
一个可定位视频对象的地理空间表达框架
作者简介:韩志刚(1981-),男,博士,副教授,研究方向为GIS开发与空间分析。E-mail: zghan@henu.edu.cn
收稿日期: 2014-12-18
要求修回日期: 2015-02-23
网络出版日期: 2015-09-07
基金资助
国家自然科学基金项目(41201402);中国博士后科学基金项目(2013M531666);河南大学优秀青年科研人才培育基金项目
A Geospatial Representation Framework for Geo-tagged Video Objects
Received date: 2014-12-18
Request revised date: 2015-02-23
Online published: 2015-09-07
Copyright
可定位视频是包含位置信息的视频,它的地理空间表达是集成视频与GIS的关键问题。针对视频添加位置标签空间语义单一的不足,设计了一个可定位视频的地理空间表达框架。该框架包括视频帧与视频片段2个层次,在扩展OGC空间数据库几何要素标准基础上,分别定义了3类共7种对象描述可定位视频的空间信息。(1)视频位置(点),描述视频帧及视频片段拍摄位置及相机姿态;(2)视频轨迹(线),描述视频片段拍摄轨迹;(3)视频平面视域(面)与立体视域(体),分别描述视频帧及视频片段拍摄场景二维与三维空间范围。该框架包含了主要空间对象类型,空间表达范围较为完备,同时支持视频帧、视频片段等不同层次数据,在不改变现有数据结构基础上,实现视频数据与GIS松散耦合与有机集成。本文讨论了视频对象空间数据获取方法,定义了逻辑模型,并以可视化与检索为例进行应用分析。结果表明,该框架扩展了现有空间数据标准,易于实现,在地理可视化、视频检索及分析挖掘方面具有应用价值。
韩志刚 , 孔云峰 , 秦耀辰 , 秦奋 . 一个可定位视频对象的地理空间表达框架[J]. 地球信息科学学报, 2015 , 17(9) : 1014 -1021 . DOI: 10.3724/SP.J.1047.2015.01014
Geo-tagged video contains location information, and it is critical for true geographic representation. The geospatial representation of geo-tagged video is the key feature for the integration of video and GIS. Regarding to the disadvantage of geo-tagged representation methods for video objects with monotone spatial semantic information, a geographic representation framework for geo-tagged video objects is proposed. On the basis of extending OGC specifications for geographic information, this paper defined the respective objects in 7 types from 3 categories to describe the spatial information on two levels, including the video frame and video clip. The 3 categories include: (1) the video positions (point) to represent the location and attitude as the camera taking shoots; (2) the video trajectories (line) to portray the track of the video clip; and (3) the video field of view in plain view (polygon) or 3D (solid) space to describe the spatial extent of the video scene. The framework consists of the main spatial objects including the point, line, polygon and solid. It is more competent for demonstrating video spatial information. Meanwhile, the framework supports different levels of video data, such as the video frame and video clip. It achieves the loosely-coupled and perfectly-integrated integration of video and GIS, which does not need to alter the data structures. This paper discussed the data acquisition methods for the spatial information of video frames or clips in detail, which take use of the GPS receiver and 3D digital compass. We also developed 9 tables and defined their relations for the logical model to realize the geographic representation of geo-tagged video objects, and we analyzed the data visualization and retrieval methods by taking them as the application cases. The results show that the geographic representation framework for geo-tagged video extends the current spatial database standard. It is easy to implement and applicable in geographic visualization, video retrieval and spatial analysis or data mining.
Key words: geo-tagged video; geographic representation; GIS; data model; spatial database
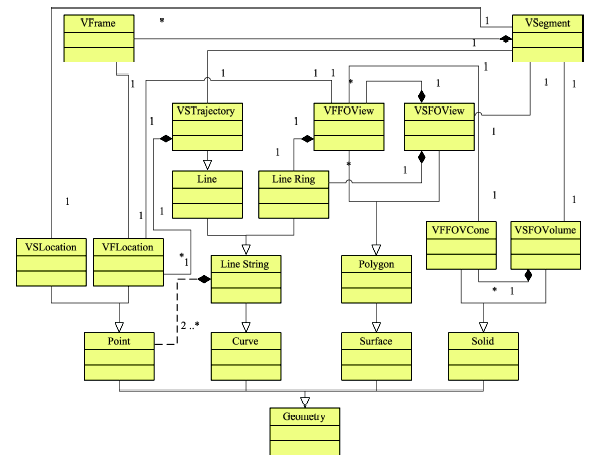
Fig. 1 Geographic representation framework for geo-tagged video objects图1 可定位视频对象的地理空间表达框架 |
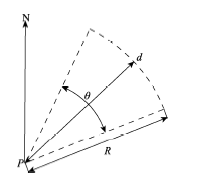
Fig. 2 Field of view of video frame in 2D图2 视频帧平面视域示意图 |
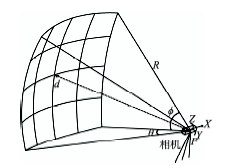
Fig. 3 Field of view of video frame in 3D图3 视频帧立体视域示意图 |
Fig. 4 Examples of the geographic representation of geo-tagged video object图4 可定位视频对象地理表达实例 |
Fig. 5 Comparison for actual and theoretical FOV of video frame图5 视频帧理论视域与实际视域对比示意图 |
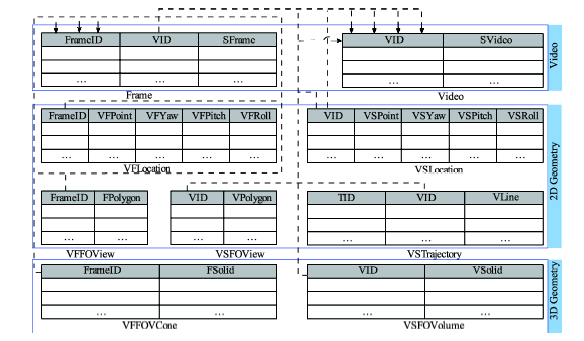
Fig. 6 Logical model of the geographic representation of geo-tagged video object图6 可定位视频对象地理表达逻辑模型实例 |
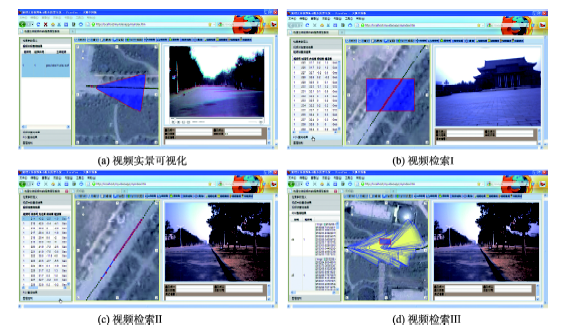
Fig. 7 Application of the geographic representation of geo-tagged video object图7 可定位视频对象地理表达应用实例 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}