
景观指数的并行计算方法
作者简介:刘 洋(1991-),女,陕西西安人,硕士生,研究方向为高性能地理计算。E-mail:youngliu2@163.com
收稿日期: 2016-07-19
要求修回日期: 2016-11-01
网络出版日期: 2017-04-20
基金资助
教育部高等学校博士学科点专项科研基金项目(20130145120013)
A Parallel Algorithm for Landscape Metrics
Received date: 2016-07-19
Request revised date: 2016-11-01
Online published: 2017-04-20
Copyright
随着地理信息科学和系统的发展,GIS数据的时空分辨率和数据量呈现爆炸式的增长趋势。传统的基于个人计算机的景观指数计算软件难以有效快速地完成海量数据的空间分析。针对该问题,本文提出了一个高效的景观指数并行计算方法。首先对原有的并查集连通域标记算法进行了2点改进:① 在第2次遍历数据时,增加了计算斑块面积、周长等斑块基本信息的功能,为景观指数的计算提供必要参数;② 在第2次遍历过程中,增加了重新标记连续序号的功能,减少了原有算法在合并操作后造成的序号不连续,需要重新遍历数据的开销。在此基础上,本文利用MPI并行编程库,采用数据分割和主从进程协同的并行计算模式实现了景观指数的并行计算。实验表明,在保证计算正确性的基础上,本文的并行算法大幅度提高了景观指数的计算性能,为快速分析大规模数据的景观形态和格局提供了有效手段。
刘洋 , 关庆锋 . 景观指数的并行计算方法[J]. 地球信息科学学报, 2017 , 19(4) : 457 -466 . DOI: 10.3724/SP.J.1047.2017.00457
Landscape metrics have been widely used to quantitatively evaluate the spatial patterns of landscapes and to analyze the temporal dynamics of landscapes and their effects. However, when dealing with massive amounts of data, the calculation of landscape metrics requires large amount of computing time and extremely large memory size, which greatly decreases the feasibility in real-world applications. This paper presents a parallel algorithm to improve the performance of landscape metric calculation. First, the classical two-pass connected component labeling (CCL) algorithm was modified: (1) the calculations of some basic geometrical metrics of patches, such as areas and perimeters, are integrated into the second pass of the data for the calculation of landscape metrics; and (2) continuous patch IDs are generated along the second pass, to reduce the overheads for re-labeling. Then, a parallel algorithm consisting of a master process and a set of worker processes is designed and implemented using the C++ programming language and Message Passing Interface (MPI). In our parallel algorithm, the whole spatial domain is decomposed into multiple sub-domains and assigned to a set of concurrent processes. Each process uses the modified CCL algorithm to identify the patches within its assigned sub-domain and calculates the basic geometrical metrics of the patches. After gathering and merging the basic metrics from other processes, the master process calculates the final landscape metrics. The experiments using the land-use dataset of California showed that the computing time of landscape metrics was largely reduced using multiple processes. In conclusion, our parallel algorithm provides a high-performance solution for landscape metric calculation using massive and high-resolution datasets.
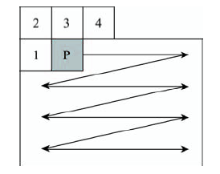
Fig. 1 Scanning the pixels of image using a mask in the connected component labeling algorithm图1 连通区域标记算法利用邻域模板扫描图像 |
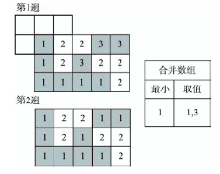
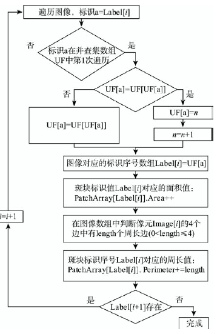
Fig. 2 CCL with two passes图2 2次遍历的连通区域标记算法 |
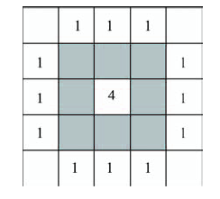
Fig. 3 Boundary edges of a patch and its perimeter calculation图3 斑块的边界边和斑块周长计算 |
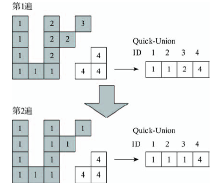
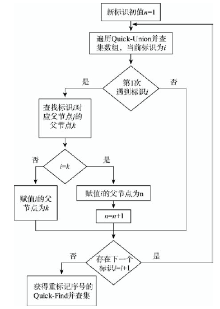
Fig. 4 Label merging by Quick-Union after the second pass图4 图像2次遍历后Quick-Union并查集合并标记 |
Fig. 5 The relabeling process in the Union-Find Array图5 重标记并查集数组的流程图 |
Fig. 6 The relabeling process in the second pass of CCL图6 连通域标记算法在第2次遍历时重标记序号的合并流程图 |
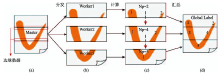
Fig. 7 The basic idea of the parallel algorithm for landscape metrics图7 景观指数并行算法的总体思路 |
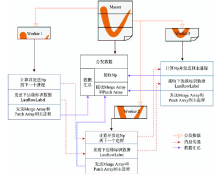
Fig. 8 Framework of parallel algorithm图8 并行算法总体计算过程 |
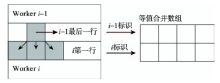
Fig. 9 Finding the patches to merge at the margins of sub-datasets图9 记录子数据块边缘斑块信息 |
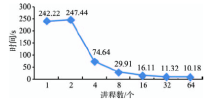
Fig. 10 Computing time of the parallel algorithm for landscape metrics图10 并行景观指数算法的计算时间 |
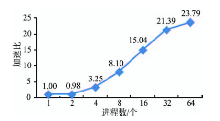
Fig. 11 Speed-ups of the parallel algorithm for landscape metrics图11 并行景观指数计算的加速比 |
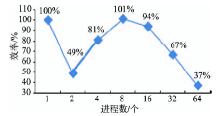
Fig. 12 Efficiencies of the parallel algorithm for landscape metrics图12 并行景观指数计算的效率 |
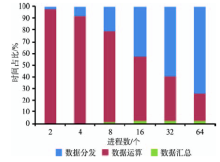
Fig. 13 Percentages of three parts in the parallel algorithm图13 并行计算的分步百分比堆积时间图 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
阿里木江·卡斯木,
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
[
|
| [19] |
|
| [20] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}