
利用卷积神经网络提取微博中的暴雨灾害信息
作者简介:刘淑涵(1996-),女,湖北十堰人,硕士生,研究方向为地理时空数据分析与挖掘。E-mail: liush96@whu.edu.cn
收稿日期: 2018-12-28
要求修回日期: 2019-03-25
网络出版日期: 2019-07-25
基金资助
国家重点研发计划项目(2016YFB0501403)
国家自然科学基金项目(41271399)
测绘地理信息公益性行业科研专项经费项目(201512015)
Extracting Rainstorm Disaster Information from Microblogs Using Convolutional Neural Network
Received date: 2018-12-28
Request revised date: 2019-03-25
Online published: 2019-07-25
Supported by
The National Key Research Program of China, No.2016YFB0501403
The National Natural Science Foundation of China, No.41271399
China Special Fund for Surveying, Mapping and Geo-information Research in the Public Interest, No.201512015
Copyright
从社交媒体中挖掘灾害应急信息,能够有效帮助传统灾害管理获取实时、主题丰富的灾害信息,从而成为灾害应急管理的新手段。得益于深度学习在自动特征提取上的成就,本文研究了一种利用卷积神经网络对社交媒体中的灾害应急信息进行自动实时提取与分类的方法。首先,利用社交媒体数据和Word2vec模型,构建与灾害类事件相关的语料库并获得相应的词向量;其次,将词嵌入文本和相应的灾情类别作为卷积神经网络的输入,经过多分类学习得到分类模型,用以提取近实时灾害信息。以2012年“7.21北京特大暴雨”事件为案例,通过分类模型获得常见灾情类别的暴雨灾害社交媒体信息。该模型在测试集上的精度达到了90%以上,并且将模型运用于新爬取的2016年暴雨数据集上也得到了较好的表现,说明该模型在近实时自动提取灾害信息方面具有可行性。在对2012年分类结果进行时空分析结果表明,通过社交媒体获得的暴雨灾害主题信息符合灾害发展的规律,说明了利用深度学习提取社交媒体数据中的灾害应急信息的有效性和可行性,能够为实时灾害应急管理提供新的思路。
刘淑涵 , 王艳东 , 付小康 . 利用卷积神经网络提取微博中的暴雨灾害信息[J]. 地球信息科学学报, 2019 , 21(7) : 1009 -1017 . DOI: 10.12082/dqxxkx.2019.180701
Nowadays social media has played an increasingly significant role in disaster management, thanks to its real-time nature and location-based services. When a disaster happens, a large number of images and texts with temporal and geographic information quickly flood in the social media network. Complementary to the traditional disaster management, social media could provide a lot of dynamic, nearly real-time disaster information to researchers. Current studies place more emphasis on using machine learning to deal with social media disaster data. Yet, in many cases deep learning has a better performance in automatic feature extraction than the traditional machine learning, and it can be used to extract and classify disaster information from social media. This paper focused on a method of extracting the disaster information from social media data using Convolutional Neural Network (CNN). To obtain the word vector corresponding to social media texts, a corpus of disaster events by using social media data was trained by word2vec model. Then, the vectorized microblog sentences and their corresponding disaster categories were used as input to the multi-classification model, which is based on convolutional neural network. After training and optimization, we used this model to extract disaster information from a large number of social media data streams. For an experiment, we combined Sina Weibo API and web crawler, and got over twenty thousand microblog texts with the theme of "Beijing Heavy Rainstorm" happened in 2012. Besides the irrelevant texts, we divided the data into seven categories. The topic classification model of rainstorm disaster information was built and trained based on a small number of tagged Sina Weibo data. The experimental results achieved the F-value of over 80% and the precision of over 90%, proving the validity of applying the model to our dataset. Moreover, this model when used to classify the data on Beijing's rainstorm in 2016 newly crawled form Weibo also had a good performance. According to the different rainstorm emergency topics classified by model, we carried out the deep mining of time series and spatial features to detect the phases of disaster development. Through visualization and statistical analysis, it was found that the time series analysis of disaster was consistent with the development of actual disasters, indicating the effectiveness of the CNN-based method in monitoring Beijing rainstorm. The study shows that using deep learning to extract disaster emergency information from social media is effective and feasible, which provides a new approach to real-time disaster emergency management.
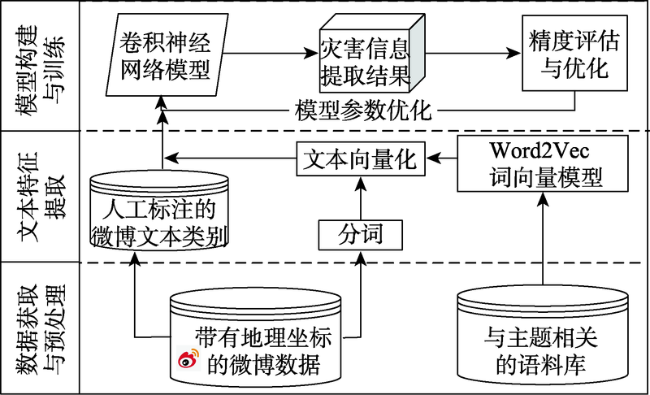
Fig. 1 Research framework of extracting rainstorm disaster information from microblogs using CNN图1 利用卷积神经网络提取微博暴雨灾害信息的研究框架 |
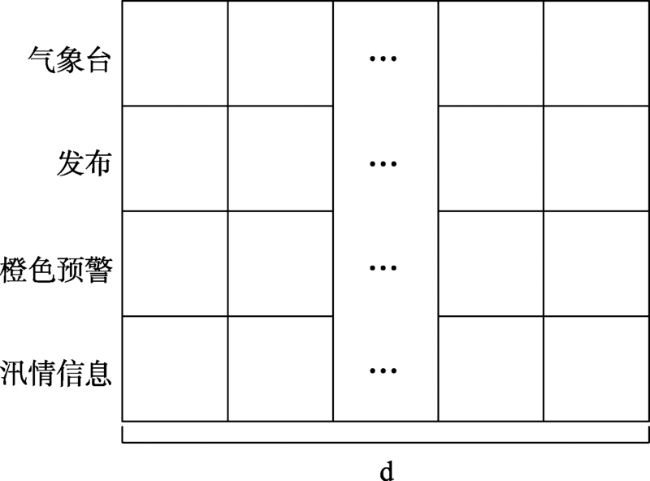
Fig. 2 An example of a sentence matrix图2 一条微博文本对应的矩阵形式 |
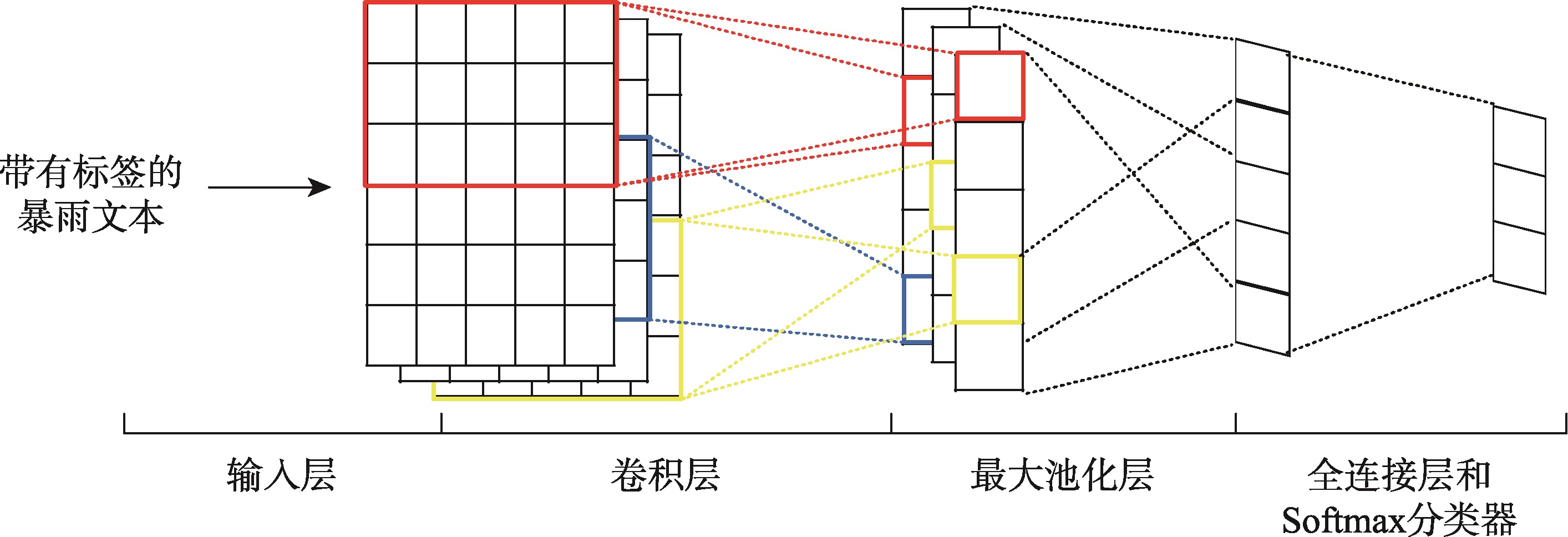
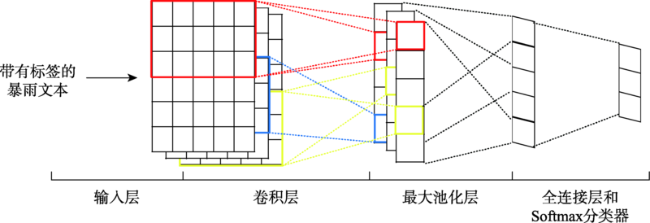
Fig. 3 Structure of the convolutional neural network for text classification图3 用于暴雨文本分类的卷积神经网络结构 |
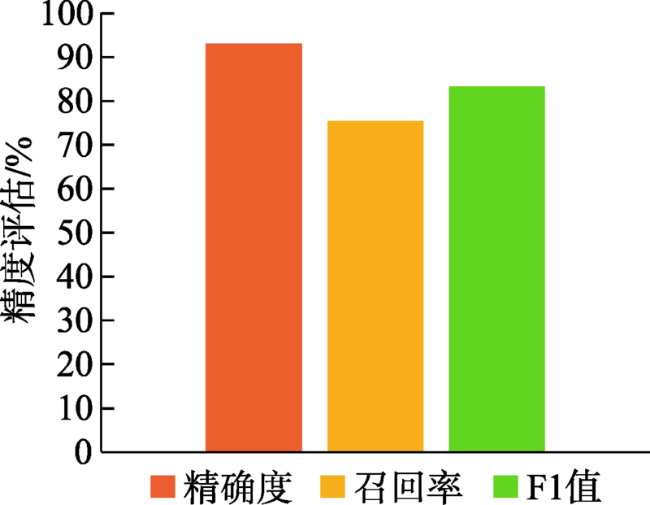
Fig. 4 Evaluation of the classification experiment using weibo rainstorm datasets图4 微博暴雨灾害文本分类精度评估 |
Tab. 1 Evaluation of the various types of rainstorm disaster information in Beijing in 2012 and 2016表1 2012年和2016年北京暴雨相关灾害信息精度评估结果 |
| 类别 | 2012年北京暴雨 | 2016年北京暴雨 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 数量/条 | 精确度/% | 召回率/% | F1值/% | 数量/条 | 精确度/% | 召回率/% | F1值/% | ||
| 正能量祈祷 | 129 | 89.9225 | 89.2308 | 89.5753 | 26 | 71.2308 | 40.7347 | 51.8296 | |
| 交通信息 | 75 | 97.3333 | 83.9080 | 90.1235 | 24 | 91.6667 | 62.8571 | 74.5763 | |
| 伤亡受灾 | 24 | 99.9999 | 82.7586 | 90.5660 | 4 | 74.9999 | 42.8571 | 54.5454 | |
| 灾害原因讨论 | 45 | 95.5556 | 91.4893 | 93.4783 | 26 | 84.6154 | 73.3333 | 78.5714 | |
| 提醒朋友 | 54 | 88.8889 | 77.4193 | 82.7586 | 5 | 80.0000 | 57.1428 | 67.0000 | |
| 天气预警 | 3 | 99.9999 | 6.9767 | 13.0434 | 3 | 66.6666 | 6.2499 | 11.4286 | |
| 整体 | 330 | 93.0303 | 75.4299 | 83.3107 | 88 | 81.6818 | 39.6904 | 53.4222 | |
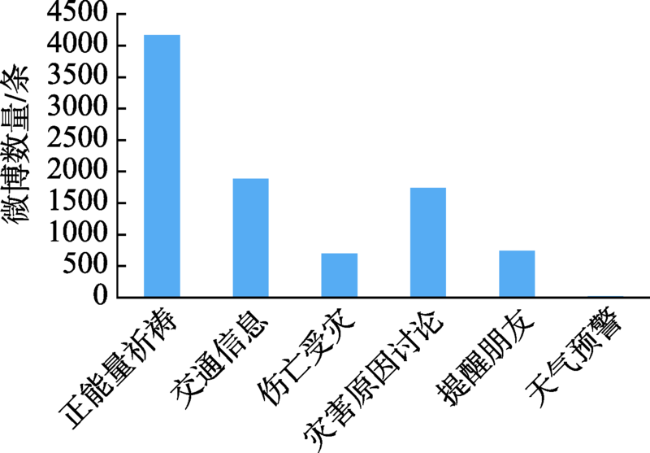
Fig. 5 Number of microblogs related to Beijing rainstorm disaster information in 2012图5 2012年北京暴雨相关灾害信息的微博数量 |
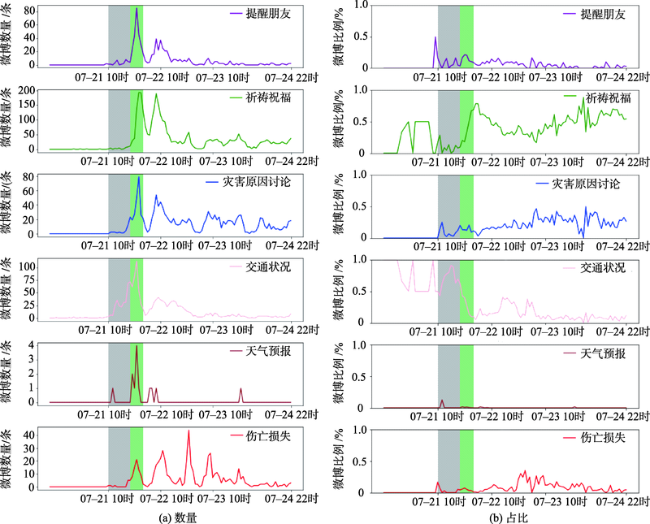
Fig. 6 Trends of the different rainstorm disaster information over time in Beijing in 2012图6 2012年北京不同主题暴雨灾害信息数量和占比随时间变化曲线 |
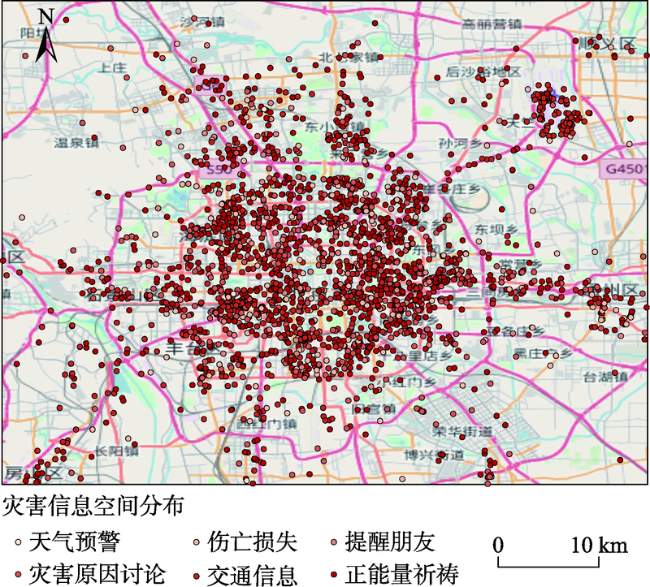
Fig. 7 Spatial distribution of the disaster information obtained from Beijing rainstorm in 2012图7 2012年北京暴雨灾害信息空间分布 |
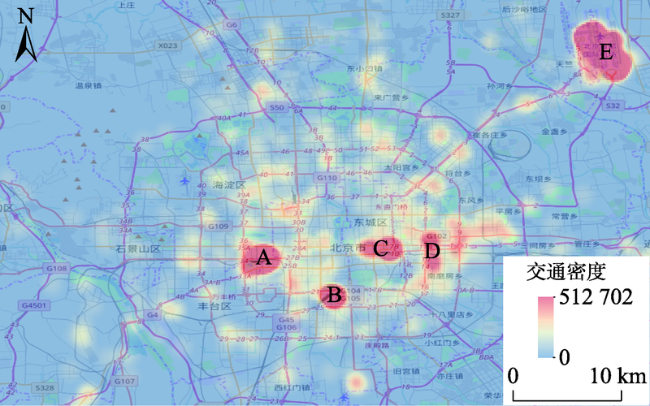
Fig. 8 Cluster map of the traffic disaster information obtained from Beijing rainstorm in 2012图8 2012年北京暴雨交通类灾害信息的空间聚类 |
| [1] |
[
|
| [2] |
[
|
| [3] |
[
|
| [4] |
[
|
| [5] |
[
|
| [6] |
|
| [7] |
|
| [8] |
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}