
主题模型与SVM组合的小尺度街区用地分类方法
作者简介:文聪聪(1994-),男,博士生,主要从事智慧城市、数据挖掘等研究。E-mail: giserwcc@126.com
收稿日期: 2017-05-23
要求修回日期: 2017-11-12
网络出版日期: 2018-03-02
基金资助
国家科技支撑计划项目课题 (2015BAJ02B00)
Topic Model Combined with the SVM for Small Scale Land Use Classification
Received date: 2017-05-23
Request revised date: 2017-11-12
Online published: 2018-03-02
Supported by
[ Foundation item: National Science and Technology Support Program, No.2015BAJ02B00
Copyright
城市用地分类作为城市规划重要的基础和依据,对城市资源配置、建设发展等具有重要意义。现有研究对用地分类都聚焦于“稀路网、大街区”的大尺度区域,随着城市发展,大尺度区域的规划模式造成了城市交通效率低下、土地低效率开发等问题,而小尺度的城市街区建设规划为解决上述问题提供了一种新的思路。为了充分挖掘现有交通大数据的潜在价值,更以高效地服务小尺度街区规划,本文将主题模型与支持向量机(SVM)相组合,提出一种面向小尺度街区的用地分类方法。本文以上海市黄浦区人民广场附近为研究区域,依据精细路网对研究区域划分,通过对一周(7天)出租车GPS数据处理,结合区域兴趣点(POI)数据,基于隐含狄利克雷分布(LDA)模型和SVM模型进行用地分类。在人工解译的分类图的基础上对本文方法进行精度评价,并基于百度地图地理数据进行结果验证。研究表明本文方法基于现有的交通大数据,实现了对小尺度街区用地分类,方法分类精度较高,在一定程度上可以节约人力物力,以便更好地服务于小尺度城市规划。
文聪聪 , 彭玲 , 杨丽娜 , 池天河 . 主题模型与SVM组合的小尺度街区用地分类方法[J]. 地球信息科学学报, 2018 , 20(2) : 167 -175 . DOI: 10.12082/dqxxkx.2018.170233
Urban land classification is the foundation of urban planning, whose result is of great significance to the allocation of urban resources and the development of urban construction. Previous researches of urban land classification are mainly focused on the study of macro-scale areas, which is characterized by “sparse road network and large block system”. However, with the development of cities, the planning model featured by macro-scale area has caused problems such as the low efficiency of urban traffic and land development. To solve these problems, the construction of urban blocks with small scales was put forward. To make full use of the potential value of the current big data of traffic in the block planning with small scales, this paper presents a land classification method for blocks with small scales through combining the topic modeling and support vector machine (SVM). The regions near People's Square of Huangpu District in Shanghai was taken as the study area. We firstly divided the study area according to fine road network, and then formed a regional mobility pattern through processing the data on the GPS of taxis in one week. By using the data on points of interest (POI), the model of Latent Dirichlet Allocation (LDA) and SVM model, the land use classes are identified. Accuracy assessment of the proposed method has been made based on classification map visually interpreted, and the obtained result has been approved by the geographic data of Baidu Map. The results indicated that this method enables the possibility of the land classification of small-scaled blocks, and could achieve high classification accuracy by utilizing the big data of traffic.
Key words: topic model; land use classification; float car; small scale; POI; SVM
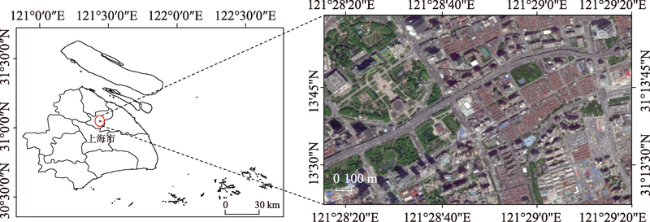
Fig. 1 Location of the study area图1 研究区域位置 |
Tab. 1 Data specification表1 研究数据说明 |
| 数据 | 年份 | 数量 | 详细说明 |
|---|---|---|---|
| 上海市区划图 | 2015 | 从区划图中选取黄浦区人民广场附近为研究区域 | |
| 研究区域路网数据/条 | 2015 | 508 | 从上海市全部路网中提取研究区域内的路网,道路类别有一级道路、二级道路、三级道路等13类 |
| 研究区域内POI数据/个 | 2015 | 4716 | 从上海市全部POI数据中提取研究区域内的POI,共有交通设施、体育休闲、公司企业等19个类别 |
| 研究区域内出租车轨迹数据/万条 | 2015 | 734 | 从上海市全部出租车轨迹数据中提取研究区域内的轨迹数据 |
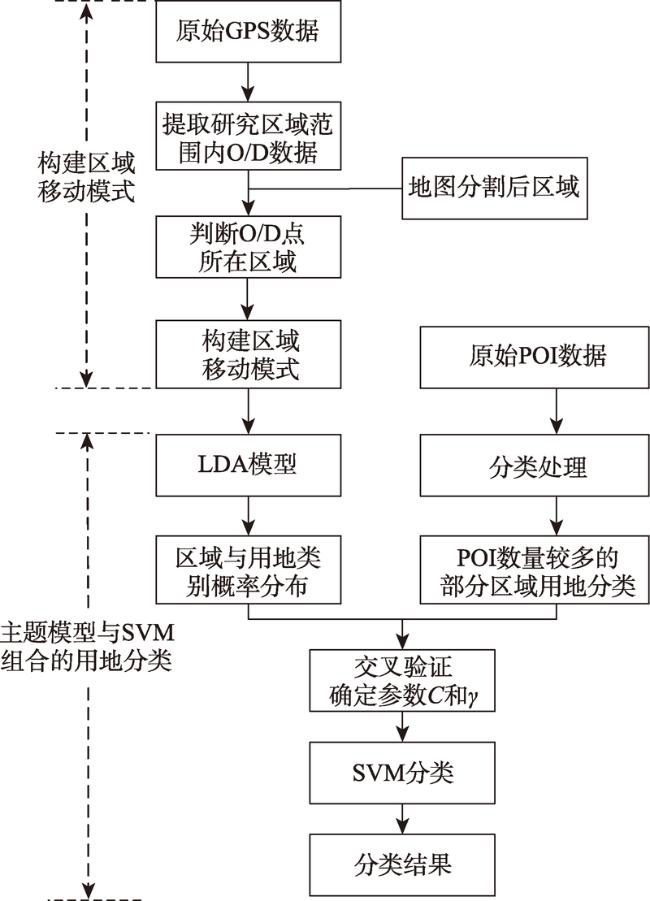
Fig. 2 The basic framework of the method in this study图2 本文方法的基本框架 |
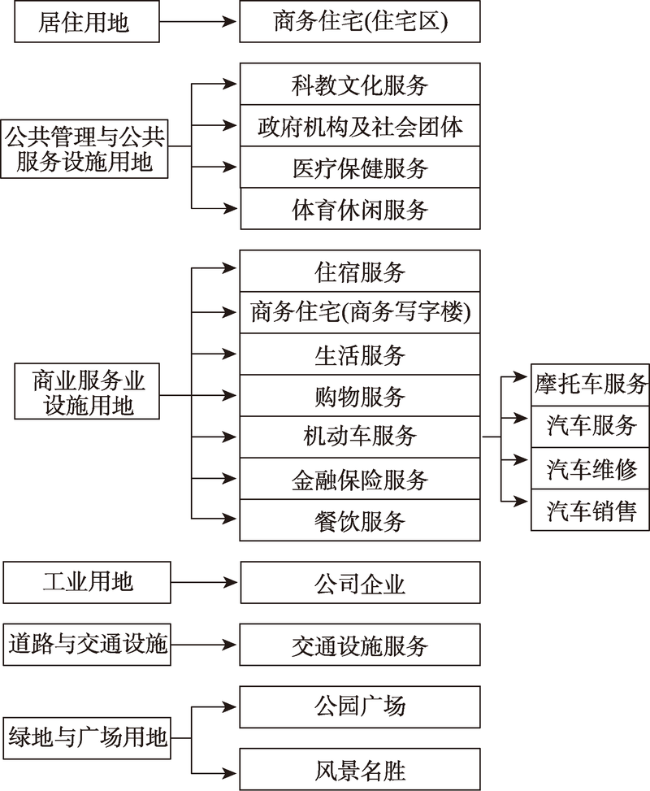
Fig. 3 POI data classification图3 POI数据分类图 |
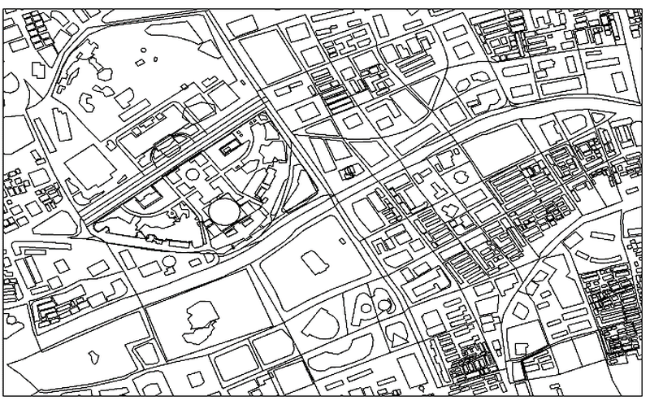
Fig. 4 Regional segmentation图4 区域分割效果图 |
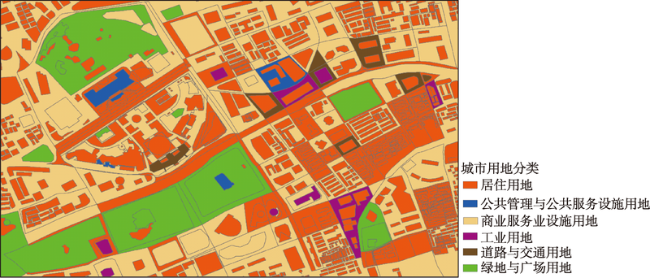
Fig. 5 Supervised classification results of SVM by the LDA model图5 LDA模型SVM监督分类结果 |
Tab. 2 The confusion matrix of the method proposed in this study表2 本文方法混淆矩阵 |
| 方法结果 | 解译结果 | ||||||
|---|---|---|---|---|---|---|---|
| 居住用地 | 公共管理与公共服务设施用地 | 商业服务设施用地 | 工业用地 | 道路与交通用地 | 绿地与广场用地 | 总计 | |
| 居住用地 | 822 | 10 | 8 | 9 | 20 | 136 | 1005 |
| 公共管理与公共服务设施用地 | 1 | 3 | 0 | 0 | 0 | 3 | 7 |
| 商业服务设施用地 | 1 | 3 | 62 | 1 | 2 | 17 | 86 |
| 工业用地 | 1 | 2 | 6 | 1 | 0 | 0 | 10 |
| 道路与交通用地 | 0 | 0 | 0 | 0 | 8 | 2 | 10 |
| 绿地与广场用地 | 2 | 0 | 0 | 4 | 1 | 32 | 39 |
| 总计 | 827 | 18 | 76 | 15 | 31 | 190 | 1157 |
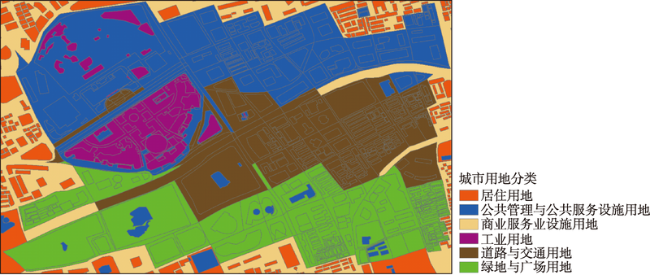
Fig. 6 A general method of the unsupervised classification results图6 常规方法非监督分类结果 |
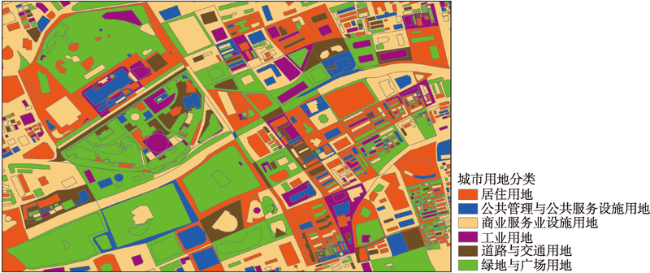
Fig. 7 The unsupervised classification results of K-Means by the LDA model图7 LDA模型K-Means非监督分类结果 |
Tab. 3 The accuracy comparison of the experimental results表3 方法精度对比 |
| 方法 | 总体精度 | Kappa系数 |
|---|---|---|
| 常规特征非监督分类方法 | 0.298185 | 0.125381 |
| LDA模型非监督分类方法 | 0.413654 | 0.251723 |
| 本文方法 | 0.802074 | 0.462550 |
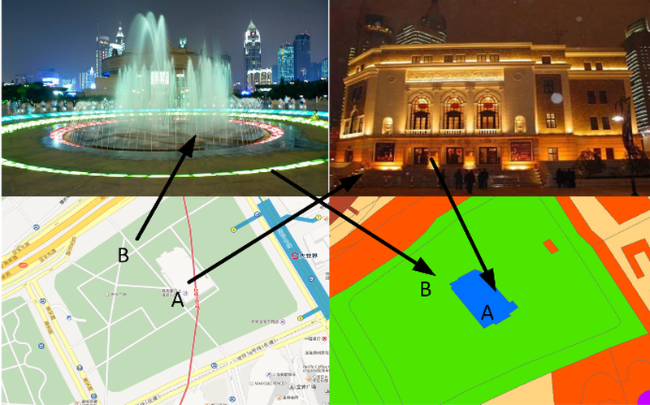
Fig. 8 Regional verification of Shanghai Music Hall (A point) and music square (B point)图8 上海音乐厅(A点)及音乐广场(B点)区域验证 |
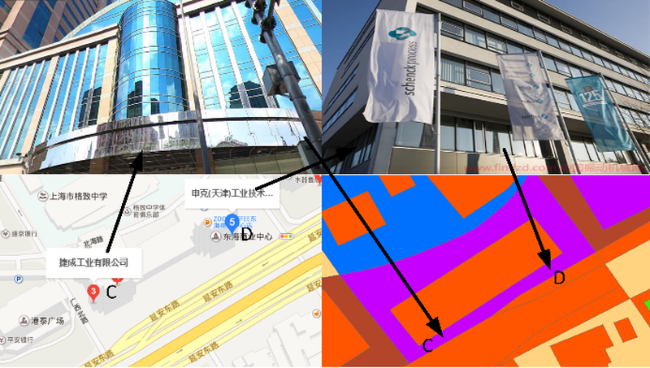
Fig. 9 Regional verification of an industrial company limited (C point) and an industrial technology company limited (D point)图9 某工业有限公司(C点)及某工业技术有限公司(D点)区域验证 |
Fig. 10 Regional verification of the Oceanic Building underground parking garage (E point)图10 海洋大厦地下停车场库(E点)区域验证 |
Fig. 11 Regional verification of Taiyuan street shops and other commercial shops around the corner (F point) and a residential building (G point)图11 太原坊三街周围商店等商业店(F点)及居民楼(G点)区域验证 |
Fig. 12 Regional verification of Duxingli surrounding areas图12 笃行里小区周边地区区域验证 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
|
| [4] |
|
| [5] |
[
|
| [6] |
|
| [7] |
[
|
| [8] |
[
|
| [9] |
|
| [10] |
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
|
| [15] |
[
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
[
|
| [21] |
[
|
| [22] |
|
| [23] |
[
|
| [24] |
|
| [25] |
|
| [26] |
[
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}