
基于C-SOM和Spark的并行空间离群挖掘方法及应用
作者简介:潘淼鑫(1987-),女,博士生,主要从事大数据挖掘与云计算研究。E-mail:pan_miaoxin@qq.com
收稿日期: 2018-05-03
要求修回日期: 2018-07-03
网络出版日期: 2019-01-20
基金资助
福建省重点科技计划项目(2015H0015)
福建省教育厅基金(JAT160125)
福建省社科青年项目(FJ2017C084)
Parallel Spatial Outliers Mining based on C-SOM and Spark
Received date: 2018-05-03
Request revised date: 2018-07-03
Online published: 2019-01-20
Supported by
Key Science and Technology Plan Projects of Fujian Province, No.2015H0015
Fujian Provincial
Education Department Foundation, No.JAT160125
Social Science Youth Projects of Fujian Province, No.FJ2017C084
Copyright
空间离群挖掘可以发现空间数据集中非空间属性值与邻域中其他空间对象明显不同的空间对象。随着空间数据量的快速增加,传统集中式处理模式面临单机性能瓶颈、难以扩展等问题,已逐渐不能满足应用需要。因此,本文根据Spark并行计算框架,充分利用Spark快速内存计算和扩展性的优势,提出了一种基于考虑约束条件的空间离群挖掘算法(C-SOM)和Spark的并行空间离群挖掘算法和原型系统。该并行算法以C-SOM为核心,并行地在多个计算节点对全局数据集和各局部数据集执行C-SOM算法,得到全局离群和局部离群。轻量级的原型系统基于Spark实现了该并行算法,采用Browser/Server架构,提供给用户可视化的操作界面,简洁实用。最后,通过福建省东南沿海土壤化学元素调查数据和人工合成数据的离群分析,验证了该并行算法和原型系统的合理性、有效性和高效性。
潘淼鑫 , 林甲祥 , 陈崇成 , 叶晓燕 . 基于C-SOM和Spark的并行空间离群挖掘方法及应用[J]. 地球信息科学学报, 2019 , 21(1) : 128 -136 . DOI: 10.12082/dqxxkx.2019.180221
Spatial outlier mining can find the spatial objects whose non-spatial attribute values are significantly different from the values of their neighborhood. Faced with the explosion of spatial data and problems such as single machine performance bottleneck and difficult expansion, the traditional centralized processing mode has gradually failed to meet the needs of applications. In this paper, we propose a parallel spatial outlier mining algorithm and its prototype system which are based on Constrained Spatial Outlier Mining (C-SOM) and make full use of the advantages of a parallel computing framework Spark's fast memory computing and scalability. The parallel algorithm uses C-SOM algorithm as the core algorithm, executes the C-SOM algorithm on a Spark cluster composed of multiple nodes for a global dataset and many local datasets concurrently to get the global outliers and the local outliers. Datasets are divided into multiple regional datasets according to the administrative division. A region dataset is considered as a local dataset and the global dataset contains all of the selected local datasets to be mined. The lightweight prototype system implements the parallel algorithm based on Spark and adopts Browser/Server architecture to provide users with a visualized operation interface which is concise and practical. Users can select the region datasets and set the parameters of C-SOM algorithm on interfaces. The prototype system will execute the parallel algorithm on a Spark cluster and finally list both the global and local outliers which have the top largest outlier factor values so that users can make further analysis. At last, we use the soil geochemical investigation data from Fujian eastern coastal zone area in China and a series of artificial datasets to carry out experiments. The results of the soil geochemical datasets experiments validate the rationality and effectiveness of the parallel algorithm and its prototype system. The results of the artificial datasets experiments show that, compared to single machine implementation, our parallel system can support analysis for much more datasets and its efficiency is much higher when the number of datasets is big enough. This study confirms the local instability characteristics of spatial outliers and demonstrates the rationality, and effectiveness of the parallel algorithm and its prototype system to detect global and local spatial outliers simultaneously.
Key words: C-SOM; Spark; parallel computing; spatial outlier; data mining
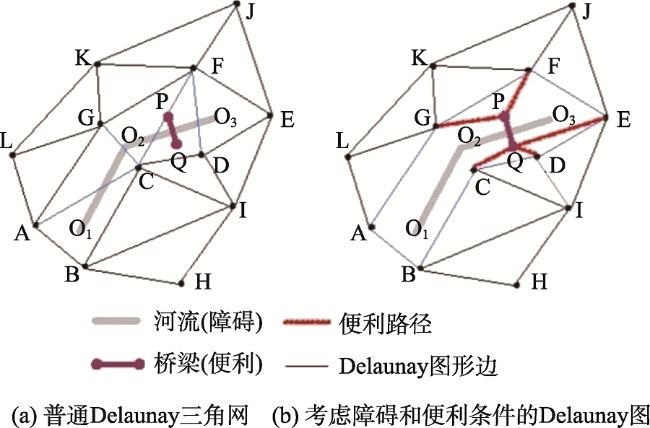
Fig. 1 Common Delaunay triangulation and constrained Delaunay graph图1 普通Delaunay三角网和约束Delaunay图 |
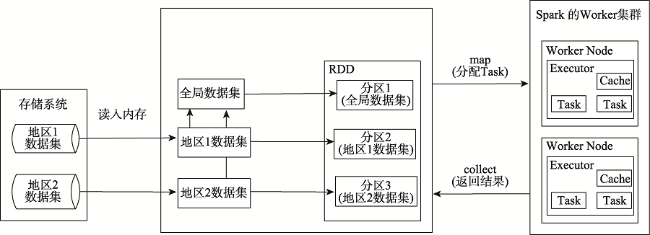
Fig. 2 The general process of parallel spatial outlier mining based on Spark图2 基于Spark的并行空间离群挖掘的基本过程 |

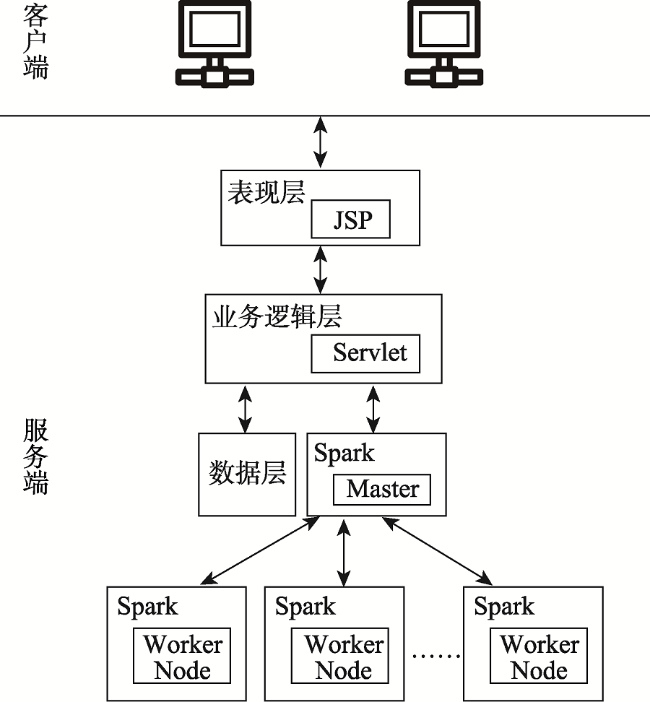
Fig. 3 The architecture diagram of parallel spatial outlier mining prototype system based on Spark图3 基于Spark的并行空间离群挖掘原型系统架构 |
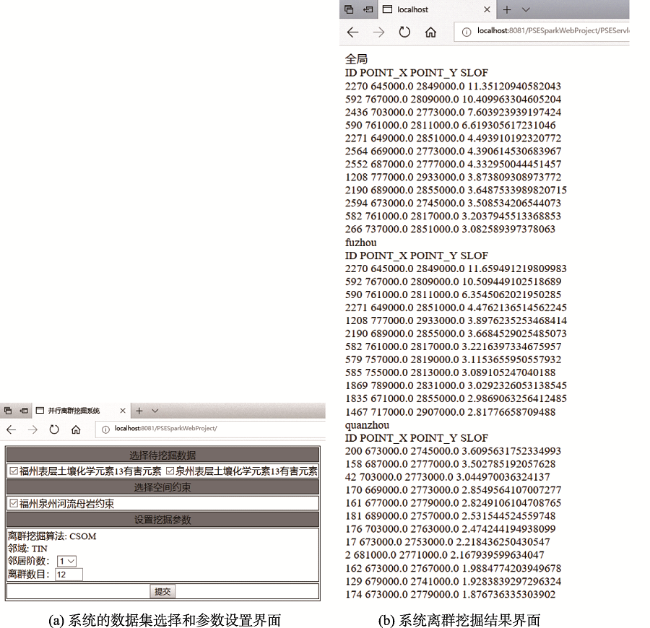
Fig. 4 Interfaces of data selecting, parameters setting and results in the prototype system图4 原型系统中数据选择、算法参数设置和结果界面 |
Tab.1 Results of the parallel outlier mining for the experimental area表1 实验区并行离群挖掘结果 |
| 序号 | 整个实验区 | 福州地区 | 泉州地区 | |||
|---|---|---|---|---|---|---|
| 对象ID(横坐标,纵坐标) | 离群因子 | 对象ID(横坐标,纵坐标) | 离群因子 | 对象ID(横坐标,纵坐标) | 离群因子 | |
| 1 | 2270(645 000, 2 849 000) | 11.351 | 2270(645 000, 2 849 000) | 11.659 | 200(673 000, 2 745 000) | 3.610 |
| 2 | 592(767 000, 2 809 000) | 10.410 | 592(767 000, 2 809 000) | 10.509 | 158(687 000, 2 777 000) | 3.503 |
| 3 | 2436(703 000, 2 773 000) | 7.604 | 590(761 000, 2 811 000) | 6.355 | 42(703 000, 2 773 000) | 3.045 |
| 4 | 590(761 000, 2 811 000) | 6.619 | 2271(649 000, 2 851 000) | 4.476 | 170(669 000, 2 773 000) | 2.855 |
| 5 | 2271(649 000, 2 851 000) | 4.494 | 1208(777 000, 2 933 000) | 3.898 | 161(677 000, 2 779 000) | 2.825 |
| 6 | 2564(669 000, 2 773 000) | 4.391 | 2190(689 000, 2 855 000) | 3.668 | 181(689 000, 2 757 000) | 2.532 |
| 7 | 2552(687 000, 2 777 000) | 4.333 | 582(761 000, 2 817 000) | 3.222 | 176(703 000, 2 763 000) | 2.474 |
| 8 | 1208(777 000, 2 933 000) | 3.874 | 579(757 000, 2 819 000) | 3.115 | 17(673 000, 2 753 000) | 2.218 |
| 9 | 2190(689 000, 2 855 000) | 3.649 | 585(755 000, 2 813 000) | 3.089 | 2(681 000, 2 771 000) | 2.168 |
| 10 | 2594(673 000, 2 745 000) | 3.509 | 1869(789 000, 2 831 000) | 3.029 | 162(673 000, 2 767 000) | 1.988 |
| 11 | 582(761 000, 2 817 000) | 3.204 | 1835(671 000, 2 855 000) | 2.987 | 129(679 000, 2 741 000) | 1.928 |
| 12 | 266(737 000, 2 851 000) | 3.083 | 1467(717 000, 2 907 000) | 2.818 | 174(673 000, 2 779 000) | 1.877 |
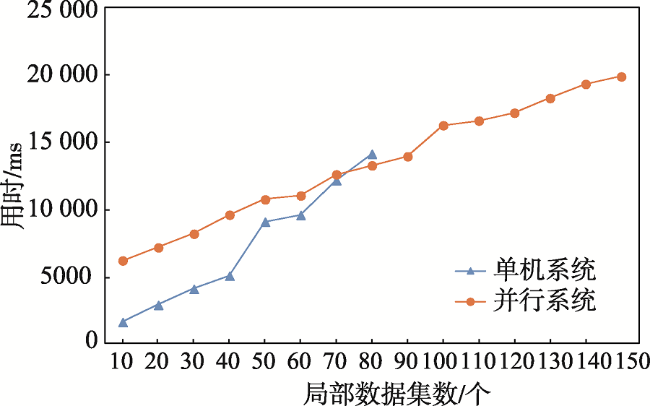
Fig. 5 Comparison of outlier mining efficiency between single machine implementation and parallel system图5 单机实现和并行系统的离群挖掘效率对比 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
[
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
Apache. Hadoop[EB/OL]. .
|
| [18] |
|
| [19] |
[
|
| [20] |
Apache. Spark[EB/OL]. .
|
| [21] |
[
|
| [22] |
[
|
| [23] |
[
|
| [24] |
[
|
| [25] |
|
| [26] |
[
|
| [27] |
[
|
| [28] |
|
| [29] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}