
基于街景影像多特征融合的广州市越秀区街道空间品质评估
|
崔 成(1995— ),男,河北保定人,硕士生,研究方向为空间数据挖掘。E-mail: cuic@lreis.ac.cn |
收稿日期: 2020-02-11
要求修回日期: 2020-03-20
网络出版日期: 2020-08-25
基金资助
国家自然科学基金项目(41571158)
国家重点研发计划项目(2016YFC1302602)
版权
Street Space Quality Evaluation in Yuexiu District of Guangzhou City based on Multi-feature Fusion of Street View Imagery
Received date: 2020-02-11
Request revised date: 2020-03-20
Online published: 2020-08-25
Supported by
National Natural Science Foundation of China(41571158)
National Key Research and Development Program of China(2016YFC1302602)
Copyright
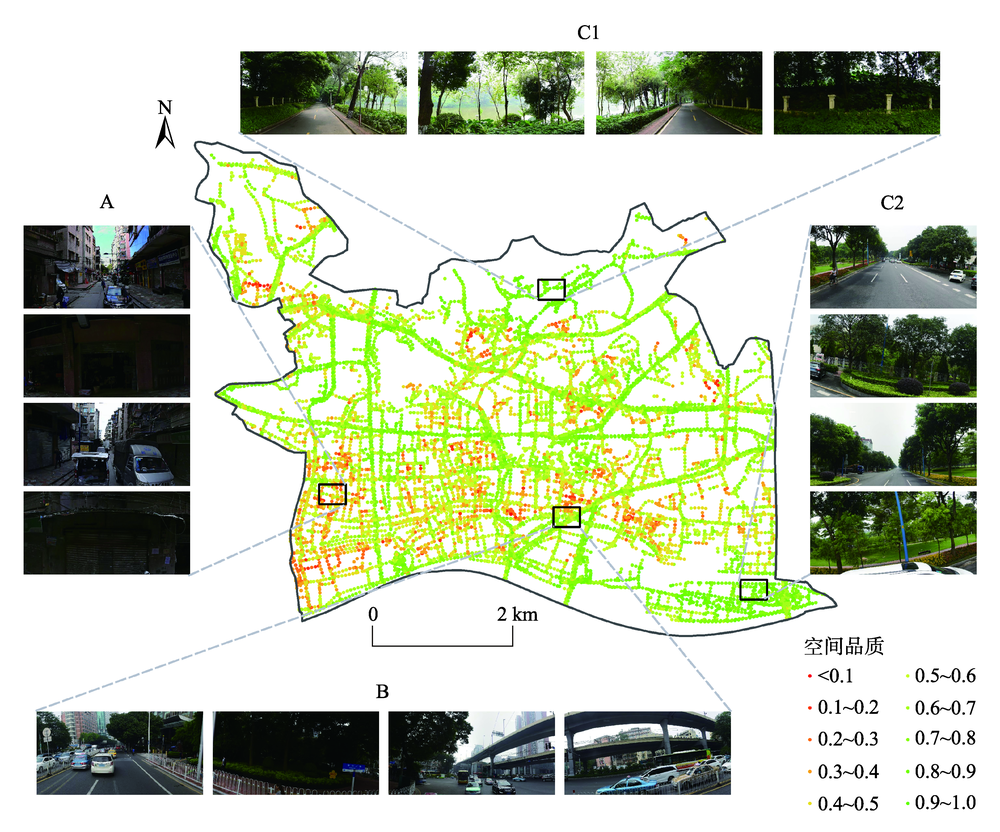
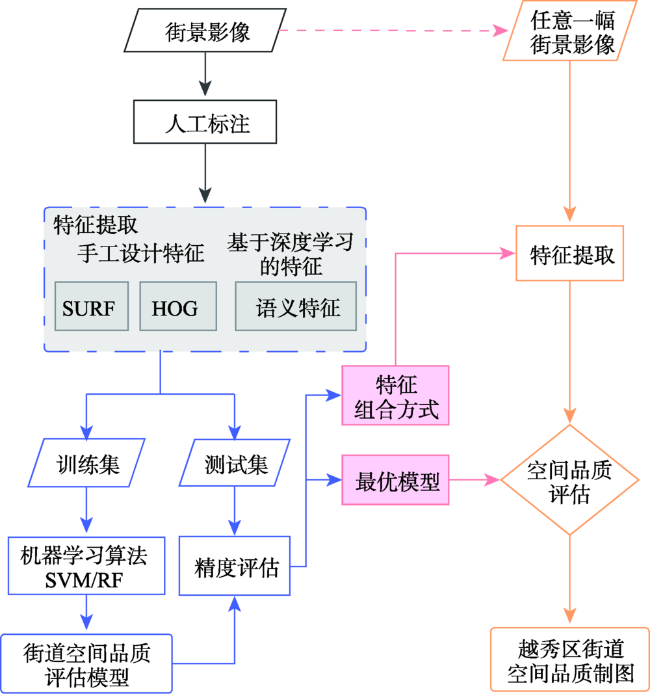
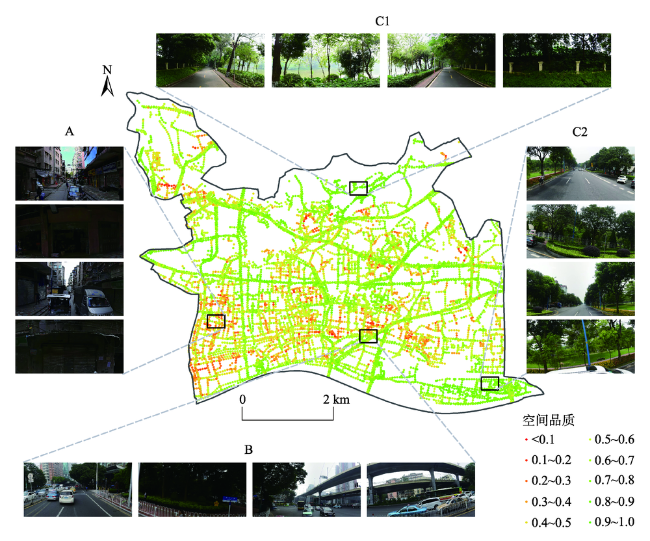
全面准确地描述街景影像的多层次特征在基于街景影像对街道空间品质进行评估的研究中具有重要意义。以广州市越秀区为例,获取前后左右各视角街景影像中手工设计的特征(SURF特征、HOG特征)和基于深度学习的特征(语义特征),基于单一特征和多特征融合采用支持向量机(Support Vector Machine, SVM)、随机森林(Random Forest, RF)训练各视角的评估模型。结果表明,以基于SVM建立的单特征模型为例,基于HOG特征(73.03%)、语义特征(72.28%)的模型平均精度优于SURF特征(56.00%),基于SVM前后左右各视角模型的最优分类精度为82.8%(前)、81.7%(后)、76.6%(左)、76.6%(右),而基于RF各视角模型的最优分类精度为82.8%(前)、85.0%(后)、78.1%(左)、70.3%(右)。前后视角的模型精度略优于左右视角。各视角最优模型均为多特征融合模型,最优模型平均分类精度和Kappa系数可达80.6%和0.62。利用街景影像评估街道空间品质时,各算法之间性能差异微弱,而特征选择及组合方式是提升精度的关键。越秀区街道空间品质存在明显空间分异,其西南部的街道空间品质亟待提升。本研究构建了基于街景影像多特征融合的大规模高精度街道空间品质测度方法,实现了对越秀区街道空间品质的评估,研究结果可为相关部门进行街道环境综合整治提供参考。
崔成 , 任红艳 , 赵璐 , 庄大方 . 基于街景影像多特征融合的广州市越秀区街道空间品质评估[J]. 地球信息科学学报, 2020 , 22(6) : 1330 -1338 . DOI: 10.12082/dqxxkx.2020.200072
Street View Imagery (SVI) is one of the important data sources for the quantitative research of urban built environment. However, it is difficult to fully represent all the information with one type of feature in the SVI due to its complexity and diversity. In this paper, we proposed an effective multi-feature fusion method to evaluate the street space quality based on SVI. Taking Yuexiu district in Guangzhou city as the study area, the Baidu SVIs in the four orientations (front, behind, left, right) at the sample points were obtained. Speeded Up Robust Feature (SURF) and Histogram of Oriented Gradient (HOG) were derived from SVIs as handcrafted features. Semantic features were also derived from SVIs using ENet convolution neural network as features based on deep learning. Based on single feature and multi-feature fusion, Support Vector Machine (SVM) and Random Forest (RF) were used to train the street space quality evaluation model for the four orientations on the training set. The optimal model and the combination of features were selected according to the classification accuracy and Kappa coefficient on the test set. Results showed that: (1) The optimal classification accuracy of models based on SVM was 82.8% (front), 81.7% (behind), 76.6% (left), 76.6% (right), respectively. In the models based on single feature, the average accuracy of the models based on HOG feature (73.03%) or semantic feature (72.28%) was better than the SURF feature (56.00%). The optimal classification accuracy of the models based on RF algorithm was 82.8% (front), 85.0% (behind), 78.1% (left), 70.3% (right). (2) The accuracy of front and behind orientation model was slightly better than that of left and right orientation. The optimal models of each orientation all are multi-feature fusion models. The average classification accuracy and Kappa coefficient of these optimal evaluation models was 80.6% and 0.62, respectively. These results showed that the proposed method could achieve a high recognition performance. (3) The selection and fusion of features were more determined to the model performance when the SVI were used to evaluate the street space quality, while the performance difference between the two algorithms was small. (4) There were obvious spatial differences in the street space quality of Yuexiu district. The street space quality in the southeast of Yuexiu district needed to be improved. A large scale and high precision street space quality evaluation method was proposed based on multi-feature fusion of SVI and achieved a high recognition performance in this study. And the street space quality score in Yuexiu district was obtained. These results could provide valuable clues for local authorities to conduct comprehensive renovations of urban built environment.
表1 百度街景影像参数信息Tab. 1 Required parameters for Baidu map street view imagery |
| 参数名 | 描述 | 取值 |
|---|---|---|
| ak | 开发者密钥,通过申请获取 | 32位字符 |
| width | 图片宽度,单位为像素,范围 [10,1024] | 1024 |
| height | 图片高度,单位为像素,范围 [10,512] | 512 |
| location | 街景采样点的位置 | 采样点经纬度坐标 |
| coordtype | 街景采样点的坐标类型 | wgs84ll |
| heading | 朝向角,表示与正北方向夹角, 范围[0,360] | 平行/垂直于道路方向 |
| pitch | 俯仰角,街景相机低头的角度, 范围[0,90] | 0 |
| fov | 视场角,范围[10,360] | 90 |
注:百度街景影像数据涵盖范围不包括路宽过窄、禁止车行的道路和单位大院、门禁社区等内部道路。 |
表2 模型分类精度与Kappa系数Tab. 2 Model classification accuracy and Kappa coefficient |
| 各视角模型的分类精度/Kappa系数 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM算法 | RF算法 | ||||||||
| 前向街景 | 后向街景 | 左向街景 | 右向街景 | 前向街景 | 后向街景 | 左向街景 | 右向街景 | ||
| SURF特征 | 50.0%/0.00 | 60.0%/0.23 | 60.9%/0.22 | 53.1%/0.08 | 46.9%/-0.07 | 71.7%/0.43 | 60.9%/0.23 | 56.3%/0.13 | |
| HOG特征 | 76.6%/0.53 | 73.3%/0.46 | 70.3%/0.40 | 71.9%/0.44 | 79.7%/0.59 | 70.0%/0.39 | 73.4%/0.47 | 70.3%/0.41 | |
| 语义特征 | 75.0%/0.51 | 75.0%/0.51 | 70.3%/0.42 | 68.8%/0.38 | 81.3%/0.62 | 81.7%/0.63 | 71.9%/0.44 | 65.6%/0.32 | |
| SURF特征+HOG特征 | 68.8%/0.37 | 75.0%/0.50 | 73.4%/0.47 | 67.2%/0.35 | 76.6%/0.53 | 75.0%/0.50 | 68.8%/0.38 | 62.5%/0.25 | |
| SURF特征+语义特征 | 81.3%/0.63 | 68.3%/0.37 | 70.3%/0.41 | 70.3%/0.41 | 82.8%/0.65 | 83.8%/0.67 | 73.4%/0.47 | 57.8%/0.15 | |
| HOG特征+语义特征 | 82.8%/0.66 | 81.7%/0.63 | 76.6%/0.54 | 71.9%/0.44 | 82.8%/0.66 | 85.0%/0.70 | 78.1%/0.57 | 67.2%/0.35 | |
| SURF特征+HOG特征+语义特征 | 82.8%/0.66 | 78.3%/0.57 | 76.6%/0.54 | 76.6%/0.53 | 82.8%/0.65 | 81.7%/0.63 | 78.1%/0.57 | 62.5%/0.25 | |
注:各列加粗数值为当前列最优的分类精度和Kappa系数。 |
| [1] |
|
| [2] |
|
| [3] |
张丽英, 裴韬, 陈宜金, 等. 基于街景图像的城市环境评价研究综述[J]. 地球信息科学学报, 2019,21(1):46-58.
[
|
| [4] |
谢润桦. 基于城市街景影像的视觉定位研究[D]. 北京:北京建筑大学, 2018.
[
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
周垠, 龙瀛. 街道步行指数的大规模评价——方法改进及其成都应用[J].上海城市规划,2017(1):88-93.
[
|
| [9] |
唐婧娴, 龙瀛. 特大城市中心区街道空间品质的测度——以北京二三环和上海内环为例[J]. 规划师, 2017,33(2):68-73.
[
|
| [10] |
赵雅芝. 基于街景地图的历史文化街区街道空间品质评价[D]. 广州:广州大学, 2019.
[
|
| [11] |
叶宇, 张昭希, 张啸虎, 等. 人本尺度的街道空间品质测度——结合街景数据和新分析技术的大规模,高精度评价框架[J]. 国际城市规划, 2019,34(1):18-27.
[
|
| [12] |
|
| [13] |
甘欣悦, 佘天唯, 龙瀛. 街道建成环境中的城市非正规性基于北京老城街景图片的人工打分与机器学习相结合的识别探索[J].时代建筑,2018(1):62-68.
[
|
| [14] |
周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017,40(6):1229-1251.
[
|
| [15] |
葛芸. 基于CNN迁移特征融合与池化的高分辨率遥感图像检索研究[D]. 南昌:南昌大学, 2019.
[
|
| [16] |
彭清, 季桂树, 谢林江, 等. 卷积神经网络在车辆识别中的应用[J]. 计算机科学与探索, 2018,12(2):282-291.
[
|
| [17] |
黄冬梅, 刘佳佳, 苏诚, 等. 多特征融合的复杂环境海洋涡旋识别[J]. 中国图象图形学报, 2019,24(1):31-38.
[
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
陆波, 尉询楷, 毕笃彦. 支持向量机在分类中的应用[J]. 中国图象图形学报, 2005,10(8):1029-1035.
[
|
| [22] |
周超, 方秀琴, 吴小君, 等. 基于三种机器学习算法的山洪灾害风险评价[J]. 地球信息科学学报, 2019,21(11):1679-1688.
[
|
| [23] |
黄衍, 查伟雄. 随机森林与支持向量机分类性能比较[J]. 软件, 2012,33(6):111-114.
[
|
| [24] |
|
| [25] |
|
| [26] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}