
基于通用知识库的地理实体开放关系过滤方法
|
高嘉良(1994-),男,山东临沂人,博士生,主要从事自然语言处理与地理知识图谱研究。E-mail:gaojl@lreis.ac.cn |
收稿日期: 2019-01-02
要求修回日期: 2019-05-23
网络出版日期: 2019-09-24
基金资助
国家自然科学基金重点项目(41631177)
版权
A Knowledge-based Method for Filtering Geo-entity Relations
Received date: 2019-01-02
Request revised date: 2019-05-23
Online published: 2019-09-24
Supported by
National Natural Science Foundation of China(41631177)
Copyright
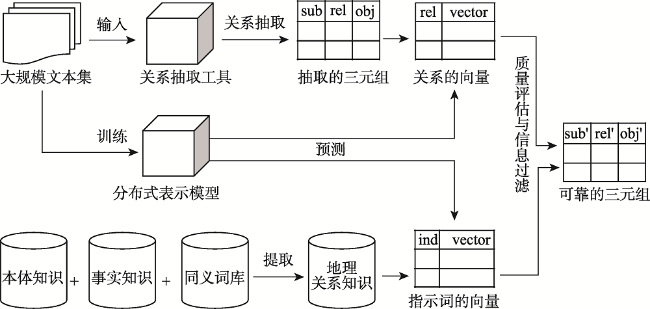
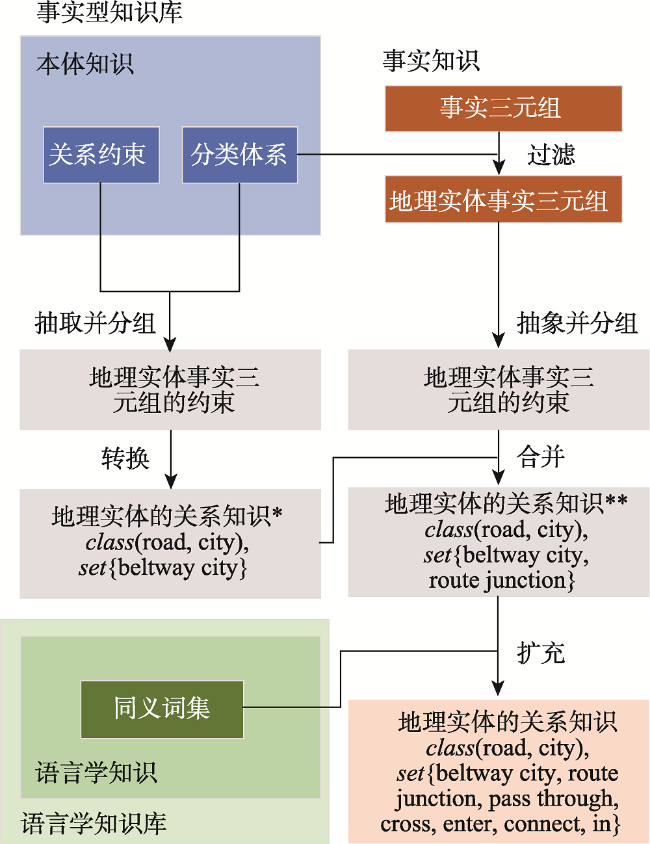
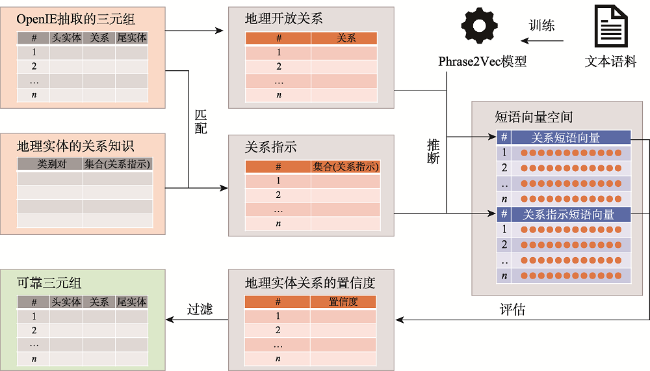
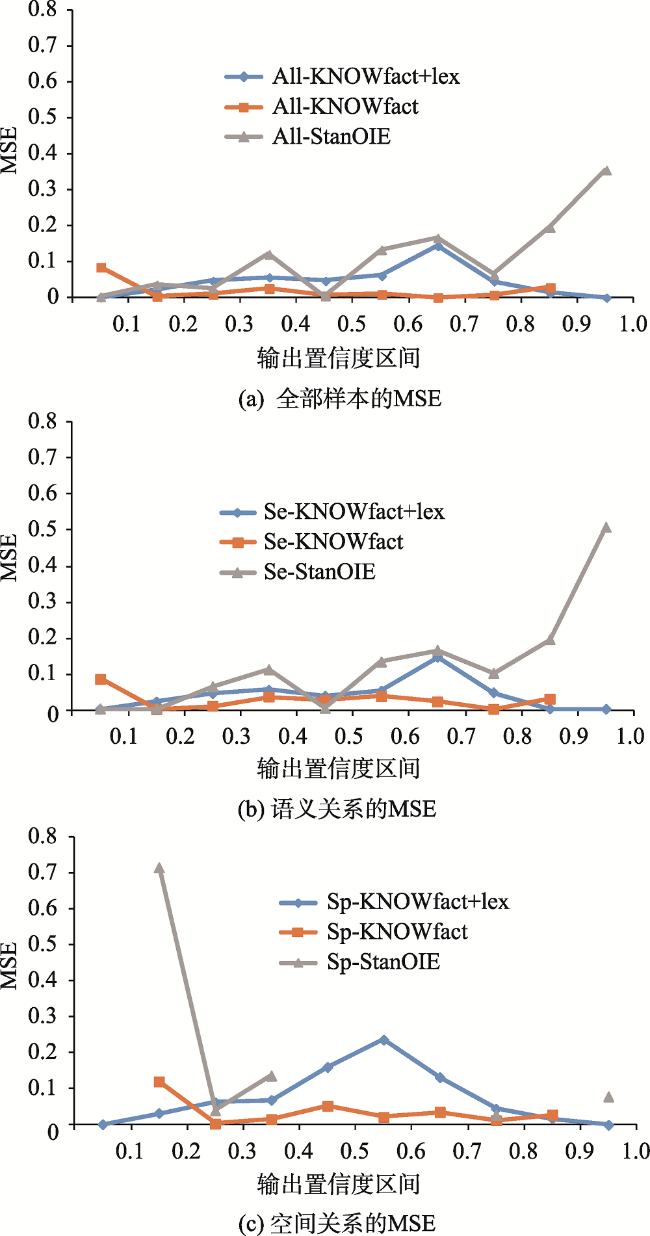
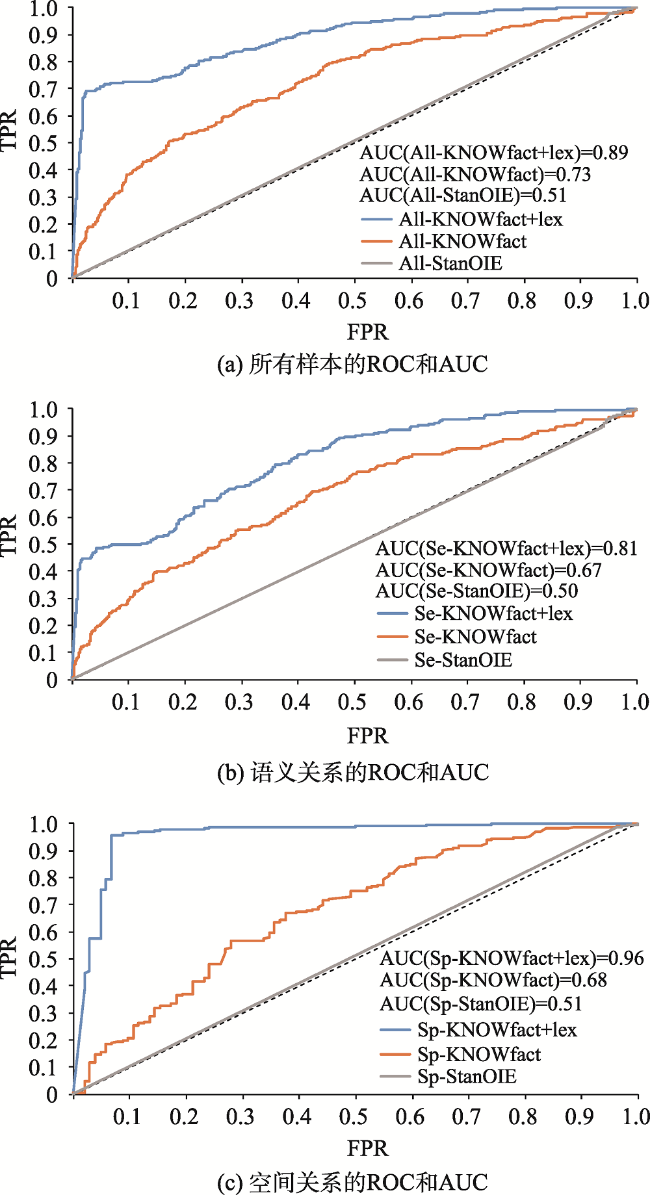
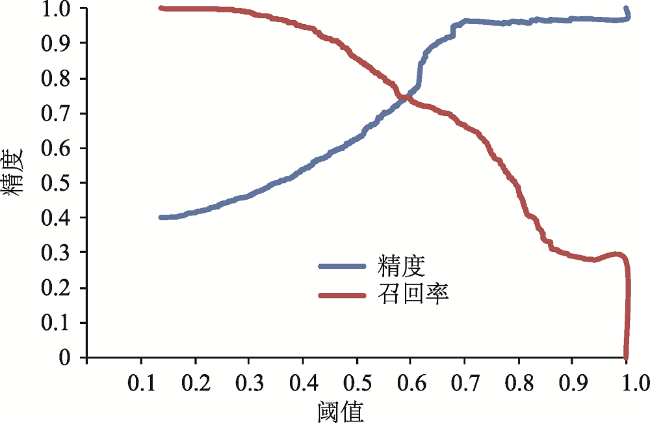
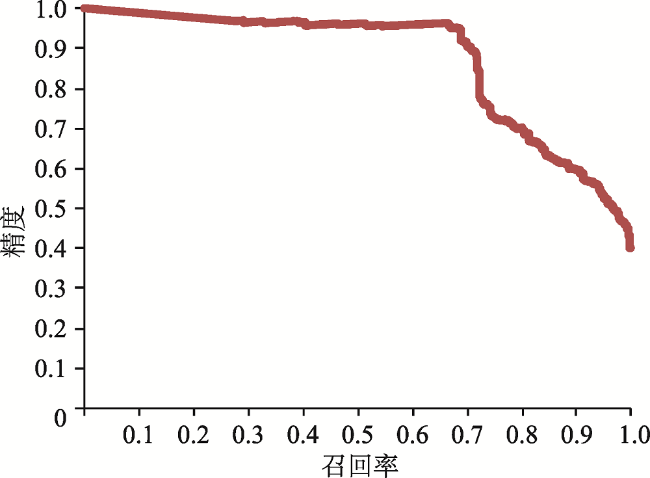
文本数据为地理知识服务提供了海量资源。面向文本数据的地理实体关系抽取是地理知识图谱构建的核心技术,直接影响地理知识推理与服务的质量。由于文本数据不可避免地含有噪声,从文本中抽取的地理实体关系需要质量评价和信息过滤。本文提出一种基于通用知识库的地理实体关系过滤方法,针对已抽取的地理实体关系从中筛选出高质量的结果:先利用“本体知识”、“事实知识”和“同义词知识”构建地理关系知识库,作为信息过滤的参照数据;再基于分布式向量表示模型度量已抽取的地理实体关系与参照数据之间的语义相似性,以提高地理知识图谱的丰度与鲜度。实验结果表明,相比业界流行的“Stanford OpenIE”工具,本文所提出的方法可将置信度区间[0, 0.2]和[0.8, 1]的MSE(Mean Square Error)从59.27%降至3.94%,AUC(Area Under the ROC Curve)从0.51提升至0.89。
高嘉良 , 余丽 , 仇培元 , 陆锋 . 基于通用知识库的地理实体开放关系过滤方法[J]. 地球信息科学学报, 2019 , 21(9) : 1392 -1401 . DOI: 10.12082/dqxxkx.2019.190005
Knowledge Graphs (KGs) are crucial resources for supporting geographical knowledge services. Given the vast geographical knowledge in web text, extraction of geo-entity relations from web text has become the core technology for constructing geographical KGs. Furthermore, it directly affects the quality of geographical knowledge services. However, web text inevitably contains noise and geographical knowledge can be sparsely distributed, both greatly restricting the quality of geo-entity relationship extraction. Here, we proposed a method for filtering geo-entity relations based on existing Knowledge Bases (KBs). Specifically, ontology knowledge, fact knowledge, and synonym knowledge were integrated to generate geo-related knowledge. Then, the extracted geo-entity relationships and the geo-related knowledge were transferred into vectors, and the maximum similarity between vectors was the confidence value of one extracted geo-entity relationship triple. Our method takes full advantage of existing KBs to assess the quality of geographical information in web text, which helps improve the richness and freshness of geographical KGs. Compared with the Stanford OpenIE method, our method decreased the Mean Square Error (MSE) from 0.62 to 0.06 in the confidence interval [0.7, 1], and improved the area under the Receiver Operating Characteristic (ROC) Curve (AUC) from 0.51 to 0.89.
表1 实验设计框架Tab. 1 Experiment design schema |
| 方法 | 关系类型 | ||
|---|---|---|---|
| 所有样本 | 空间关系样本 | 语义关系样本 | |
| StanOIE | All-StanOIE | Se-StanOIE | Sp-StanOIE |
| KNOWfact | All-KNOWfact | Se-KNOWfact | Sp-KNOWfact |
| KNOWfact+lex | All-KNOWfact+lex | Se-KNOWfact+lex | Sp-KNOWfact+lex |
表2 正负例判别结果的混淆矩阵Tab. 2 Confusion matrix of the discrimination result of positive and negative examples |
| 人工标注 | 方法评价结果 | |
|---|---|---|
| 正例 | 负例 | |
| 1 | TP | FN |
| 0 | FP | TN |
表3 空间关系的预测结果Tab. 3 Percentages of the predictions for spatial relation samples (%) |
| 样本 类型 | 置信 区间 | 方法 | ||
|---|---|---|---|---|
| KNOWfact+lex | KNOWfact | StanOIE | ||
| Sp-0 | [0, 0.3) | 19.23 | 12.50 | 0.96 |
| [0.7, 1] | 6.72 | 10.57 | 98.07 | |
| Sp-1 | [0, 0.3) | 0.00 | 1.93 | 0.39 |
| [0.7, 1] | 95.75 | 20.46 | 99.62 | |
表4 语义关系的预测结果Tab. 4 Percentages of the predictions for semantic relation samples (%) |
| 样本 类型 | 置信 区间 | 方法 | ||
|---|---|---|---|---|
| KNOWfact+lex | KNOWfact | StanOIE | ||
| Se-0 | [0, 0.3) | 25.59 | 20.23 | 1.93 |
| [0.7, 1] | 0.96 | 1.10 | 95.18 | |
| Se-1 | [0, 0.3) | 2.06 | 10.69 | 1.37 |
| [0.7, 1] | 40.35 | 9.31 | 96.55 | |
表5 全部样本的预测结果Tab. 5 Percentages of the predictions for all samples (%) |
| 样本 类型 | 置信 区间 | 方法 | ||
|---|---|---|---|---|
| KNOWfact+lex | KNOWfact | StanOIE | ||
| All-0 | [0, 0.3) | 24.79 | 19.25 | 1.80 |
| [0.7, 1] | 1.68 | 2.29 | 95.54 | |
| All-1 | [0, 0.3) | 1.09 | 6.56 | 0.90 |
| [0.7, 1] | 66.48 | 14.57 | 97.99 | |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
余丽, 陆锋, 张恒才 . 网络文本蕴涵地理信息抽取:研究进展与展望[J]. 地球信息科学学报, 2015,17(2):127-134.
[
|
| [14] |
|
| [15] |
|
| [16] |
蒋盛益, 陈东沂, 庞观松 , 等. 微博信息可信度分析研究综述[J]. 图书情报工作, 2013,57(12):136-142.
[
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
徐增林, 盛泳潘, 贺丽荣 , 等, 知识图谱技术综述[J]. 电子科技大学学报, 2016,45(4):589-606.
[
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
陆锋, 余丽, 仇培元 . 论地理知识图谱[J]. 地球信息科学学报, 2017,19(6):723-734.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}