
支持频繁位置更新的移动对象索引方法
作者简介:彭召军(1992-),男,硕士生,研究方向为地理空间数据库索引技术和时空数据库索引技术。E-mail:107618599@qq.com
收稿日期: 2016-07-12
要求修回日期: 2016-10-23
网络出版日期: 2017-02-17
基金资助
国家自然科学基金项目(41501507)
A Moving Object Indexing Method that Supports Frequent Location Updating
Received date: 2016-07-12
Request revised date: 2016-10-23
Online published: 2017-02-17
Copyright
传统R-tree及其变种难以满足移动对象频繁更新位置的需求。本文通过在R*-tree中引入多种移动对象索引策略,提出一种基于延迟更新和备忘录更新/插入相结合的移动对象索引结构LUMR*-tree(Lazy Update Memo R*-tree)。利用延迟更新策略,LUMR*-tree能够在几乎不改变索引结构的前提下快速完成更新操作;通过引入更新备忘录(Update Memo, UM),LUMR*-tree将复杂的更新操作简化为插入操作,避免了从索引树中频繁删除旧记录的过程;借助垃圾清理器定期清理索引树和UM中的旧记录,动态维护UM中的数据项和内存大小,保证了LUMR*-tree的稳定性和高效性。实验结果表明,LUMR*-tree通过牺牲少量查询性能获得了优良的更新性能,能够满足移动对象频繁位置更新的需求,具有较好的实用价值和广泛的应用前景。
关键词: 移动对象; R*-树; 延迟更新; LUMR*-tree; UM
彭召军 , 封俊翔 , 王青山 , 熊伟 . 支持频繁位置更新的移动对象索引方法[J]. 地球信息科学学报, 2017 , 19(2) : 152 -160 . DOI: 10.3724/SP.J.1047.2017.00152
Traditional R-tree and its variants cannot support frequent location updating of moving objects. By introducing a variety of moving object indexing strategies in R*-tree, we proposed a moving object index structure-LUMR*-tree (Lazy Update Memo R*-tree), which combines lazy update and memo update/insert strategy. The LUMR*-tree can quickly complete update without changing its structure by lazy update strategy. It can also simplify an update operation to an insert operation with the Update Memo (UM), which can avoid frequently purging old entries from the index tree effectively. The removal of old entries is implemented by a garbage cleaner inside the LUMR*-tree. Thus, data items and memory size of UM are maintained dynamically, which ensures high stability and efficiency of the LUMR*-tree. Experimental results show that, the LUMR*-tree achieved significantly higher update performance at the cost of slightly poorer query performance, it can support frequent location updating of moving objects. To sum up, the LUMR*-tree has good practical values and wide application prospects.
Key words: Moving Object; R*-tree; Lazy Update; LUMR*-tree; UM
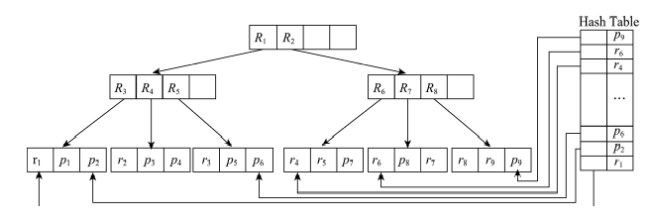
Fig. 1 Structure of R*-tree and auxiliary index图1 R*-tree结构和二次索引 |
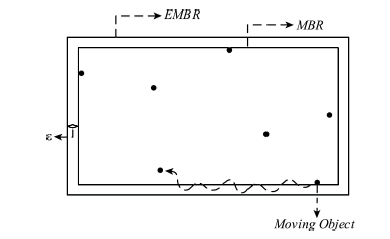
Fig. 2 Extended MBR图2 扩展 MBR |
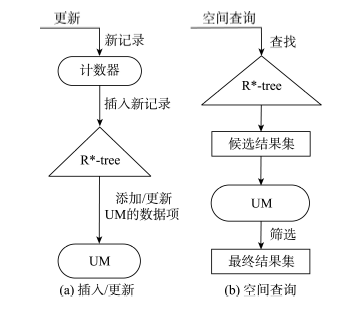
Fig. 3 Spatial operation processes of R*-treewith update memo图3 加入UM的R*-tree空间操作流程 |
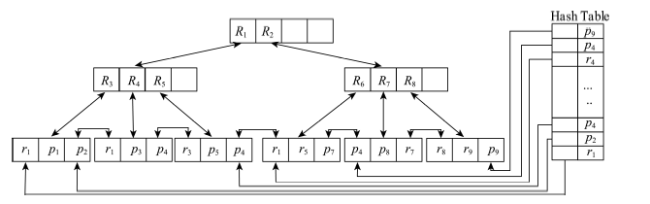
Fig. 4 Structure of LUMR*-tree图4 LUMR*-tree结构图 |
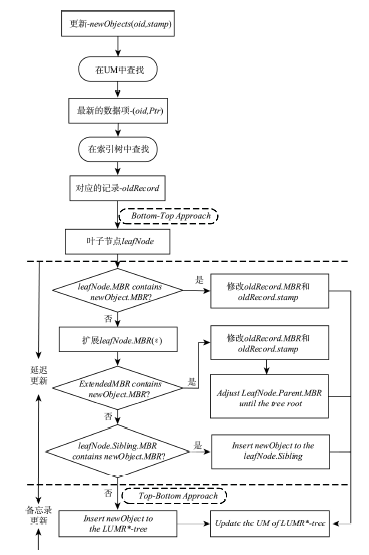
Fig. 5 Updated processes of LUMR*-tree图5 LUMR*-tree的更新流程 |
Tab. 1 Experiment parameters and values表1 常用实验参数及取值 |
| 参数 | 值 |
|---|---|
| 移动对象的数量(M) | [1, 10],1 |
| 目录矩形扩展率() | (0,0.0025,0.005),0.0025 |
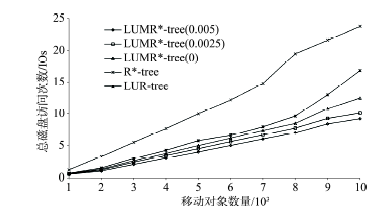
| 更新次数(次) | [1000,10000],1000 |
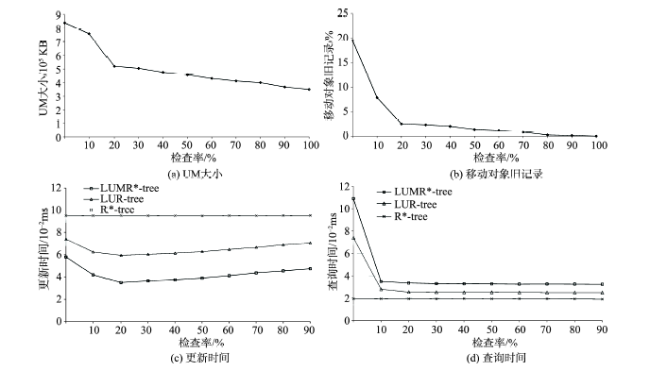
| 检查率(ir) | [0,1],20% |
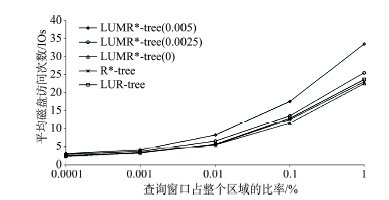
| 查询窗口占整个区域的比率 | (0.0001%,0.001%,0.01%,0.1%,1%),0.01% |
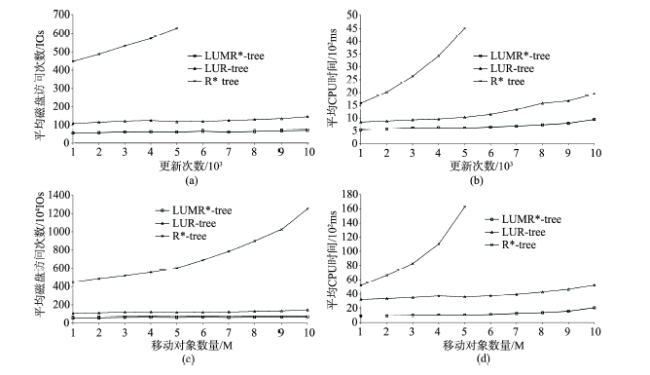
Fig. 6 Average disk I/O (range query)图6 平均磁盘访问次数(范围查询) |
Fig. 7 Total disk I/O (1000 updates)图7 总磁盘访问次数(1000次更新) |
Fig. 8 Effect of inspection ratio图8 检查率的影响 |
Fig. 9 Updating cost图9 更新代价 |
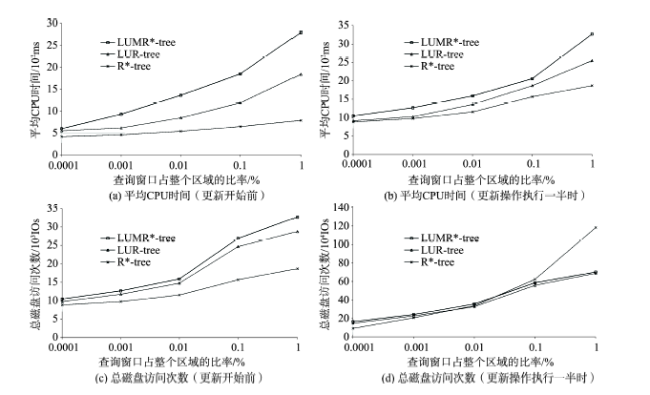
Fig. 10 Window searching图10 窗口查询 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
[
|
| [15] |
|
| [16] |
Marios Hadjieleftheriou. libSpatialindex[DB/OL].https://github.com/libspatialindex/ libspatialindex.
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}