
室内用户语义位置预测研究
作者简介:王培晓(1994-),男,山东济南人,硕士生,研究方向为地理信息服务、时空数据挖掘等。E-mail: 260129327@qq.com
收稿日期: 2018-08-31
网络出版日期: 2018-12-20
基金资助
国家重点研发计划项目(2017YFB0503500);数字福建建设项目(闽发改网数字函(2016)23号);湖北省教育厅人文社会科学研究项目(17Q071)
Research on Semantic Location Prediction of Indoor Users
Received date: 2018-08-31
Online published: 2018-12-20
Supported by
National Key Research and Development Program of China, No.2017YFB0503500;Digital Fujian Program, No.2016-23;Hubei Provincial Education Department Humanities and Social Sciences Research Project, No.17Q071.
Copyright
位置预测技术可以提前预知用户下一时刻的位置,在基于位置的服务(Location-based Service,LBS)领域中发挥着极其重要的作用。现有的位置预测技术大多仅使用用户的地理轨迹,仅使用地理轨迹挖掘出来的用户移动模式易受地理特性的限制缺乏深层次的语义信息。本文基于某商场群体用户的室内轨迹数据和语义信息预测用户下一个时刻语义位置。语义位置预测包括停留区域识别、停留区域语义匹配、语义位置建模。在停留区域识别阶段,为减少室内停留时间不固定对停留区域识别的影响,本研究提出了一种新型的时空凝聚层次聚类算法(Spatial-Temporal Agglomerative Nesting, ST-AGNES),该算法具有思想简单、超参数少、自动生成聚类个数等优点。在语义匹配阶段,引入了吸引度规则,充分利用停留区域所有轨迹点与室内高密度的商铺名称信息做匹配。最后,采用长短型记忆神经网络模型(Long Short-Term Memory,LSTM)挖掘群体用户的语义位置模式并预测用户未来的语义位置,实验预测正确率达到61.3%。
关键词: LSTM模型; ST-AGNES算法; 吸引度规则; 室内轨迹; 位置预测
王培晓 , 王海波 , 傅梦颖 , 吴升 . 室内用户语义位置预测研究[J]. 地球信息科学学报, 2018 , 20(12) : 1689 -1698 . DOI: 10.12082/dqxxkx.2018.180411
The location prediction technology can predict the location of the user at the next moment in advance, and plays an extremely important role in the field of Location-based Service (LBS).Most of the existing location prediction techniques only use the geographical location information and time information of the user's historical trajectory. The geographic trajectory is composed of a series of geographically-pointed time-stamped latitude and longitude points, and the geographic trajectory only mines users. Mobile mode is limited by geographic features. In this paper, we propose a novel approach for predicting the next semantic location of a user's movement based on the geographic and semantic characteristics of the group user trajectory. The semantic location prediction based on group users generally consists of three steps: Firstly, the specific algorithm is used to identify the staying area in the user's trajectory; Next, the semantic matching algorithm is used to associate the user's staying area with the semantic information; Finally, Mining the semantic location pattern of group users, using this pattern to predict the semantic location of the user at the next moment. In the stage of staying area identification, in order to reduce the influence of indoor stay time unfixed on the recognition of stay area, this paper proposes a new type of spatial-temporal agglomerative nesting (ST-AGNES), which can automatically identify the number of staying areas in the user's trajectory using only the distance threshold. In the semantic matching stage, this paper proposes a semantic matching method based on attractance rules, which makes uses all trajectory points in the stay area to be associated with indoor high-density semantic information. In the final forecasting stage, this paper uses Long Short-Term Memory (LSTM) to mine the semantic location patterns of group users and predict the future semantic location of users. The experimental results have achieved a prediction accuracy rate of 61.3%.
Key words: LSTM; ST-AGNES; attraction rule; indoor trajectory; location prediction
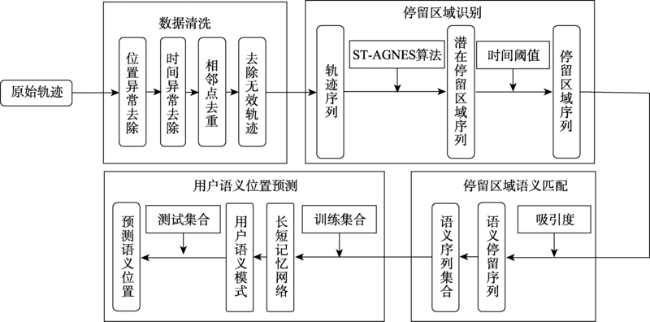
Fig. 1 Location prediction process图1 室内用户位置预测总体流程 |
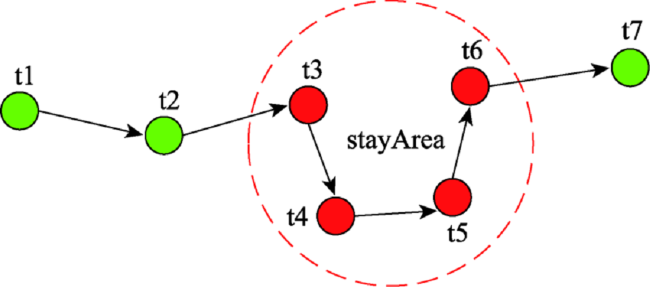
Fig. 2 Stay area图2 用户停留区域 |
Fig. 3 Time-series dataset X图3 按时间顺序分布的数据集X |
Fig. 4 Spatio-temporal agglomerative nesting图4 时空凝聚层次聚类算法 |
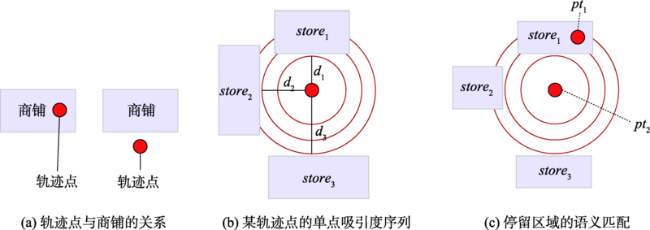
Fig. 5 Semantic matching of user stay areas图5 用户停留区域的语义匹配 |
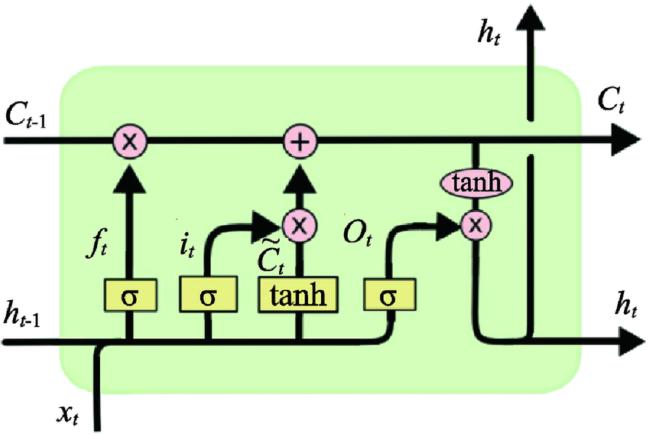
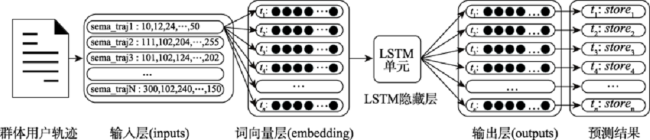
Fig. 6 LSTM cell structure图6 LSTM单元结构 |
Fig. 7 Indoor user semantic location prediction model图7 室内用户语义位置预测模型 |
Tab. 1 Samples of user's records表1 用户轨迹数据实例 |
| 用户ID | 时间 | X/m | Y/m | 所在楼层ID |
|---|---|---|---|---|
| 0000CE*** | 2017-12-20 10:46:45 | 130219*** | 43904*** | 1 |
| 0000CE*** | 2017-12-20 10:46:57 | 130219*** | 43903*** | 1 |
| 0000CE*** | 2017-12-20 10:47:05 | 130219*** | 43904*** | 1 |
| … | … | … | … | … |
| 0000CE*** | 2017-12-20 19:20:33 | 130219*** | 43904*** | 4 |
| 0000CE*** | 2017-12-20 19:20:45 | 130219*** | 43904*** | 4 |
Tab. 2 Samples of semantic stores表2 商场商铺实例 |
| 商铺ID | 商铺形状 | 商铺名称 | 所在楼层ID |
|---|---|---|---|
| 1 | Shape(面) | *** | 2 |
| 2 | Shape(面) | *** | 2 |
| 3 | Shape(面) | *** | 4 |
| … | … | … | … |
| 351 | Shape(面) | *** | 4 |
| 352 | Shape(面) | *** | 3 |
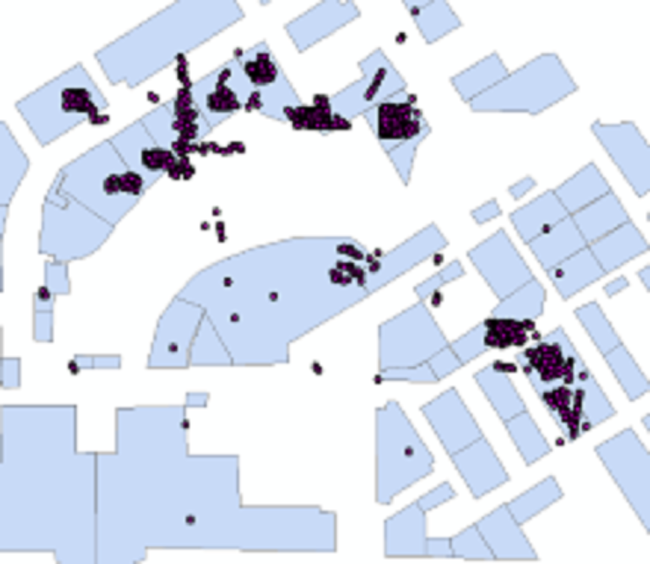
Fig. 8 User's stay area points and indoor store图8 某用户停留区域轨迹点与室内商铺 |
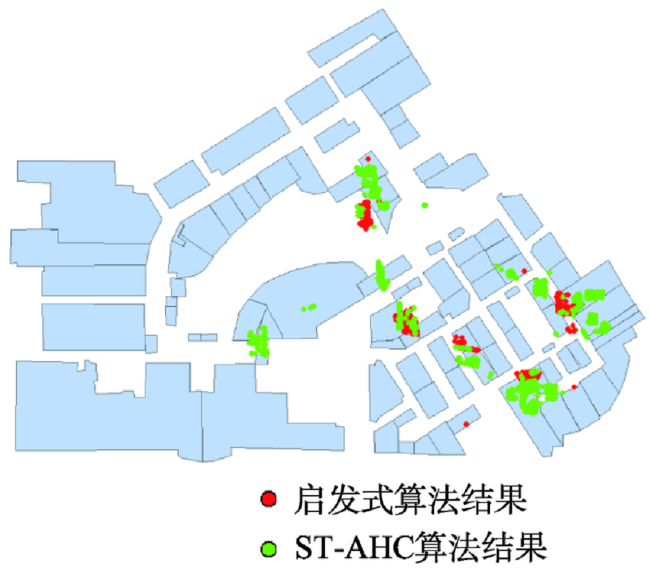
Fig. 9 Comparison of a user's stay area obtained by heuristic algorithm and ST-AGNES algorith图9 启发式算法和ST-AGNES算法得到的某用户停留区域对比 |
Tab. 3 Samples of semantic stores表3 用户语义轨迹实例 |
| 用户ID | 用户语义轨迹 |
|---|---|
| 0000CE*** | S48,S91,S34,S231,S34,S91,S11,S79 |
| FA8170*** | S301,S60,S286,S132,S94,S292,S285,S310,S48 |
| FAA378*** | S20,S211,S223,S20,S343,S20 |
| … | … |
| FE53FA*** | S107,S132,S107,S296,S107,S132,S124,S132 |
| 0AEE45*** | S234,S43,S297,S60,S48,S32,S322,S271,S94,S95 |
Tab. 4 LSTM model parameters表4 LSTM模型参数 |
| BATCH_SIZE | NUM_LAYERS | HIDDEN_SIZE | EMBEDDING_SIZE | LEARNINT_ RATE |
|---|---|---|---|---|
| 64 | 2 | 256 | 128 | 0.01 |
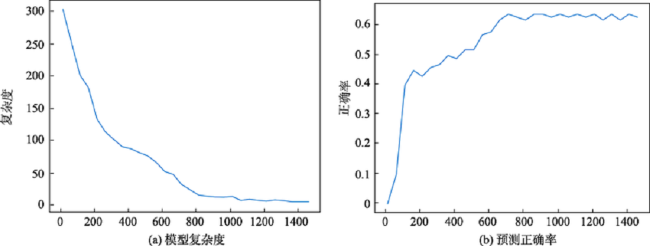
Fig. 10 Model perplexity and prediction accuracy图10 模型复杂度与预测正确率 |
Tab. 5 User semantic location prediction results表5 某用户语义位置预测结果 |
| 已知语义轨迹 | 预测语义位置 | 实际位置 |
|---|---|---|
| YAGERRIS | reemoor(0.09),KISS KITTY(0.09),AESOMINO (0.08) | FAmecoco |
| YAGERRIS,FAmecoco | marfeel (0.13),reemoor (0.11),FIOCCO(0.11) | reemoor |
| YAGERRIS,FAmecoco,reemoor | KISS KITTY (0.26),FIOCCO (0.19),marfeel (0.08) | KISS KITTY |
| YAGERRIS,FAmecoco,reemoor,KISS KITTY | FIOCCO(0.35) ,marfeel(0.17),ILAPAOE(0.11) | FIOCCO |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
[
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
[
|
| [12] |
[
|
| [13] |
|
| [14] |
[
|
| [15] |
[
|
| [16] |
[
|
| [17] |
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
Leiva L A. Vidal E.Warped K -Means: An algorithm to cluster sequentially-distributed data[M]. Elsevier Science Inc., 2013:196-210.
|
| [22] |
[
|
| [23] |
[
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}