
基于联合主题特征的网络新闻文本蕴含环境污染事件检测
|
黄宗财(1992-),男,江西兴国人,硕士生,主要研究方向为地理信息抽取、时空数据挖掘与可视化研究。E-mail: 1262686237@qq.com |
收稿日期: 2019-01-21
要求修回日期: 2019-06-21
网络出版日期: 2019-10-29
基金资助
国家自然科学基金重点项目(41631177)
数字福建建设项目(闽发改网数字函)([2014]191号)
数字福建建设项目(闽发改网数字函)([2016]23号)
数字福建建设项目(闽发改网数字函)([2016]77号)
福建省科技创新平台项目(2015H2001)
版权
Detection of Environmental Pollution Events in News Corpora based on Joint Thematic Features
Received date: 2019-01-21
Request revised date: 2019-06-21
Online published: 2019-10-29
Supported by
National Natural Science Foundation of China(41631177)
Digital Fujian Construction Project([2014]191号)
Digital Fujian Construction Project([2016]23号)
Digital Fujian Construction Project([2016]77号)
Fujian Science and Technology Innovation Platform Project(2015H2001)
Copyright
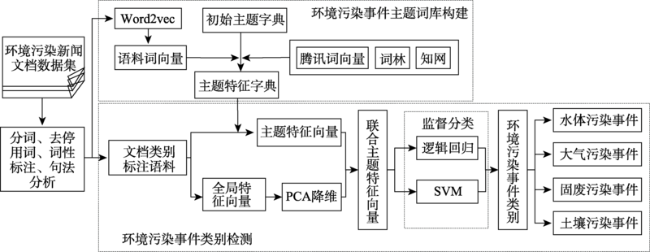
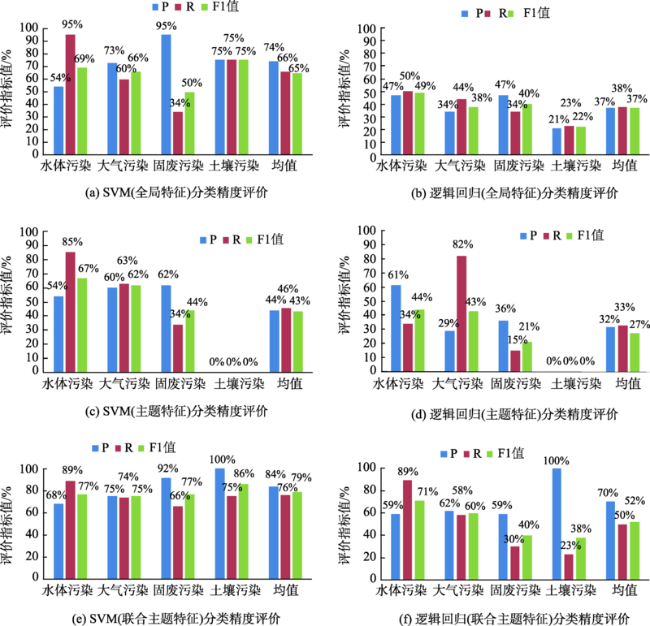
网络新闻文本在环境污染事件感知方面具有重要的应用价值。然而,由于环境污染事件的“多米诺效应”,网络新闻文本往往存在对多类型污染事件的混合描述,现有事件检测方法容易导致文本分类错误。本文提出一种基于联合主题特征的网络新闻文本蕴含环境污染事件检测方法,通过兼顾环境网络新闻文本的全局特征和主题分布特征来改善检测分类效果。该方法采用词频-逆文档频率向量对文档进行全局特征表示,并结合文档的主题分布特征向量,构建联合主题特征向量作为监督分类模型的输入,实现环境污染事件检测。实验结果表明,使用联合主题特征的支持向量机方法进行事件类别检测平均F1值相较于全局特征提高15%,相较于主题特征提高36%。本文提出的网络新闻文本蕴含环境污染事件检测方法可支持污染事件类型检测和影响信息抽取,有助于环境污染事件的时空统计与变化趋势预测。
黄宗财 , 仇培元 , 陆锋 , 吴升 . 基于联合主题特征的网络新闻文本蕴含环境污染事件检测[J]. 地球信息科学学报, 2019 , 21(10) : 1510 -1517 . DOI: 10.12082/dqxxkx.2019.190037
News have important application value in especially detecting environmental pollution event perceptions. However, due to the "domino effect" of environmental pollution incidents, news corpora often have mixed descriptions of multiple types of pollution incidents, and existing event detection methods easily lead to text classification errors. This paper proposed a new method for detecting environmental pollution events in news corpora based on joint theme features, which accounts for the global features and theme distribution characteristics. In this method, a joint topic feature vector,which combines TF-IDF (Term Frequency-Inverse Document Frequency) and theme distribution feature vector of the document, is constructed as the input of the supervised classification model to detect environmental pollution events. Using joint topic feature vector as the input of SVM (Support Vector Machine) method, the experimental results show that the average F1 value of event classification detection was 15% higher than that of global feature and 36% higher than that of topic feature.Our findings suggest that the proposed method supports the detection of pollution event types and the extraction of information and helps reveal their spatiotemporal statistical characteristics and the temporal trends.
表1 初始主题词及其扩展词Tab. 1 Initial thesaurus and its extensions |
| 初始主题词 | 扩展主题词 |
|---|---|
| 粉尘 | 污垢、烟尘、浮灰、沙尘、尘埃、灰尘、纤尘、火山灰、宇宙尘、灰原子尘、煤灰、烬、烟灰、藏污纳垢、污痕、粉煤灰、尘、秽土、浮尘、尘烟、埃、炮灰、污、黄尘、垢、尘垢、泥垢、灰渣、尘暴、污渍、油垢、污秽、污点、垢污、灰烬、油泥、浮土、肮脏、灰土、香灰、油污、矿尘、污浊、黄埃、炉灰、水垢、风尘、飘尘、粉尘、煤尘、尘土、煤尘、飘落、带起、粉尘 |
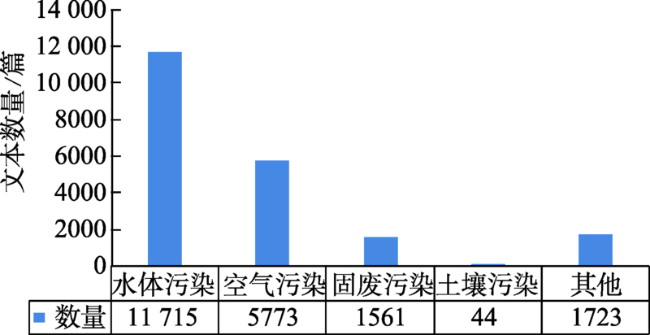
表2 1996-2018年城市环境污染事件新闻数量Top12Tab. 2 Top12 Number of news on urban environmental pollution events during 1996-2018 |
| 城市 | 新闻数量/篇 | 城市 | 新闻数量/篇 |
|---|---|---|---|
| 北京 | 1017 | 香港 | 70 |
| 上海 | 331 | 天津 | 60 |
| 广州 | 203 | 杭州 | 59 |
| 深圳 | 158 | 成都 | 53 |
| 南京 | 136 | 福岛 | 51 |
| 重庆 | 78 | 西安 | 46 |
| [1] |
但德忠 . 我国环境监测技术的现状与发展[J]. 中国测试技术, 2005,31(5):1-5.
[
|
| [2] |
余丽, 陆锋, 张恒才 . 网络新闻文本蕴涵地理信息抽取:研究进展与展望[J]. 地球信息科学学报, 2015,17(2):127-134.
[
|
| [3] |
韩雪华, 王卷乐, 卜坤 , 等. 基于Web文本的灾害事件信息获取进展[J]. 地球信息科学学报, 2018,20(8):1037-1046.
[
|
| [4] |
梁晗, 陈群秀, 吴平博 . 基于事件框架的信息抽取系统[J]. 中文信息学报, 2006,20(2):40-46.
[
|
| [5] |
杨腾飞, 解吉波, 李振宇 , 等. 微博中蕴含台风灾害损失信息识别和分类方法[J]. 地球信息科学学报, 2018,20(7):906-917.
[
|
| [6] |
张仲华, 苏方方, 姬东鸿 . 生物医学事件触发词识别研究[J]. 计算机应用研究, 2017,34(3):661-664.
[
|
| [7] |
仇培元, 张恒才, 余丽 , 等. 微博客蕴含交通事件信息抽取的自动标注方法[J]. 中文信息学报, 2017,31(2):107-116.
[
|
| [8] |
李江龙, 吕学强, 周建设 , 等. 金融领域的事件句抽取[J]. 计算机应用研究, 2017(10):2915-2918.
[
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
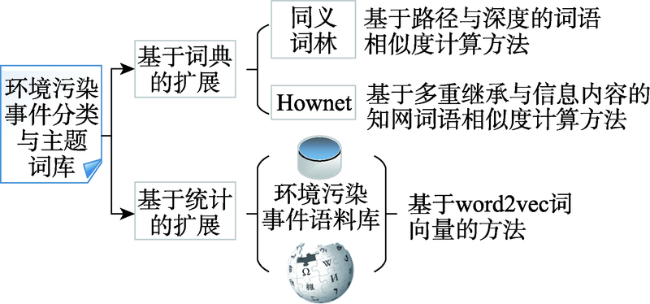
陈宏朝, 李飞, 朱新华 , 等. 基于路径与深度的同义词词林词语相似度计算[J]. 中文信息学报, 2016,30(5):80-88.
[
|
| [19] |
张波, 陈宏朝, 朱新华 , 等. 基于多重继承与信息内容的知网词语相似度计算[J]. 计算机应用研究, 2018(10):2975-2979.
[
|
| [20] |
|
| [21] |
|
| [22] |
张春菊, 张雪英, 王曙 , 等. 中文文本的事件时空信息标注[J]. 中文信息学报, 2016,30(3):213-222.
[
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}