
基于MPP架构的并行空间数据库原型系统的设计与实现
作者简介:陈达伦(1990-),男,硕士生,主要从事空间数据库并行化研究。E-mail:Xiaoking31@126.com
收稿日期: 2015-03-12
要求修回日期: 2015-05-14
网络出版日期: 2016-02-04
基金资助
基金项目:国家高技术发展研究计划“863”项目(2013AA12A204、2013AA122302)
Research of the Parallel Spatial Database Proto System Based on MPP Architecture
Received date: 2015-03-12
Request revised date: 2015-05-14
Online published: 2016-02-04
Copyright
快速高效地查询信息是衡量当前空间数据库性能的重要指标之一。传统的单节点关系型空间数据管理方式难以满足大数据量空间数据查询的需求,特别是高性能的复杂空间多表连接任务需求。鉴此,本文设计并实现了基于Massive Parallel Processing(MPP)架构的并行空间数据库中间件原型系统。系统充分利用无共享(shared-nothing)架构的优势,特别是针对空间数据的特性,设计了并行空间数据划分与导入、并行空间多表连接、空间数据查询优化等算法与模型。首先介绍了近年来并行数据库系统的发展现状,接着阐述了基于MPP架构的并行空间数据库中间件系统的查询计划算法及其系统架构,最后作者对一些大规模数据量做查询实验及其查询结果分析。实验表明,在处理挖掘大规模数据量时,该系统有近似线性的加速比,相比于传统单节点数据库,它能充分提高海量空间数据的复杂查询的性能,解决了空间数据库并行化处理海量数据的问题。
关键词: MPP; 空间数据库; 并行; Shared Nothing
陈达伦 , 陈荣国 , 谢炯 . 基于MPP架构的并行空间数据库原型系统的设计与实现[J]. 地球信息科学学报, 2016 , 18(2) : 151 -159 . DOI: 10.3724/SP.J.1047.2016.00151
The efficiency for querying complex spatial information resources is an important indicator to evaluate the performance of current spatial databases. Traditional single node relation spatial data management is difficult to meet the demand of high-performance in querying large amounts of spatial data, especially for the complex join query on multi-table. In order to solve this problem, we design and implement a spatial database middleware prototype system. This system takes full advantages of the massive parallel processing (MPP) and shared-nothing architecture. In consideration of the characteristics of spatial data, we design the spatial data parallel import, multi-spatial-tables join strategy, spatial data query optimization and other algorithms and models. This paper firstly introduces the development status of parallel database systems in recent years, and then elaborates its MPP architecture and its organizational model, and the strategy of the join query on multi-spatial-table. Finally, we made some query experiments on massive spatial data and analyzed the results of these inquiries. The experimental results show that this system indicates a good performance (nearly linear speedup) in processing the complex query of massive spatial data. Compared with the tradition single node database, this system can fully improve the efficiency of complex querying for large spatial data, and it is a more efficient solution to solve the complex spatial data queries.
Key words: MPP; spatial database; parallel processing; shared-nothing
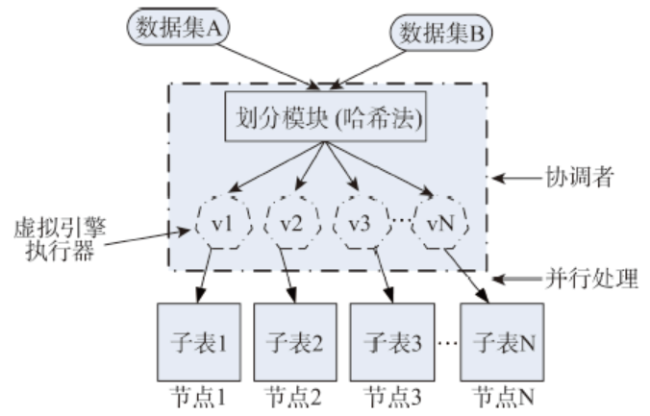
Fig. 1 The schematic diagram of the partition and import of spatial data图1 空间数据划分与导入示意图 |
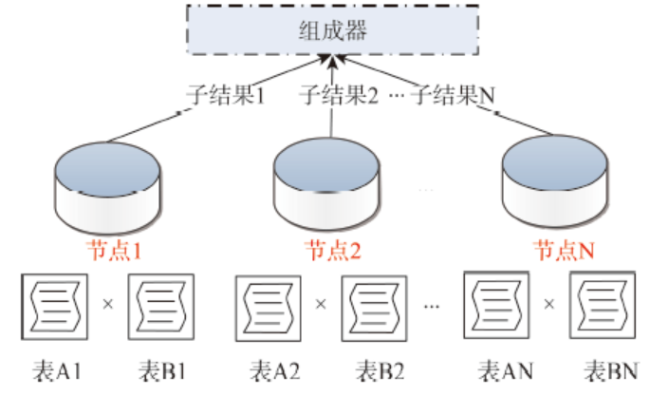
Fig. 2 The schematic diagram indicating the joining of multi-tables with partitioned column图2 分区列多表并行连接 |
Tab. 1 Algorithm for joining un-partitioned multi-tables表1 非分区多表并行连接算法 |
| 算法:非分区列多表并行连接 |
|---|
| 步骤1 select A.name, A.shape from A For i=1 to Count_node(从节点数) 将表A的查询的投影列(A.name)、连接列(几何列A.shape)发送至协调者。其中,空间列以二进制BLOB对象的形式传输 end for 步骤2 create temp table tmp1(name char(20),shape st_geometry ) 协调者节点将结果集打包,生成临时结果集TDR For i=1 to Count_node(从节点数) 在各个节点上创建临时表TempA*,以及临时空间索引批量插入临时结果集TDR到各个节点的临时表 end for 步骤3 select ta.name, B.name,st_astext( ta.shape) from TempA* as ta,B where st_within(ta.shape = B.shape)=1 For i= 1 to P do(并行地) 对于各个节点,将临时表TempA*与表B进行连接操作,将结果集发送到协调者节点上 对于空间列进行st_astext数据类型转换 end for 协调者归并结果集 步骤4 协调者执行查询计划中的下一步骤(归并数据进行下一个表的连接或格式化输出至客户端) |
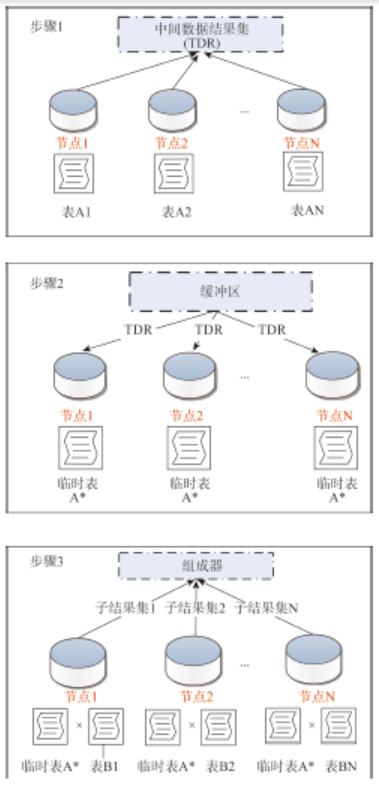
Fig. 3 The schematic diagram indicating the joining of multi-tables with un-partitioned spatial column图3 非分区列空间多表并行连接示意图 |
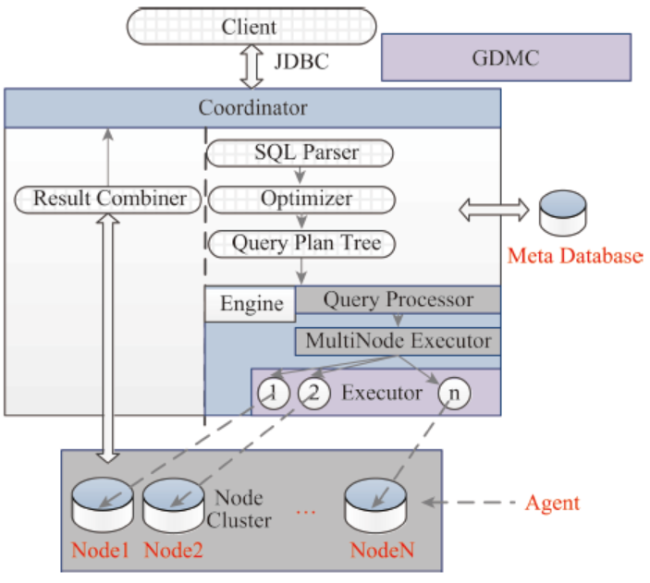
Fig. 4 The GDMC system architecture图4 GDMC系统架构图 |
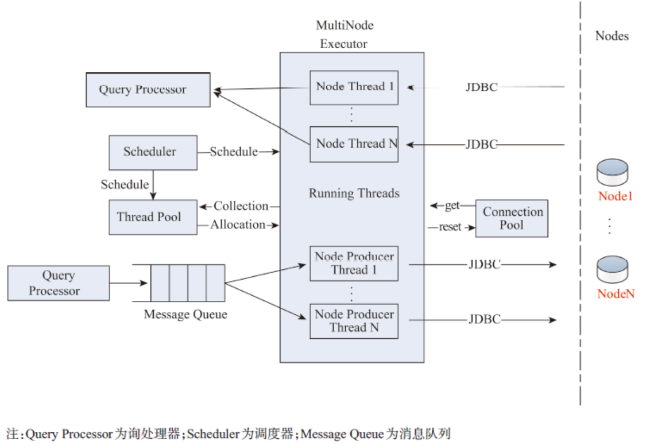
Fig. 5 The diagram of query processor and multi-nodes executor图5 查询处理器与多节点执行器示例图 |
Tab. 2 System hardware specifications表2 系统的硬件配置 |
| 节点名 | 硬件配置 | 操作系统/JDK版本 | 数量/台 | 设备用途 |
|---|---|---|---|---|
| 协调节点 | CPU:I7-3610 QM 内存:8 GB | CentOS 6.4/ JDK 1.7.0 | 1 | 管理后端支持节点,解析SQL语句,制定查询计划,归并查询结果 |
| 后端从节点 | CPU:I3-3220 内存:4 GB | CentOS 6.4/ JDK 1.7.0 | 4 | 提供数据库计算功能,返回子查询结果集 |
| 物理元数据库节点 | CPU:I5-2400 内存: 6 GB | CentOS 6.4/ JDK 1.7.0 | 1 | 提供数据库元数据信息。包括表、视图、约束等元数据 |
| 客户端节点 | CPU:I7-3610 QM 内存: 8 GB | CentOS 6.4/ JDK 1.7.0 | 1 | 输入SQL查询语句,输出查询结果 |
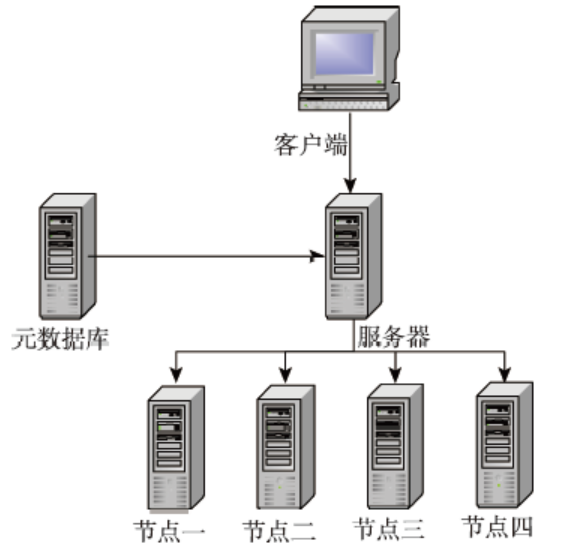
Fig. 6 The diagram of GDMC system’s logical networking图6 GDMC系统的逻辑组网 |
Fig. 7 The diagram of the parallel selection query experiment of GDMC system图7 系统的并行选择查询实验结果图(四节点) |
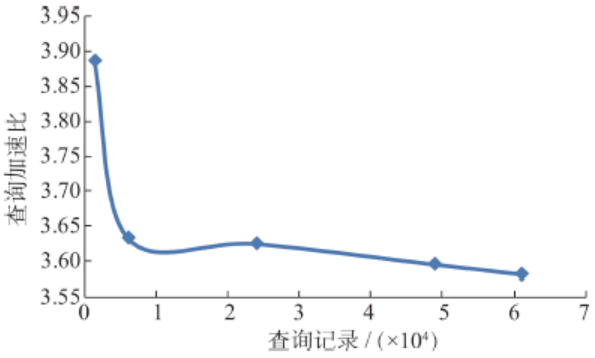
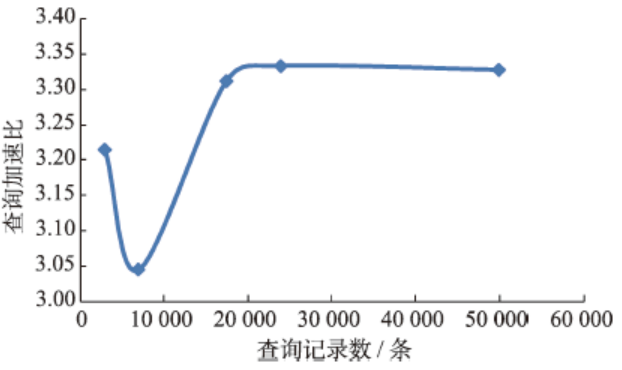
Fig. 8 The result diagram of the experiment for querying data in different sizes of query windows图8 统计查询不同大小窗口内的记录条数实验结果图 |
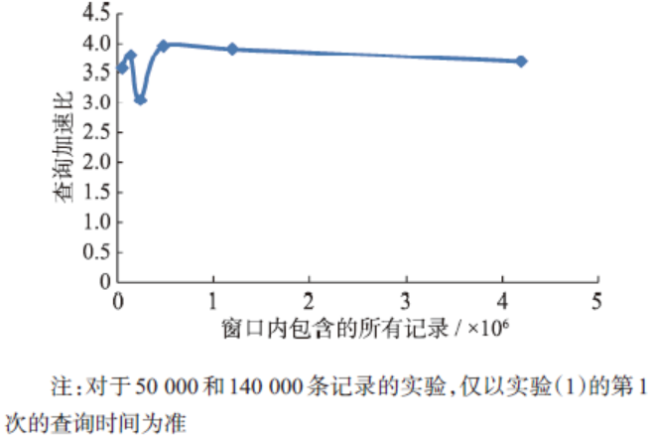
Fig. 9 The result diagram of the experiment for querying all the spatial objects in different sizes of query windows图9 系统查询遍历窗口中所有空间实体的实验结果图 |
Tab. 3 Statistics showing the results for querying the number of records that belong to a specified region表3 查询统计属于某地区的记录行数 |
| 结果集记录数 / 条 | 单节点萍执行平均时间 / s | 四节点执行平均时间 / s |
|---|---|---|
| 130 000 | 383.312 | 100.269 |
Tab. 4 The result for querying the total area of bare soil in a specified region表4 查询某地区土地利用类型为裸土的总面积 |
| 单节点执行平均时间 / s | 四节点执行平均时间 / s |
|---|---|
| 307.3 | 56.32 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
[
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
|
| [19] |
|
| [20] |
[
|
| [21] |
|
| [22] |
[
|
| [23] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}