
萤火虫算法优化的高光谱遥感影像极限学习机分类方法
作者简介:蔡 悦(1991-),男,硕士生,研究方向为高光谱遥感分类。E-mail: cy_0717@163.com
收稿日期: 2014-10-13
要求修回日期: 2015-02-25
网络出版日期: 2015-08-05
基金资助
国家自然科学基金项目(41201341)
中国科学院数字地球重点实验室开放基金项目(2014LDE003)
河海大学中央高校基本科研业务费项目(2014B08514)
An Extreme Learning Machine Optimized by Firefly Algorithm for Hyperspectral Image Classification
Received date: 2014-10-13
Request revised date: 2015-02-25
Online published: 2015-08-05
Copyright
机器学习方法在高光谱遥感影像分类中广泛应用,本文使用新型的极限学习机(Extreme Learning Machine,ELM)进行高光谱遥感影像分类,针对ELM中正则化参数C和核参数σ,提出以萤火虫算法(Firefly Algorithm,FA)进行优化。首先,采用萤火虫算法进行高光谱遥感影像的波段选择,以便降低维数;然后,利用萤火虫算法以分类精度最大化为准则对ELM的参数组合(C,σ)进行寻优;最后,利用参数优化后的ELM分类器,对3个不同传感器的高光谱遥感影像进行分类。实验中将新型的萤火虫算法与遗传算法(Genetic Algorithm,GA)和粒子群算法(Particle Swarm Optimization,PSO)进行了对比,并将ELM的性能与支持向量机(Support Vector Machine,SVM)方法作对比。结果表明,FA优化方法优于传统的GA和PSO优化方法,ELM方法的效果在训练时间和分类准确率2个方面都优于SVM方法。实验说明,本文提出的方法具有较好的适用性和较优的分类效果。
蔡悦 , 苏红军 , 李茜楠 . 萤火虫算法优化的高光谱遥感影像极限学习机分类方法[J]. 地球信息科学学报, 2015 , 17(8) : 986 -994 . DOI: 10.3724/SP.J.1047.2015.00986
Machine learning technology has been widely used in remote sensing image classification. Extreme learning machine (ELM) is proposed recently for image classification, but the regularization and kernel parameters (C, σ) of ELM have significant influence on classification performance. In this paper, an ELM classifier with firefly algorithm (FA)-based parameter optimization is proposed for hyperspectral image classification. Firstly, FA algorithm is used for band selection in order to reduce the computational load of hyperspectral image classification. Then, the parameters (C, σ) of ELM are optimized by FA with respect to the classification accuracy. In our experiments, the firefly algorithm is also compared with other parameter optimization algorithms such as genetic algorithm (GA) and particle swarm optimization (PSO). In addition, the support vector machine (SVM)-based classification algorithm is also implemented for comparison purpose. The experiments are conducted on three classical hyperspectral remote sensing data. Results indicate that the performance of ELM method is better than SVM method from the aspects of classification accuracy and running time. Our experiments successfully prove that the proposed algorithm can provide a better performance for hyperspectral image classification.
Key words: ELM; hyperspectral remote sensing; classification; parameter optimization
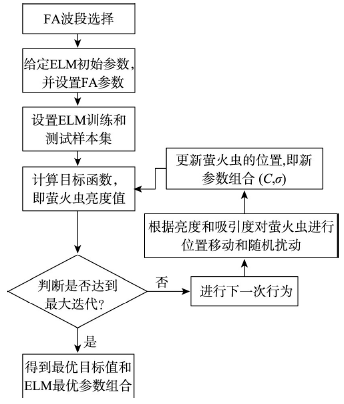
Fig. 1 Framework indicating the optimization of ELM parameters by FA图1 萤火虫算法优化ELM参数流程图 |
Fig. 2 Washington, DC Mall image data, training data and test data图2 华盛顿DC区MALL遥感影像训练样本和测试样本 |
Tab. 1 Sample sizes of DC dataset表1 DC MALL 数据样本数 |
| 类别 | 道路 | 草地 | 阴影 | 小路 | 树木 | 房屋 |
|---|---|---|---|---|---|---|
| 训练样本 | 55 | 57 | 50 | 46 | 49 | 52 |
| 测试样本 | 892 | 910 | 567 | 623 | 656 | 1123 |
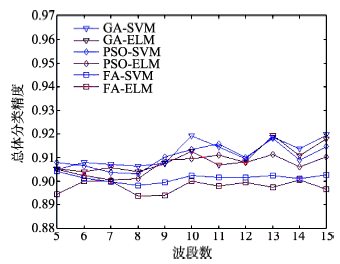
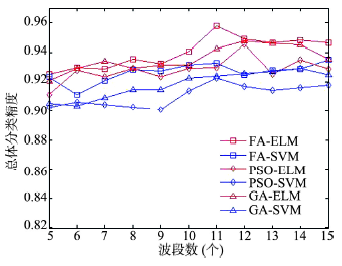
Fig. 3 Classification accuracy of DC MALL data with different algorithms图3 DC MALL数据不同算法分类结果 |
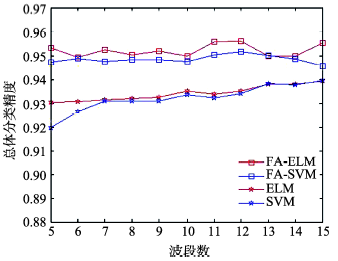
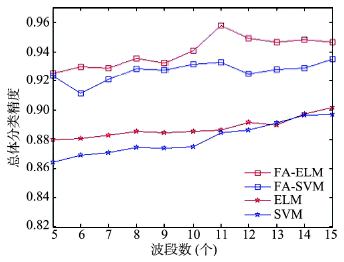
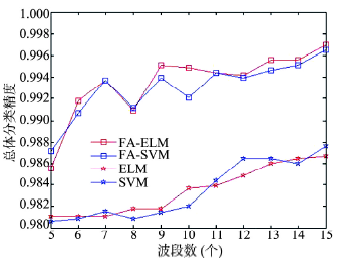
Fig. 4 Classification accuracy of DC data before and after optimization using FA algorithms图4 DC MALL数据萤火虫算法优化前后分类结果 |
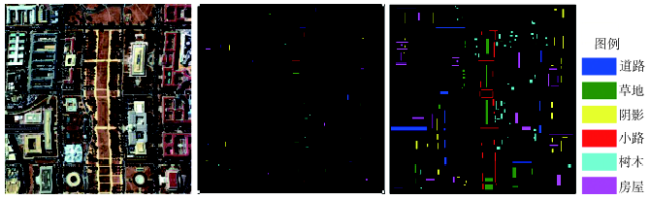
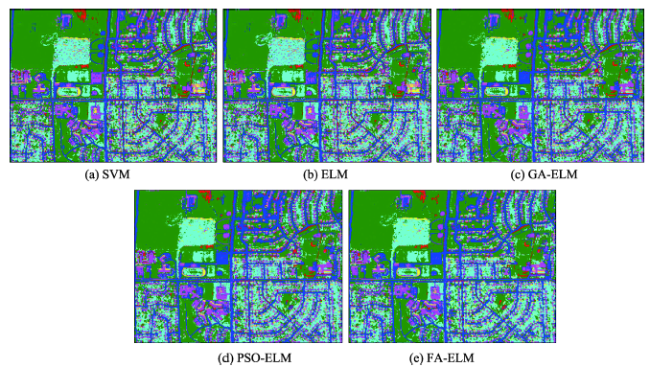
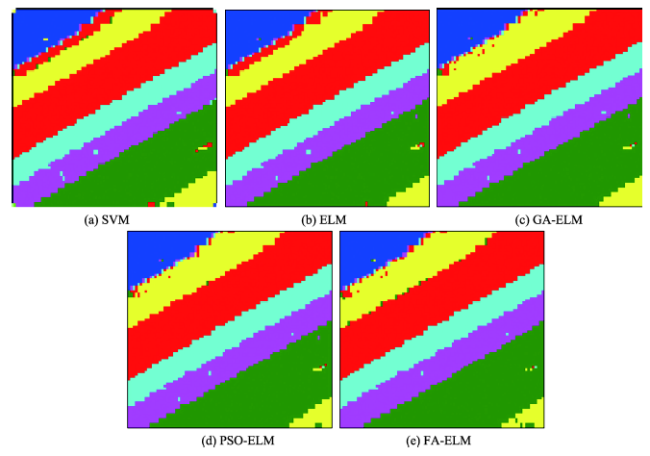
Fig. 5 Classification map of DC data using different algorithms图5 DC MALL数据分类覆盖图 |
Fig. 6 Purdue campus image, training data and test data图6 普渡遥感影像图,训练样本和测试样本 |
Tab. 2 Sample sizes of Purdue dataset表2 Purdue数据样本数 |
| 类别 | 道路 | 草地 | 阴影 | 裸地 | 树木 | 房顶 |
|---|---|---|---|---|---|---|
| 训练样本 | 73 | 72 | 49 | 69 | 67 | 74 |
| 测试样本 | 1231 | 1072 | 215 | 380 | 1321 | 1244 |
Fig. 7 Classification accuracy of Purdue data with different algorithms图7 Purdue数据不同算法分类结果 |
Fig. 8 Classification accuracy of Purdue data before and after optimization using FA algorithms图8 Purdue数据萤火虫算法优化前后分类结果 |
Fig. 9 Classification map of Purdue data using different algorithms图9 Purdue数据分类覆盖图 |
Tab. 3 Sample sizes of Salinas-A dataset表3 Salinas-A 数据样本数 |
| 样本类别 | 样本数(个) |
|---|---|
| 花椰菜 | 391 |
| 玉米 | 1343 |
| 长叶莴苣-4周 | 616 |
| 长叶莴苣-5周 | 1525 |
| 长叶莴苣-6周 | 674 |
| 长叶莴苣-7周 | 799 |
Fig. 10 Image of Salinas-A scene and Ground-truth Map图10 萨利纳斯山谷遥感影像图和样本 |
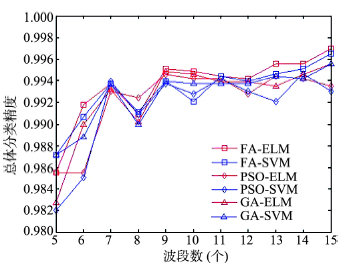
Fig. 11 Classification accuracy of Salinas-A data with different algorithms图11 Salinas-A数据不同算法分类结果 |
Fig. 12 Classification accuracy of Salinas-A data before and after optimization using FA algorithms图12 Salinas-A数据萤火虫算法优化前后分类结果 |
Fig. 13 Classification map of Salinas-A data using different algorithms图13 Salinas-A数据分类覆盖图 |
Tab. 4 Running time of ELM and SVM (seconds)表4 ELM与SVM运行时间对比(s) |
| 5 | 15 | 所有波段 | ||||||
|---|---|---|---|---|---|---|---|---|
| ELM | SVM | ELM | SVM | ELM | SVM | |||
| DC | 0.009 | 0.041 | 0.012 | 0.198 | 0.014 | 0.573 | ||
| Pu | 0.018 | 0.080 | 0.020 | 0.086 | 0.026 | 0.205 | ||
| SA | 0.028 | 0.133 | 0.036 | 0.145 | 0.043 | 0.970 | ||
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}