
地图点要素注记自动配置中聚类分组的蚁群算法应用
作者简介:周鑫鑫(1991-),男,安徽芜湖人,硕士生,研究方向为不动产信息系统及地图制图。E-mail: windofmay@foxmail.com
收稿日期: 2014-12-15
要求修回日期: 2015-03-10
网络出版日期: 2015-08-05
基金资助
国家自然科学基金项目“不动产统一登记驱动下的地籍混合维度空间数据表达模型研究”(41471318)
Automatic Label Placement of Point Feature: Using Ant Colony Algorithm Based on Group Clustering
Received date: 2014-12-15
Request revised date: 2015-03-10
Online published: 2015-08-05
Copyright
大规模点要素注记自动配置问题是地图注记的难点之一,主要受限于时间效率和注记配置质量。针对该问题,本文首先提出一种椭圆形多方位多级注记待选方位配置方案,使其参数化、多元化。其次,结合点要素空间分布特征,提出一种以聚类分组的蚁群算法,并讨论和优化核心参数,实现大规模点要素的注记快速配置。实验表明,该算法计算效率明显提升,算法性能稳定。针对注记密度在5%~30%随机分布点要素的地图,其相比传统蚁群算法算法效率提高73.2%;同时,该算法的注记结果质量比传统蚁群算法注记结果质量好,注记适应度提升8.0%。实验采用抚顺县集体土地所有权界址点数据进行验证,结果表明效率提升86.7%,且注记适应度提升14.6%。本算法适用于点要素规模大、点簇疏密变化差异大的点要素注记自动配置问题的快速求解。
周鑫鑫 , 孙在宏 , 吴长彬 , 丁远 . 地图点要素注记自动配置中聚类分组的蚁群算法应用[J]. 地球信息科学学报, 2015 , 17(8) : 902 -908 . DOI: 10.3724/SP.J.1047.2015.00902
The problem of Large-scaled Point Feature Cartographic Label Placement (LS-PFCLP) is one of map labeling difficulties, which is mainly limited by time efficiency and labels’ quality. Changing this plight will accelerate the application development of Intelligent Cartography. The article firstly contraposes the form simplification of traditional potential label position scheme and puts forward an oval multi-orientations and multi-levels cartographic potential label position scheme to make a better conformation of the potential label position scheme to the actual demand, and make it parameterized and multiplex. Secondly, the article combines the space distribution features of point features to adopt an Ant Colony Algorithm based on cluster grouping (C-ACA), whose core framework is decreasing the large scale of points to plural mini-scaled point collections through DBSCAN clustering, then integrating Ant Colony Algorithm to C-ACA. In the process of C-ACA’s implementation, we discuss and optimize the core parameters, such as Eps and MinPts of DBSCAN, ant colony size parameters (、、、), and evaluation function of , to achieve Large-scaled Point Feature Cartographic Label Placement. Experiments show that C-ACA has a great contribution to the efficiency improvement of LS-PFCLP. When compared, with two cases of random points tests and one realistic boundary points case, with techniques such as Ant Colony Algorithm (ACA), the C-ACA has been proven to be an efficient choice, with better performance in both efficiency and quality. In case 1, The C-ACA improves the efficiency by 73.2 percent than normal-ACA, when the label density falls in between 5% and 30%. Moreover, the altered resultant label’ quality is 8.0 percent better than before. In case 2, the result of C-ACA has justified the stability presentation. In case 3, we have used this algorithm to process the boundary points of the collective land ownership data of Fushun county in China, which has improved the efficiency by 86.7% and the quality by 14.6% with outstanding performance. We concluded that the improved algorithm is applicable to LS-PFCLP with points that having massive quantity and greater variations of clustering density.
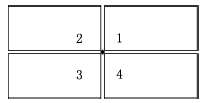
Fig. 1 The 4 directions’ cartographic pattern图1 4方位注记配置示意图 |
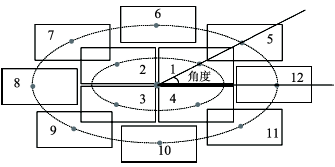
Fig. 2 The oval multi-orientations and multi-levels’ cartographic annotation-allocation pattern图2 椭圆形多方位多级注记待选方位配置方案示意图 |
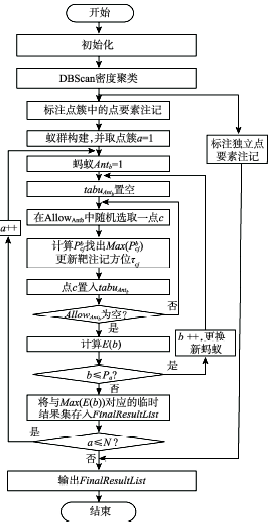
Fig. 3 Flow diagram of the algorithm图3 算法流程图 |
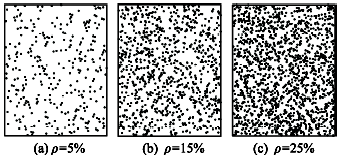
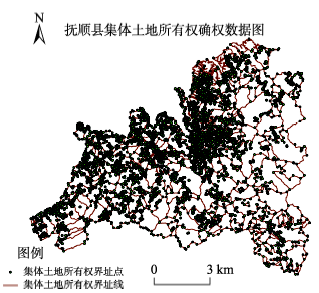
Fig. 4 Illustration of experimental data 1图4 实验1数据示意图 |
Fig. 5 Illustration of experimental data 3图5 实验3数据示意图 |
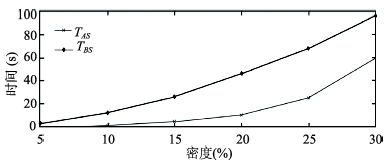
Tab. 1 The statistical result of the experimental data表1 实验结果统计表 |
| 序号 | ρ(%) | 点数 | A算法 | B算法 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| A1 | TAS | FA | TBS | FB | |||||||
| 实验1 | 1 | 5 | 318 | 63 | 0.38 | 432 | 3.06 | 436 | 87.58 | 0.92 | |
| 2 | 10 | 636 | 132 | 1.10 | 2034 | 12.22 | 2168 | 91.00 | 6.18 | ||
| 3 | 15 | 954 | 163 | 4.55 | 3774 | 26.49 | 4296 | 82.82 | 12.15 | ||
| 4 | 20 | 1272 | 138 | 10.27 | 8609 | 46.36 | 9762 | 77.85 | 11.81 | ||
| 5 | 25 | 1590 | 95 | 24.92 | 15 998 | 67.40 | 17 187 | 63.03 | 6.92 | ||
| 6 | 30 | 1908 | 50 | 60.12 | 27 041 | 95.49 | 29 068 | 37.04 | 6.97 | ||
| 实验2 | 7 | 20 | 1272 | 124 | 13.32 | 9184 | 49.41 | 9722 | 73.04 | 5.53 | |
| 8 | 20 | 1272 | 127 | 12.45 | 8604 | 49.64 | 8883 | 74.92 | 3.14 | ||
| 9 | 20 | 1272 | 129 | 12.64 | 7878 | 49.34 | 8805 | 74.38 | 10.53 | ||
| 10 | 20 | 1272 | 138 | 11.04 | 8609 | 46.78 | 8626 | 76.40 | 0.20 | ||
| 11 | 20 | 1272 | 150 | 12.33 | 7672 | 49.36 | 7794 | 75.02 | 1.57 | ||
| 12 | 20 | 1272 | 129 | 12.66 | 8457 | 48.29 | 10 370 | 73.78 | 18.45 | ||
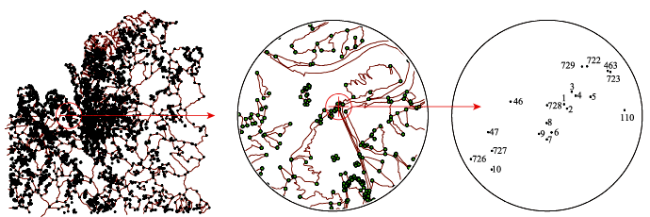
| 实验3 | 13 | 0.7 | 8390 | 1077 | 247.60 | 53 543 | 1868.22 | 62 696 | 86.75 | 14.60 | |
Fig. 6 The total time-consumption contrast between A and B图6 A算法和B算法总耗时对比图 |
Fig. 7 The label result of Fushun County boundary points based on algorithm A图7 A算法的抚顺县界址点注记配置结果示意图 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}