
蕴含地理事件微博客消息的自动识别方法
作者简介:仇培元(1986-),男,博士生,研究方向为互联网空间信息搜索。E-mail: qiupy@lreis.ac.cn
收稿日期: 2015-09-07
要求修回日期: 2015-11-03
网络出版日期: 2016-07-15
基金资助
国家“863”计划课题(2013AA120305)
国家自然科学基金项目(41401460)
Automatic Identification Method of Micro-blog Messages Containing Geographical Events
Received date: 2015-09-07
Request revised date: 2015-11-03
Online published: 2016-07-15
Copyright
微博客文本蕴含类型丰富的地理事件信息,能够弥补传统定点监测手段的不足,提高事件应急响应质量。然而,由于大规模标注语料的普遍匮乏,无法利用监督学习过程识别蕴含地理事件信息的微博客文本。为此,本文提出一种蕴含地理事件微博客消息的自动识别方法,通过快速获取的语料资源增强识别效果。该方法利用主题模型具有提取文档中主题集合的优势,通过主题过滤候选语料文本,实现地理事件语料的自动提取。同时,将分布式表达词向量模型引入事件相关性计算过程,借助词向量隐含的语义信息丰富微博客短文本的上下文内容,进一步增强事件消息的识别效果。通过以新浪微博为数据源开展的实验分析表明,本文提出的蕴含地理事件信息微博客消息识别方法,识别来自事件微博话题的消息文本的F-1值可达到71.41%,比经典的基于SVM模型的监督学习方法提高了10.79%。在模拟真实微博环境的500万微博客数据集上的识别准确率达到60%。
仇培元 , 陆锋 , 张恒才 , 余丽 . 蕴含地理事件微博客消息的自动识别方法[J]. 地球信息科学学报, 2016 , 18(7) : 886 -893 . DOI: 10.3724/SP.J.1047.2016.00886
Micro-blogs usually contain abundant types of geographical event information, which could compensate for the shortcomings of traditional fixed point monitoring technologies and improve the quality of emergency response. Identify the micro-blog messages that containing the geographical event information is the prerequisite for fully utilizing this data source. The trigger-based and the supervised machine learning methods are commonly adopted to identify the event related texts. Comparatively, the supervised machine learning methods have better performance than the trigger-based ones for unrestricted texts. Unfortunately, the lack of large-scale tagged corpuses cause the supervised machine learning methods cannot be implemented to identify the geographical event related messages. In this paper, we propose an automatic method for recognizing micro-blogs that are related to geographical events based on the topic model and word vector. This method could achieve a satisfying identification result by increasing the corpus scale rapidly. Firstly, the topic model is capable to extract topics from documents. Thus, the web pages fetched by a search engine are grouped by the topics, and the corpus is obtained after combining the pages under the topics that are related to geographical events through judging their keywords of each topic. Secondly, the distributed representation word vector model is introduced to compensate the lack of context in the micro-blog, which is caused by its character count limit. These word vectors are integrated into the context semantic information from corpus training during the vector generation process. Thirdly, the correlation between the micro-blog message and the given geographical event is calculated and applied to determine whether this message contains the specified geographical event or not. In addition, some heuristic rules are used to correct the error correlations of very short messages. Experiments where the rainstorm is set as the targeting geographical event are conducted to validate the feasibility of this approach. The test conducted on Sina topic micro-blog shows that the F-1 of identification reaches 71.41% and is 10.79% higher than the traditional machine learning algorithm based on Support Vector Machine. Based on the premise that the precision loss is limited, the recall rate would rise with an increase in the corpus scale. The recognition precision could achieve 60% in a dataset containing five million micro-blog texts that simulating the actual data content and environment. These recognized event related micro-blogs could be used to extract detailed information elements in the future.
Key words: micro-blog; geographical event; event text identification; topic model; word vector
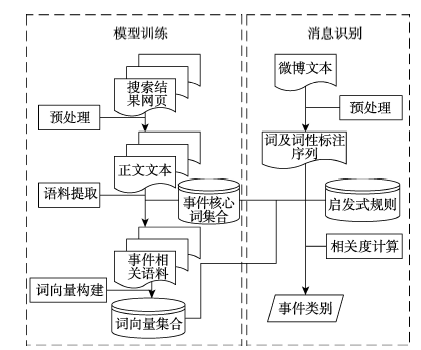
Fig.1 Flowchart of the identification method |
Fig.2 An example of topic extraction and correlation interpretation from the candidate corpuses about rainstorm图2 暴雨事件候选语料的主题提取及相关性判读示意 |
Fig.3 An example of related words computation based on the word vector图3 基于词向量的相关词计算结果示例 |
Tab.1 Some instances of speech patterns表1 词性模式 |
| 模式 | 出现次数 |
|---|---|
| v n | 327 |
| n v | 170 |
| n n | 72 |
| m q n | 19 |
| n m q | 18 |
| n d v | 16 |
| a n | 16 |
| v m n | 15 |
| n a | 11 |
| v b n | 10 |
| m n p v | 10 |
| v u n | 10 |
注:a代表形容词;b为区别词;d为副词;m为数词;n为名词;p为介词;q为量词;u为助词;v为动词 |
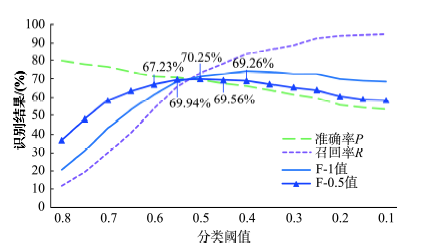
Fig.4 Identification results under different thresholds图4 不同分类阈值识别结果 |
Tab.2 Performance of the identification approach for micro-blogs containing rainstorm events表2 蕴含暴雨事件消息识别结果 |
| 抽取方法 | 准确率/(%) | 召回率/(%) | F-1值/(%) | F-0.5值/(%) |
|---|---|---|---|---|
| 本文方法 | 69.71 | 73.20 | 71.41 | 70.38 |
| SVM方法 | 68.48 | 54.88 | 60.62 | 65.00 |
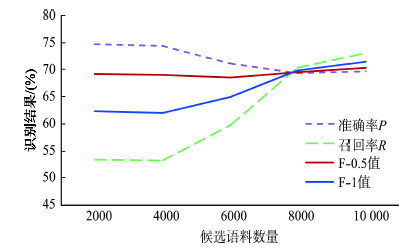
Fig.5 Identification results using different scales of candidate corpuses |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
[
|
| [14] |
[
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
[
|
| [24] |
|
| [25] |
[
|
| [26] |
[
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}