
连续变量的自适应局部空间同位模式挖掘算法
作者简介:范协裕(1985-),男,福建永春人,博士,讲师,研究方向为空间数据挖掘、网络地理信息系统。E-mail: xunbei100@aliyun.com
收稿日期: 2015-07-27
要求修回日期: 2015-11-09
网络出版日期: 2016-07-15
基金资助
福建省教育厅科技计划项目(JA14102)
国家自然科学基金青年科学基金项目(41401399)
Self-adaptive Local Co-location Pattern Mining Algorithm for Continuous Variables
Received date: 2015-07-27
Request revised date: 2015-11-09
Online published: 2016-07-15
Copyright
目前,局部空间同位模式挖掘方法存在需要预设定邻域范围、挖掘的结果无统计显著性意义而难以对结论进行科学地判定等问题,如当前常用的近邻方法难以确定合适的搜索圆半径,而固定距离法由于空间数据集的多尺度特性,距离阈值的设定对结果的影响较大。因此,针对连续变量的空间采样点数据集,本文提出了一种自适应局部空间同位模式挖掘算法。首先,定义了连续变量的空间同位模式兴趣度函数、模式指示器函数及Voronoi邻域,并通过构建Voronoi邻域矩阵避免了预设定邻域阈值的问题,最后采用统计量进行局部空间同位模式及其区域的发现,使挖掘的结果具有统计显著性意义,进而帮助专家对挖掘结果做出更科学的判定。通过使用真实的连接了烟草适应性评价结果的耕地地力样点调查数据和水污染数据,对开发的算法进行测试。实验结果表明,算法无需预设邻域范围,可查找同区域内的不同空间同位模式。实验所发现的局部空间同位模式发现了实验数据研究区域存在的特有现象,对耕地地力调查工作具有实际的指导作用。
范协裕 , 陈瀚阅 , 刑世和 . 连续变量的自适应局部空间同位模式挖掘算法[J]. 地球信息科学学报, 2016 , 18(7) : 902 -909 . DOI: 10.3724/SP.J.1047.2016.00902
Existing approaches in finding the local co-location patterns have several shortcomings: (1) they depend on user predefining thresholds for proximity between the spatial feature instances and (2) the mining results miss the statistically significant explanation. In this paper, we proposed a new self-adaptive method for finding the local co-location patterns for spatial datasets containing continuous variables. The interestingness and indicator function and the proximity area that are defined based on the Voronoi diagrams are introduced. A proximity matrix is built to avoid user predefining thresholds for proximity. At last, the local Getis-Ord's statistic quantity for the interestingness value is employed, which endowed the mining results with statistical significant. The actual datasets for cropland productivity surveying jointly with the land suitability evaluation results for tobacco planting and for water pollution are used to test the developed algorithm. The experimental results show that, the proposed approach is able to identify different local co-location patterns without the interference of user specified thresholds for proximity, and the captured local co-location patterns in the cropland productivity surveying datasets reveal the localized specified phenomenon in the experimental area. This approach has practical significances for cropland productivity surveying.
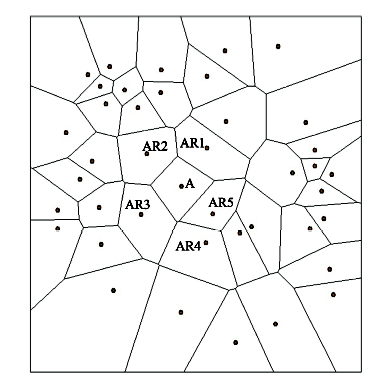
Fig.1 Proximity area based on Voronoi diagrams图1 Voronoi自适应邻域 |
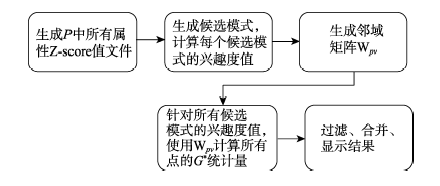
Fig.2 Framework of SLCPMA图2 自适应区域空间同位模式算法框架图 |
Tab.1 Datasets used in the experiments表1 实验数据集 |
| 数据集 | 内容 | 数据量 |
|---|---|---|
| GWDB水数据 | 砷(As),钼(Mo),钒(V),硼(Bo),氟(Fl),二氧化硅(Si),氯化物(Cl),硫酸盐(SO4),总溶解固体(TDS)和水井深度(WD) | 1655 |
| 长汀耕地地力数据及烟草适宜性评价结果 | 烟草适应性评价得分(Score),有机质(Organic),PH,碱解氮(N),有效磷(P),速效钾(L) | 475 |
Fig.3 Experimental result of co-location mining for Texas-GWDB datasets图3 Texas-GWDB数据同位模式挖掘结果 |
Fig.4 The co-location patterns and region discovered through the experiment图4 Texas GWDB同位模式及其区域 |
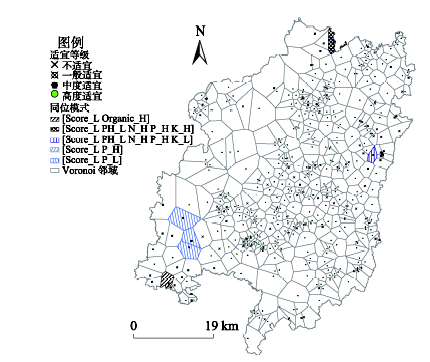
Fig.5 Land suitability evaluation results for tobacco planting in Chanting county and its co-location patterns with the top 5 scores图5 长汀县烟草适宜性评价及值前五的同位模式 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
Bagherjeiran A, Celepcikay O U, Jiamthapthaksin R, et al. COUGAR^2: An open source machine learning and data mining development platform[EB/OL]. .
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
[
|
| [20] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}