
基于异构集群计算的地统计面插值并行算法
作者简介:云硕(1992-),男,湖北汉川人,硕士生,研究方向为高性能地理计算。E-mail: yunshuo374299544@163.com
收稿日期: 2015-10-09
要求修回日期: 2015-11-11
网络出版日期: 2015-12-20
基金资助
教育部高等学校博士学科点专项科研基金(20130145120013)
中央高校基本科研业务费用专项资金资助项目(1410491B09)
A Parallel Geostatistical Areal Interpolation Algorithm Suited for Heterogeneous Cluster Computing
Received date: 2015-10-09
Request revised date: 2015-11-11
Online published: 2015-12-20
Copyright
地统计面插值算法在空间统计分析中有广泛应用,其目的是通过一组面要素的某已知属性值估算另一组面要素的属性值。地统计面插值算法多是基于克里金(Kriging)插值及其衍生算法。克里金插值算法考虑属性在空间位置上的变异性,需计算要素之间的协方差,是典型的计算密集型算法。本文分析了基于克里金插值的地统计算法计算过程,该算法中面要素间协方差计算相互独立,可作为并行计算单元划分。另外,面要素间协方差计算可使用快速傅里叶变换(FFT)快速计算,而FFT是一种非常适合并行处理的计算密集型算法。本文根据算法特征设计了基于异构集群计算的并行算法,并使用MPI+CUDA实现了该算法。实验结果表明,本文实现的算法比使用MPI实现的CPU集群的算法有更好的性能,具备良好的可扩展性,并且随着插值精度提高表现出更好的性能。
云硕 , 关庆锋 . 基于异构集群计算的地统计面插值并行算法[J]. 地球信息科学学报, 2015 , 17(12) : 1465 -1473 . DOI: 10.3724/SP.J.1047.2015.01465
The goal of geostatistical areal interpolation is to estimate the unknown attribute values of a group of areal units using another group of areal units with known attribute values. Most geostatistical areal interpolation algorithms are based on the Kriging interpolation and its derivatives. Kriging interpolation considers the spatial variability of attributes and the covariance between the spatial units. It is a typical computationally intensive algorithm. The computation of covariance between a pair of areal unitsis independent from the computation between the other pairs, thus it is parallelizable. In addition, the covariance can be calculated using fast Fourier transform (FFT), which is a computationally intensive algorithm and is very suitable for the parallel processing.This paper presents a parallel algorithm for geostatistical areal interpolation that is suited for CPU+GPU heterogeneous computing clusters. The algorithm was implemented using MPI and CUDA. The experiment results showed that the hybridparallel algorithm outperformed the MPI-basedparallel algorithm that uses only the CPUs, and it exhibited a good scalability.
Key words: parallel computing; heterogeneous cluster; areal Interpolation; GPU; MPI; CUDA
Tab. 1 Independence analysis ofthe block-point covariance calculation表1 块对点协方差计算独立性分析 |
| 所需参数 | 计算是否独立 |
|---|---|
| 格网的协方差矩阵 | 是 |
| 该要素的采样函数分布向量 | 是 |
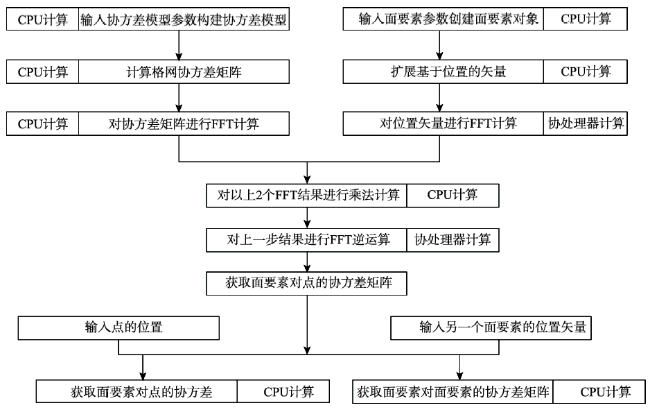
Fig. 1 Flow chart of the parallel algorithm图1 并行算法流程 |
Fig. 2 Covariance calculation between blocks图2 面要素间协方差计算 |
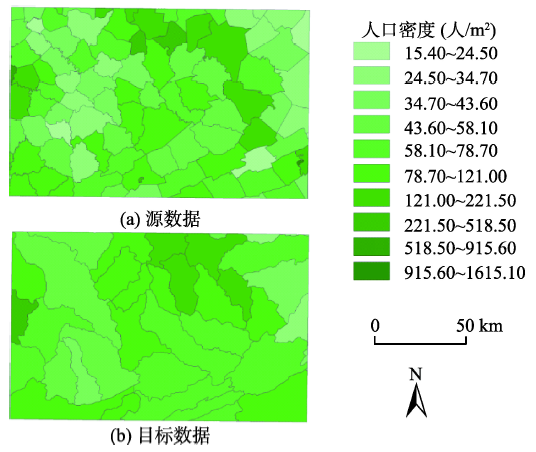
Fig. 3 The results of interpolation (the source data (a) and the target data (b))图3 插值计算结果 |
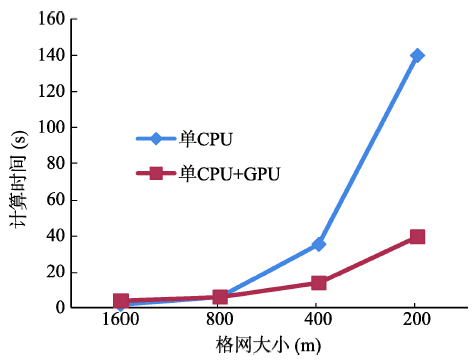
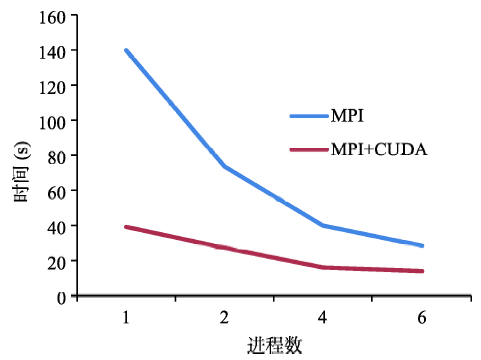
Fig. 4 Computationaltime of a single process图4 单进程时间对比 |
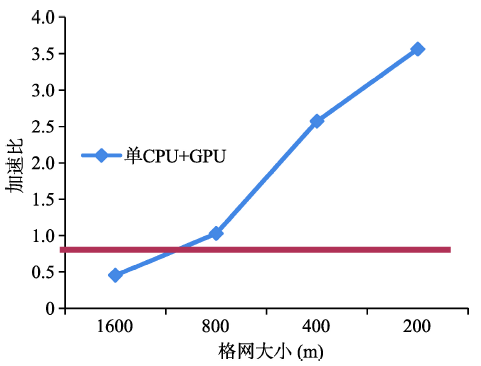
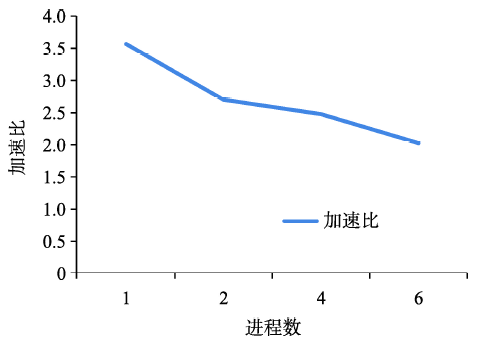
Fig. 5 Speed-up of a single process图5 单进程加速比对比 |
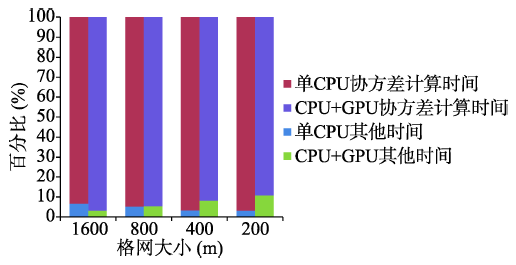
Fig. 6 The time proportions of covariance calculations图6 协方差计算占总体计算的时间比例 |
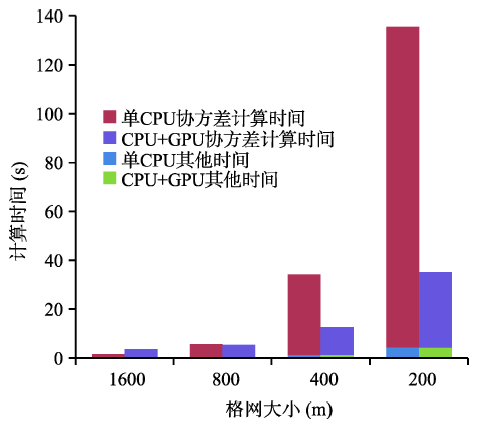
Fig. 7 Computationaltime of different settings图7 不同部分计算时间 4.2.2 CPU+GPU异构并行测试结果与分析 |
Fig. 8 Computationaltime of the heterogeneous parallelism and homogeneous parallelism图8 异构并行和同构并行的计算时间对比 |
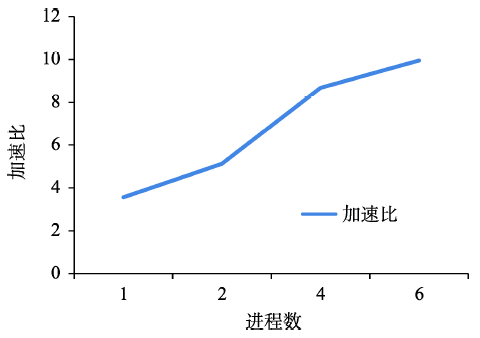
Fig. 9 Speed-up of heterogeneous parallelism over homogeneous parallelism图9 异构并行相对同构并行的加速比 |
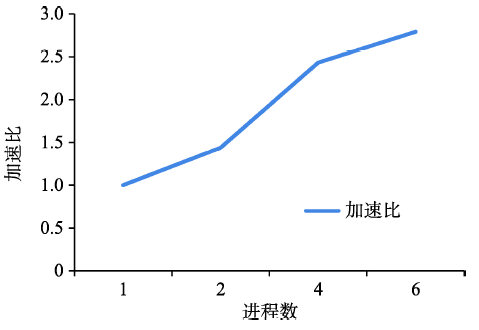
Fig. 10 Speed-up of heterogeneous parallelism over sequential algorithm图10 异构并行算法相对串行算法的加速比 |
Fig. 11 Speed-up of heterogeneous parallelism over a single CPU+GPU process图11 异构并行算法相对异构单进程的加速比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}