
基于 HBase 的面向语义单元的室内移动对象索引
作者简介:张得群(1991-),男,河南新乡人,硕士生,主要从事室内移动对象管理与分析方面研究。E-mail:dequn92@foxmails.com
收稿日期: 2016-07-27
要求修回日期: 2016-09-29
网络出版日期: 2017-03-20
基金资助
国家自然科学基金项目(41590845)
山西省-中国科学院科技合作项目(20141011001)
Semantic Cell Oriented Indoor Moving Objects Index based on HBase
Received date: 2016-07-27
Request revised date: 2016-09-29
Online published: 2017-03-20
Copyright
随着室内定位技术的广泛应用,传感器记录了大量室内移动对象的位置数据,而索引技术作为移动对象数据分析的基础工作也得到越来越多的研究。已有索引技术多是针对室外空间的移动对象,不能支持室内移动对象数据的三维立体性、轨迹的复杂性、随机性等特点,这些索引技术也仅仅关注了移动对象的位置信息,忽略了语义信息,不能有效地支持室内移动对象的管理和分析,并且当面对海量的移动对象数据时,这些架构在传统关系型数据库上的索引都存在性能瓶颈问题。因此,本文提出了面向语义单元的移动对象表达模型,利用语义单元将室内移动对象的位置语义化,设计了SCoII (Semantic Cell Oriented Indoor moving objects Index)索引结构对室内移动对象的历史数据进行索引,能够有效支持语义粒度上的时空范围查询、移动对象语义轨迹查询。索引基于HBase实现,能够适应大规模的并发更新与查询,具有良好的规模扩展性,规避了大数据给传统数据库带来的性能瓶颈问题,实验证明其具有良好的更新和查询性能。该索引的实现方便了基于语义的室内移动对象分析和数据挖掘工作,为今后的分析工作奠定了基础。
张得群 , 谢传节 , 裴韬 . 基于 HBase 的面向语义单元的室内移动对象索引[J]. 地球信息科学学报, 2017 , 19(3) : 307 -316 . DOI: 10.3724/SP.J.1047.2017.00307
With the development of indoor positioning technique, more and more position data of indoor moving objects are recorded by sensors. As the basic work of moving objects database, index technique has become a research hot-spot. Majority of existing moving objects index are for outdoor moving objects which are not suitable for indoor environment. Also, they only build index on geography coordinates of moving objects, lack of supporting of semantic information which can offer effective support for management and analysis of indoor moving objects. There will be a performance bottleneck when massive data are ingested and frequent querying are asked when implemented on traditional relational database. In this paper, we built a grid of indoor floor environment and create a map relation from grid to semantic cell. Then, we utilized this map to semanticize indoor moving objects’ location if it was contained in a semantic cell. After this work, we built an index called SCoII (Semantic Cell Oriented Indoor moving objects Index). SCoII can answer not only semantic spatio-temporal range query but also indoor moving object’s semantic trajectory query, which can support for semantic-based analysis of indoor moving objects. SCoII is implemented on HBase, so it also avoided the performance degradation of traditional relational database when encounting massive data and have good performance of updating and querying without bottleneck. Experimental results also showed that it can be adapt to big data. Supporting for semantic information of indoor moving object is the most important feature of SCoII. More data mining jobs can be done on indoor moving object’s semantic location and semantic trajectory such as the simple example given out at the end. Management and analysis based on semantic of indoor moving objects will be convenient on SCoII, which lays a foundation of analysis work in the future.
Key words: indoor; moving objects; index; semantic; HBase
Tab. 1 List of moving objects index表1 移动对象索引总结 |
| 索引分类 | 索引名称 | 索引结构 | 支持的查询种类 |
|---|---|---|---|
| 基于传统数据库的 移动对象索引 | RTR-TP2R-tree | R-tree | 室内时空范围查询、轨迹查询 |
| DR-tree | R-tree | 室内对象轨迹查询 | |
| ACII | 先 R-tree后 Hash | 全时态移动对象查询 | |
| MQII | Hash后使用链表指针 | 对象查询、范围查询 | |
| 基于分布式数据库的 移动对象索引 | MD-HBase | KD-tree/Quad-tree + Z-ordering | 时空范围查询 |
| Pyro | Moore | 时空范围查询 | |
| GeoMesa | Z-ordering | 对象查询、时空范围查询 | |
| STEHIX | Hilbert + Quad-tree + 分段索引 | 时空范围查询,kNN |
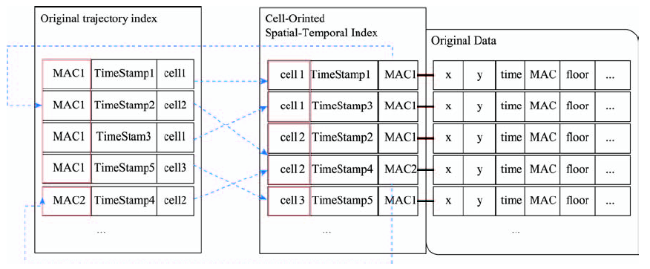
Fig. 1 Structure of SCoII图1 面向语义单元的室内移动对象索引结构 |
Tab. 3 A sample result of semantic trajectory query表3 语义轨迹查询结果示例 |
| Cell名称 | 进入时间 | 离开时间 | 停留时长/s |
|---|---|---|---|
| Rouge Diamant | 12:21:24 | 12:21:26 | 2 |
| 过道 | 12:21:26 | 12:21:28 | 2 |
| Rouge Diamant | 12:21:28 | 12:21:31 | 3 |
| Bcuthentique | 12:21:31 | 12:22:29 | 58 |
| FIVE PLUS+ | 12:23:14 | 12:24:01 | 47 |
| TRENDIANO | 12:27:51 | 12:50:04 | 1333 |
| Levi's ladies | 12:50:04 | 13:04:53 | 889 |
| Jack jones | 13:27:16 | 13:28:16 | 60 |
| TEENIE&WEENIE | 13:28:58 | 13:30:56 | 118 |
| TEENIE&WEENIE | 13:41:22 | 17:43:14 | 14 512 |
| H&M | 17:43:14 | 17:57:07 | 833 |
Fig. 2 Storage Structure of SCoII图2 SCoII存储结构 |
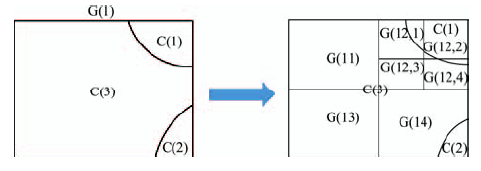
Fig. 3 Procedures of grid sub-division图3 Grid四分细化过程 |
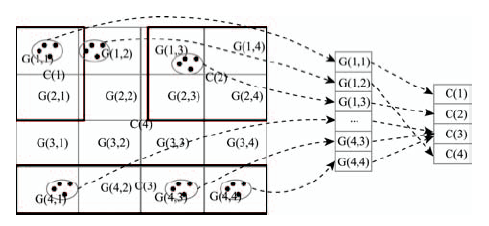
Fig. 4 Utilizing Grid Index to determine cell which an IMO dropped in图4 利用Grid索引快速判断移动对象所处的语义单元 |




Tab. 2 Fields of a positioning record表2 定位记录字段组成 |
| 字段 | 含义 |
|---|---|
| x | X坐标值 |
| y | Y坐标值 |
| floor | 定位点所在的楼层,20040表示F4,10020表示B2 |
| time | 数据采集的时间,精确到秒 |
| mac | 定位对象设备的物理地址 |
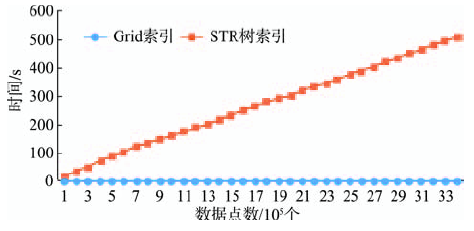
Fig. 5 Efficiency comparison between GridCell and STR-tree图5 GridCell与STR判断语义单元效率对比 |
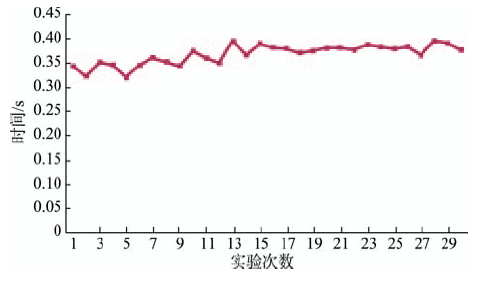
Fig. 6 Time needed for updating every ten thousand points on HBase图6 HBase数据更新效率(s/万) |
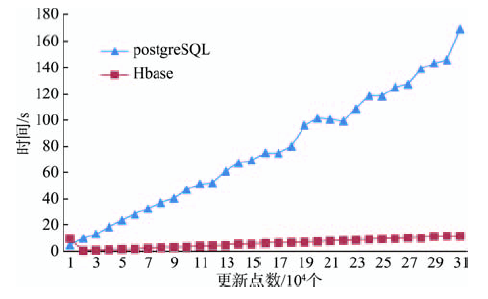
Fig. 7 Efficiency comparison between HBase and PostgreSQL图7 HBase与PostgreSQL更新效率对比 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
|
| [3] |
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
|
| [10] |
[
|
| [11] |
[
|
| [12] |
|
| [13] |
|
| [14] |
[
|
| [15] |
[
|
| [16] |
|
| [17] |
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}