
基于BiLSTM-CRF的中文层级地址分词
|
程 博(1993-),男,湖北黄石人,硕士生,主要从事时空数据挖掘、自然语言处理。E- mail: 15625110283@163.com |
收稿日期: 2018-12-13
要求修回日期: 2019-04-29
网络出版日期: 2019-08-25
基金资助
广东省重大科技专项(2017B030305005)
版权
Chinese Address Segmentation based on BiLSTM-CRF
Received date: 2018-12-13
Request revised date: 2019-04-29
Online published: 2019-08-25
Supported by
Major Science and Technology Projects of Guangdong Province,(2017B030305005)
Copyright
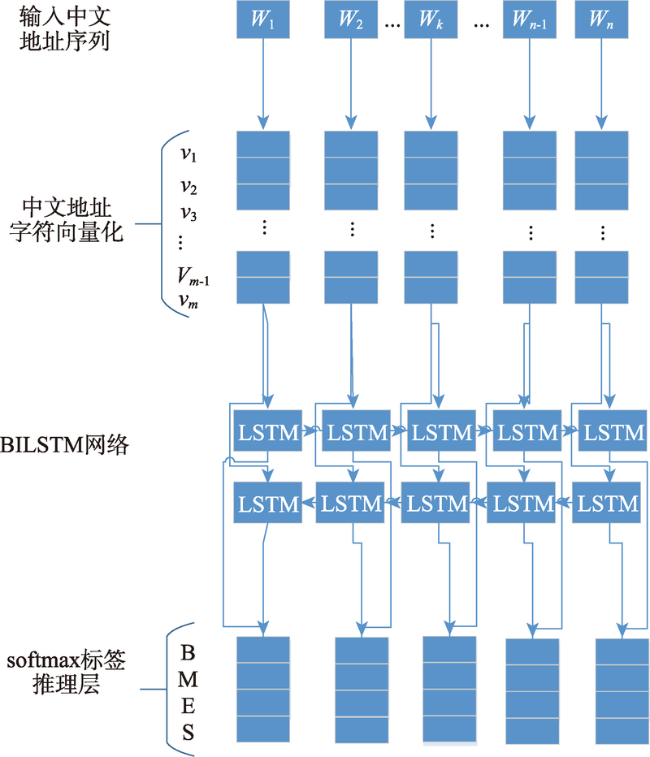
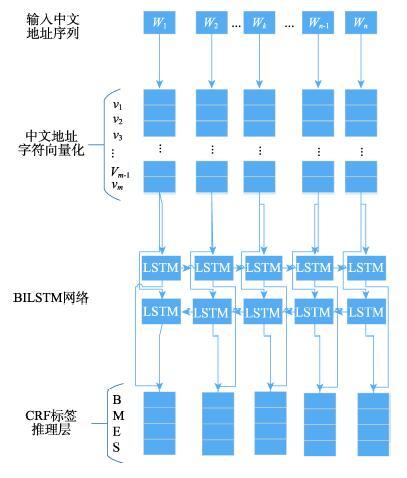
中文地址分词是中文地址标准化的基础工作和地理编码的重要手段,同时也是中文分词和地理研究领域中关注的热点问题之一。针对当前中文地址分词方法缺乏地址层级切分和过多依赖词典和特征的问题,本研究结合四词位标注集和中文层级地址特点,构建针对中文层级地址分词的地址标注体系,并提出融合双向长短时记忆网络和条件随机场(BiLSTM-CRF)的中文层级地址分词模型。该模型既考虑了BiLSTM模型能够记忆上下文地址的特性,也保留了CRF算法可以通过转移概率矩阵控制地址标注输出的能力。针对该地址标注体系标注的训练地址样本,分别使用CRF、LSTM、BiLSTM与BiLSTM-CRF模型进行训练对比。结果表明:① 基于中文地址标注体系的模型分词效果更佳,地址标注更为精细,符合实际地址分布情况;② BiLSTM-CRF模型精确度达到93.4%,高于CRF(90.4%)、LSTM(89.3%)和BiLSTM(91.2%),其整体地址分词性能和各层级地址分词效果相对于其他模型更突出;③ 各模型分词性能与地址层级保持一致,即地址层级越高,分词效果越好。本研究提出的中文地址标注体系和分词模型为开展中文地址标准化工作提供了方法参考,同时也为进一步提升地理编码技术的精准度提供了可能。
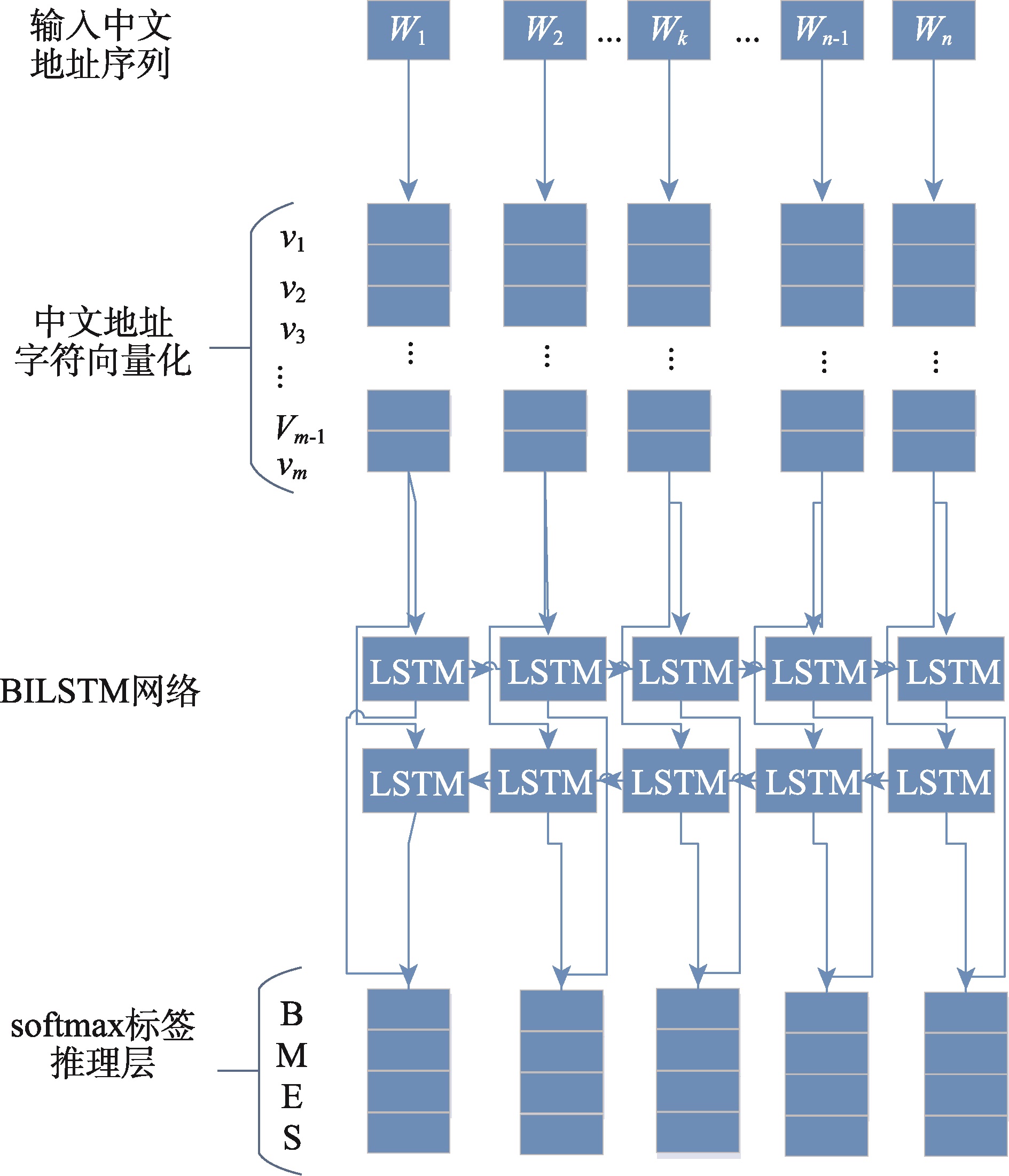
程博 , 李卫红 , 童昊昕 . 基于BiLSTM-CRF的中文层级地址分词[J]. 地球信息科学学报, 2019 , 21(8) : 1143 -1151 . DOI: 10.12082/dqxxkx.2019.180654
Chinese word segmentation is a basic step in Chinese text processing and Chinese natural language processing. As a branch of Chinese word segmentation, Chinese address segmentation, which has become one of the hottest issues in Chinese word segmentation and geography research, is an important method to standardize Chinese address and conduct geocoding. Existing studies on Chinese address segmentation are mainly based on Statistical Machine Learning (SML) and Recurrent Neural Network (RNN). However, either of them cannot combine the advantages of the other. Furthermore, the current Chinese address segmentation methods lack address level segmentation and are too dependent on dictionaries and features. Therefore, this paper combined the four-word-position tagging set and Chinese hierarchical address characteristics to construct an address tagging system, and proposed a Chinese hierarchical address segmentation model (BiLSTM-CRF) which combines bidirectional long-term memory networks and conditional random fields algorithm. The proposed model utilizes the BiLSTM model to remember the characteristics of context address, while retaining the ability of the CRF algorithm to control the address tagging output by transferring probability matrix. In so doing, it has more powerful capability than the traditional statistical machine learning algorithms and RNN in the field of sequence labeling and word segmentation. To test the performance of BiLSTM-CRF on address samples marked by the address tagging system, CRF, LSTM, and BiLSTM were used to compare with BiLSTM-CRF and were respectively applied for training under the same condition as BiLSTM-CRF. We found that: (1) The segmentation effect of BiLSTM-CRF which is based on the Chinese address tagging system was better than the models for comparison, and the address tagging was more elaborate, in line with the actual address distribution. (2) The BiLSTM-CRF model had an accuracy of 93.4%, which was higher than the CRF (90.4%), LSTM (89.3%) and BiLSTM (91.2%) models. The overall address word segmentation performance and the effect of BiLSTM-CRF on each level address segmentation were more prominent than the other models. (3) The word segmentation performance of each model was correlated with the address level positively, i.e., the higher the address level, the better the word segmentation effect. The Chinese address tagging system and word segmentation model proposed in this study give a reference for the standardization of Chinese address, and provide the possibility to further improve the accuracy of geocoding technology. Future study can focus on fine-tuning the model to improve the model accuracy.
表1 原始地址数据格式Tab. 1 Original address data format |
| 样本编号 | 原始地址 | 地址层级关系 |
|---|---|---|
| 1 | 广东省惠州市仲恺区淡水街道办 | 省-市-区-街道 |
| 2 | 惠州市仲恺区沥林镇英光村民委员会 | 市-区-乡镇-村 |
| 3 | 广东省惠州市淡水爱民路基顿酒店 | 省-市-街道-街路巷-兴趣点 |
| 4 | 惠州市罗阳富力广场门口 | 市-兴趣点-方位 |
注:数据来源于广东省广州市航天精一(广东)信息科技有限公司。 |
表2 词位标注集Tab. 2 Word label set |
| 词位 | B | M | E | S | A |
|---|---|---|---|---|---|
| 含义 | 词首 | 词中 | 词尾 | 单字词 | 后缀 |
Tab. 3 Hierarchical address labeling system |
| 地址要素类型 | 标注 | 含义 | 示例 |
|---|---|---|---|
| 省、自治区 | B_PRO | 省级地址词首 | 广|B_PRO 东|E_PRO 省|S_PRO-A |
| M_PRO | 省级地址词中 | ||
| E_PRO | 省级地址词尾 | ||
| S_PRO-A | 省级地址后缀单字词 | ||
| 市、自治州、盟 | B_CITY | 市级地址词首 | 惠|B_CITY 州|E_CITY 市|S_CITY-A |
| M_CITY | 市级地址词中 | ||
| E_CITY | 市级地址词尾 | ||
| S_CITY-A | 市级地址后缀单字词 | ||
| 区、县 | B_COUNTY | 区、县级地址词首 | 仲|B_COUNTY 恺|E_COUNTY 区|S_COUNTY-A |
| M_COUNTY | 区、县级地址词中 | ||
| E_COUNTY | 区、县级地址词尾 | ||
| S_COUNTY-A | 区、县级地址后缀单字词 | ||
| 乡、镇、街道、派出所 | B_STREET | 乡镇级地址词首 | 淡|B_STREET 水|E_STREET 街|B_STREET-A 道|M_STREET-A 办|E_STREET-A |
| M_STREET | 乡镇级地址词中 | ||
| E_STREET | 乡镇级地址词尾 | ||
| S_ STREET -A | 乡镇级地址后缀单字词 | ||
| B_STREET-A | 乡镇级地址后缀词首 | ||
| M_STREET-A | 乡镇级地址后缀词中 | ||
| E_STREET-A | 乡镇级地址后缀词尾 | ||
| 村、社区 | B_COM | 村级地址词首 | 河|B_COM 背|E_COM 村|B_COM-A 民|M_COM-A 委|M_COM-A 员|M_COM-A 会|E_COM-A |
| M_COM | 村级地址词中 | ||
| E_COM | 村级地址词尾 | ||
| S_COM-A | 村级地址后缀单字词 | ||
| B_COM-A | 村级地址后缀词首 | ||
| M_COM-A | 村级地址后缀词中 | ||
| E_COM-A | 村级地址后缀词尾 | ||
| 街、路、巷 | B_ROAD | 街路巷地址词首 | 先|B_ROAD 烈|M_ROAD 东|E_ROAD 路|S_ROAD-A |
| M_ROAD | 街路巷地址词中 | ||
| E_ROAD | 街路巷地址词尾 | ||
| S_ROAD-A | 街路巷地址后缀单字词 | ||
| 门楼牌 | B_ML | 门楼牌地址词首 | 20|B_ML 号|E_ML |
| M_ML | 门楼牌地址词中 | ||
| E_ML | 门楼牌地址词尾 | ||
| 建筑物 | B_BUILD | 建筑物地址词首 | 国|B_BUILD 际|M_BUILD 大|M_BUILD 厦|E_BUILD |
| M_BUILD | 建筑物地址词中 | ||
| E_BUILD | 建筑物地址词尾 | ||
| 单元 | B_UNIT | 单元地址词首 | 12|B_UNIT 单|M_UNIT 元|E_UNIT |
| M_UNIT | 单元地址词中 | ||
| E_UNIT | 单元地址词尾 | ||
| 房间 | B_ROOM | 房间地址词首 | 208|B_ROOM 房|M_ROOM 间|E_ROOM |
| M_ROOM | 房间地址词中 | ||
| E_ROOM | 房间地址词尾 | ||
| 兴趣点 | B_POI | POI地址词首 | 人|B_POI 民|M_POI 医|M_POI 院|E_POI |
| M_POI | POI地址词中 | ||
| E_POI | POI地址词尾 | ||
| 方位 | B_ORI | 方位地址词首 | 附|B_ORI 近|E_ORI 前|B_ORI 方|E_ORI 旁|S_ORI |
| M_ORI | 方位地址词中 | ||
| E_ORI | 方位地址词尾 | ||
| S_ORI | 方位地址单字词 |
表4 实验环境参数Tab. 4 Parameters of the experimental environment |
| 参数 | 值 |
|---|---|
| CPU | Intel(R) Core(TM) i7-7700HQ@2.80GHZ 16G |
| GPU | NVIDIA GeForce GTX 1050 4G |
| 操作系统 | window 10 64 bits |
| 编程语言 | python |
| 深度学习框架 | Tensorflow |
表5 模型训练参数Tab. 5 Model training parameters |
| 模型参数 | 值 |
|---|---|
| 词向量维度 | 200 |
| 批处理大小(batch_size) | 128 |
| 神经网络隐藏单元数 | 100 |
| Dropout率 | 0.5 |
| 神经网络层数 | 1 |
| 初始学习率 | 0.1 |
| 优化算法 | Adam |
| epoch | 40 |
表6 模型整体分词性能Tab. 6 Overall performances of the models in word segmentation |
| 模型 | 精确率P | 召回率R | 均值F1 |
|---|---|---|---|
| CRF | 0.904 | 0.898 | 0.901 |
| LSTM | 0.893 | 0.887 | 0.890 |
| BiLSTM | 0.912 | 0.907 | 0.909 |
| BiLSTM-CRF | 0.934 | 0.929 | 0.931 |
表7 各级地址模型性能Tab. 7 Address model performances at all levels |
| 地址层级 | 均值F1 | |||
|---|---|---|---|---|
| CRF | LSTM | BiLSTM | BiLSTM-CRF | |
| 省 | 0.977 | 0.968 | 0.986 | 0.993 |
| 市 | 0.971 | 0.961 | 0.983 | 0.997 |
| 区县 | 0.950 | 0.936 | 0.958 | 0.960 |
| 乡镇街道 | 0.936 | 0.925 | 0.932 | 0.942 |
| 村 | 0.915 | 0.906 | 0.914 | 0.922 |
| 街路巷 | 0.896 | 0.888 | 0.902 | 0.907 |
| 门楼牌 | 0.902 | 0.893 | 0.900 | 0.913 |
| 建筑物 | 0.897 | 0.879 | 0.911 | 0.918 |
| 单元 | 0.928 | 0.925 | 0.931 | 0.935 |
| 房间 | 0.918 | 0.910 | 0.915 | 0.919 |
| 兴趣点 | 0.873 | 0.857 | 0.877 | 0.905 |
| 方位 | 0.921 | 0.913 | 0.932 | 0.961 |
| [1] |
张文豪, 卢山, 程光 . 基于LSTM网络的中文地址分词法的设计与实现[J]. 计算机应用研究, 2018,35(12):1-2.
[
|
| [2] |
郭正斌, 张仰森 . 基于定长序列的双向LSTM分词优化方法[J]. 郑州大学学报(理学版), 2018,50(2):97-101.
[
|
| [3] |
莫建文, 郑阳, 首照宇 , 等. 改进的基于词典的中文分词方法[J]. 计算机工程与设计, 2013,34(5):1802-1807.
[
|
| [4] |
褚颖娜, 廖敏, 宋继华 . 一种基于统计的分词标注一体化方法[J]. 计算机系统应用, 2009,18(12):55-58.
[
|
| [5] |
|
| [6] |
蒋建洪, 赵嵩正, 罗玫 . 词典与统计方法结合的中文分词模型研究及应用[J]. 计算机工程与设计, 2012,33(1):387-391.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
张雪英, 闾国年, 李伯秋 , 等. 基于规则的中文地址要素解析方法[J]. 地球信息科学学报, 2010,12(1):9-16.
[
|
| [19] |
余靖毅, 邬伦, 高勇 . 基于Storm的地理编码引擎[J]. 地球信息科学学报, 2015,17(12):1431-1441.
[
|
| [20] |
赵阳阳, 王亮, 仇阿根 . 地址要素识别机制的地名地址分词算法[J]. 测绘科学, 2013,38(5):74-76.
[
|
| [21] |
应申, 李威阳, 贺彪 , 等 .统计决策树下的城市地址集中文分词[J].武汉大学学报·信息科学版, 2018(12):1-9.
[
|
| [22] |
谢婷婷, 严柯 . 基于统计的中文地址位置语义解析方法研究[J]. 软件导刊, 2017,16(10):19-21.
[
|
| [23] |
李一, 刘纪平, 罗安 . 深度学习的中文地址切分算法[J]. 测绘科学, 2018,43(10):107-111.
[
|
| [24] |
|
| [25] |
|
| [26] |
金宸, 李维华, 姬晨 , 等. 基于双向LSTM神经网络模型的中文分词[J]. 中文信息学报, 2018,32(2):29-37.
[
|
| [27] |
GB/T 23075-2009数字城市地理信息公共平台地名/地址编码规则.
[ GB/T 23075-2009 The rules of coding for address in the common platform for geospatial information service of digital city. ]
|
| [28] |
|
| [29] |
|
| [30] |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}