
Web环境下地学数据共享用户行为模式分析
作者简介:王 末(1987-),男,博士生,研究方向为空间数据挖掘。E-mail: wangm.13b@igsnrr.ac.cn
收稿日期: 2015-11-06
要求修回日期: 2016-03-16
网络出版日期: 2016-09-27
基金资助
国家科技基础条件平台——地球系统科学数据共享平台(2005DKA32300)科技基础性工作重点项目(2011FY110400)中国工程院国际工程科技知识中心项目
A Study on the User Behavior of Geoscience Data Sharing Based on Web Usage Mining
Received date: 2015-11-06
Request revised date: 2016-03-16
Online published: 2016-09-27
Copyright
了解科学数据共享用户行为特征对实现高效、精准的数据共享服务具有重要的参考意义。本文基于国家地球系统科学数据共享平台网站服务器日志及服务记录数据,利用空间数据挖掘及Web使用挖掘技术,探索地球系统科学数据共享用户行为模式。在数据预处理阶段,完成用户识别、会话识别、位置识别,并对数据进行空间建模、空间数据库建库。在数据挖掘阶段,分别对用户产生的网页浏览数、会话数、数据集浏览数为对象进行空间“热点”分析,识别用户行为的地域差异。针对用户数据浏览和下载行为,采用FP-growth算法对用户——数据之间进行关联规则挖掘,发现用户对数据关注和使用的高频规律。分析结果表明:(1)该共享平台用户地在国内各省市均有分布,用户最多的3个省(市)分别为北京市、山东省、江苏省,该分布与国内高校学生分布相关程度不高,但与“211工程”高校学生的空间分布相关度较高;(2)空间“热点”分析表明,北京、天津及河北北部无论在网页浏览、数据浏览还是会话量上都是“热点”区域,但识别的“冷点”区域有较大不同,尤其是数据访问“冷点”分布较广,如南方沿海省份、河南省、山东省、四川省等;(3)关联规则挖掘发现多个数据浏览高频项目集以及关联规则。数据下载高频项与数据浏览高频模式较好吻合,但下载行为未表现出明显关联规则。本文提供了一种结合Web使用挖掘和空间数据挖掘的用户行为模式挖掘方法,该方法也可用于其他类型网站的数据挖掘。
王末 , 王卷乐 . Web环境下地学数据共享用户行为模式分析[J]. 地球信息科学学报, 2016 , 18(9) : 1174 -1183 . DOI: 10.3724/SP.J.1047.2016.01174
Understanding the user behavior of science data sharing is a key step to implement effective and accurate service for science data sharing. This study aims to explore the user behavior of science data sharing using spatial data mining and Web usage mining techniques for the National Earth System Science Data Sharing Platform. At the stage of data preprocessing, procedures of user identification, session identification and user location identification were performed. Spatial hotspot analysis was conducted to analyze the user pageviews, sessions, and dataset visits to explore the geographical variance of user behaviors using the Getis-Ord Gi* method. FP-growth was taken to be the algorithm for mining association rules, and was performed for analyzing data visits and data downloads. Data mining results show that: (1) the user distribution of data sharing platform does not show significant correlation with the overall university population distribution in China, but shows a significant positive correlation with the population of research-oriented universities; (2) the hotspot analysis shows that regions of hotspots were clustering in Beijing, Tianjin, and northern Hebei Province for all three perspectives, whereas the cold spots geographically scattered to a greater extent, e.g. the southern coastal provinces, Henan Province, Shandong Province, Sichuan Province, etc.; (3) the association rules mining reveals a number of frequently visited item sets and rules from the valuable user pageviews. The frequently visited item sets for data downloads were well coincided with the frequently visited data. However, no conspicuous rules occurred in data downloads. Results of the spatial hotspot analysis and association rules mining detected the geographical variance of users’ interests in data and discovered the usage patterns for the frequently visited data, which can be used for designing the personalized recommendation. This study provides a method for mining web user behaviors with the combination of Web usage mining and spatial data mining techniques, which can also be applied to the data mining of websites in other fields.
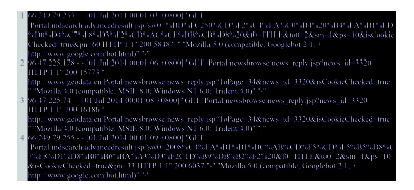
Fig.1 An example of Web server log entries图1 Web服务器日志数据示例 |
Tab.1 Contents of a Web server log entry表1 Web服务器日志数据内容 |
| 类别 | 详情 | fan
|---|---|
| 主机IP | 128.227.49.92 |
| 时间 | 05/Aug/2014:10:26:42 +0800 |
| 方法 | GET |
| URL | /extra/res/libs/kendo/extensions/kendo.extension.ui.js |
| 协议 | HTTP/1.1 |
| 状态 | 200 |
| 文件大小 | 15072 |
| 访问来源 | http://www.geodata.cn/extra/TopicsWin2/pro3.jsp |
| 客户端 | Mozilla/5.0 (Windows NT 6.3; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0 |
2.1.2 注册用户服务记录 |
用户注册信息在数据挖掘过程中提供了重要的用户外在属性信息,为用户行为的解释提供依据,也可用于用户的分类。本文将采用匿名的用户注册信息,作为辅助数据,判定用户来源。用户注册信息包括用户的学历、职业、联系方式、所在机构等信息。
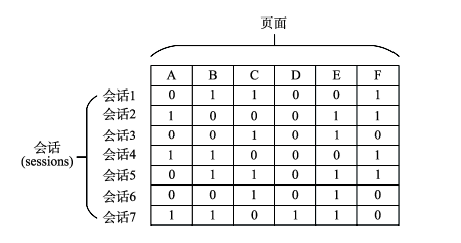
Fig.2 User pageview matrix (in this case, A, B and C represent different webpages)图2 页面访问会话矩阵示例(A、B、C等表示不同的页面) |
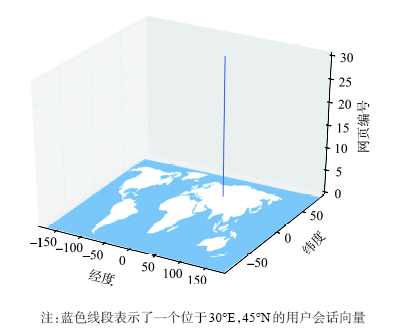
Fig.3 An example of a georeferenced user transaction data model, the blue line represents the transaction vector of a user located at 30°E, 45°N图3 空间信息增强型用户会话向量模型 |
Tab.2 Statistics of data preprocessing results表2 数据预处理结果统计 |
| 原始日志记录 | 清洗后记录 | 用户数 | 会话数 | 识别位置 |
|---|---|---|---|---|
| 11 062 608 | 2 845 150 | 76 111 | 448 495 | 76 069 |
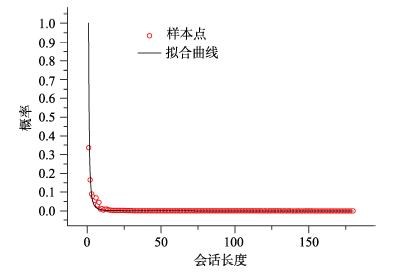
Fig.4 Distribution of the session length probability图4 用户会话长度概率分布拟合曲线 |
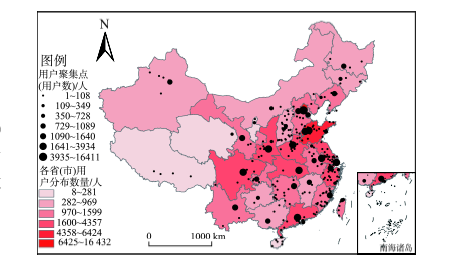
Fig.5 User distribution in China图5 国内用户数量分布 |
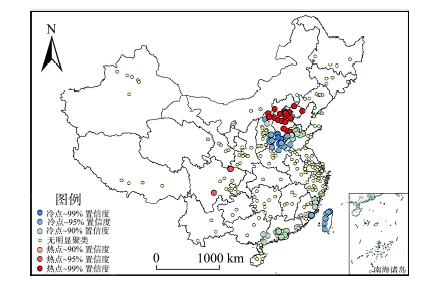
Fig.6 Hotspot analysis of user pageviews图6 用户网页浏览数“热点”分析 |
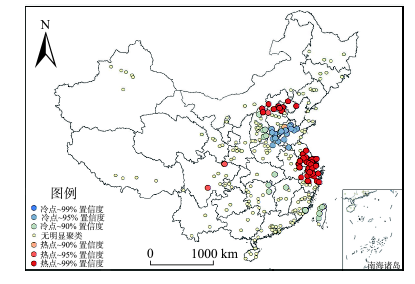
Fig.7 Hotspot analysis of user sessions图7 用户会话数“热点”分析 |
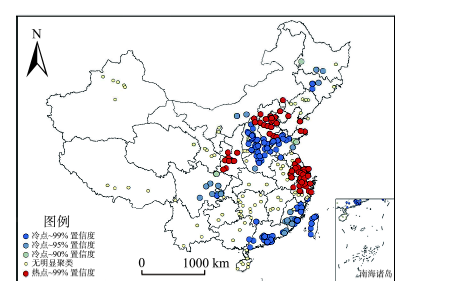
Fig.8 Hotspot analysis of datasets visits图8 用户数据集浏览数“热点”分析 |
Tab.3 Frequent itemsets for datasets visits of all users (S≥10%)表3 所有用户数据访问高频项目集(S≥10%) |
| 项目集 | 支持度(S)/(%) | 内容描述 |
|---|---|---|
| 100101-22 | 27.1 | 中国1:400万地貌图(形态) |
| 100101-2 | 12.9 | 中国1:400万资源环境数据(中国地形,1988年) |
| 100101-18 | 11.6 | 全国土地利用数据库(分省:1980s,1987-2001年;分县:1980s) |
| 100101-38 | 10.8 | 全国1 km网格人口数据(1995,2000, 2003,2005和2010年) |
| 100101-66 | 10.6 | 中国1:400万全要素基础数据 (1970s-1990s) |
Tab.4 Frequent itemseds for datasets visits ofactive users (S≥25%)表4 活跃用户数据访问高频项目集(S≥25%) |
| 项目集 | 支持度(S)/(%) | 内容描述 |
|---|---|---|
| 100101-18 | 34.1 | 全国土地利用数据库(分省:1980s,1987-2001年;分县:1980s) |
| 100101-38 | 32.4 | 全国1 km网格人口数据(1995、2000、2003、2005和2010年) |
| 100101-2 | 30.7 | 中国1:400万资源环境数据(中国地形,1988年) |
| 100101-3 | 29.6 | 1996年浙江省1:25万数字化土地利用现状图 |
| 100101-30 | 29.2 | 全国多年平均降雨分布图(1 km)(建站到1996年) |
| 100101-38、100101-18 | 28.0 | 全国1 km网络人口数据、全国土地利用数据库 |
| 100101-18、100101-2 | 27.5 | 全国土地利用数据库、中国1:400万资源环境数据 |
| 100101-30、100101-18 | 27.2 | 全国多年平均降雨分布图、全国土地利用数据库 |
| 100101-66 | 27.1 | 中国1:400万全要素基础数据(1970 s-1990 s) |
| 100101-18、100101-3 | 26.8 | 全国土地利用数据库、1996年浙江省1:25万数字化土地利用现状图 |
Tab.5 Association rules (C≥90%)表5 关联规则(C≥90%) |
| 关联规则 | 置信度(C)/(%) |
|---|---|
| 100101-30 ==> 100101-2 | 90.4 |
| 100101-3==> 100101-18 | 90.8 |
| 100101-38、 100101-18==> 100101-2 | 91.4 |
| 100101-18、100101-2==> 100101-3 | 92.4 |
| 100101-2、100101-18 ==> 100101-38 | 92.9 |
| 100101-30、100101-18==> 100101-3 | 93.0 |
| 100101-30 ==> 100101-18 | 93.1 |
| 100101-18、100101-3==> 100101-30 | 94.1 |
| 100101-18、100101-2==> 100101-30 | 94.2 |
| 100101-18、100101-3 ==> 100101-2 | 94.6 |
| 100101-30、100101-2==> 100101-3 | 95.4 |
| 100101-30、100101-18 ==> 100101-2 | 95.4 |
| 100101-2、100101-3 ==>100101-30 | 96.9 |
| 100101-38、100101-2 ==> 100101-18 | 97.2 |
| 100101-2、100101-3==> 100101-18 | 97.8 |
| 100101-30、100101-3 ==> 100101-2 | 98.2 |
| 100101-30、100101-2 ==> 100101-18 | 98.2 |
| 100101-30、100101-3==> 100101-18 | 98.5 |
3.3.2 数据下载或申请关联规则 |
Tab.6 Frequent itemsets for datasetsdownloads or application (top 5)表6 注册用户数据下载或申请高频项目集(前5) |
| 项目集 | 支持度(S)/(%) | 内容描述 |
|---|---|---|
| 100101-66 | 13.7 | 中国1:400万全要素基础数据(1970s-1990s) |
| 100101-38 | 9.6 | 全国1 km网格人口数据(1995、2000、2003、2005和2010年) |
| 100101-11860 | 8.1 | 全国1:25万土地覆被数据(1980s,2005年) |
| 100101-18 | 8.0 | 全国土地利用数据库(分省:1980s,1987-2001年;分县:1980s) |
| 100101-29 | 7.3 | 陆地卫星MSS/TM/ETM+(1973-2008年、覆盖全国) |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}