
基于开源大数据的北京地区餐饮业空间分布格局
作者简介:徐晓宇(1995-),女,辽宁营口人,硕士生,主要从事地学信息可视化与数据挖掘研究。E-mail: xuxiaoyu@pku.edu.cn
收稿日期: 2018-09-04
要求修回日期: 2018-11-29
网络出版日期: 2019-01-30
基金资助
国家重点研发计划项目(2016YFC0803108)
Analysis on Spatial Distribution Pattern of Beijing Restaurants based on Open Source Big Data
Received date: 2018-09-04
Request revised date: 2018-11-29
Online published: 2019-01-30
Supported by
National Key Research and Development Program of China, No.2016YFC0803108
Copyright
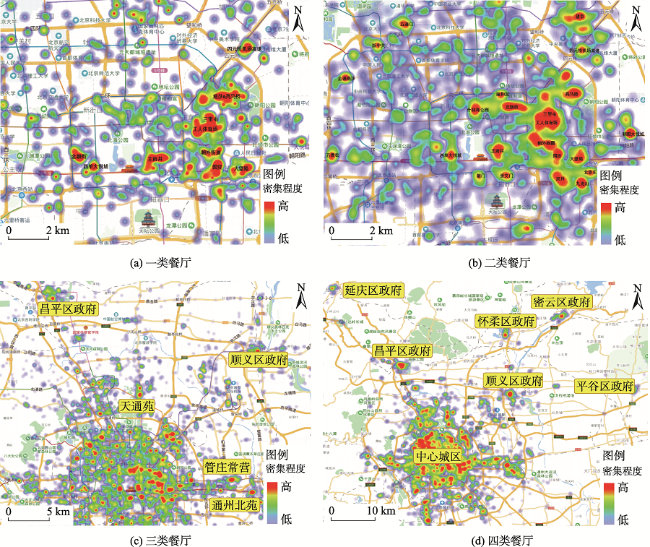
基于大数据进行城市服务设施空间格局分析已成为一种新的研究热点,而餐饮业是城市服务业的典型代表,因此通过开源大数据对城市餐饮业的空间布局进行研究具有重要的意义。本文以北京地区作为研究区,采用网络爬虫技术获取大众点评上153 895家餐饮店数据,引入基于密度的CFSFDP聚类算法从空间分布密集度和人均消费等级方面对餐饮业背后蕴含的地理聚集特征进行分析。研究发现:① 北京地区餐饮店总体呈现多中心的空间分布特征,其集聚程度以主城区为核心向外逐级递减,并明显表现出围绕重要商圈、旅游景点和住宅区进行布局以及沿交通轴线扩展的趋势;② 不同人均消费水平的餐饮店呈现等级体系特征,即高档餐馆少而集聚,中低档餐馆多而散的分布特点;③ 餐馆分布密集程度和定价表现出接近市场和消费者的特征。同时,本文综合空间集聚特征和消费水平2项指标对影响餐饮店集群空间分布格局的因素进行了分析,以期为政府规划部门进行城市商业空间布局研究提供借鉴。
徐晓宇 , 李梅 . 基于开源大数据的北京地区餐饮业空间分布格局[J]. 地球信息科学学报, 2019 , 21(2) : 215 -225 . DOI: 10.12082/dqxxkx.2019.180437
Using big data to analyze the spatial pattern of urban service facilities has become a new research hotspot, and catering industry is a typical representative of urban service industry. Therefore, it is of great significance to study the spatial layout of urban catering industry through open source big data. The restaurants in a city can be abstracted as point objects in the geographical study , and clustering analysis is a classical data mining method that quantificationally identifies geographical clustering among objects. In this paper, Beijing is selected as the research area, and the data of 153 895 restaurants in Dianping.com are obtained by using web crawler technology. The density-based CFSFDP clustering algorithm (clustering by fast search and find of density peaks) is adopted here to analyze the geographical clustering characteristics of catering industry in terms of spatial distribution density and per capita consumption level. This approach, which is based on the idea that cluster centers are characterized by a higher density than their neighbors and by a relatively larger distance from points with higher densities, can recognize clusters regardless of their shape and the dimensionality of the space in which they are embedded, so more accurate spatial analysis results can be obtained. The results show that: (1) the spatial pattern of Beijing restaurants is imbalanced, which generally presents the characteristics of multi-center spatial distribution, and the agglomeration degree of restaurants decreases with the distance increase from the main urban area which are regarded as the core. Besides, the restaurants hot spots mainly circles around important business centers, tourist attractions as well as residential areas, and extends along the traffic line evidently. (2) The catering stores with different per capita consumption levels have the characteristics of hierarchical system. That is to say, there are the number of high-grade restaurants is few, and mainly concentrated in the commercial centers, financial centers and famous tourist attractions in Dongcheng district, Xicheng district, Chaoyang district and Haidian district, while the number of middle and low-grade restaurants is much more and their spatial distribution are more scattered. (3) The density and price of restaurants accords with consumption level of consumers. At the same time, this paper also analyses the factors influencing the spatial distribution pattern of catering clusters by combining the two indicators of spatial agglomeration characteristics and consumption level, in order to provide useful reference of urban commercial spatial layout for the government planning departments.
Key words: geographical big data; CFSFDP; restaurant; spatial pattern; Beijing area
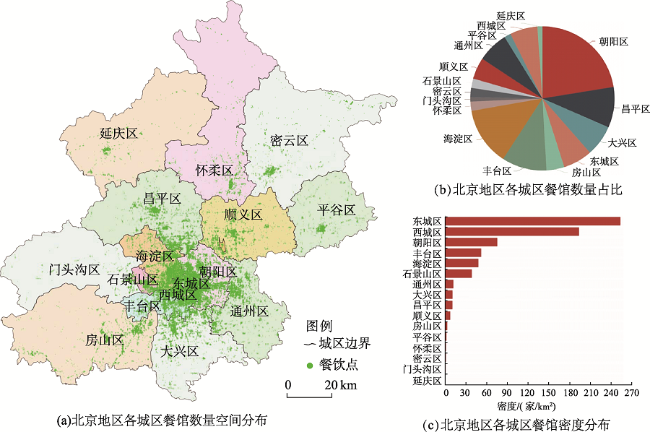
Fig. 1 The distribution of restaurants in Beijing图1 北京地区餐饮店分布 |
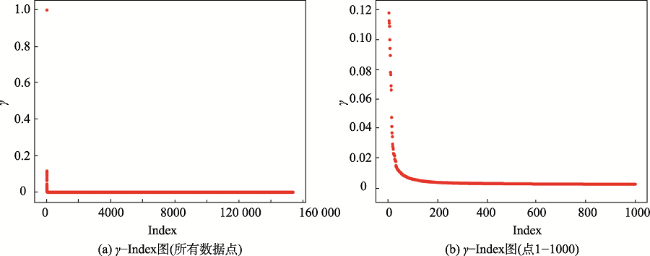
Fig. 2 The value of sorted in decreasing order图2 降序排列 |
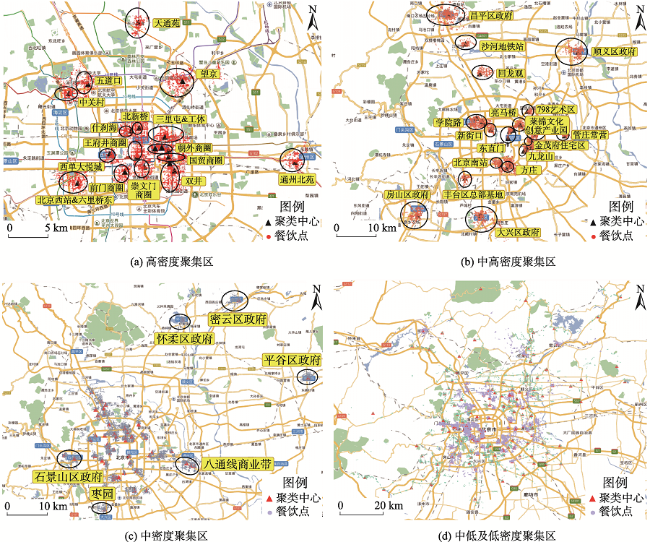
Fig. 3 The cluster results of restaurants in Beijing area图3 北京地区餐饮服务业聚类结果 |
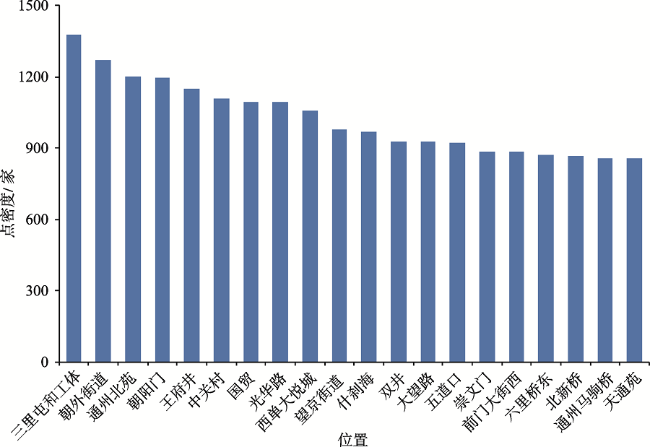
Fig. 4 The cluster centers whose local density is on TOP20图4 点密度TOP20的餐饮服务业聚类中心 |
Fig. 5 Thermodynamic chart of restaurants' prices in Beijing area图5 北京地区餐厅价格热力图 |
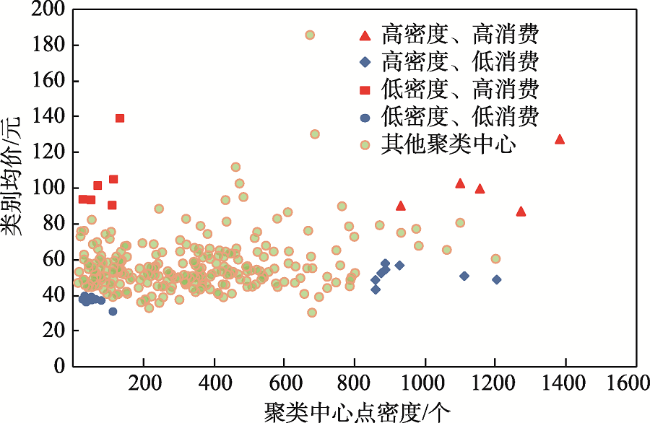
Fig. 6 Scatter diagram of all clustering centers图6 聚类中心散点图 |
Tab. 1 Hierarchical system of typical gathering areas in Beijing表1 北京地区典型集聚区等级体系 |
| 等级 | 集聚区代表 | 空间区位特征 |
|---|---|---|
| 高密度、高消费区域 | 三里屯、朝外街道、王府井大街、国贸、天安门广场、 大望路等 | 繁华商圈/热门旅游地点,人流量大;周围包括大量企业、外国商社和高端楼盘,汇集了大批高收入、高消费的白领群体 |
| 高密度、低消费区域 | 通州北苑、中关村、五道口、六里桥东、西直门等 | 辖内社区众多/邻近高等院校;具备地理优势和便利的交通条件 |
| 低密度、高消费区域 | 朝阳区裕京花园别墅附近、顺义区龙安别墅附近等 | 别墅区 |
| 低密度、低消费区域 | 大兴安定镇、房山琉璃河镇、顺义区河南村等 | 周边城区分散的居民区等 |
The authors have declared that no competing interests exist.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
[
|
| [8] |
[
|
| [9] |
[
|
| [10] |
[
|
| [11] |
[
|
| [12] |
[
|
| [13] |
[
|
| [14] |
[
|
| [15] |
|
| [16] |
|
| [17] |
[
|
| [18] |
[
|
| [19] |
[
|
| [20] |
[
|
| [21] |
[
|
| [22] |
|
| [23] |
[
|
| [24] |
[
|
| [25] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}