
支持时空耦合计算的HTM-ST日地空间系统数据组织模型
作者简介:康栋贺(1993-),男,硕士生,研究方向日地空间时空数据组织与计算。E-mail: kangdonghe.k@gmail.com
收稿日期: 2017-02-08
要求修回日期: 2017-03-26
网络出版日期: 2017-06-20
基金资助
中国科学院科研信息化专项“空间科学领域云”建设与应用课题(XXH12503-05-08)
HTM-ST: A Data Model Supporting Spatio-Temporal Coupled Computation for Solar-Terrestrial System
Received date: 2017-02-08
Request revised date: 2017-03-26
Online published: 2017-06-20
Copyright
数据组织模型是对科学数据进行有效管理、共享与应用的基础。日地空间物理学科通常采用基于语义标注的传统数据组织模型,但是该模型忽略了数据间的时空关系,难以支持大规模数据处理与关联分析,应建立一种支持时空计算的数据组织模型,从而有效支持当前日地空间物理领域对数据快速发现、精细结构识别、耦合关系研究与时空演化分析等方面的应用需求。鉴于此,本文提出了HTM-ST离散化时空数据组织模型,该模型在层次三角网格的基础上,在时间维度通过等长剖分进行扩展,从而形成离散化的时空剖分,采用时-空耦合编码将高维的剖分单元组织到一维空间中,并基于上述剖分结构与编码算法在HBase环境下设计了模型的存储方案。本文利用多颗极轨卫星的能量粒子探测数据实现了该数据组织模型的原型示范系统,并设计了基于该模型的时空查询算法和地方时全球数据插值算法,用于对该模型进行实验验证。实验分析表明,HTM-ST模型具有高效性和鲁棒性,可以作为面向时空关系的日地空间物理数据组织与存储基础。
康栋贺 , 邹自明 , 胡晓彦 , 钟佳 . 支持时空耦合计算的HTM-ST日地空间系统数据组织模型[J]. 地球信息科学学报, 2017 , 19(6) : 735 -743 . DOI: 10.3724/SP.J.1047.2017.00735
Data Model is the basis for the effective management, sharing and application of scientific data. Nowadays, the sematic data model is a conventional and dominant data organization method in the solar-terrestrial physics domain which aims to describe data along with its various metadata, such as observatories, instruments, and data types etc. However, it’s difficult to support mass data processing and correlation analysis because the model neglects the temporal and spatial relations among data. Hence, a data model supporting spatio-temporal computation should be established to facilitate data discovery, fine structure identification, coupling relation research and spatio-temporal evolution analysis and other research hotspots of solar-terrestrial physics. Therefore, this paper proposed a computable spatio-temporal data model, HTM-ST that supports these applications. On the basis of the HTM global discrete grid, this model established discrete spatio-temporal subdivision by extending HTM’s spherical units to equal-divided time dimension. Besides, a novel spatio-temporal coupled coding algorithm is described to represent these high-dimensional units in the one-dimensional space. Meanwhile, the model’s storage scheme is designed and implemented in the HBase platform based on the model’s subdivision structure and coding algorithm. In this paper, a prototype system is implemented to evaluate the efficiency of the model, by comparing multiple spatio-temporal queries over energetic particle data observed by five polar orbit satellites. The experimental results show that HTM-ST data model is more efficient and robust. It could be used as the solar-terrestrial physics data organization and storage foundation for spatio-temporal relationship.
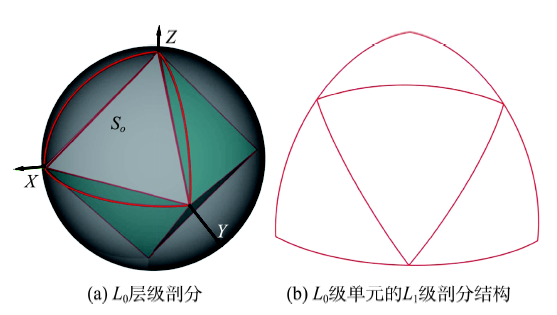
Fig. 1 An illustration of the HTM subdivision method图1 HTM网格剖分示意图 |
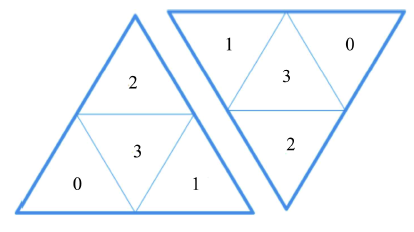
Fig. 2 Coding template of HTM图2 HTM编码模板 |
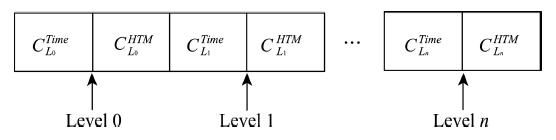
Fig. 3 Coupled coding structure图3 耦合编码结构 |
Tab. 1 Data record storage表1 数据记录存储 |
| Row Key | Time Stamp | Column Family: Electric Field | Column Family: Magnetic Field | Column Family: Energetic Particles | Column Family: Neutral Gas | Column Family: Plasma | Column Family: Irradiance | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Variable | Value | Variable | Value | Variable | Value | Variable | Value | Variable | Value | Variable | Value | |||||||
| ID1 | t1 | EF:Var1 | Value1 | EP:Var4 | Value4 | NG:Var6 | Value6 | |||||||||||
| t2 | EF:Var2 | Value2 | P:Var7 | Value7 | I:Var8 | Value8 | ||||||||||||
| t3 | MF:Var3 | Value3 | EP:Var5 | Value5 | ||||||||||||||
| ID2 | t4 | EF:Var1 | Value9 | P:Var7 | Value11 | |||||||||||||
| t5 | EP:Var4 | Value9 | ||||||||||||||||
Tab. 2 Special attribute表2 特殊属性 |
| Row Key | Time Stamp | Column Family: cf | Column Family: attr | |||
|---|---|---|---|---|---|---|
| Variable | Value | Variable | Value | |||
| Var1 | t1 | cf: | EF | attr: sat | NOAA-15 | |
| t2 | attr:instr | MEPED | ||||
| Var2 | t3 | cf: | EF | attr: sat | NOAA-18 | |
Tab. 3 Configuration of software and hardware表3 集群软、硬件配置表 |
| 硬件环境 | 软件环境 | ||||
|---|---|---|---|---|---|
| 节点数目/个 | 4 | 操作系统 | Centos 6.5 | ||
| CPU | 2核 | Hadoop | 1.2.1 | ||
| 内存/GB | 8 | HBase | 0.98 | ||
| 硬盘/GB | 500 | ||||
Fig. 4 An illustration of single constraint图4 单球冠查询示意图 |
Tab. 4 Parameters of global data interpolation表4 全球数据插值计算参数表 |
| 参数名称 | 备注 | 示例 |
|---|---|---|
| a | 物理要素标识 | Var1(40~130 kev电子积分通量) |
| T | 研究时间范围 | [20140201000000, 20140214120000) |
| LT | 地方时时段 | 00:00至03:00 |
| 地方时时段集合,时段互不重叠且覆盖完整24小时 |
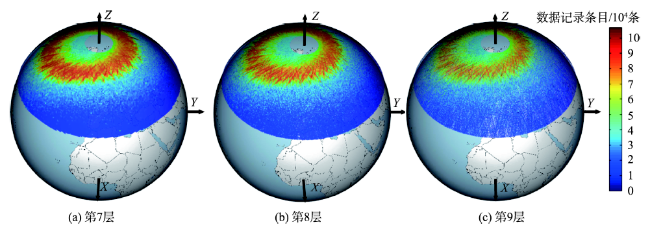
Fig.5 Query results of zone Ⅰ(North of 30°)图5 范围Ⅰ(北纬30°以上)查询结果 |
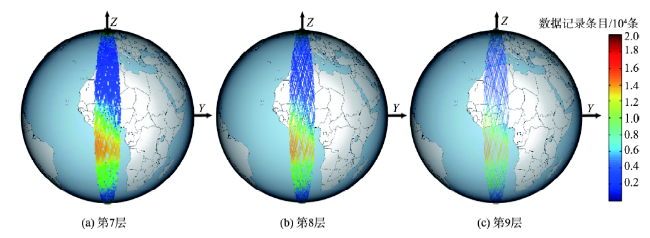
Fig.6 Query results of zone Ⅱ(7.5° W~7.5° E)图6 范围Ⅱ(7.5° W~7.5° E)查询结果 |
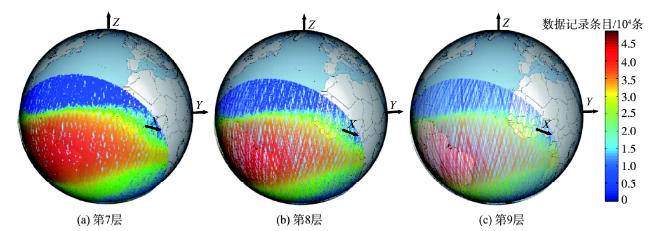
Fig. 7 Query results of zone Ⅲ(South Atlantic Anomaly)图7 范围Ⅲ(南大西洋异常区)查询结果 |
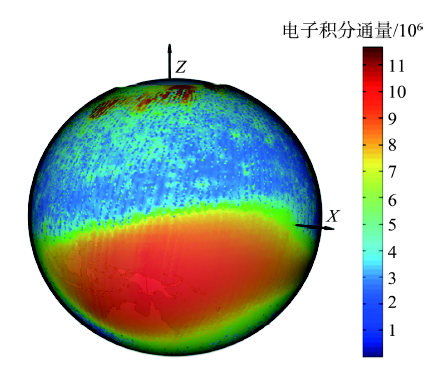
Fig. 8 Global distribution of electron integral flux from local time 00:00 to 03:00图8 地方时0:00-3:00的全球电子积分通量分布图 |
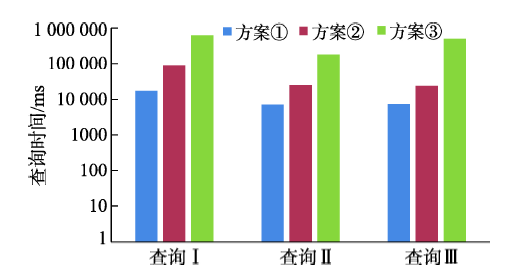
Fig. 9 Query efficiency comparison of different coding methods图9 不同编码算法的查询效率对比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
[
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}