 2 Parts of speech (POS) of feature words for road traffic表2 道路交通特征词词性 |
| 特征词词性 | 词性代码 | 示例 |
|---|---|---|
| 道路名称词 | ndsr | “人民路”、“鲁班立交桥”等 |
| 附属定位词 | ndrs | “内侧”、“北侧”、“匝道入口”等 |
| 方向描述词 | fd | “东”、“南”、“西”、“北”、“东北”等 |
| 数词 | m | “100”,“1500”等 |
| 量词 | q | “米”、“公里”等 |
| 介词 | pd | “到”、“往”、“向”等 |
| 事件类型词 | ndte | “临时管制”、“道路施工”等 |
| 事件状态词 | adrs | “行驶缓慢”、“压力较大”等 |
| 一般词 | co | 与表达道路交通事件特征无关的词汇 |
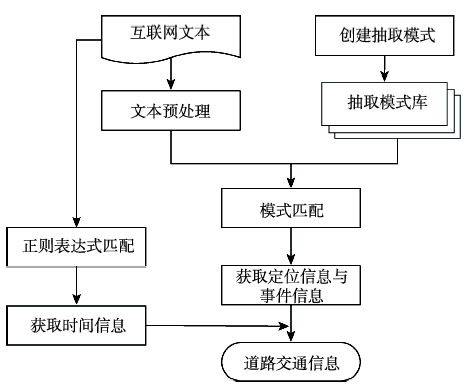
Fig. 1 Flow chart of extracting road traffic information from Internet texts图1 互联网文本蕴含道路交通信息抽取流程 |
Tab. 3 Extraction patterns of location information表3 定位信息抽取模式 |
| 抽取模式 | 实例 |
|---|---|
| {{ndsr,rm},{ndsr,rs},{pd,NULL},{ndsr,re}} | 延安北侧延西立交至虹桥枢纽 |
| {{ndsr,rm},{ndsr,rs),{pd,NULL},{ndsr,re},{fd,fs}} | 浦东济阳路东侧中环至卢浦大桥入口双向 |
| {{ndsr,rm},{ndsr,rs},{pd,NULL},{ndsr,rs},{fd,fs},{pd,NULL},{fd,fe}} | 延安高架路南侧虹井路上匝道至虹许路下匝道西向东 |
| {{ndsr,rs},{pd,NULL},{ndsr,re}} | ……,真南路出口至金沙江路入口 |
| {{ndsr,rm},{fd,fs},{m,os},{q,os}} | 逸仙路往北500 米 |
| {{ndsr,rs),{pd,NULL},{ndsr,re},{fd,fs}} | 外滩至华山路双向 |
| {{ndsr,rs},{pd,NULL},{ndsr,re},{fd,fs},{pd,NULL},{fd,fe}} | ……,娄山关路上匝道至延西立交出口匝道西向东 |
| {{ndsr,rm},{fd,fs},{pd,NULL},{fd,fe}} | 鲁班路南向北 |
| {{fd,fs},{pd,NULL},{fd,fe}} | ……,东向西 |
| {{ndsr,rm}} | 迎宾三路地道 |
| {{ndsr,rm},{fd,fs}} | 人民路隧道双向 |
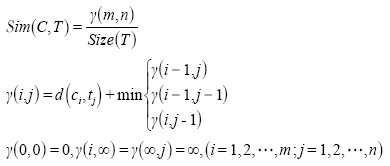
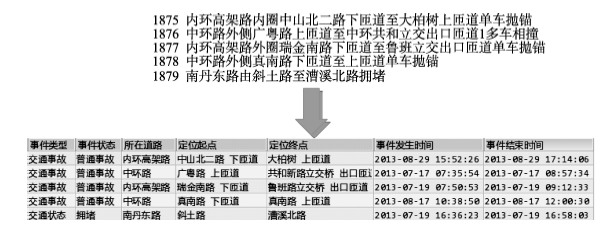
Fig. 2 Example of messages for road traffic and extracted information from official websites图2 官方网站发布交通信息短文本及抽取结果示例 |
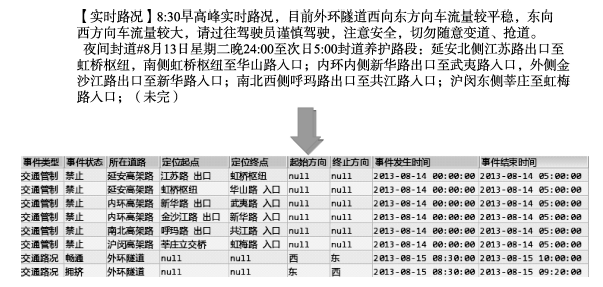
Fig. 3 Example of messages and extracted information from microblog图3 微博消息文本及抽取结果示例 |
Tab. 4 Performance of road traffic information extraction from Internet texts表4 互联网文本蕴含道路交通信息抽取实验结果 |
| 文本集合 | 蕴含交通信息总数 | 抽取交通信息数量 | 抽取正确信息数量 | 准确率(%) | 召回率(%) | F-值(%) |
|---|---|---|---|---|---|---|
| A | 2034 | 1827 | 1794 | 98.19 | 88.20 | 92.93 |
| B | 2595 | 2301 | 2160 | 93.87 | 83.24 | 88.24 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}