
论地理知识图谱
作者简介:陆 锋(1970-),博士,研究员,博士生导师,中国GIS协会理论与方法委员会主任,ACM SIGSpatial China主席,主要从事空间数据模型、空间数据库、空间数据挖掘、知识图谱、导航与位置服务等研究。E-mail: luf@lreis.ac.cn
收稿日期: 2017-04-28
要求修回日期: 2017-05-25
网络出版日期: 2017-06-20
基金资助
国家自然科学重点基金项目(41631177)
中国科学院重点部署项目(ZDRW-ZS-2016-6-3)
On Geographic Knowledge Graph
Received date: 2017-04-28
Request revised date: 2017-05-25
Online published: 2017-06-20
Copyright
陆锋 , 余丽 , 仇培元 . 论地理知识图谱[J]. 地球信息科学学报, 2017 , 19(6) : 723 -734 . DOI: 10.3724/SP.J.1047.2017.00723
Web texts contain a great deal of implicit geospatial information, which provide great potential for the geographic knowledge acquisition and service. Geographic knowledge graph is the key to extend traditional geographic information service to geographic knowledge service, and also the ultimate goal of the collection and processing of implicit geographic information from web texts. This paper systematically reviews the state of the arts of the researches on open geographic semantic web, geographic entity and relation extraction, geographic semantic web alignment, and knowledge graph storage methods. The pressing key scientific issues are also addressed, including the quality evaluation of geospatial information collected from web texts, geographic semantic understanding, spatial semantic computing model, and heterogeneous geographic semantic web alignment.
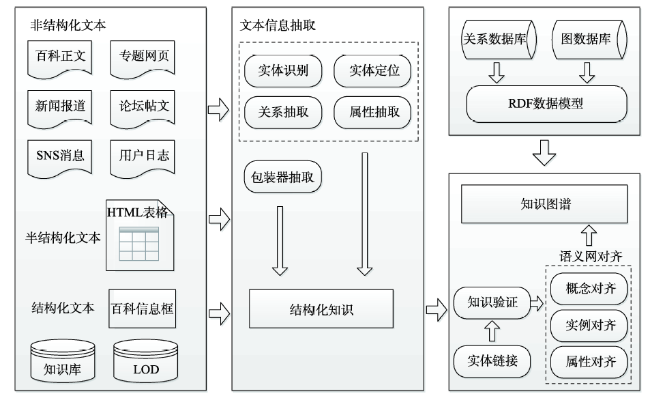
Fig. 1 Flowchart of knowledge graph building图1 知识图谱构建基本流程 |
Tab. 1 Open geographical semantic web表1 开放地理语义网(个) |
| 语义网名称 | 类数量 | 属性数量 | 实例数量 | 三元组数量 |
|---|---|---|---|---|
| OSM Semantic Network | 924 | 4 217 | - | - |
| GeoNames Ontology | 690 | 28 | 10 951 423 | 150 000 000 |
| GeoWordNet | 334 | - | 3 600 000 | 53 000 000 |
| LinkedGeoData | - | - | 1 100 000 000 | 20 000 000 000 |
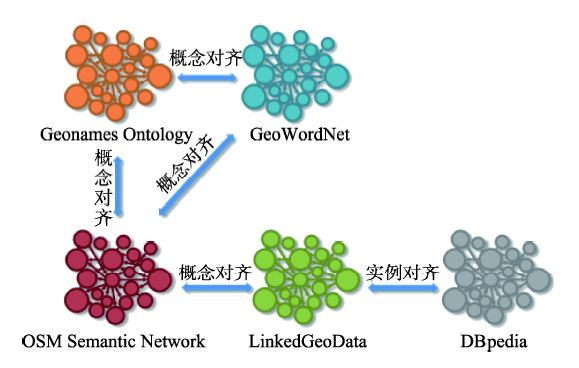
Fig. 2 State of the arts for open geographical semantic web alignment图2 开放地理语义网对齐现状 |
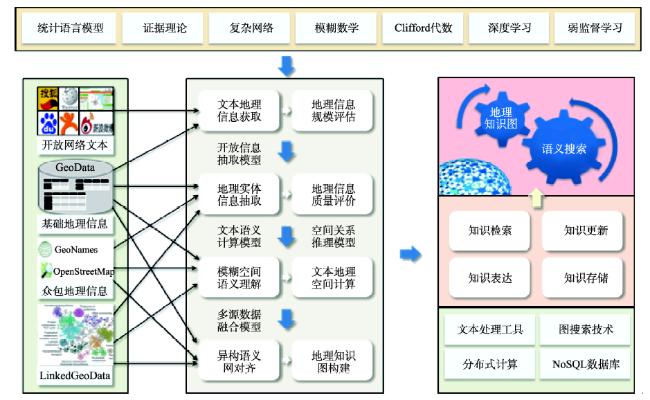
Fig. 3 Flowchart of geographical knowledge graph building图3 地理知识图谱构建技术流程 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
[
|
| [16] |
[
|
| [17] |
|
| [18] |
|
| [19] |
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
[
|
| [24] |
[
|
| [25] |
[
|
| [26] |
|
| [27] |
|
| [28] |
[
|
| [29] |
|
| [30] |
[
|
| [31] |
|
| [32] |
[
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
OWL Web Ontology Language Overview[EB/OL].OWL Web Ontology Language Overview[EB/OL]. /, 2004
|
| [37] |
|
| [38] |
[
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
[
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|
| [52] |
[
|
| [53] |
[
|
| [54] |
|
| [55] |
|
| [56] |
|
| [57] |
|
| [58] |
|
| [59] |
|
| [60] |
|
| [61] |
|
| [62] |
|
| [63] |
|
| [64] |
|
| [65] |
|
| [66] |
|
| [67] |
|
| [68] |
|
| [69] |
|
| [70] |
|
| [71] |
|
| [72] |
Resource Description Framework (RDF): Concepts and Abstract Syntax[EB/OL]. ,2004.
|
| [73] |
|
| [74] |
[
|
| [75] |
|
| [76] |
|
| [77] |
|
| [78] |
|
| [79] |
[
|
| [80] |
[
|
| [81] |
[
|
| [82] |
|
| [83] |
|
| [84] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}