
基于时间序列聚类方法分析北京出租车出行量的时空特征
作者简介:程静(1993-),女,湖北黄冈人,硕士生,研究方向为空间数据挖掘。E-mail: cheng1993jing@163.com
收稿日期: 2015-09-14
要求修回日期: 2015-12-10
网络出版日期: 2016-09-27
基金资助
国家自然科学基金项目(41271385、41271386)
Analyzing the Spatio-Temporal Characteristics of Beijing′s OD Trip Volume Based on Time Series Clustering Method
Received date: 2015-09-14
Request revised date: 2015-12-10
Online published: 2016-09-27
Copyright
受城市资源配置、区域功能分化的影响,城市中居民的出行往往呈现出特定的模式和规律,而这种出行模式的背后反映出城市的功能结构。城市车辆GPS导航的广泛使用,以及车辆轨迹数据的大量获取,为分析城市居民出行模式及理解城市功能结构提供了数据支撑。本文以道路分割城市得到的地块为研究单元,利用北京市一个月的出租车轨迹数据,对北京居民的出行模式及城市功能格局进行分析。在轨迹数据分析中,本文从轨迹数据中提取每个地块的出行量时间序列信息,然后采用结合时间序列距离度量和时间序列自身相关性的聚类方法,对出行量时间序列数据进行聚类分析,从而研究乘客出行的时空分布特征,最后结合北京市POI数据,探讨了不同区域乘客出行规律和区域功能类型的相互关系。结果表明,出租车出行量时间序列模式在工作日和周末间存在明显差异。此外,工作日的2个出行高峰与通常的通勤早晚高峰不同。由出行量所得的区域聚类结构,除具有重要交通枢纽功能的地块外,总体上以市中心为圆心大致呈同心圆分布,且距离市中心越远出行量越小。研究结果对于分析北京市居民出行行为、辅助城市交通规划具有一定的意义。
程静 , 刘家骏 , 高勇 . 基于时间序列聚类方法分析北京出租车出行量的时空特征[J]. 地球信息科学学报, 2016 , 18(9) : 1227 -1239 . DOI: 10.3724/SP.J.1047.2016.01227
Citizens′ intra-city trips are often influenced by the allocation of resources and urban functional areas, such as the educational areas, entertainment areas, business areas and residential areas. Therefore, citizens′ travelling pattern can reflect the city structure and unveil the urban function zoning. Meanwhile, the widespread of GPS vehicle navigation equipment makes it possible to achieve a vast amount of vehicle trajectory. With the support of the vast vehicle trajectory data, we can analyze citizens′ travelling mode and understand the city structure. In this paper, we investigated citizens′ travelling pattern and the urban functional structure of Beijing with the taxi trajectory data of one-month period and the information of land parcels divided by major roads. To analyze the citizen′s travelling mode, we extracted the trip volume time series in every parcel and adopted a new method which could cover the proximity on both the values and the behavior to cluster the time series data. In the end, we discussed the correlation between citizens′ travelling mode and urban functions in different regions, based on Beijing′s POI data. The result showed that there were obvious differences in the travelling patterns between the weekdays and weekends. During the weekdays, there were two rush hours, which were different from the ordinary commute rush hours. Looking at the clustering results of the weekday data, the spatial distribution of different clusters basically arranged like concentric circles, and the travelling volume of every circle decreased with respect to the increasing distance to its center. The conclusions made in this research are meaningful for the analysis of citizens′ travelling mode and for assisting urban transportation planning.
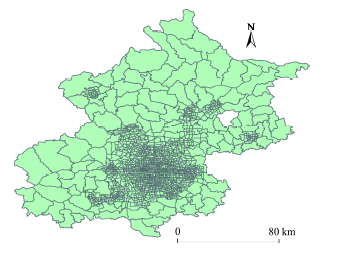
Fig.1 The division result of the traffic zones in Beijing图1 北京市地块划分结果 |
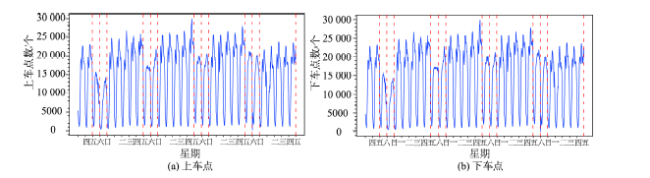
Fig.2 The time series of taxi pick-ups and drop-offs图2 出租车轨迹上下车点数量随时间变化 |
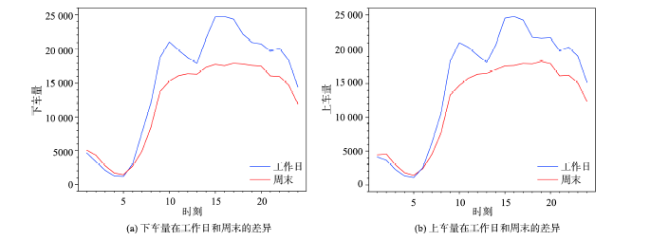
Fig.3 The comparison of daily average amount of pick-ups and drop-offs between weekdays and weekends图3 工作日周末每天平均上下车数量对比 |
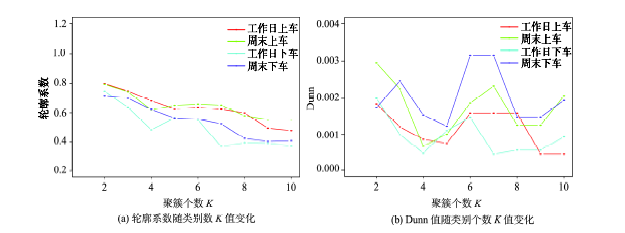
Fig.4 The changes of Silhouette and Dunn results with respect to different K values图4 轮廓系数和Dunn值随K值的变化 |
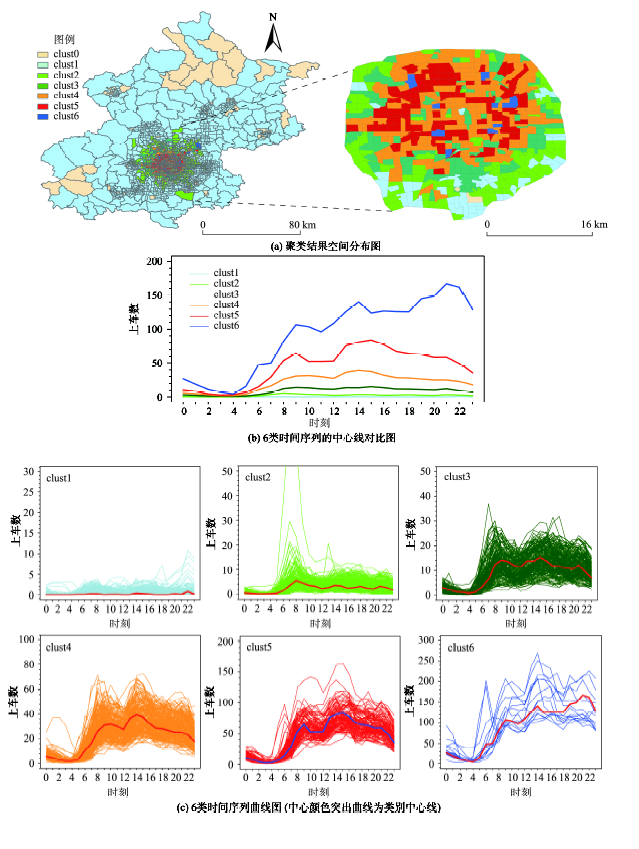
Fig.5 The clustering results of weekday pick-ups′ time series图5 工作日上车量聚类结果 |
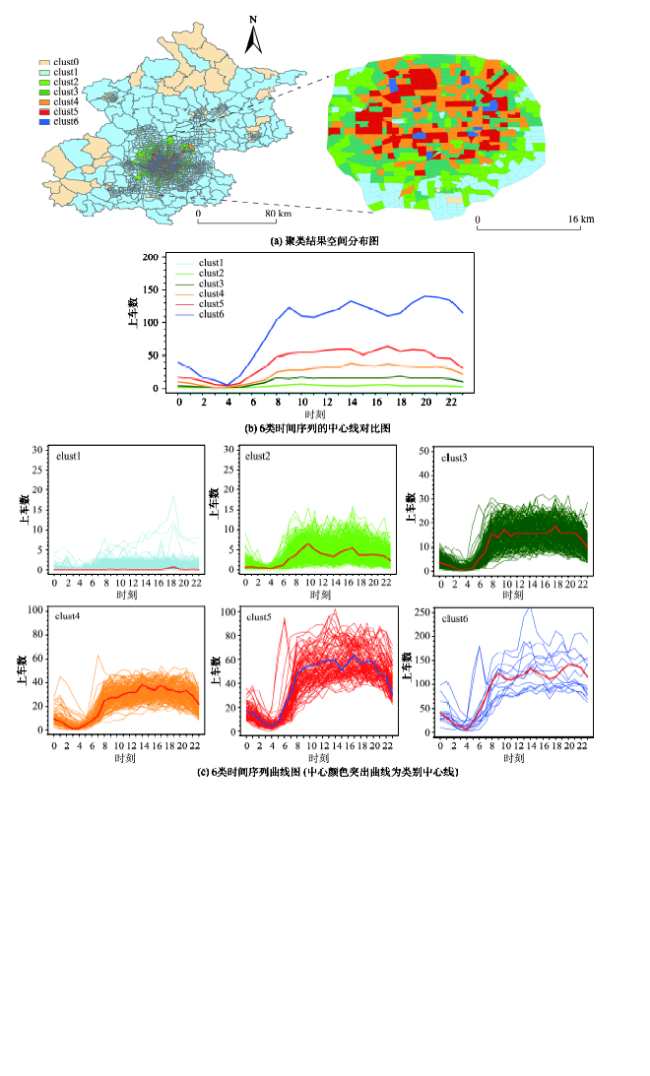
Fig.6 The clustering results of weekend pick-ups′ time series图6 周末上车量聚类结果模具费 |
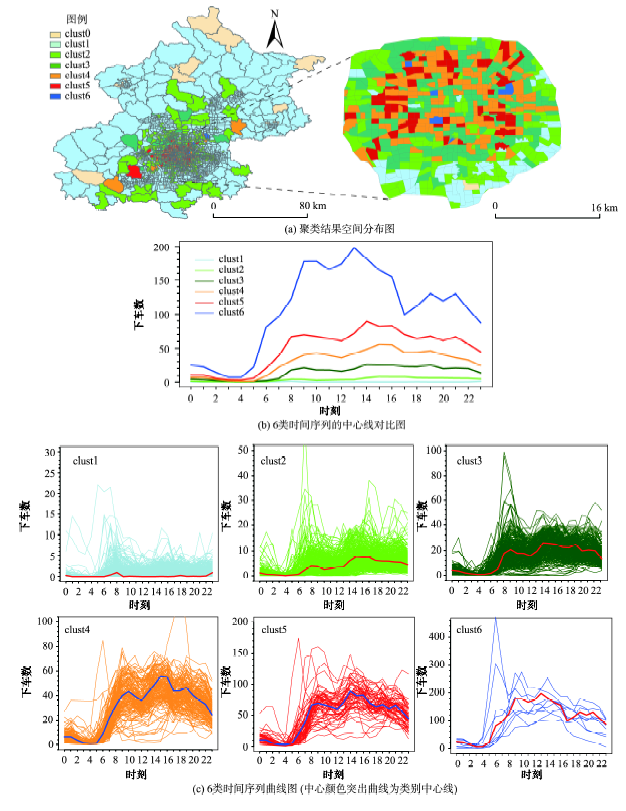
Fig.7 The clustering results of weekday drop-offs′ time series图7 工作日下车量聚类结果 |
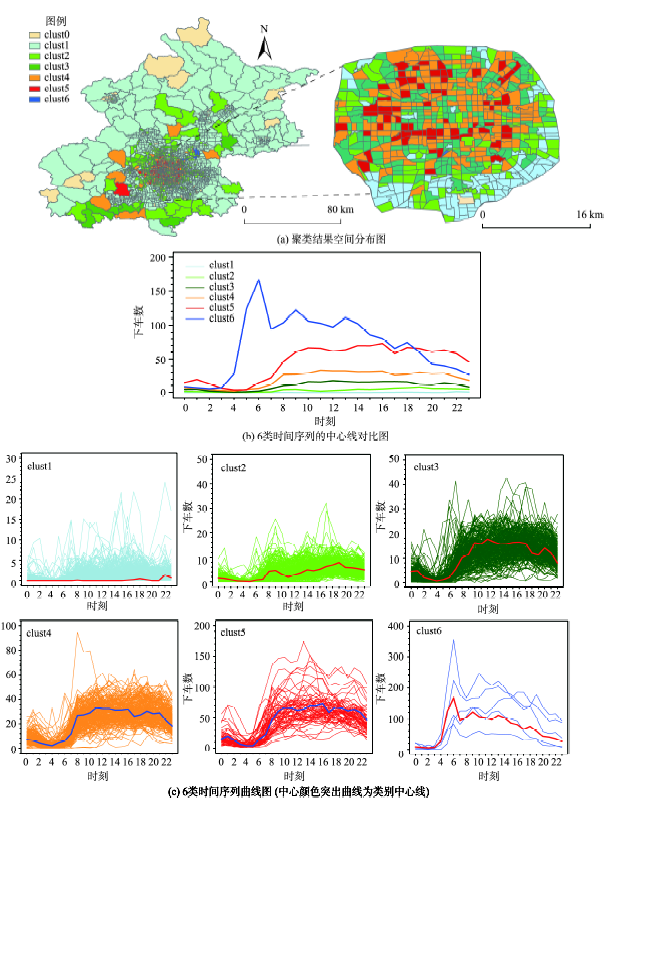
Fig.8 The clustering results of weekend drop-offs′ time series图8 周末下车量聚类结果 |
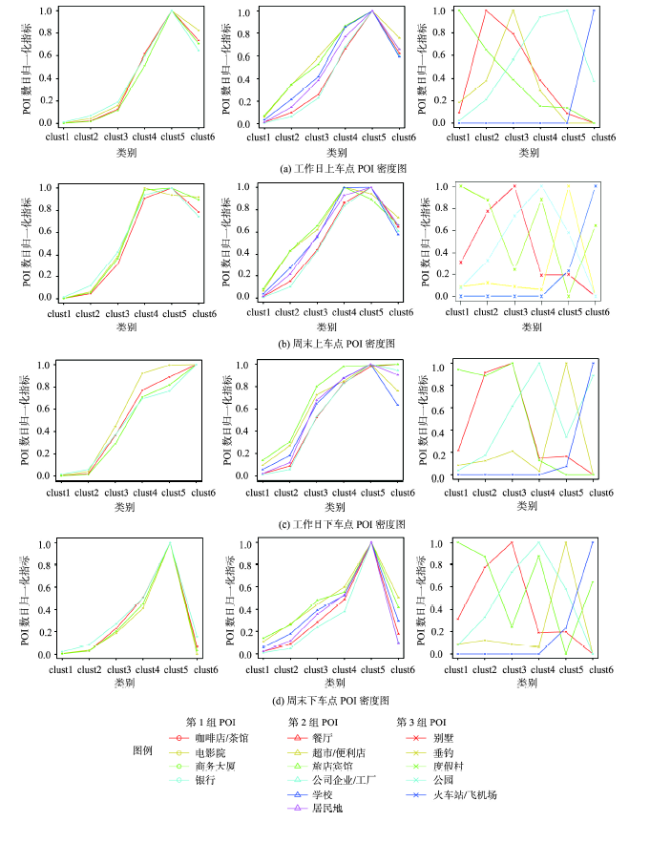
Fig.9 The normalized density of POI in every cluster (the order of the three graphs in every sub-graph set corresponds to the order of the POI groups)图9 每类地块归一化POI密度值(每组图中第1至第3幅图分别对应第1至第3组POI) |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
[
|
| [7] |
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}