
手机用户上网时段的混合Markov预测方法
作者简介:方志祥(1977-),男,教授,主要从事时空行为建模、导航与位置服务研究。E-mail: zxfang@whu.edu.cn
收稿日期: 2017-03-23
要求修回日期: 2017-06-23
网络出版日期: 2017-08-20
基金资助
国家自然科学基金项目(41231171、41371420)
湖北省青年英才开发计划
武汉大学自主科研项目拔尖创新人才类资助项目(2042015KF0167)
A mixed Markov Method to Predict the Surfing Time Period of Mobile Phone Users
Received date: 2017-03-23
Request revised date: 2017-06-23
Online published: 2017-08-20
Copyright
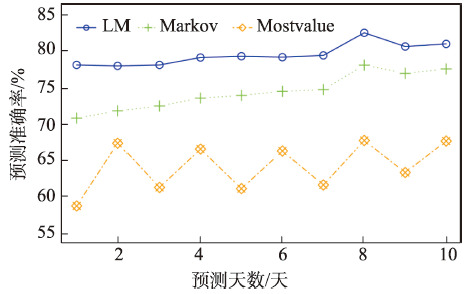
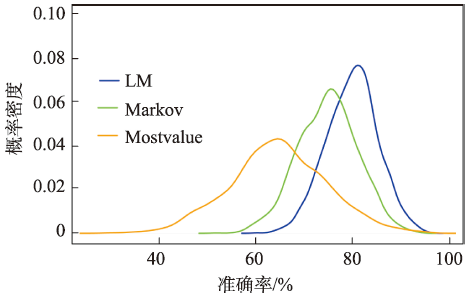
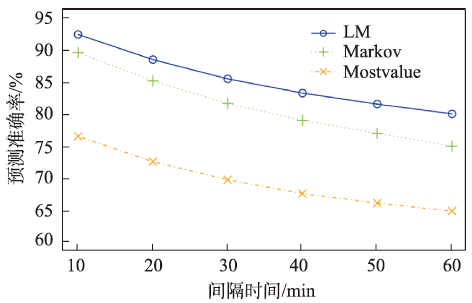
手机用户上网时段研究与预测对手机用户行为与模式分析、网络服务内容设计、网络黏性与心理、移动互联商业智能等具有重要意义。本文结合Markov模型和关联规则模型,提出一种手机用户上网时段的混合Markov预测方法——Lift-Markov(LM)方法,并采用中国某城市4G手机用户流量上网产生的流量收费数据进行实验验证与分析。研究发现:该实验区域37.66%的手机用户个体存在明显的以天为周期的周期性特性;本文所提出的LM方法在10、20、30、40、50、60 min间隔时的平均预测准确率都优于Markov模型和Mostvalue模型,其中在60 min间隔时能达到79.75%的平均准确率,优于Markov模型(74.64%)和Mostvalue模型(64.44%);LM方法的预测准确率分布相比于其他2种模型都要窄,而且密度分布峰值最高、标准差最小,说明本文方法对人群的上网时段预测准确率较为集中与稳定,具有较好的预测性能。
关键词: 手机上网数据; 手机上网行为; 上网时间特征; 时段预测; 混合Markov方法
方志祥 , 于冲 , 张韬 , 冯明翔 , 倪雅倩 . 手机用户上网时段的混合Markov预测方法[J]. 地球信息科学学报, 2017 , 19(8) : 1019 -1025 . DOI: 10.3724/SP.J.1047.2017.01019
In recent years, big data of mobile phones has become a great data source for researches and applications. It has been widely used to understand the human behaviors in cyberspace space. Researching and forecasting the surfing time of mobile phone users have great significance for analyzing mobile phone users’ behaviors and patterns, designing network service, and understanding the relationship of surfing behaviors, website stickiness, users’ psychology, mobile Internet intelligent business. We proposed a mixed Markov method (Lift-Markov method. LM), combining the traditional Markov model and association rule model, to predict the surfing time period of mobile phone users. A dataset of surfing records of 4G mobile phone users collected by Hubei Mobile within twenty days is used to demonstrate the capability of predicting web-surfing time periods of users. LM method has a better prediction accuracy when it is compared with the traditional Markov model and the Most-value model. There are two main findings here: the first one is that there is obvious periodicity in surfing time periods of 37.66% mobile phone users in experimental area by Fourier transformation and periodic tests, which could help us understand the surfing characteristics of users. Also, the second one is that the average accuracy of our proposed method is better than the Markov model and the Most-value model in 10 minutes, 20 minutes, 30 minutes, 40 minutes, 50 minutes and 60 minutes intervals. LM method can perform an average accuracy of 79.75% in predicting web-surfing time on a scale of 60 minutes, better than the Markov model (74.64%) and the Most-value model (64.44%). Compared with the other two models, the accuracy distribution of the LM method is narrower, the peak value is higher, and the standard deviation is smaller, which means that the prediction accuracy of the LM method is more concentrated and stable, with good predictive performance.
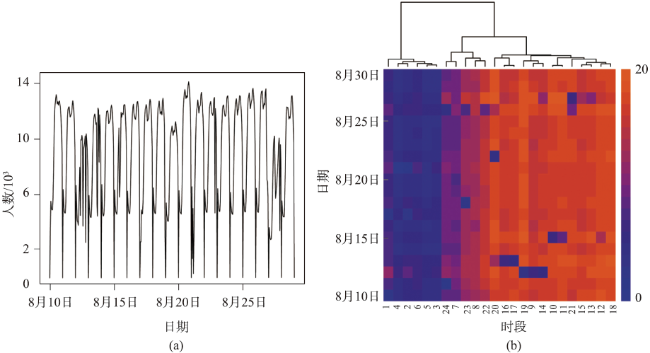
Fig. 1 The temporal features of surfing by smart phone users图1 用户手机上网时段分布特征 |
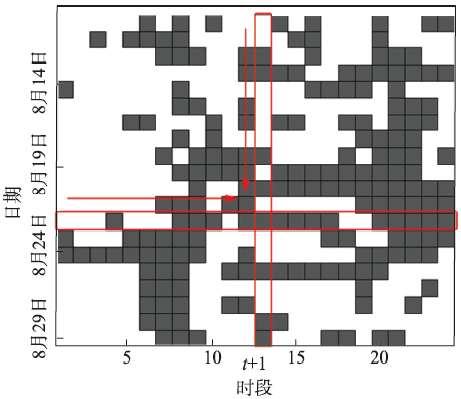
Fig. 2 The image of users′ surfing status图2 用户上网状态示意图 |
Tab. 1 Accuracy of LM method in different threshold values表1 LM方法在不同阈值下的准确率 |
| 最小支持度阈值 | 最小置信度阈值 | ||||
|---|---|---|---|---|---|
| 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | |
| 0.3 0.4 0.5 0.6 | 79.61 79.67 79.69 79.70 | 79.62 79.67 79.71 79.70 | 79.63 79.67 79.70 79.70 | 79.60 79.64 79.68 79.68 | 79.59 79.63 79.66 79.67 |
Fig. 3 Comparison results of three methods for 10 testing days图3 3种方法在10 天内的准确率对比结果 |
Fig. 4 Accuracy distribution of three methods图4 3种方法的预测准率分布 |
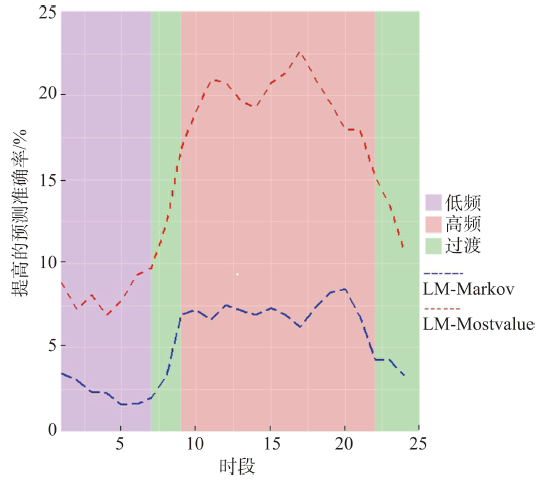
Fig. 5 Increased accuracy of the proposed method in three kinds of time periods, such as high-frequency, low-frequency and transition periods.图5 高频时期、低频时期和过渡时期时本文方法的准确率提升幅度 |
Fig. 6 Comparison results of average prediction correction in different intervals图6 不同间隔时间时3种方法的平均预测准确率对比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
[
|
| [13] |
|
| [14] |
|
| [15] |
[
|
| [16] |
[
|
| [17] |
|
| [18] |
[
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
Schuster, Arthur.On the investigation of hidden periodicities with application to a supposed 26 day period of meteorological phenomena[J]. Terrestrial Magnetism, 2007,3(1):13-41.
|
| [26] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}