
基于多任务学习的高分辨率遥感影像建筑提取
|
朱盼盼(1989- ),女,河南周口人,博士生,主要从高分辨率光学遥感影像信息提取研究。E-mail: zlyxbmsl@163.com |
收稿日期: 2019-12-26
要求修回日期: 2020-04-23
网络出版日期: 2021-05-25
基金资助
国家自然科学基金项目(41371324)
版权
Multitask Learning-based Building Extraction from High-Resolution Remote Sensing Images
Received date: 2019-12-26
Request revised date: 2020-04-23
Online published: 2021-05-25
Supported by
National Natural Science Foundation of China(41371324)
Copyright
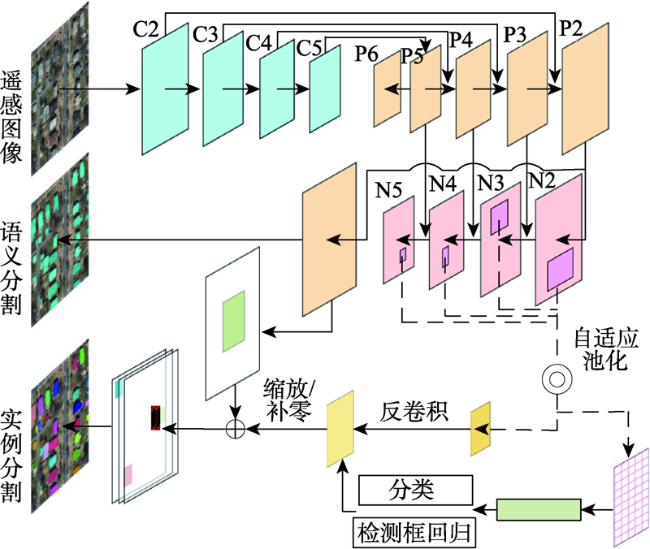
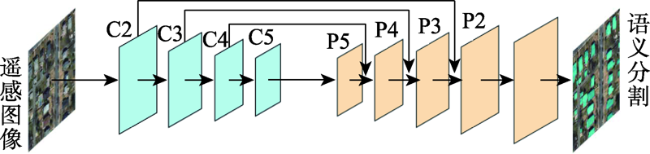
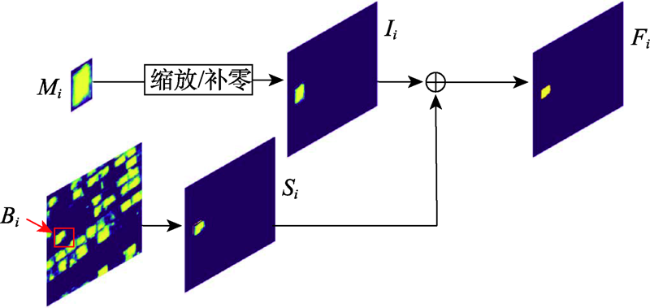
建筑物的自动提取对城市发展与规划、防灾预警等意义重大。当前的建筑物提取研究取得了很好的成果,但现有研究多把建筑提取当成语义分割问题来处理,不能区分不同的建筑个体,且在提取精度方面仍然存在提升的空间。近年来,基于多任务学习的深度学习方法已在计算机视觉领域得到广泛应用,但其在高分辨率遥感影像自动解译任务上的应用还有待进一步发展。本研究借鉴经典的实例分割算法Mask R-CNN和语义分割算法U-Net的思想,设计了一种将语义分割模块植入实例分割框架的深度神经网络结构,利用多种任务之间的信息互补性来提升模型的泛化性能。自底向上的路径增强结构缩短了低层细节信息向上传递的路径。自适应的特征池化使得实例分割网络可以充分利用多尺度信息。在多任务训练模式下完成了对遥感影像中建筑物的自动分割,并在经典的遥感影像数据集SpaceNet上对该方法进行验证。结果表明,本文提出的基于多任务学习的建筑提取方法在巴黎数据集上建筑实例分割精度达到58.8%,在喀土穆数据集上建筑实例分割精度达到60.7%,相比Mask R-CNN和U-Net提升1%~2%。
朱盼盼 , 李帅朋 , 张立强 , 李洋 . 基于多任务学习的高分辨率遥感影像建筑提取[J]. 地球信息科学学报, 2021 , 23(3) : 514 -523 . DOI: 10.12082/dqxxkx.2021.190805
Automatic extraction of buildings is of great significance to urban development and planning, and disaster prevention and early warning. Current researches on building extraction have achieved good results, but the existing research methods often take building extraction as a semantic segmentation problem and cannot distinguish different building individuals. Thus, there is still room of improvement in extraction accuracy. In recent years, deep learning methods based on multitask learning have been widely used in the field of computer vision, but its application in automatic interpretation of high-resolution remote sensing images has not yet further developed. The instance segmentation branch of Mask R-CNN is built on the basis of target detection, and can predict segmentation masks on each region of interest. However, some spatial details and the contextual information of the edge pixels of the region of interest will be lost inevitably. The semantic segmentation task can introduce more contextual information to the network. Therefore, the integration of semantic segmentation and instance segmentation tasks can improve the generalization performance of the whole network. Based on the classic instance segmentation method (Mask R-CNN) and a typical semantic segmentation method (U-Net), this research designs a deep neural network structure which embeds the semantic segmentation module into the instance segmentation framework, and improves the generalization performance of the model by using the information complementarity between various tasks. The bottom-up path augmentation structure shortens the path of lower layers’ information to pass up. The adaptive feature pooling makes it possible for instance segmentation network to make full use of multi-scale information. The automatic building segmentation of remote sensing images is performed in the multi-task training mode and the proposed method is verified on the classic remote sensing image data set (SpaceNet). The result shows that the building instance segmentation accuracy of our proposed method is 58.8% in the Paris data set and 60.7% in the Khartoum data set, increased by 1%~2% compared to individual Mask R-CNN and U-Net. The disadvantages of the proposed method are shown in two aspects, one is that the false extraction and missing extraction of small buildings are relatively high, and the other is that the accuracy of building boundary extraction needs to be improved.
表2 COCO预训练模型评测结果Tab. 2 Results on COCO dataset (%) |
| 实验组 | 平均值 | 人 | 骑手 | 汽车 | 卡车 | 公交车 | 火车 | 摩托车 | 自行车 | |
|---|---|---|---|---|---|---|---|---|---|---|
| APDET | S | 37.8 | 33.5 | 29.5 | 50.1 | 33.3 | 41.3 | 30.0 | 25.6 | 22.4 |
| M | 38.3 | 34.5 | 30.1 | 51.3 | 32.7 | 41.9 | 33.3 | 26.9 | 20.1 | |
| APMASK | S | 34.7 | 31.4 | 28.7 | 49.0 | 30.6 | 39.9 | 29.2 | 23.1 | 17.9 |
| M | 35.6 | 33.3 | 28.5 | 49.2 | 29.1 | 40.1 | 30.4 | 23.9 | 19.1 |
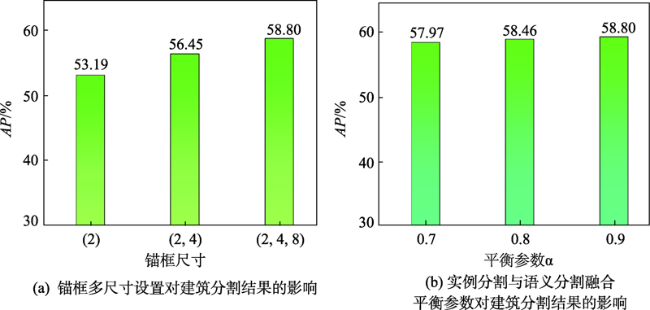
表3 SpaceNet测试集模型评估结果Tab. 3 Results on SpaceNet dataset (%) |
| 方法 | 巴黎 | 喀土穆 | |||||
|---|---|---|---|---|---|---|---|
| APDET | APSEM | APINS | APDET | APSEM | APINS | ||
| U-Net | - | 60.8 | - | - | 60.1 | - | |
| Mask R-CNN | 88.2 | - | 57.9 | 88.0 | - | 58.9 | |
| 本文的方法(S) | 88.8 | 61.3 | 58.4 | 87.6 | 59.8 | 60.7 | |
| 本文的方法(M) | 90.1 | 62.9 | 58.8 | 89.0 | 61.3 | 59.0 | |
| ALL | 91.8 | 63.4 | 60.7 | 90.6 | 62.7 | 61.5 | |
注:ALL代表将所有模型结果进行投票融合的结果。S代表测试时使用单张图像的结果值;M代表测试时使用不同角度的多张图像进行融合的结果值。APDET代表目标检测结果的AP值;APSEM代表语义分割结果的AP值;APINS代表实例分割结果的AP值。 |
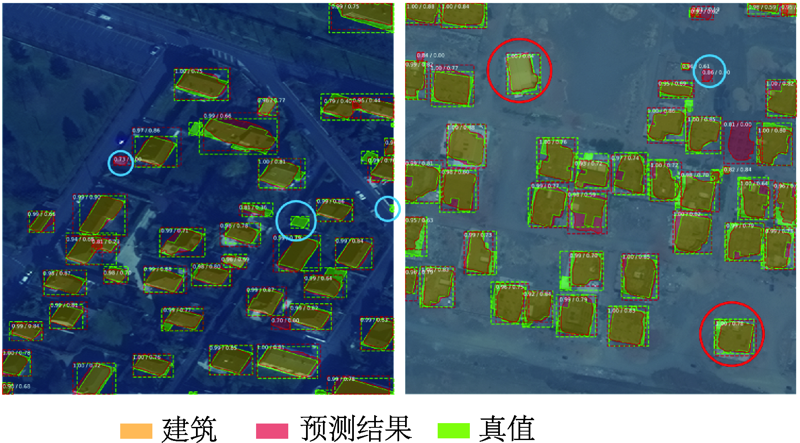
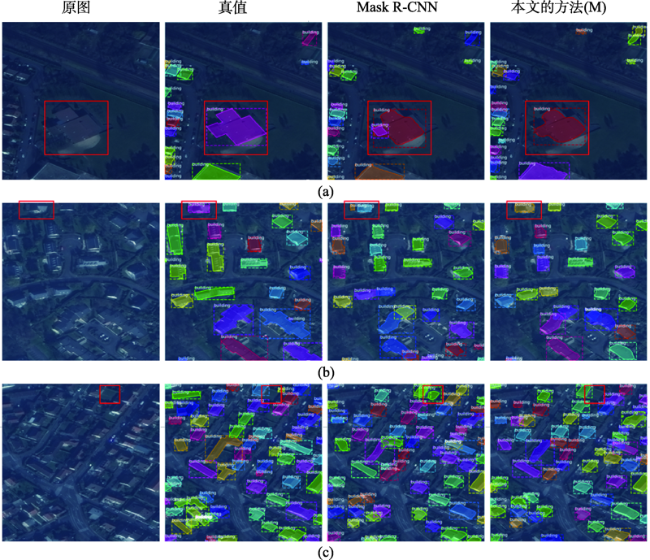
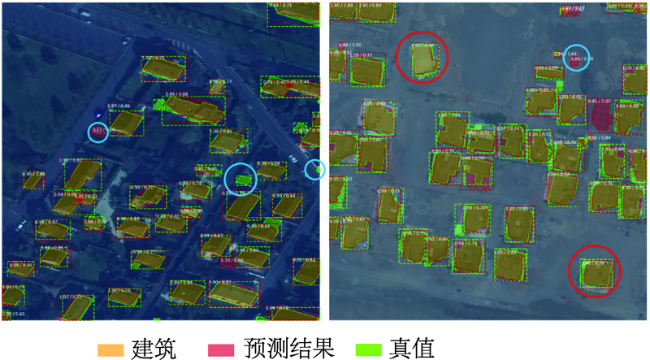
图5 巴黎数据样例建筑实例分割可视化结果注:边界框指示每栋建筑的位置,颜色块指示框内哪些像素是建筑。 Fig. 5 Visualization results of building instance segmentation of Paris data samples |
图6 喀土穆数据样例建筑实例分割可视化结果注:边界框指示每栋建筑的位置,颜色块指示框内哪些像素是建筑。 Fig. 6 Visualization results of building instance segmentation of Khartoum data samples |
| [1] |
王俊, 秦其明, 叶昕, 等. 高分辨率光学遥感图像建筑物提取研究进展[J]. 遥感技术与应用, 2016,31(4):653-662.
[
|
| [2] |
刘帆. 一种高分辨率遥感影像建筑物提取方法研究[J]. 中国新技术新产品, 2018,13(7):18-19.
[
|
| [3] |
杨安妮, 许亚辉, 苏红军. 结合建筑指数的城市建筑用地提取与变化检测分析[J]. 测绘与空间地理信息, 2014,37(8):30-34.
[
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
李青, 李玉, 王玉, 等. 利用格式塔的高分辨率遥感影像建筑物提取[J]. 中国图象图形学, 2017,22(8):1162-1174.
[
|
| [11] |
Yuan J Y.Automatic building extraction in aerial scenes using convolutional networks[J]. arXiv Preprint arXiv: 1602. 06564, 2016.
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
惠健, 秦其明, 许伟, 等. 基于多任务学习的高分辨率遥感影像建筑实例分割[J]. 北京大学学报(自然科学版), 2019,55(6):1-12.
[
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}