
基于Storm的地理编码引擎
作者简介:余靖毅(1990 -),男,湖北武汉人,硕士生,研究方向为地理大数据计算与挖掘。E-mail: harryyu1018@pku.edu.cn
电话
收稿日期: 2015-04-15
要求修回日期: 2015-05-29
网络出版日期: 2015-12-20
基金资助
国家自然科学基金项目(41271385)
A Geocoding Engine Based on Storm
Received date: 2015-04-15
Request revised date: 2015-05-29
Online published: 2015-12-20
Copyright
近年来,随着Web 2.0和具有位置感知能力的移动计算设备的普及应用,带来了大量含有时空语义的地理大数据。在这个背景下,以地图厂商人工方式和半自动方式更新地名地址库为基础的传统地理编码服务,已难以满足新的应用需求。本文提出一种地理大数据驱动的自适应地理编码引擎的构建思路和方法,通过引入实时计算和流式计算平台Storm,实现对网络中的多源地理大数据的爬取与实时处理,加速地名地址库及相关资源的生成与更新过程,并给出了相适应的地理编码匹配方法。在实时流式计算框架基础上,通过JTS Topology Suite实现流式并行的空间操作,设计并实现了基于Storm的地理编码引擎原型系统,满足多源地理大数据的高效处理和地理编码要求。实验结果表明,该引擎通过实时流式处理可加速地址库的扩充与更新过程,并且利用地址库持续更新的方法,提升了地理编码的匹配率和定位准确度。
余靖毅 , 邬伦 , 高勇 . 基于Storm的地理编码引擎[J]. 地球信息科学学报, 2015 , 17(12) : 1431 -1441 . DOI: 10.3724/SP.J.1047.2015.01431
The explosion in geographical data with spatio-temporal characteristics has led a surge in the demand of adaptive geocoding engine construction driven by Big Geo-Data, when Web 2.0 techniques popularize and mobile devices that are capable of location-awareness become prevalent. The traditional geocoding service, which maintains gazetteers manually or semi-automatically by authoritative mapping agencies, cannot satisfy the needs of the latest researches. In order to solve the problems related to efficient storage and manipulation of massive Geo-Data in GIScience and related fields, our research proposes a method to build the adaptive geocoding engine in a geo-data-driven approach using Storm, a real-time and stream computing platform, thus to process multi-source network spatio-temporal data in real-time and accelerate the progression of building and maintaining gazetteers. Based on these data, an adaptive matching method of geocoding is built on the next stage. A prototype system of geocoding engine based on Storm is designed and implemented, which can process and geocode the multiple-source Geo-Data effectively. Experiments that were conducted on the POI datasets from Baidu reveals a high matching rate, which is more than 98%, and a accuracy rate of above 95%, while the average corresponding time per geocoding is about 75ms, which is practically applicable. The cases certify that real-time Storm-based streaming spatial operations not only consume an order of magnitude less time than traditional desktop stand-alone operations, but also enhance the matching rate and improve the positioning precision, which implies that the proposed solution is both feasible and practically effective. Our work offers new insights on collecting and processing POI datasets, enriching and building gazetteers, improving geocoding results in real-time with the use of Storm clusters. It makes contributions to apply real-time streaming computation methods to GIS for the state-of-the-art of Geo-Data computing, analytics and mining.
Key words: geocoding; real-time stream processing; Big Geo-Data; Storm
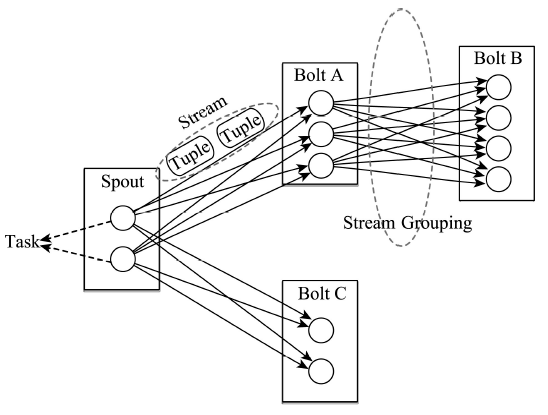
Fig. 1 The relationship between components in Storm图1 Strom平台中各种组件之间关系 |
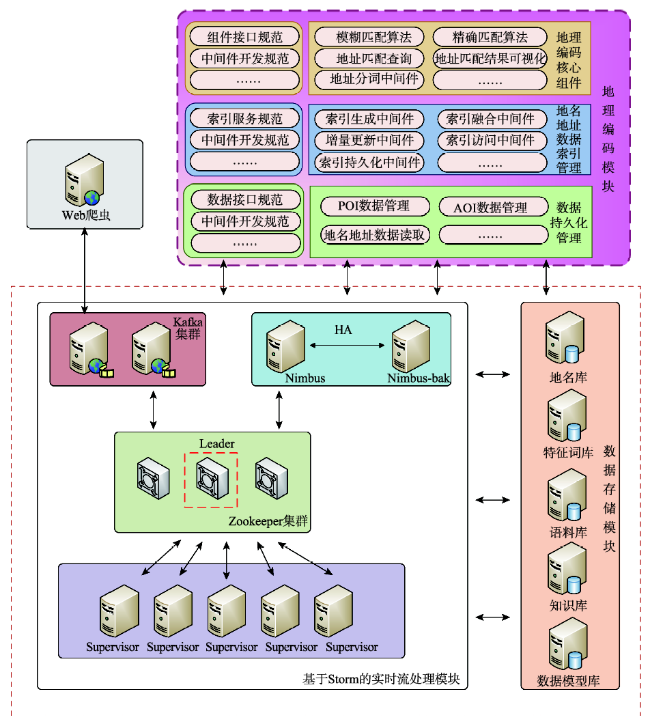
Fig. 2 System architecture图2 系统架构 |
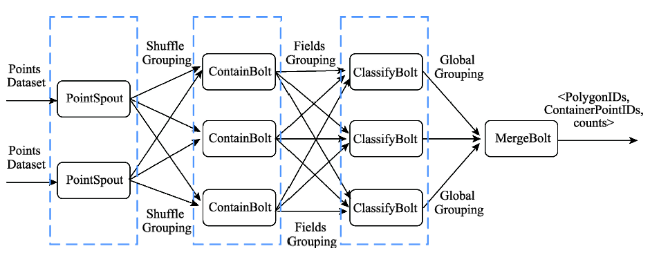
Fig. 3 The processing stream for spatial classification in Storm图3 Storm平台中空间分类的流处理过程 |
算法1 根据空间分布对点进行划分 |
| 输入:用于划分的点集合PointSet和目标多边形PolygonSet |
| 输出:对应<PolygonID, ContainerPointIDs>列表,以及每个多边形中包含的点的数量 |
| PolygonIDs getFeatures(PolygonSet) |
| < pointID, longitude, latitude>PointSet |
| /* 分组检测所属多边形过程 */ |
| Contain(pointID, longitude, latitude, PolygonIDs) |
| point new Point(pointID, longitude, latitude) |
| for iPolygonIDs do |
| /* 判断是否在多边形内 */ |
| if PolygonSet[i]contains point then |
| tuple createTuple(i, point) |
| emit(tuple) /* 发送消息单元tuple */ |
| end |
| end |
| /* 空间划分过程 */ |
| polygonKeyMap是一个HashMap结构用于记录对应多边形包含点数和点实例数组 |
| Classify(polygonID, pointID) |
| if polygonIDPolygonIDs then |
| count, pointIDs polygonKeyMap.get(polygonID) |
| countcount + 1 |
| pointIDs.add(pointID) |
| polygonKeyMap.store(count, pointIDs) |
| emit(polygonIDs, count, pointIDs) |
| end |
| /* 合并统计过程 */ |
| polygonMap是一个由polygonID作为键值,<包含点数, 点ID集合>为键的结构 |
| Merge(polygonID, count, pointIDs) |
| if polygonIDPolygonIDs then |
| polygonKeyMap polygonMap .get(polygonID) |
| polygonKeyMap.store(count, pointIDs) |
| polygonMap.set(polygonID, polygonKeyMap) |
| end |
| return PolygonIDs, ContainerPointIDs, counts |
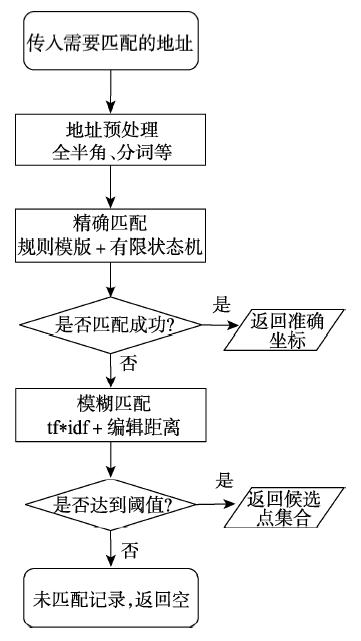
Fig. 4 Addresses matching process图4 地址匹配的流程 |
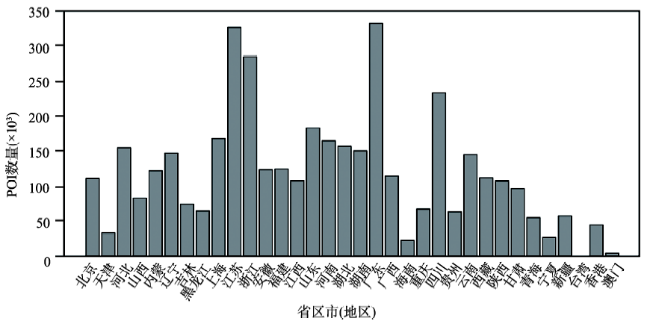
Fig. 5 The spatial distribution of POI based on Chinese provinces图5 POI数据按省区市(地区)分布情况 |
Tab. 1 The metadata structure of Baidu POI data表1 从百度爬取的原始POI元数据结构 |
| 字段 | 含义 | 举例 |
|---|---|---|
| ID | 唯一标识码 | 05324af8fb50b53e210220b1 |
| Name | 名称 | 北京大学 |
| Address | 地址 | 北京市海淀区颐和园路5 |
| Type | 类型/标签 | 高等教育,教育 |
| Telephone | 电话 | (010)62752114 |
| Zipcode | 邮编 | 100871 |
| Longitude | 经度 | 116.298518 |
| Latitude | 纬度 | 39.993301 |
Tab. 2 The roles and configurations of 5 servers表2 Storm集群中服务器的角色和配置 |
| 服务器IP | 角色 | 操作系统 | 配置信息 |
|---|---|---|---|
| 192.168.1.106 | Nimbus;Kafka;Zookeeper | Ubuntu 14.04 | 1G内存;2.4GHz处理器;40G存储 |
| 192.168.1.107, 192.168.1.108 | Supervisor | Ubuntu 14.04 | 1G内存;2.4GHz处理器;40G存储 |
| 192.168.1.121, 192.168.1.122 | Supervisor;Zookeeper | Ubuntu 14.04 | 1G内存;2.4GHz处理器;80G存储 |
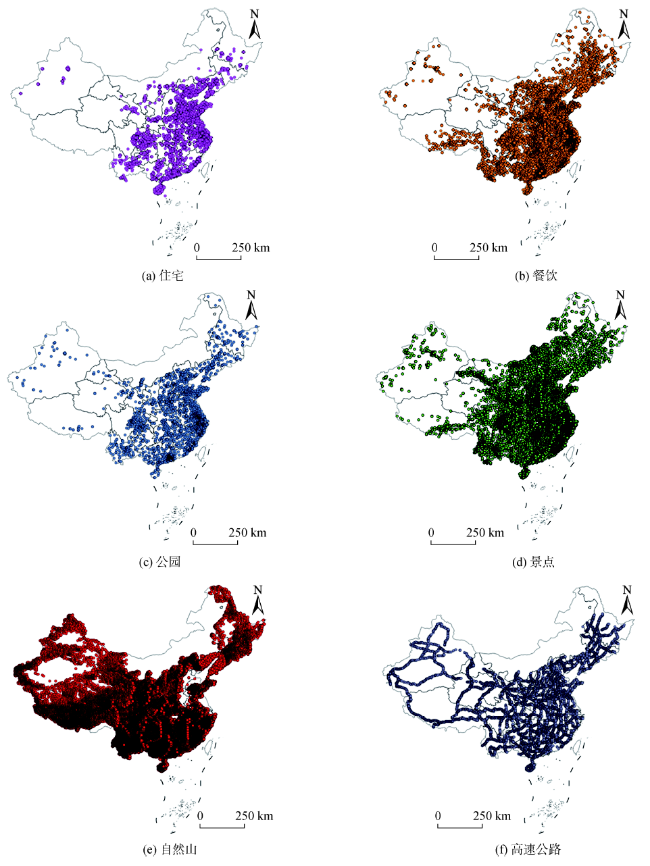
Fig. 6 The spatial distributions of POI with different types图6 各类型POI数据的空间分布 |
Tab. 3 Extracting and classifying POI表3 抽取分类POI数据 |
| POI类型 | 标识 | 关键字 | 数量 |
|---|---|---|---|
| 住宅 | Residence | 住宅,小区 | 99 722 |
| 餐饮 | Catering | 餐饮,休闲餐饮,西式快餐 | 294 106 |
| 公园 | Park | 公园 | 6118 |
| 景点 | Scenic | 风景区,旅游区,文物古迹,旅游景点 | 42 935 |
| 自然山 | Mountain | 自然山 | 262 859 |
| 高速公路 | Highway | 国道,高速道路 | 8795 |
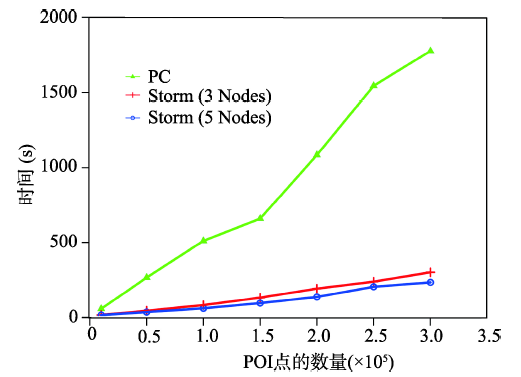
Fig. 7 Comparison of time efficiency for single desktop PC and Storm clusters图7 数据处理速度对比图 |
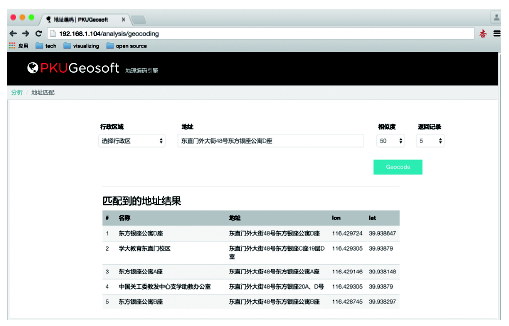
Fig. 8 The results of geocoding engine图8 地理编码引擎效果图 |
Tab. 4 Geocoding matching results表4 地理编码匹配实验结果 |
| 地址来源 | 条数 | 匹配率(%) | 准确率(%) | 耗时(s/条) |
|---|---|---|---|---|
| 随机抽取地址 | 10 000 | 100 | 97.3 | 0.075 |
| 人工构造地址 | 500 | 98.6 | 95.6 | 0.075 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}