
基于Anchor-free的交通标志检测
|
范红超(1977— ),男,湖北襄阳人,博士,教授,主要从事众源地理信息数据挖掘与分析研究。 |
收稿日期: 2019-08-05
要求修回日期: 2019-11-27
网络出版日期: 2020-04-08
基金资助
国家自然科学基金项目(41771484)
版权
Anchor-Free Traffic Sign Detection
Received date: 2019-08-05
Request revised date: 2019-11-27
Online published: 2020-04-08
Supported by
National Natural Science Foundation of China(41771484)
Copyright
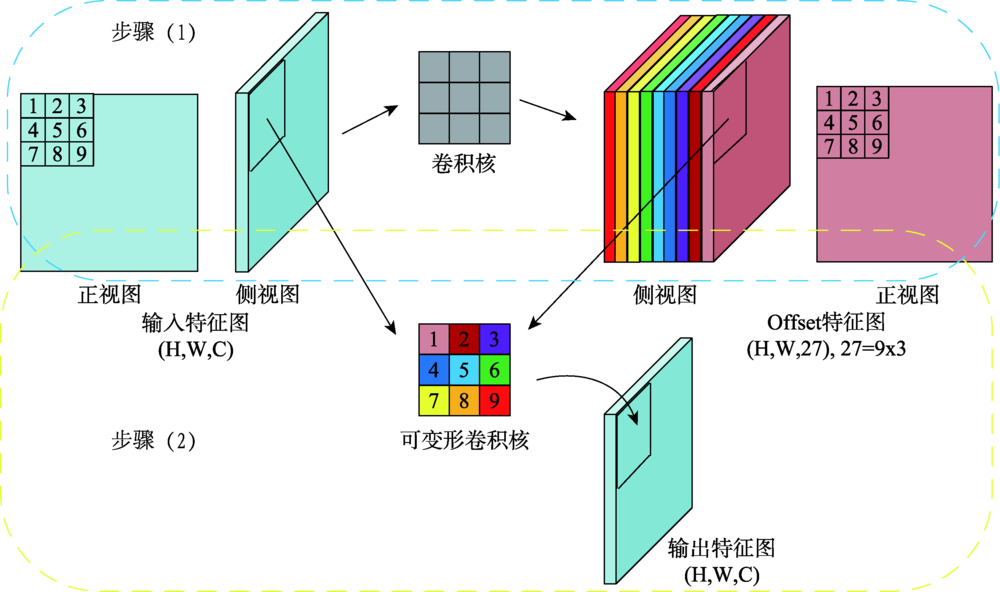
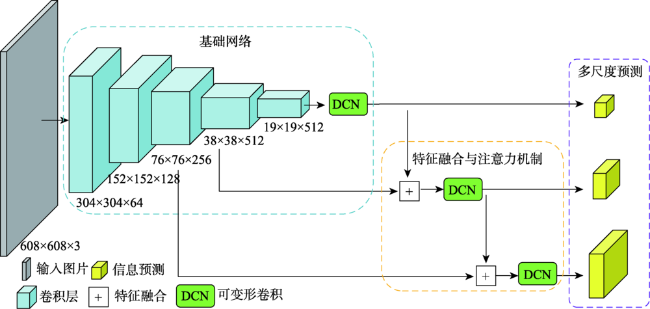
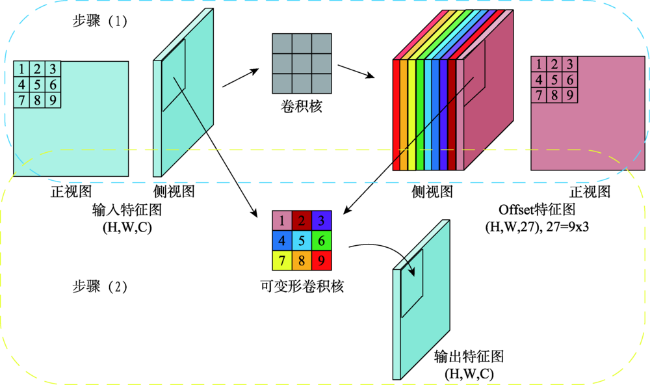
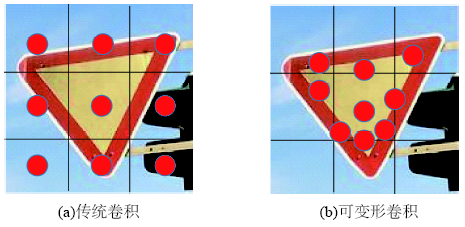
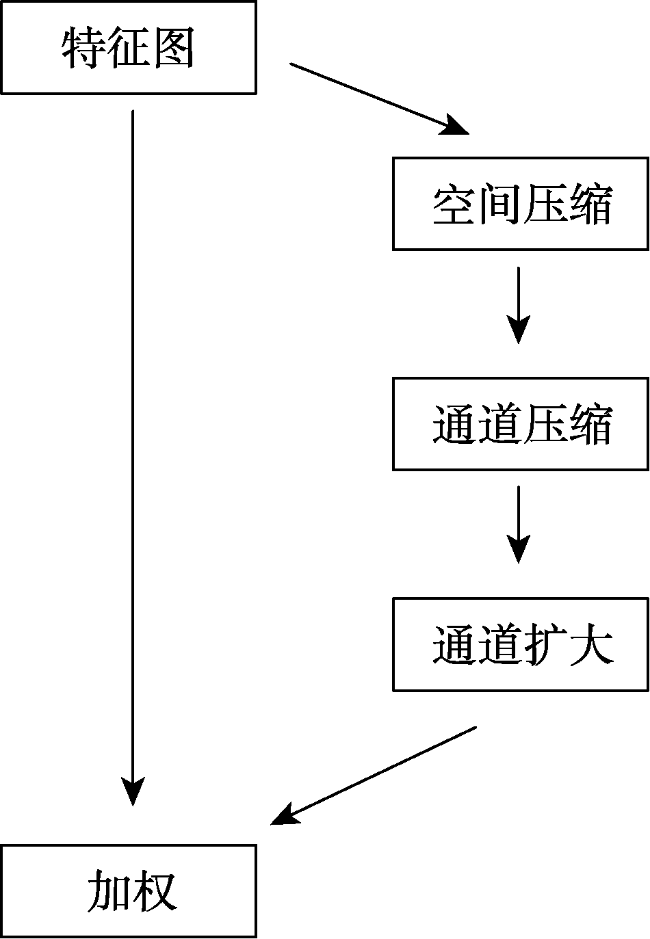
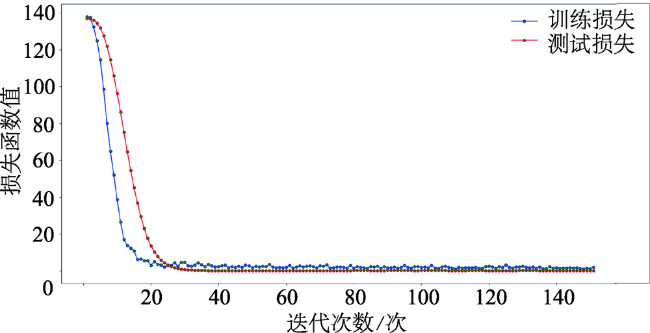
交通标志检测是自动驾驶中的重要研究方向,实时准确地从街景图像中检测交通标志对实现自动驾驶及智慧城市的发展具有重要意义。传统的算法基于颜色、形状特征进行检测,只能提取特定种类的交通标志,算法无法同时检测不同类型的交通标志。基于图像特征+机器学习分类器的算法需要人工设计特征,算法速度较慢。主流的基于深度学习的方法多基于先验框,在网络设计上引入了额外的超参数,且在训练过程中产生过量的冗余边界框,容易造成正负样本不平衡。本文受Anchor-free思想的启发,引用YOLO检测器直接回归物体边界框的思路,提出一种基于Anchor-free的实时交通标志检测网络AF-TSD(Anchor-free Traffic Sign Detection)。AF-TSD摒弃了先验框的设计,并引入自适应采样位置可变卷积与注意力机制,大大提高网络的特征表达能力。本文开展大量对比实验,实验结果表明本文提出的AF-TSD交通标志检测网络速度接近主流算法,但精度优于主流算法,在德国GTSDB交通标志检测数据集上取得了96.80%的精度,检测速度平均单张图片32 ms,达到实时检测的要求。
范红超 , 李万志 , 章超权 . 基于Anchor-free的交通标志检测[J]. 地球信息科学学报, 2020 , 22(1) : 88 -99 . DOI: 10.12082/dqxxkx.2020.190424
Traffic signs are essential elements in High Definition (HD) maps and hence very important for vehicles in autonomous driving. Real-time and accurate detection of traffic signs from street level images is of great significance for the development of autonomous driving. Conventional algorithms detect traffic signs based on image color and shape features, and can only work for specific kinds of traffic signs. Algorithms based on image feature and machine learning classifier need artificial designed features, and the detection speed is slow. To date, many approaches using deep learning methods have been developed based on anchor boxes, which introduce extra hyper parameters in network design. When switching to a different detection task, anchor boxes need to be redesigned. Anchor-based methods also generate massive redundant anchor boxes during model training, which easily cause imbalance between positive and negative samples. Inspired by the idea of anchor-free and YOLO, this paper proposed a real-time traffic sign detection network called AF-TSD, which regresses object boundary directly. AF-TSD adopts an effective convolution module named deformable convolution to enhance the feature expression ability of convolutional neural networks. This module adds 2D offsets to the regular grid sampling locations in the standard convolution. It also modulates input feature amplitudes from different spatial locations/bins. Both the offsets and amplitudes are learned from the preceding feature maps, via additional convolutional layers. In addition, AF-TSD introduces attention mechanism. It is inserted after fusion of the feature pyramid, and adaptively recalibrates channel-wise feature responses by explicitly modeling the interdependencies between channels. This module first squeezes global spatial information into a channel descriptor. Then the excitation operator maps the input-specific descriptor to a set of channel weights. The attention mechanism in this paper is lightweight and imposes only a slight increase in model complexity and computational burden. To test the superiority of AF-TSD, extensive comparative experiments were carried out. We first evaluated the influence of different modules on detection precision. The experimental results show that the deformable convolution and attention mechanism can help extract features of traffic signs. Then, AF-TSD was compared with mainstream detection networks, including Faster R-CNN, RetinaNet, and YOLOv3. Our proposed AF-TSD traffic sign detection network achieved 96.80% of mAP on GTSDB traffic sign detection dataset, which was superior to mainstream detection algorithms. The average detection speed was 32ms per images, which can meet the requirements of real-time detection.

表1 AF-TSD网络结构设计对比Tab 1 Comparison of network structure designs in AF-TSD |
| 基础网络 | 输入图像尺寸 | mAP/% |
|---|---|---|
| VGG | 95.40 | |
| VGG-DCN | 96.29 | |
| VGG-DCN-Attention | 96.80 | |
| VGG-Attention | 96.02 |
表2 AF-TSD与Faster R-CNN、RetinaNet、YOLOv3及YOLOv3(Anchor-free)之间的性能对比Tab. 2 Performance comparison of AF-TSD with Faster R-CNN, RetinaNet, YOLOv3, and YOLOve (Anchor-free) |
| 方法 | 输入图像尺寸像元×像元 | mAP/% | s/每张图 |
|---|---|---|---|
| Faster R-CNN | 88.50 | 0.120 | |
| RetinaNet | 92.43 | 0.094 | |
| YOLOv3 | 93.54 | 0.024 | |
| YOLOv3(Anchor-free) | 94.92 | 0.026 | |
| AF-TSD | 96.80 | 0.032 |
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
徐迪红, 唐炉亮 . 基于颜色和标志边缘特征的交通标志检测[J]. 武汉大学学报·信息科学版, 2008,33(4):433-436.
[
|
| [5] |
张静, 何明一, 戴玉超 , 等. 多特征融合的圆形交通标志检测[J]. 模式识别与人工智能, 2011,24(2):226-232.
[
|
| [6] |
贾永红, 胡志雄, 周明婷 , 等. 自然场景下三角形交通标志的检测与识别[J]. 应用科学学报, 2014,32(4):423-426.
[
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
http://benchmark.ini.rub.de/?section=gtsdb&subsection=news
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}