
以节点为中心的关系边聚类与可视化算法
|
张政(1990— ),男,河南郑州人,博士生,研究方向为地理信息可视化与地理信息服务。E-mail:giser_zzy@163.com |
收稿日期: 2019-10-01
要求修回日期: 2020-03-28
网络出版日期: 2020-11-25
基金资助
国家重点研发计划项目(2016YFB0502300)
国家自然科学基金项目(41471336)
版权
Node-centered Edge Clustering and Visualization Algorithm
Received date: 2019-10-01
Request revised date: 2020-03-28
Online published: 2020-11-25
Supported by
National Key Research and Development Program of China(2016YFB0502300)
National Natural Science Foundation of China(41471336)
Copyright
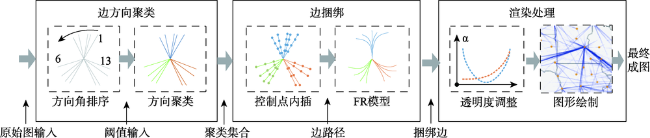
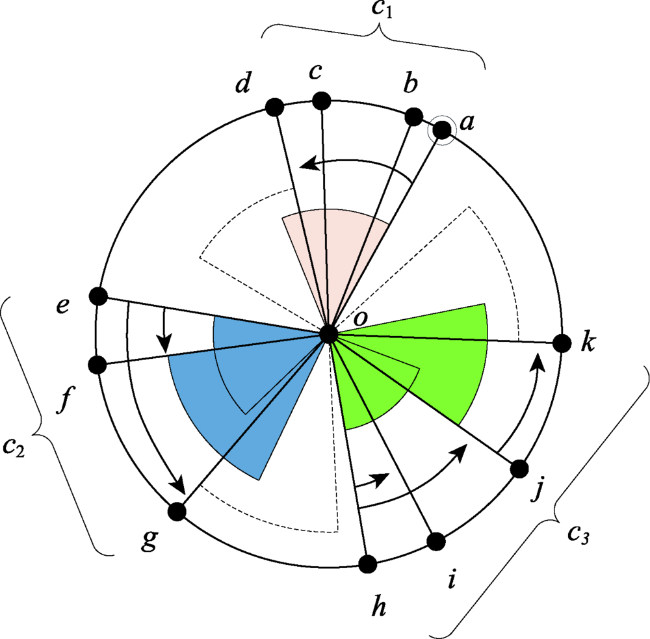
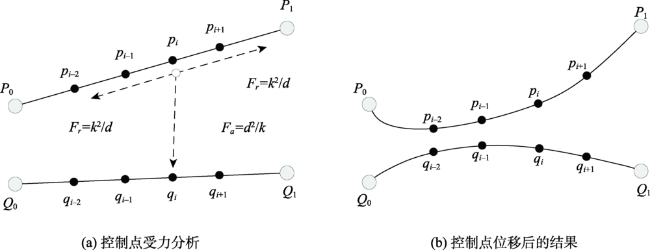
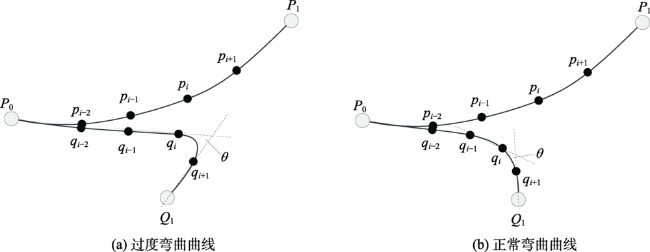
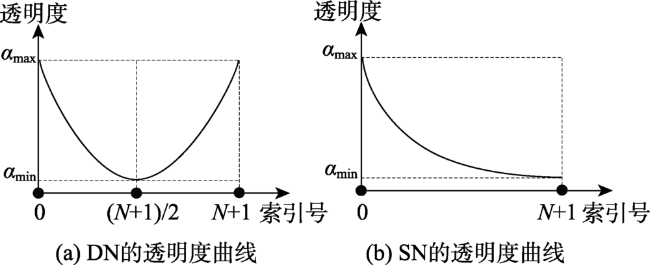
对象间的关联关系可视化主要是通过图的连边进行表达的,但是对象间的关联关系纷繁复杂,大量的连边交错会造成严重的视觉混乱,图布局和边捆绑都是解决复杂连边造成的视觉混乱问题的有效途径,然而某些节点的地理位置具有实际的含义,只能通过边捆绑方法来减少幅面载负量,进而揭示图的潜在关联规律。以往的边捆绑算法是在边的两端节点固定的前提下,调整边的中间控制点的位置,这样会使得大量边被聚集在一起,不仅会造成二次视觉混乱,且难以在节点级别揭示图的关联趋势。针对这一问题,本文提出了一种以节点为中心的关系边聚类与可视化算法。首先使用方向聚类算法实现隶属于同一个节点的连边的聚类,本文提出的方向聚类方法速度约是K-means算法的13倍,约是DBSCAN算法的6倍,然后对各个连边实现控制点的内插,在此基础上使用FR模型使得控制点位移,并通过弯曲度控制防止“过度弯曲”情况的出现,最后调整边的透明度,使得可视化的结果突出显示边靠近端点处的部分。实验结果表明,本文NCEB算法的幅面载负量L和中点距离变化量△d的约为FDEB算法的二分之一,证明本文算法可以将捆绑位置从边的中间部位移动到节点端,不仅解决了传统边捆绑算法造成的二次视觉混乱问题,而且使得节点周围的连边分布趋势清晰可读,且视觉负载大大降低,有效减少了视觉误差和信息误判。

张政 , 华一新 , 张亚军 , 曾梦熊 , 杨振凯 . 以节点为中心的关系边聚类与可视化算法[J]. 地球信息科学学报, 2020 , 22(9) : 1779 -1788 . DOI: 10.12082/dqxxkx.2020.190568
The visualization of the associative relation between objects is mainly expressed by the edges of the graph. But a large number of edges will cause serious visual confusion due to the complexity of the associative relation between objects. Graph layout and edge bundling are both effective methods to solve the problem of visual confusion caused by complex edges. While the geo-location of some nodes has significant meaning, only edge bundling methods can be used to reduce the map load and reveal the potential association rules of graph. In the past, the edge bundling algorithms adjusted the position of the middle control points of the edge under the condition that the two end nodes of the edge were fixed. This would cause a large number of edges being gathered together, which would not only cause a secondary visual confusion, but also be difficult to reveal the potential rules of the graph at the node level. To solve this problem, this paper proposed a node-centered edge clustering and visualization algorithm. Firstly, the direction clustering algorithm was used to realize the clustering of direction edges. The direction clustering method proposed in this paper was about 13 times faster than K-means algorithm, and about 6 times faster than DBSCAN algorithm. Then, the interpolation of the control points was implemented for each edge. On this basis, FR model was used to prevent the occurrence of “excessive bending”. Finally, we adjusted the transparency of the edges so that the result of the visualization would be able to highlight the portion of the edge near the end nodes. The experimental results show that the value of the NCEB algorithm's map load (L) and the mid-point distance change (△d) were about half of the FDEB algorithm, which proved that the NCEB algorithm can move the binding position from the middle part of the edge to the node, thus not only solving the secondary visual confusion caused by traditional edge bundling methods, but also revealing the association rule and trend of the graph at the node level. The final distribution trend of the edge around the node was clear and readable, and the visualization result greatly reduced the map load, which effectively reduced visual errors and misunderstanding of information. The results of our experiments show that the proposed algorithm can reveal the potential associated trend of graphs at the node level and greatly reduce visual confusion.
表1 几种方向聚类算法的结果统计Tab. 1 Statistics of the Result of the Some Direction Clustering Algorithms |
| 法名称 | 节点个数/个 | 边个数/个 | 平均聚类数/个 | 平均聚类时间/s |
|---|---|---|---|---|
| 改进K-means的边聚类算法 | 235 | 2101 | 2.208 | 15.167 |
| 改进DBSCAN的边聚类算法 | 2.979 | 6.267 | ||
| 本文边聚类算法 | 3.132 | 1.087 |
表2 力引导算法计算方案Tab. 2 Calculation scheme of force-directed algorithm |
| 迭代次数 | P | S | I |
|---|---|---|---|
| 0 | 2 | 0.05 | 60 |
| 1 | 4 | 0.025 | 40 |
| 2 | 8 | 0.0125 | 26 |
| 3 | 16 | 0.00625 | 17 |
| 4 | 32 | 0.003125 | 11 |
| 5 | 64 | 0.0015625 | 7 |
表3 算法评价实验的统计结果Tab. 3 Statistical results of the algorithm evaluation experiment |
| 数据 | 算法 | L | |
|---|---|---|---|
| 航班 | FDEB | 0.32 | 0.33 |
| 本文算法 | 0.18 | 0.12 | |
| 移民 | FDEB | 0.57 | 0.37 |
| 本文算法 | 0.29 | 0.14 |
| [1] |
华一新, 周成虎. 面向全空间信息系统的多粒度时空对象数据模型描述框架[J]. 地球信息科学学报, 2017,19(9):1142-1149.
[
|
| [2] |
张政, 华一新, 张晓楠, 等. 多粒度时空对象关联关系基本问题初探[J]. 地球信息科学学报, 2017,19(9):1158-1163.
[
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
路强, 马坤乐. 基于内容重要性边捆绑的图可视化算法[J]. 计算机辅助设计与图形学学报, 2016,28(11):1899-1905.
[
|
| [14] |
|
| [15] |
|
| [16] |
李志林, 刘启亮, 唐建波. 尺度驱动的空间聚类理论[J]. 测绘学报, 2017,46(10):1534-1548.
[
|
| [17] |
伍育红. 聚类算法综述[J]. 计算机科学, 2015,42(6A):491-499.
[
|
| [18] |
牛健平. 全国航班数据与可视化[EB/OL]. https://cloud.tencent.com/developer/article/1357025, 2018-10-23.
[
|
| [19] |
江南, 曹亚妮, 孙庆辉, 等. 双峰型基础电子地图载负量变化规律的探究[J]. 测绘学报, 2014,43(3):306-313.
[
|
| [20] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}