
稀疏地理实体关系的关键词提取方法
作者简介:余 丽(1986-),女,博士生,研究方向为互联网空间信息搜索。E-mail: yul@lreis.ac.cn
收稿日期: 2016-07-18
要求修回日期: 2016-09-22
网络出版日期: 2016-11-20
基金资助
国家“863”计划项目(2013AA120305)
国家自然科学基金项目(41401460、41271408、41601421)
A Method of Context Enhanced Keyword Extraction for Sparse Geo-entity Relation
Received date: 2016-07-18
Request revised date: 2016-09-22
Online published: 2016-11-20
Copyright
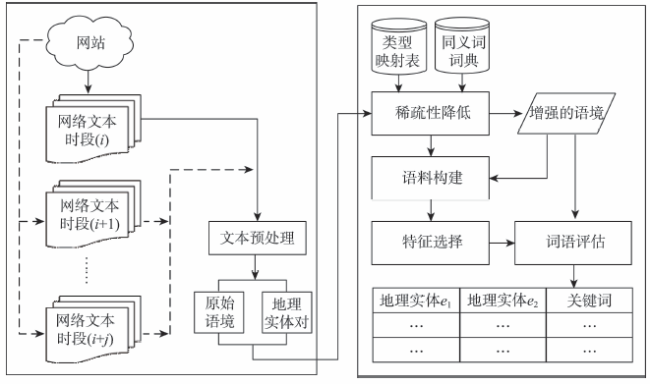
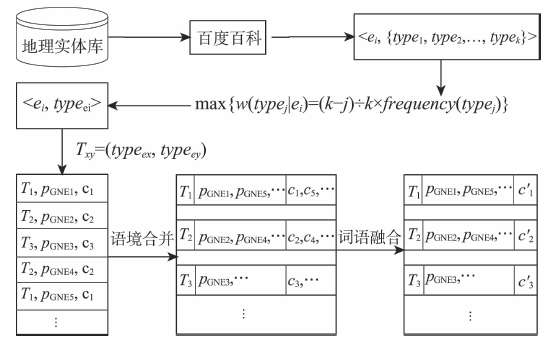
网络文本蕴含地理实体关系抽取技术,需要高时效、强鲁棒的关键词提取方法。与监督学习方法相比,无监督学习方法能捕获文本的动态变化特征并发现新增的关系类型,因此备受关注。其中,基于频率的关键词提取方法获得广泛研究,然而,网络文本蕴含的地理实体关系分布稀疏,基于频率的方法难以直接应用于地理实体关系的关键词提取。为解决该问题,本文基于公开访问的网络资源,提出一种语境增强的关键词提取方法。首先,基于在线百科和开放的同义词词典,通过语境合并和语义融合创建增强的语境,以降低语境中词语的稀疏性。接着,Domain Frequency和Entropy频率统计方法从增强语境中自动构建一个大规模语料。然后,基于该语料选择词法特征并统计其权值,用于扩大语境中词语间的差异。最后,使用选择的词法特征度量增强语境中词语的重要性,将权值最大的词语作为描述地理实体关系的关键词,并基于大规模真实网络文本开展实验。实验结果表明:对于地理实体关系的关键词识别,本文方法的平均精度为85.5%,比Domain Frequency和Entropy方法分别提高41%和36%;对于新增关键词识别,本文方法的精度达到60.3%。语境增强的关键词提取方法能有效地处理地理实体关系分布的稀疏性,可服务于网络文本蕴含地理实体关系的抽取。
余丽 , 陆锋 , 刘希亮 , 程诗奋 , 张雪英 . 稀疏地理实体关系的关键词提取方法[J]. 地球信息科学学报, 2016 , 18(11) : 1465 -1475 . DOI: 10.3724/SP.J.1047.2016.01465
Geo-entity relation recognition from rich web texts requires robust and effective keyword extraction method. Unsupervised learning methods attract more attention because they can capture dynamic variations of features in text and discover additional relation types. Frequency-based methods for keyword extraction have been extensively studied. However, the sparse distribution of geo-entity relations in web texts makes it difficult to directly apply frequency-based methods to geo-entity keyword extraction. This paper proposes a context enhanced keyword extraction method to solve this problem. Firstly, the contexts of geo-entities are enhanced to reduce the sparseness of terms, with context merging and semantic fusion. Secondly, two well-known frequency-based statistical methods (Domain Frequency and Entropy) are used to automatically build a large-scale corpus. Thirdly, the lexical features and their weights are statistically determined based on the corpus. Finally, all terms in the enhanced contexts are measured according to their lexical features and the most important terms are picked as keywords of geo-entity pairs. Experiments are conducted with large and real web texts. The results show that compared with the Document Frequency and Entropy methods, the presented method improved the precision by 41% and 36%, respectively. It also correctly generated additional 60% of keywords.
Fig. 1 The flow chart of keyword extraction applied to recognize geo-entity relations图1 地理实体关系的关键词提取流程 |
Tab. 1 A case of web text after data-processing表1 预处理后的网络文本示例 |
| 中关村/GNE | 位于/v | 海淀区/GNE | ,/w | 邻近/v |
|---|---|---|---|---|
| 北京大学/GNE | 和/c | 清华大学/GNE | 。/w | |
| 此外/d | ,/w | 中关村/GNE | 是/v | 中国/GNE |
| 的/u | 科技中心/N | ,/w | 被/p | 誉为/v |
| “/w | 中国的硅谷/GNE | ”/w | 。/w |
Tab. 2 Examples of geo-entity pairs andcorresponding keywords表2 地理实体对和关键词 |
| 地理实体对 | 关键词 |
|---|---|
| (中关村,海淀区) | (位于) |
| (中关村,北京大学) | (邻近) |
| (中关村,清华大学) | (邻近) |
| (中关村,中国) | (科技中心) |
| (中关村,中国的硅谷) | (誉为) |
Fig. 2 Sparseness reduction for terms in contexts图2 降低语境中词语的稀疏性 |
Fig. 3 Examples of extracted keywords for the first group of data图3 第1组数据提取的关键词示例 |
Tab. 3 Geo-entity pairs and involved keywords for each corpus表3 语料中的地理实体对及其关键词 |
| 编号 | #(PGNE)corpus | #(Tkw)corpus | #(Ptop5(kw))corpus | ||||
|---|---|---|---|---|---|---|---|
| 1 | 4720 | 115 | 方位词 | 包含 | 水系 | 被包含 | 行政区划 |
| 1083 | 582 | 269 | 113 | 112 | |||
| 2 | 4444 | 113 | 方位词 | 包含 | 名称 | 水系 | 行政区划 |
| 1092 | 457 | 224 | 212 | 165 | |||
| 3 | 4300 | 114 | 方位词 | 管辖 | 包含 | 名称 | 行政区划 |
| 1016 | 373 | 268 | 241 | 192 | |||
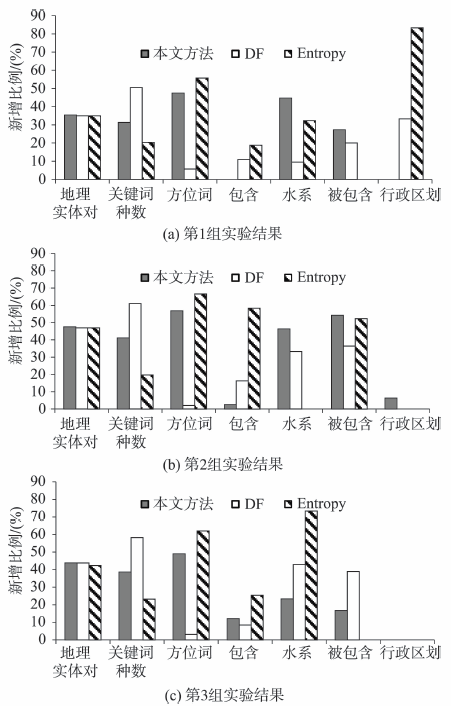
Tab. 4 Precisions of three methods for all additional extracted keywords (%)表4 3种抽取关键词方法的精度(%) |
| 关键词种类 | 本文方法 | DF | Entropy |
|---|---|---|---|
| 行政区划 | 100 | 0 | 15 |
| 被包含 | 100 | 56 | Null |
| 管辖 | 100 | 100 | 81 |
| 包含 | 100 | 18.7 | 93 |
| 水系 | 94 | 50 | 53 |
| 名称 | 66 | 13 | Null |
| 方位词 | 63.7 | 83.3 | 27.7 |
| new(kw) | 60.3 | 31.7 | 26.7 |
| 均值 | 85.5 | 44.1 | 49.4 |
Fig. 4 Additional geo-entity pairs and keywordsextracted from the experimental data图4 实验数据提取的新增地理实体对和关键词 |
Tab. 5 Comparison between different methods with respect to residual errors表5 关键词实例提取中常见错误分析 |
| 描述 | 样例 | 错误率/(%) | |||
|---|---|---|---|---|---|
| 本文方法 | DF | Entropy | |||
| A | 关键词很少出现在文本中 | “云台山除锦屏山外,其余均为海中岛屿,古称郁洲山或苍梧山。”提取的关键词实例为(云台山,苍梧山,<岛屿>),正确的关键词为“古称”,它在实验数据中出现的频次比“岛屿”更低 | 6.3 | 14.3 | 18.4 |
| B | 语境中词语在特征表现上 无显著差异 | “大夏河是甘肃省中部较大的河流,属黄河水系。”提取的关键词实例为(大夏河,黄河,<中部,属>),正确的关键词为“属”,但“中部”和“属”的权值均为最大值 | 2.5 | 5.4 | 3.1 |
| C | 同句中存在多个不同地理 实体时,关键词无法区分 | “北镇主要河流有绕阳和及其支流东沙河。”提取的关键词实例为(绕阳河,东沙河,<河流>) | 0.7 | 1.2 | 4.8 |
| D | 时间约束的关键词 | “宝山县南宋属嘉定县。”提取的关键词实例为(宝山县,嘉定县,<属>) | 0.3 | 2.9 | 1.6 |
| E | 空间约束的关键词 | “汉江以北属秦岭山区。”提取的关键词实例为(汉江,秦岭,<属>) | 0.5 | 2.1 | 1.4 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
[
|
| [9] |
|
| [10] |
|
| [11] |
[
|
| [12] |
[
|
| [13] |
|
| [14] |
[
|
| [15] |
|
| [16] |
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
[
|
| [27] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}