
基于特征压缩激活Unet网络的建筑物提取
|
刘 浩(1995-),男,湖南常德人,硕士生,研究方向为遥感图像信息提取。 E-mail: liuhao@radi.ac.cn |
收稿日期: 2019-06-09
要求修回日期: 2019-08-12
网络出版日期: 2019-12-11
基金资助
国家自然科学基金项目(No.41631179)
浙江省自然科学基金(No.LQ19D010006)
国家重点研发计划项目(No.2017YFB0503600)
版权
Building Extraction based on SE-Unet
Received date: 2019-06-09
Request revised date: 2019-08-12
Online published: 2019-12-11
Supported by
National Natural Science Foundation of China(No.41631179)
Zhejiang Provincial Natural Science Foundation of China(No.LQ19D010006)
National Key Research and Development Program of China(No.2017YFB0503600)
Copyright
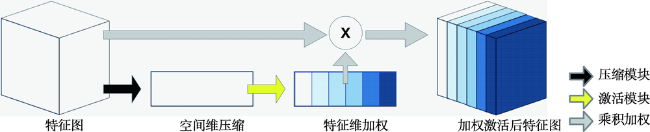
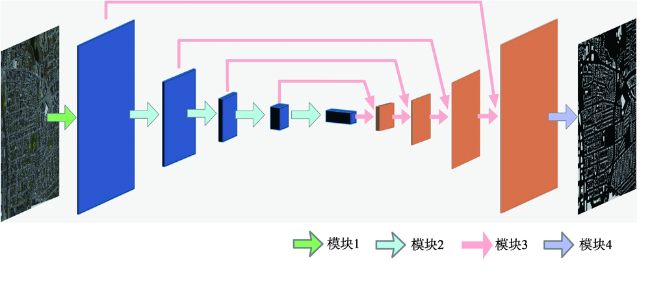
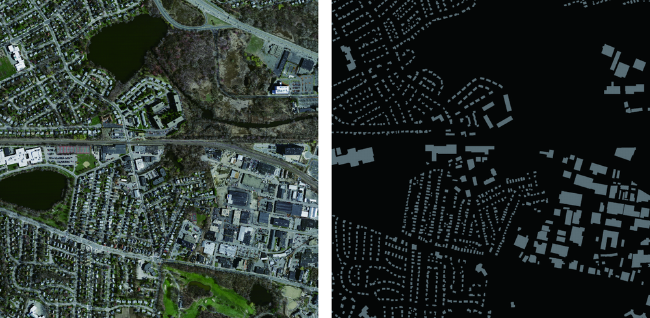
自动提取城市建筑物对城市规划、防灾避险等行业应用具有重要意义,当前利用高空间分辨率遥感影像进行建筑物提取的卷积神经网络在网络结构和损失函数上都存在提升的空间。本研究提出一种卷积神经网络SE-Unet,以U-Net网络结构为基础,在编码器内使用特征压缩激活模块增加网络特征学习能力,在解码器中复用编码器中相应尺度的特征实现空间信息的恢复;并使用dice和交叉熵函数复合的损失函数进行训练,减轻了建筑物提取任务中的样本不平衡问题。实验采用了Massachusetts建筑物数据集,和SegNet、LinkNet、U-Net等模型进行对比,实验中SE-Unet在准确度、召回率、F1分数和总体精度 4项精度指标中表现最优,分别达到0.8704、0.8496、0.8599、0.9472,在测试影像中对大小各异和形状不规则的建筑物具有更好的识别效果。
关键词: 高空间分辨率遥感影像; Massachusetts建筑物数据集; 建筑物提取; 深度学习; 卷积神经网络; SE-Unet; 损失函数
刘浩 , 骆剑承 , 黄波 , 杨海平 , 胡晓东 , 徐楠 , 夏列钢 . 基于特征压缩激活Unet网络的建筑物提取[J]. 地球信息科学学报, 2019 , 21(11) : 1779 -1789 . DOI: 10.12082/dqxxkx.2019.190285
Automatic extraction of urban buildings has great importance in applications like urban planning and disaster prevention. In this regard, high-resolution remote sensing imagery contain sufficient information and are ideal data for precise extraction. Traditional approaches (excluding visual interpretation) demand researchers to manually design features to describe buildings and distinguishing them from other objects. Unfortunately, the complexity in high-resolution imagery makes these features fragile due to the change of sensors, imaging conditions, and locations. Recently, the convolutional neural networks, which succeeded in many visual applications including image segmentation, were used to extract buildings in high spatial resolution remote sensing imagery and achieved desirable results. However, convolutional neural networks still have much to improve regarding especially network architecture and loss functions. This paper proposed a convolutional neural network SE-Unet. It is based on U-Net architecture and employs squeeze-and-excitation modules in its encoder. The squeeze-and-excitation modules activate useful features and deactivate useless features in an adaptively weighted manner, which can remarkably increase network capacity with only a few extra parameters and memory cost. The decoder of SE-Unet concatenates corresponding features in the encoder to recover spatial information, as the U-Net does. Dice and cross-entropy loss function was applied to train the network and successfully alleviated the sample imbalance problem in building extraction. All experiments were performed on the Massachusetts building dataset for evaluation. Comparing to SegNet, LinkNet, U-Net, and other networks, SE-Unet showed the best results in all evaluation metrics, achieving 0.8704, 0.8496, 0.8599, and 0.9472 in terms of precision, recall, F1-score, and overall accuracy, respectively. Also, SE-Unet presented even better precision in extracting buildings that vary in size and shape. Our findings prove that squeeze-and-excitation modules can effectively strengthen network capability, and that dice and cross-entropy loss function can be useful in other sample imbalanced situations that involve high-resolution remote sensing imagery.
表1 SE-Unet和其他网络结构对比Tab. 1 Comparison between SE-Unet and other networks |
表2 网络在Massachusetts数据集测试数据上的精度评价对比Tab. 2 Rerformance comparison of the networks on the testing set of Massachusetts building dataset |
| 网络 | 等值点 | 松弛等值点 | 精确度 | 召回率 | 分数 | 总体精度 |
|---|---|---|---|---|---|---|
| Mnih[19] | - | 0.9211 | - | - | - | 0.7638 |
| Saito [20] | - | 0.9426 | - | - | - | 0.8087 |
| HF-FCN[24] | 0.8424 | 0.9643 | - | - | - | - |
| 刘文涛[27] | - | - | - | - | - | 0.9239 |
| SegNet | 0.8095 | 0.9520 | 0.8494 | 0.7567 | 0.8004 | 0.9326 |
| SegNet* | 0.8259 | 0.9577 | 0.8306 | 0.8201 | 0.8253 | 0.9348 |
| LinkNet | 0.8131 | 0.9552 | 0.8429 | 0.7736 | 0.8068 | 0.9338 |
| LinkNet* | 0.8285 | 0.9592 | 0.8270 | 0.8307 | 0.8288 | 0.9353 |
| U-Net | 0.8513 | 0.9687 | 0.8727 | 0.8316 | 0.8370 | 0.9458 |
| U-Net* | 0.8528 | 0.9689 | 0.8636 | 0.8447 | 0.8540 | 0.9461 |
| SE-Unet | 0.8549 | 0.9701 | 0.8813 | 0.8250 | 0.8521 | 0.9468 |
| SE-Unet* | 0.8607 | 0.9710 | 0.8704 | 0.8496 | 0.8599 | 0.9472 |
注:带*表示使用dice和交叉熵复合的损失函数训练;不带*表示由交叉熵损失函数训练;-表示引用文献中缺少该指标数据。 |
| [1] |
|
| [2] |
钟燕飞, 张良培 . 遥感影像K均值聚类中的初始化方法[J]. 系统工程与电子技术, 2010,32(9):2009-2014.
[
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
方鑫, 陈善雄 . 密集城区高分辨率遥感影像建筑物提取[J].测绘通报, 2019(4):79-83.
[
|
| [7] |
|
| [8] |
陈云浩, 冯通, 史培军 , 等. 基于面向对象和规则的遥感影像分类研究[J]. 武汉大学学报·信息科学版, 2006,36(4):316-320.
[
|
| [9] |
单治彬, 孔金玲, 张永庭 , 等. 面向对象的特色农作物种植遥感调查方法研究[J]. 地球信息科学学报, 2018,20(10):1509-1519.
[
|
| [10] |
王宁, 陈方, 于博 . 基于形态学开运算的面向对象滑坡提取方法研究[J]. 遥感技术与应用, 2018,33(3):520-529.
[
|
| [11] |
张猛, 曾永年, 朱永森 . 面向对象方法的时间序列MODIS数据湿地信息提取——以洞庭湖流域为例[J]. 遥感学报, 2017,21(3):479-492.
[
|
| [12] |
林祥国, 张继贤 . 面向对象的形态学建筑物指数及其高分辨率遥感影像建筑物提取应用[J]. 测绘学报, 2017,46(6):724-733.
[
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
刘文涛, 李世华, 覃驭楚 . 基于全卷积神经网络的建筑物屋顶自动提取[J]. 地球信息科学学报, 2018,20(11):26-34.
[
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}