
基于贝叶斯机器学习的生态模型参数优化方法研究
作者简介:何立杰(1992-),女,硕士生,研究方向为计算机科学与技术。E-mail: 1129123670@qq.com
收稿日期: 2017-04-14
要求修回日期: 2017-07-26
网络出版日期: 2017-10-20
基金资助
国家重点研发计划(2016YFC0500204)
国家自然科学基金项目(31501217、41571424)
辽宁省科学技术计划项目(2014201001)
Parameters Optimization Method of Ecosystem Model Based on Bayesian Machine Learning
Received date: 2017-04-14
Request revised date: 2017-07-26
Online published: 2017-10-20
Copyright
参数优化方法是准确估计生态模型参数、降低其不确定性的有效手段。本文提出一种基于贝叶斯机器学习的No-U-Turn Sampler(NUTS)生态模型参数优化方法。NUTS是一种高效的参数优化方法,每次取样中利用递归算法生成候选参数集(二叉树)推断参数的后验信息,如果满足约束条件“非U型回转”,不断构建子树更新参数;否则,记录本次抽样的“最优”参数集,并开始下一次取样,直到获取足够样本。该算法在每次取样中充分优化参数,避免因随机游走行为产生冗余抽样,提高了参数优化效率。本文以千烟洲亚热带人工针叶林碳通量模拟为例,基于Pymc3框架利用NUTS参数优化方法实现了碳通量(Net Ecosystem Exchange,NEE)模型参数反演,并与Metropolis-Hastings(MH)方法进行对比。结果表明,本文算法的参数值达到稳定波动时的抽样次数减少了85%左右,参数优化效率提升3倍左右。参数优化后,2种NEE模型中7个参数不确定性降低10%~53%。此外,NEE模拟效果明显提升,模拟值与实测值的R2分别提高23%和17%,RMSE分别降低3%和4%。综上所述,本文提出的参数优化方法对生态领域的参数估计或数据同化工作具有一定的借鉴意义。
何立杰 , 何洪林 , 任小丽 , 葛蓉 , 杨涛 , 朱超 . 基于贝叶斯机器学习的生态模型参数优化方法研究[J]. 地球信息科学学报, 2017 , 19(10) : 1270 -1278 . DOI: 10.3724/SP.J.1047.2017.01270
Parameter optimization is an effective means for the accurate estimation of ecosystem model parameters and the reduction of the uncertainty in model predictions. We proposed a method for parameter optimization of the ecosystem model, which is based on the Bayesian machine learning and called No-U-Turn-Sampler (NUTS). As an efficient means of parameter optimization, NUTS uses a recursive algorithm to build a set of candidate points to obtain the posterior information of the parameters. If the constraint condition of “Non-U-Turn” is met, subtrees will be built to update parameters. Otherwise, “the optimal” set of parameters from current sample will be recorded, and then the next sampling begin to run until enough samples are taken. This algorithm avoids sampling redundancy caused by random walk and thus improves the efficiency of parameter optimization. Taking the carbon flux simulations of the Qianyanzhou subtropical coniferous plantation as an example, we implemented the parameter inversion of the carbon flux (Net Ecosystem Exchange, NEE) model using the NUTS method based on the Pymc3 framework. The comparison between the inversion results of NUTS and Metropolis-Hastings (MH) shows that the sampling frequency reduces about 85%, and the optimization efficiency increases about 3 times when the parameter values of the NUTS algorithm reaches convergence. The uncertainties of the seven parameters estimated by NUTS in the two NEE models are reduced by 10%-53% compared to MH. The NEE simulation improved significantly, with the R2 between the simulated values and the observed values increased by 23% and 17%, respectively and the RMSE decreased by 3% and 4%, respectively. In sum, the NUTS parameter optimization method proposed in this paper provides an efficient approach for the parameter optimization in ecosystem modeling.
Key words: NUTS; ecosystem model; parameter optimization; MCMC; Pymc3
Fig.1 The process of updating a likely candidate sets during sampling图1 一次取样中参数集更新的过程 |
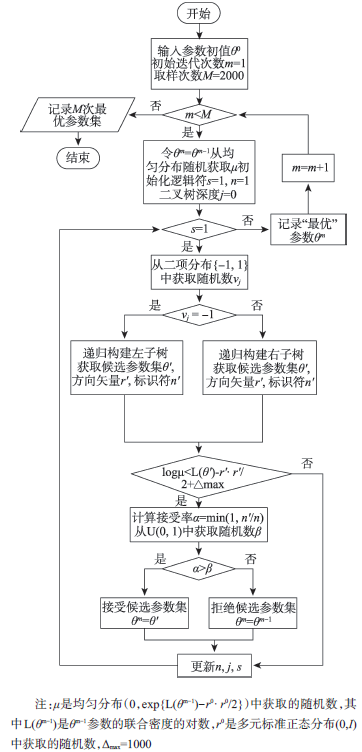
Fig. 2 Flow chart of NUTS parameter optimization method图2 NUTS参数优化方法流程图 |
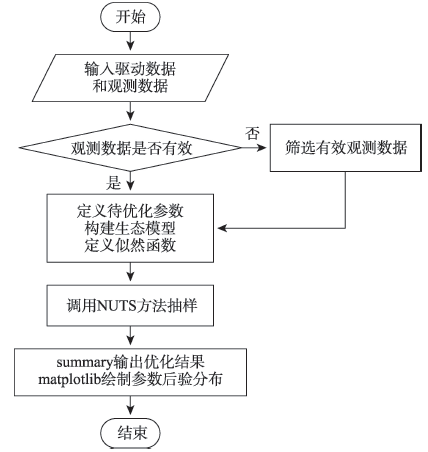
Fig. 3 Flow chart of NUTS parameter optimization process图3 参数优化过程流程图 |
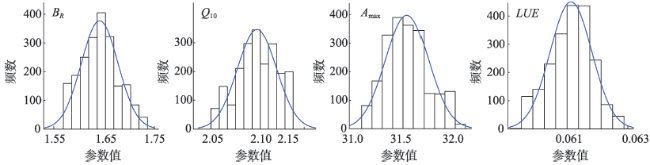
Fig. 4 Parameter posterior distribution of the model LM图4 LM模型的参数后验分布 |
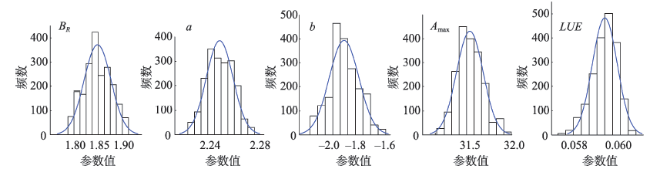
Fig. 5 Parameter posterior distribution of the model QM图5 QM模型的参数后验分布 |
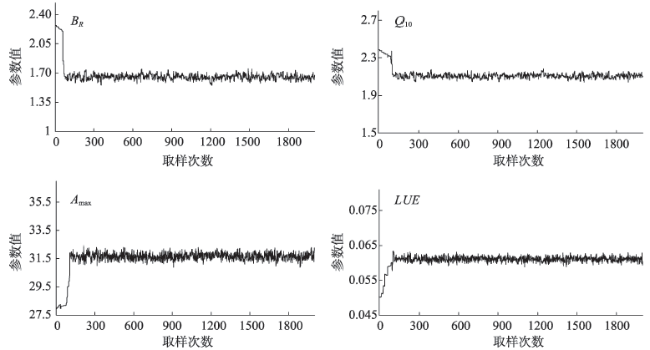
Fig. 6 Parameters trajectory of the NUTS algorithm图6 NUTS算法优化的参数轨迹 |
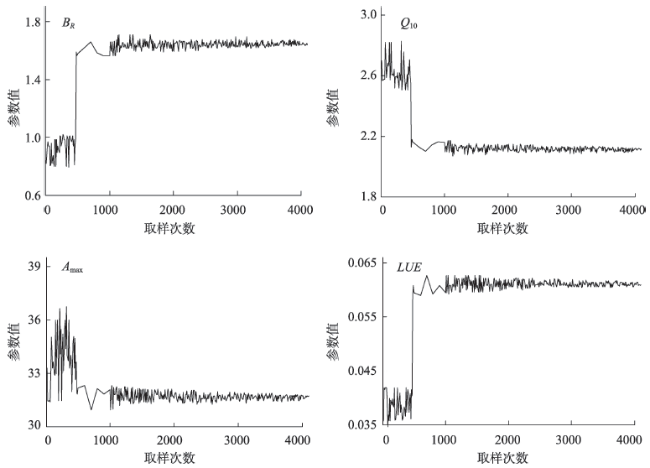
Fig. 7 Parameter trajectory of the Metropolis-Hastings algorithm图7 MH算法优化的参数轨迹 |
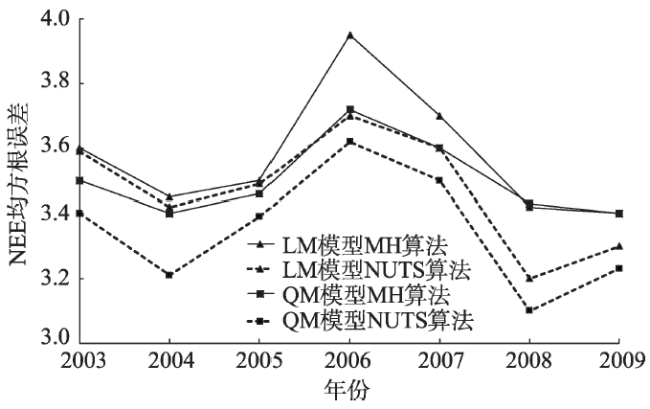
Fig. 8 Comparison of RMSE of half-hourly modeled NEE from the two models and observed NEE at QYZ under different algorithms图8 不同算法的NEE模拟值与实测RMSE逐年对比图 |
Tab.1 Parameter uncertainty analysis表1 参数不确定性分析 |
| 参数 | 先验值 | LM模型后验值 | QM模型后验值 | |||
|---|---|---|---|---|---|---|
| 本文算法 | 文献[19]算法 | 本文算法 | 文献[19]算法 | |||
| BR | [0.25,10] | 1.65±0.02 | 1.67±0.04 | 1.84±0.03 | 1.84±0.05 | |
| Q10 | [1,3.5] | 2.11±0.02 | 2.1±0.04 | |||
| a | [1,10] | 2.24±0.02 | 2.22±0.03 | |||
| b | [-10,10] | -1.95±0.09 | -1.96 ± 0.11 | |||
| Amax | [5,50] | 31.5±0.20 | 31.0±0.37 | 31.6±0.27 | 29.13±0.30 | |
| LUE | [0.001,0.1] | 0.061±0.00 | 0.061±0.00 | 0.060±0.00 | 0.060±0.00 | |
Tab. 2 R2 and RMSE comparison of different parameters optimization algorithms表2 不同参数优化算法的R2和RMSE对比情况 |
| 判断指标 | LM模型 | QM模型 | |||
|---|---|---|---|---|---|
| 本文NUTS算法 | 文献[19]MH算法 | 本文NUTS算法 | 文献[19]MH算法 | ||
| R2 | 0.80 | 0.65 | 0.81 | 0.69 | |
| RMSE/(umol/m2) | 3.47 | 3.57 | 3.35 | 3.50 | |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
[
|
| [7] |
|
| [8] |
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
|
| [21] |
[
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
[
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
[
|
| [31] |
[ Li C, He H L, Liu M, et al. CO2 flux data processing system of ChinaFLUX and its application[J]. Journal of Geo-information Science, 2008,10(5): 557-565. ]
|
| [32] |
|
| [33] |
|
| [34] |
[
|
| [35] |
|
| [36] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}