
GPU加速的改进PAM聚类算法研究与应用
作者简介:周恩波(1992-),男,江西丰城人,研究生,主要从事时空大数据分析与云计算方面研究。E-mail: enbozhou@pku.edu.cn
收稿日期: 2016-10-11
要求修回日期: 2017-03-22
网络出版日期: 2017-06-20
基金资助
国家重点研发计划重点专项(2016YFC0801800)
Research and Application of Accelerating Improved PAM Clustering Algorithm by GPU
Received date: 2016-10-11
Request revised date: 2017-03-22
Online published: 2017-06-20
Copyright
空间聚类是空间数据挖掘的重要方法,而K-Medoids是一种常用的空间聚类算法。K-Medoids聚类算法存在初始点选择问题,而且计算复杂。为了提高算法的有效性和时间效率,本文结合模拟退火算法思想,改进了传统的K-Medoids算法PAM,提出一种基于GPU计算的并行模拟退火PAM算法。类比矩阵乘法运算,定义了一种新的矩阵计算方法,可以有效减少数据在GPU全局内存和共享内存之间的传输,提高了算法在GPU中的执行效率。利用模拟退火算法搜索聚类中心点,保证了聚类结果的全局最优性。基于不同的数据集,将串行和并行模拟退火PAM算法以及已有的遗传PAM算法进行比较,结果表明并行模拟退火PAM算法聚类结果正确,且时间效率高。最后,应用本文改进算法对贵州省安监系统的安全监管隐患数据进行聚类分析,发现了隐患聚集中心,相关结果对政府的决策具有一定的实际应用价值。
周恩波 , 毛善君 , 李梅 , 孙振明 . GPU加速的改进PAM聚类算法研究与应用[J]. 地球信息科学学报, 2017 , 19(6) : 782 -791 . DOI: 10.3724/SP.J.1047.2017.00782
Spatial clustering is one of the most important methods in spatial data mining. As a common but powerful spatial clustering algorithm, K-Medoids is applied in many fields such as generalization of spatial entity information, spatial point pattern analysis and epidemiology application. However, K-Medoids algorithm meets two main challenges innately as follow. At first, K-Medoids has selection problem of the initial medoids. Different initial medoids may not attain the same clustering results which could lead to a non-optimal results sometimes. Furthermore, time efficiency of the algorithm is not satisfactory because there exist quantities of iterations to find the most suitable partition. Existing studies on the K-Medoids algorithm don’t take the validness and time efficiency into consideration at the same time. Optimal methods like the Genetic Algorithm are applied to improve the validness of K-Medoids but the time efficiency is not acceptable when dealing with growing data. The MapReduce model is utilized to handle with data of high volume which can’t adapt to some circumstances short of computer clusters. In order to improve the result validity and time efficiency of the algorithm, this paper revised the traditional K-Medoids algorithm of Partitioning Around Medoids (PAM) combining with the idea of the Simulate Anneal Arithmetic (SAA) and proposed a parallel Simulate Anneal Partitioning Around Medoids (SAPAM) algorithm which was implemented efficiently in Graphics Processing Units (GPUs). SAA algorithm is used to search for the initial medoids which promises the validness of the algorithm. The stochastic factor introduced in SAA algorithm gives the possibility of eliminating the local optima to attain the global optimal clustering results of PAM. To accelerate the clustering process, we design the parallel SAPAM algorithm to utilize quantities of GPU’s threads which execute the program at the same time. By analogy with the matrix multiplication, a new matrix computation method is defined to reduce the time consumption of data transfer between GPU’s global memory and shared memory. The matrix computation method reuses data in the shared memory of GPU and computes the distances between medoids and many points at a time which improve the algorithm’s performance evidently. To validate the proposed algorithm, we generated eight datasets with different attributes and sizes randomly and conducted experiments on the eight datasets to compare the proposed parallel SAPAM algorithm with the traditional PAM algorithm, sequential SAPAM algorithm and the parallel genetic K-Medoids algorithm. The experiment results showed that SAPAM algorithm attained more accurate clustering results compared with the traditional PAM and the parallel genetic K-Medoids algorithm. Besides, the proposed algorithm performed better than the sequential SAPAM algorithm and the parallel genetic K-Medoids algorithm in time efficiency. According to the results, our GPU-based SAPAM algorithm was four to eight times faster than the traditional PAM algorithm. The results demonstrate that the proposed method can execute efficiently and attain a valid result. Finally, SAPAM algorithm was applied to analyze the safety monitoring data of Guizhou province to get the clustering pattern of the safety threats. The clustering results show us several clusters of the safety threats which may provide some practical application value to the governor.
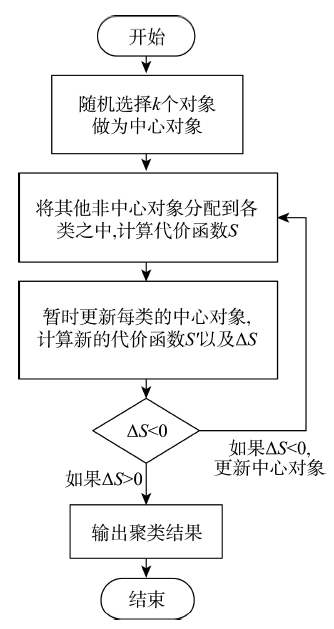
Fig. 1 Traditional PAM algorithm procedures图1 经典PAM算法流程 |
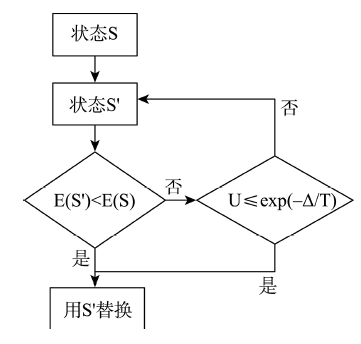
Fig. 2 Key procedures of SAA图2 模拟退火的关键步骤 |
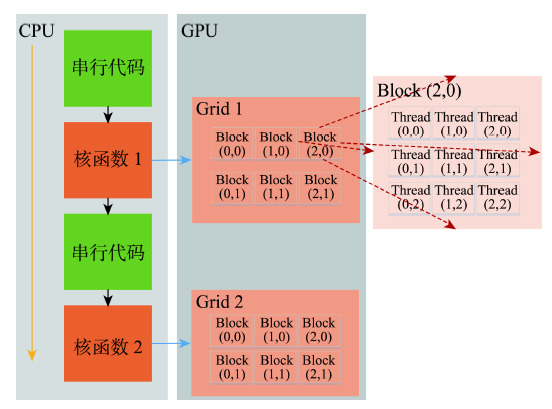
Fig. 3 The architecture of CUDA图3 CUDA的体系架构 |
Tab. 1 The proposed new algorithm表1 提出的新算法 |
| 步骤 | 过程 |
|---|---|
| 1 | 初始化初始温度T0,终止温度TE,状态温度TK,内层循环次数InnerLoop和冷却系数DecRate等参数 |
| 2 | 随机选取k个初始中心点,计算目标函数值F(k) |
| 3 | 设置循环变量MaxInnerLoop=0 |
| 4 | 计算每个对象和中心点之间的距离,将目标划入最近的类中并重新产生中心点 |
| 5 | 计算新的目标函数值F(k+1),如果F(k+1)<F(k),接受新状态,否则计算P=exp(-(F(k+1)-F(k))/TK),并产生一个0到1之间的随机数α,若P>α,接受新状态,否则拒绝新状态并且返回前一状态 |
| 6 | 如果MaxInnerLoop<InnerLoop,MaxInnerLoop加1并转到第4步,否则转向第7步 |
| 7 | 如果TK<TE,算法终止,输出结果,否则条令TK=TK×DecRate |
Tab. 2 The pseudocode which generates new medoids表2 产生新中心点的伪码 |
| 输入参数:待聚类的数据数组data,数据总数dataCount,老中心点数组oldCenter,新中心点数组newCenter,聚类数目clusterCount 输出参数:无 |
|---|
| void GetNewCenters(data, dataCount, oldCenter, newCenter, clusterCount){ 定义循环变量i; for (i = 0; i < clusterCount; i++){ do{ 产生一个0到dataCount之间的随机整数r; } while (第r个对象data[r]不在第i个老中心点oldCenter[i]所在的类,或者第r个 对象data[r]是中心点); newCenter[i] = data[r]; } } |
Tab. 3 The pseudocode which partitions the objects表3 对象划分的伪码 |
| 输入参数:待聚类的数据数组data,中心点数组centers,聚类结果数组result,数据总数dataCount,聚类数目clusterCount,数据字段数dimensionCount 输出参数:无 |
|---|
| __global__ void allocationKernel(data, centers, result, dataCount, clusterCount, dimensionCount){ 在共享内存中声明存储数据的数组da[]; 在共享内存中声明存储非中心点对象到各中心点的距离的数组dis[]; //对数据矩阵中每一行循环,blockIdx.x表示GPU中Block序号,NUM_BLOCKS表示定义的Block总数 for (int ij = blockIdx.x; ij < n; ij += NUM_BLOCKS){ //将矩阵中的每一行从全局内存中拷贝到共享内存中以重用数据,减少数据传输量 // threadIdx.x表示一个Block内的线程序号,blockDim.x表示一个Block中线程总数 for (int i = threadIdx.x; i < d; i += blockDim.x) da[i] = data[ij*d + i]; __syncthreads();//线程同步 //使用同一个block中的线程计算a⊕b for (int j = threadIdx.x; j < k; j += blockDim.x) calculate dis[j]; __syncthreads();//线程同步 使用每个Block中序号为1的线程计算对象分配结果; } } |
Tab. 4 The experimental computer environment表4 实验用计算机配置 |
| 参数 | 值 |
|---|---|
| CPU | Intel(R) Core(TM) i7-4710HQ CPU @2.50GHz(2501 MHz) |
| 内存 | 8G |
| GPU | NVIDIA GeForce GTX 860M |
| GPU 内存 | 4095 MB |
Fig. 4 The distribution of dataset 1 and clustering results图4 数据集1分布及聚类结果 |
Tab. 5 The five datasets used in the experiments表5 实验所用得5组数据集 |
| 数据集 | 对象数/个 | 字段数/个 | 聚类数目/个 |
|---|---|---|---|
| 1 | 10 000 | 5 | 4 |
| 2 | 20 000 | 5 | 3 |
| 3 | 20 000 | 5 | 4 |
| 4 | 50 000 | 5 | 4 |
| 5 | 100 000 | 5 | 6 |
| 6 | 100 000 | 5 | 4 |
| 7 | 200 000 | 5 | 5 |
| 8 | 200 000 | 5 | 4 |
Tab. 6 Clustering results comparison among traditional PAM, parallel GA K-Medoids and SAPAM表6 传统PAM、并行遗传K-Medoids和模拟退火PAM聚类结果比较 |
| 数据集 | 聚类结果平方误差 | ||
|---|---|---|---|
| 传统PAM | 并行遗传K-Medoids | 模拟退火PAM | |
| 1 | 2.09529E+07 | 1.77726E+07 | 1.74360E+07 |
| 2 | 3.69280E+07 | 3.24828E+07 | 3.24792E+07 |
| 3 | 6.27123E+07 | 3.29482E+07 | 3.27136E+07 |
| 4 | 9.01593E+07 | 8.59827E+07 | 8.40918E+07 |
| 5 | 2.61621E+08 | 1.97264E+08 | 1.99169E+08 |
| 6 | 4.19342E+08 | 2.70153E+08 | 2.69891E+08 |
| 7 | 1.10902E+09 | 7.21299E+08 | 7.22798E+08 |
| 8 | 1.01737E+09 | 8.89928E+08 | 8.83764E+08 |
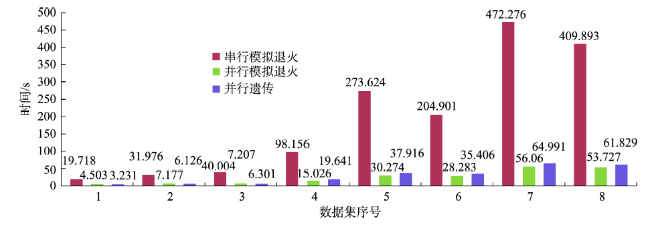
Fig. 5 The comparison of the result图5 实验结果比较 |
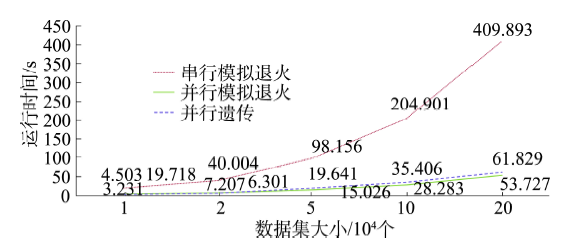
Fig. 6 The curve of time-dataset size图6 时间-数据集大小曲线 |
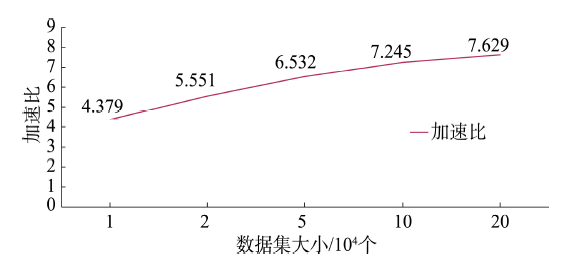
Fig. 7 The curve of speedup ratio-dataset size图7 加速比-数据集大小曲线 |
Tab. 7 The safety threats data of Guizhou province between 2010 and 2016 (only part fields)表7 贵州省2010年至2016年安全隐患数据(部分字段) |
| ID | lng | lat | 隐患地点 | 隐患级别 | 隐患描述 |
|---|---|---|---|---|---|
| 0 | 106.11130770827423 | 27.10817188123285 | 永贵能源开发有限责任公司黔西县甘棠镇新田煤矿 | 1 | 1402回风顺槽工作面前探支护使用不可靠(前探梁使用单环,且其上部未用背板铺设严实) |
| 1 | 105.3180498760137 | 27.487599915062724 | 毕节市七星关区对坡镇先明煤矿 | 1 | 井底水仓温度传感器未送有资质部门进行安全性能校检 |
| 2 | 107.48110251895538 | 27.077516930920083 | 瓮安县成功磷化有限公司 | 1 | 现场职业危害告知卡破损,未及时更新 |
| … | … | ... | … | … | … |
| 30046 | 105.27592194191595 | 26.154829632942278 | 贵州路鑫喜义工矿股份有限公司六枝特区中寨乡凸山田煤矿 | 1 | 顶板管理 |
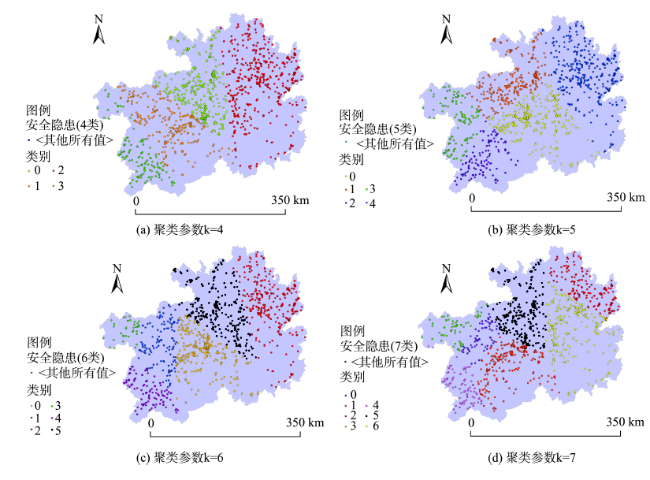
Fig. 8 The clustering result of safety threats data of Guizhou Province图8 贵州省安全隐患数据不同类别数的聚类结果 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
|
| [15] |
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
[
|
| [20] |
|
| [21] |
[
|
| [22] |
[
|
| [23] |
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}