
基于自动回标的地理实体关系语料库构建方法
作者简介: 王姬卜(1993-),女,山西临汾人,硕士生,主要从事地理信息工程研究。E-mail: 418771916@qq.com
收稿日期: 2018-01-04
要求修回日期: 2018-03-28
网络出版日期: 2018-07-13
基金资助
国家自然科学基金重点项目(41631177);数字福建建设项目(闽发改网数字函[2014]191 号、[2016]23 号、[2016]77号);福建省科技创新平台项目(2015H2001)
Constructing the Corpus of Geographical Entity Relations Based on Automatic Annotation
Received date: 2018-01-04
Request revised date: 2018-03-28
Online published: 2018-07-13
Supported by
National Natural Science Foundation of China, No.41631177; Digital Fujian Construction Project, No.[2014]191, [2016]23, [2016]77; Fujian Science and Technology Innovation Platform Project, No.2015H2001
Copyright
地理实体关系语料库是地理信息获取与地理知识服务的基础数据资源,其规模直接影响机器学习模型训练的效果。快速更新的网络文本不断涌现新的关系实例,要求语料库及时更新以覆盖更丰富的关系实例。手工构建和更新语料库成本高昂,亟需一种快速构建大规模地理实体关系语料库的方法。本文提出一种基于回标技术的地理实体关系语料库构建方法。首先,参考地理实体分类标准与语义关系、空间关系分类标准,针对地理实体关系的自然语言描述习惯,建立地理实体关系的标注体系;然后,结合精确匹配与模糊匹配策略,提高客体匹配的覆盖率;接着,基于优序图法建立句子打分规则,实现种子三元组到句子映射的定量评价;最后,使用中文百度百科文本验证方法的有效性。实验结果显示,本文方法平均回标成功率为67.83%,关系标注的准确率为76.36%。相比人工构建空间关系标注语料库的过程,本文提出的语料自动构建方法,标注速度快,规模大,为自动扩充标注语料库提出了可行方案。同时,该方法兼顾了地理实体间的语义关系和空间关系,且关系类型不受限,可用于开放式关系抽取任务。
王姬卜 , 陆锋 , 吴升 , 余丽 . 基于自动回标的地理实体关系语料库构建方法[J]. 地球信息科学学报, 2018 , 20(7) : 871 -879 . DOI: 10.12082/dqxxkx.2018.180032
The corpus of geographical entity relations is the basic data resource of geographical information acquisition and geographical knowledge services, and its scale directly affects the training effect of machine learning models. Fast-updated web text is constantly emerging as a new relational example, requiring the corpus to be updated in a timely manner to cover richer relational instances. Manually constructing and updating corpus are expensive. Therefore, it needs a more efficient technology of corpus construction for massive geographical entity relations. In this paper, we propose an efficient method of corpus construction for massive geographical entity relations through the automatic annotation technique. First of all, based on encyclopedia resources, referring geographical entity classification standard and semantic relation, spatial relation classification standard to establish an annotation scheme of geographical relation, which considers both the linguistic habits of natural language and the annotation normalization. Secondly, we combine the fully-matching with the approximate matching to improve the coverage rate of object entity finding. Thirdly, we define the rules of sentence scoring by using the optimal sequence diagram method, as well as quantitatively evaluate the results of mapping the seed triples to the sentences. Finally, a series of experiments based on the Chinese BaiduBaike are carried out, which is used to verify the effectiveness of the improved automatic annotation. The results show that, the average success rate of the automatic annotation is 67.83%, and the average accuracy of the annotated relations by our method is 76.36%. Comparing with the manually annotated corpus of the spatial relations, the proposed method constructed a large-scale corpus of geographical entity relations more efficiently, which provides a feasible scheme for expending geographical entity relations corpus automatic. Experimental results on self-built corpus by LSTM (Long Short Term Memory) network shows that the accuracy of geographical relation extracting from web texts is 73.2%, and the accuracy of relative corpora is 75.2%, which proofs that the corpus of geographical entity relations is available. At the same time, this method takes into account the semantic relationship and spatial relationship between geographical entities, and it can be used for open relation extraction task. Besides, the relation types are not limited, which can be applied to open relation extraction.
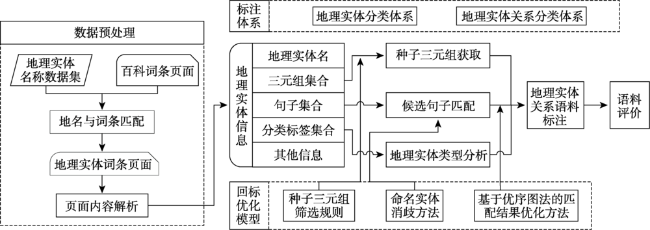
Fig. 1 Process of automatic constructing corpus图1 语料库自动构建流程 |
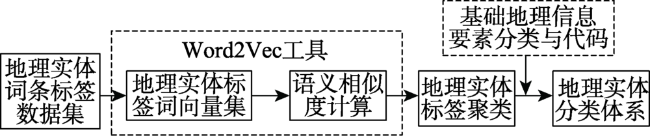
Fig. 2 Classification system construction of geographic entity图2 地理实体分类体系构建流程 |
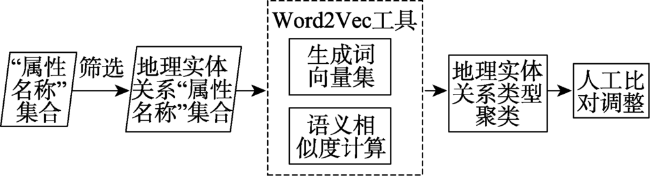
Fig. 3 Classification system construction of geographical relationship图3 地理实体关系分类体系构建流程 |
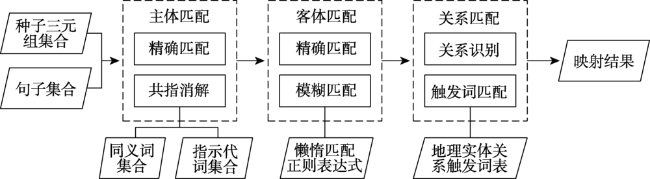
Fig. 4 Quality evaluation for the automatically constructed corpus of geographical entity relations图4 地理实体关系映射过程 |
Tab. 1 Classification of geographic entity表1 地理实体分类 |
| 大类 | 项数 | 小类 |
|---|---|---|
| 地形地貌 | 35 | 大洋、海域、海湾、海峡、海滩、岛、礁、半岛、河流、湖泊、沼泽、运河、河口、水渠、瀑布、三角洲、滩涂、泉、温泉、冰川、冰盖、冰原、冰山、火山、大洲、山脉、山峰、山谷、悬崖、盆地、沙漠、荒漠、峡谷、丘陵、高原 |
| 建筑设施 | 36 | 自然保护区、风景名胜区、公园、公路、铁路、地铁、桥梁、汽车站、火车站、机场、港口、水库、水电站、核电站、工厂、体育场馆、展览馆、博物馆、图书馆、档案馆、电影院、剧院、美术馆、游乐场、城堡、宫殿、遗址、遗迹、陵墓、清真寺、教堂、寺庙、道观、广场、摩天大楼、大型雕塑 |
| 行政区划 | 11 | 国家、首都、外国行政区、外国城市、省级行政区、地级行政区、县级行政区、乡级行政区、村级行政区、城市群、城市 |
| 组织机构 | 12 | 企业、教育机构、医疗机构、研究机构、宗教组织、体育组织、演艺团体、行业协会、管理机构、政党、经济组织、政治组织 |
Tab. 2 Classification of geographic relationship表2 地理实体关系分类 |
| 关系分类 | 关系名称 | 属性名称 | |||
|---|---|---|---|---|---|
| 项数 | 内 容 | 项数 | 内 容 | ||
| 空间关系 | 80 | 地理位置、地理区域、包含景点、包含高校、临近火车站、途经城市、过境公路、流经地区、连接城市、源头、所属城市、临近机场等 | 230 | 地理位置、位于、注入、主要景区、所属国家、途经、流经地区、所属山系 | |
| 等同关系 | 8 | 中文名、全名、别名、简称、原名、誉名、外文名、译名 | 43 | 别称、别名、古称、美称、医院原名、公司简称、法语名称 | |
| 等级关系 | 6 | 隶属、归属、下辖、分支机构、包含、组成 | 34 | 下辖地区、所属联盟、隶属单位、隶属、所属 公司、所属教会 | |
| 事件关系 | 11 | 搬迁、创立、筹建、设计、建造、施工、运营、合作、管理、勘探、批准 | 30 | 筹建、筹建单位、开发商、待建路段、搬迁、管理单位、批准单位、建造者、运营单位 | |
| 合计 | 105 | 337 | |||
Tab. 3 Feasibility analysis for data source of geographic entry from Baidu Encyclopedia表3 百度百科地理实体词条数据源可用性分析 |
| 分类 | 词条数 | 信息框数 | 含种子三元组的词条数 | 种子三元组数 | 关系种类数 | 句子数 |
|---|---|---|---|---|---|---|
| 地形地貌 | 30 | 24 | 19 | 91 | 27 | 1346 |
| 行政区划 | 126 | 107 | 91 | 364 | 33 | 4056 |
| 建筑设施 | 124 | 106 | 75 | 251 | 46 | 2287 |
| 组织机构 | 635 | 534 | 447 | 1075 | 52 | 11 753 |
| 总计 | 915 | 771 | 632 | 1781 | 91 | 19 442 |
Fig. 5 Sample of explicit annotation result图5 显式标注结果示例 |
Fig. 6 Sample of implicit annotation result图6 隐式标注结果示例 |
Tab. 4 Quality evaluation for the automatically constructed GRE corpus表4 自动构建的地理实体关系语料库的质量评价 |
| 统计项 | 河流 | 山脉 | 地标建筑 | 道路 | 中国行政区划 | 外国行政区划 |
|---|---|---|---|---|---|---|
| 种子三元组数 | 1386 | 1404 | 934 | 2921 | 8080 | 4038 |
| 标注的句子数 | 1024 | 986 | 587 | 2147 | 6059 | 3161 |
| 标注的关系类型数 | 50 | 61 | 54 | 80 | 52 | 46 |
| 显式标注的句子数 | 776 | 696 | 345 | 1024 | 3896 | 2119 |
| 成功率/% | 73.90 | 70.22 | 62.82 | 73.51 | 74.98 | 78.29 |
| 准确率/% | 91 | 61 | 86 | 67 | 62 | 72 |
| 统计项 | 自然保护区 | 企业 | 教育机构 | 医疗机构 | 博物馆 | 总计 |
| 种子三元组数 | 457 | 774 | 1922 | 248 | 641 | 22 805 |
| 标注的句子数 | 317 | 398 | 349 | 94 | 347 | 15 470 |
| 标注的关系类型数 | 30 | 27 | 13 | 12 | 26 | 97 |
| 显式标注的句子数 | 243 | 120 | 313 | 78 | 187 | 9795 |
| 成功率/% | 69.31 | 51.48 | 18.17 | 37.99 | 54.18 | 67.83 |
| 准确率/% | 76 | 75 | 72 | 95 | 83 | 76.36 |
Tab. 5 Top 10 relationship types of corpus number表5 语料数居前10位的关系 |
| 关系名称 | 包含景点 | 地理位置 | 临近火车站 | 途经城市 | 别名 | 隶属 | 临近机场 | 流经地区 | 包含高校 | 所属城市 |
|---|---|---|---|---|---|---|---|---|---|---|
| 语料数 | 842 | 791 | 352 | 315 | 261 | 261 | 168 | 158 | 119 | 102 |
| 准确率/% | 78 | 86 | 31 | 91 | 62 | 69 | 60 | 95 | 52 | 76 |
The authors have declared that no competing interests exist.
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
[
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
|
| [11] |
[
|
| [12] |
|
| [13] |
|
| [14] |
[
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
[
|
| [19] |
|
| [20] |
[
|
| [21] |
[
|
| [22] |
[
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}