
基于移动激光扫描点云特征图像和SVM的建筑物立面半自动提取方法
作者简介:彭晨(1992-),男,硕士生,研究方向为城市遥感与GIS开发。E-mail: 51130801069@ecnu.cn
收稿日期: 2015-07-19
要求修回日期: 2015-09-14
网络出版日期: 2016-07-15
基金资助
国家自然科学基金项目(41471449)
上海市自然科学基金项目(14ZR1412200)
中央高校基本科研业务费专项资金项目
A Method for Semiautomated Segmentation of Building Facade from Mobile Laser Scanning Point Cloud Based on Feature Images and SVM
Received date: 2015-07-19
Request revised date: 2015-09-14
Online published: 2016-07-15
Copyright
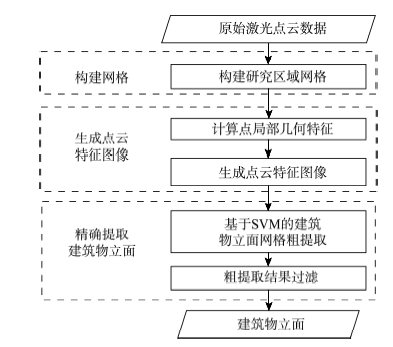
建筑物立面是城市地物的重要组成部分,而移动激光扫描是获取城市地物三维信息的重要手段之一。本文提出了一种基于移动激光扫描点云的建筑物立面半自动提取算法。该方法首先构建研究区水平网格;然后计算局部点云几何特征,并且将特征投影到水平网格生成点云特征图像;接着基于支持向量机(Support Vector Machine,SVM)对建筑物立面网格进行粗提取;最后使用网格属性(形状系数、网格面积、最大高程)对粗提取结果进行过滤,并将结果反投影到三维空间中得到精确的建筑物立面。以卡内基梅隆大学的移动激光扫描点云进行试验后表明,本算法能够较好地提取出建筑物立面,提取精度为84%,召回率为90%,数据修正后精度为88%,召回率为91%。通过与现有算法对比,本文提出的算法具有较高精度。
关键词: 移动激光扫描系统; 建筑物立面提取; 点云特征图像; 支持向量机(SVM)
彭晨 , 余柏蒗 , 吴宾 , 吴健平 . 基于移动激光扫描点云特征图像和SVM的建筑物立面半自动提取方法[J]. 地球信息科学学报, 2016 , 18(7) : 878 -885 . DOI: 10.3724/SP.J.1047.2016.00878
Building facade is an important component of urban street features. Delineating and representing the building facade would benefit the urban building design and planning. As a new mobile mapping system, Mobile Laser Scanning (MLS) allows the quick and cost-effective acquisition of close-range three-dimensional (3D) measurements of urban street objects. This paper presents a semiautomated segmentation method for identifying the building facades from MLS point clouds data. The method consists of three major steps: (1) a horizontal grid system is built for the study area, and the multidimensional geometric features of 3D point clouds data, including the normal vector feature, omni-variance feature, geometric dimensionality of α1, α2 and α3, and eigen-entropy feature, are defined and calculated. Then, a feature image is created after projecting these features to the horizontal grid. (2) Building facades are roughly extracted using Support Vector Machine (SVM). (3) The rough extraction result is filtered according to the characteristics of grid including the shape coefficient, grid′s area, and the largest elevation. Two MLS point cloud datasets of Carnegie Mellon University (CMU) database were used in this study to estimate the feasibility and effectiveness of the method. It was found that this method performs well in extracting the building facades. The precision of the results is 0.88, and its recall rate is 0.90, which is better than some existing methods. Our method provides an effective tool for extracting building facades of streets from MLS point cloud data.
Fig.1 Flow chart of the algorithm图1 算法流程图 |
Tab.1 Labeled id and name of CMU Oakland 3-D point cloud dataset表1 卡内基梅隆大学移动激光扫描点云数据库的分类编号和类别 |
| 编号 | 类别 | 编号 | 类别 | 编号 | 类别 | 编号 | 类别 |
|---|---|---|---|---|---|---|---|
| 1001 | undet | 1109 | fire_hydrant | 1202 | ground | 1401 | wall |
| 1002 | linear_misc | 1110 | post | 1203 | paved_road | 1402 | stairs |
| 1003 | surf_misc | 1111 | sign | 1205 | curb | 1408 | fence |
| 1101 | wire_bundle | 1113 | bench | 1206 | walkway | 1409 | gate |
| 1102 | isolated_wire | 1114 | lamp | 1300 | foliage | 1410 | ceiling |
| 1103 | utility_pole | 1115 | traffict_lights | 1301 | grass | 1411 | facade_ledge |
| 1104 | crossarm | 1116 | traffic_lights_support | 1302 | small_trunk | 1412 | column |
| 1105 | support_wire | 1117 | garbage | 1303 | large_trunk | 1413 | mailbox |
| 1106 | support_pole | 1118 | crosswalk_light | 1305 | thick_branch | 1500 | human |
| 1107 | lamp_support | 1119 | parking_meter | 1306 | shrub | 1501 | vehicle |
| 1108 | transformer | 1200 | load_bearing | 1400 | facade | 9999 | legacy |
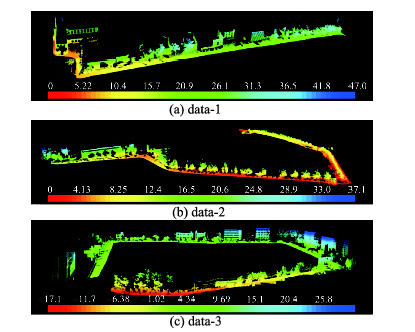
Fig.2 Overview of CMU Oakland 3-D point cloud dataset.图2 卡内基梅隆大学移动激光扫描点云数据库 |
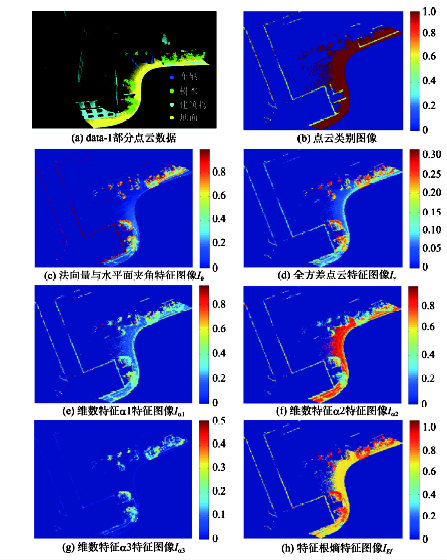
Fig.3 Feature images generated by 3D point clouds图3 点云特征图像 |
Tab.2 Precisions and recalls of classification based on the building grids by linear SVM表2 建筑物网格粗提取精度和召回率 |
| 数据集 | 网格类型 | 精度/(%) | 召回率/(%) |
|---|---|---|---|
| Data-1 | 建筑物立面网格 | 90.7 | 62.6 |
| 非建筑物立面网格 | 94.7 | 99.0 | |
| Data-2 | 建筑物立面网格 | 95.6 | 41.1 |
| 非建筑物立面网格 | 94.3 | 99.8 | |
| Data-3 | 建筑物立面网格 | 96.1 | 51.9 |
| 非建筑物立面网格 | 93.6 | 99.7 |
Fig.4 Results of segmentation图4 建筑物立面提取结果 |
Tab.3 Precisions and recalls of building facade segmentation from point clouds表3 建筑物立面点云提取精度和召回率 |
| 数据集 | A/m2 | CI | MH/m | 精度/(%) | 召回率/(%) |
|---|---|---|---|---|---|
| Data-1 | 1.25 | 0.45 | 3 | 81.7 | 89.4 |
| Data-2 | 2.75 | 0.45 | 3 | 89.8 | 90.7 |
| Data-3 | 1.25 | 0.45 | 3 | 83.6 | 90.0 |
Fig.5 The building which is not extracted from data-1图5 data-1中未提取的建筑物 |
Tab.4 Precisions/recalls of different methods表4 不同方法建筑物立面提取结果比较分析 |
| 计算方法 | 精度/(%) | 召回率/(%) | F1 |
|---|---|---|---|
| S3DP | 83 | 93 | 0.88 |
| M3N | 80 | 92 | 0.86 |
| LogR | 74 | 87 | 0.80 |
| 本文方法 | 84 | 90 | 0.87 |
| 修正后本文方法 | 88 | 91 | 0.90 |
Fig.6 The impact of grid size on the extraction results图6 网格大小对提取结果的影响 |
Fig.7 Comparison of extraction results图7 提取结果对比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
[
|
| [14] |
[
|
| [15] |
[
|
| [16] |
|
| [17] |
[
|
| [18] |
|
| [19] |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}