
基于ALBERT模型的园林植物知识实体与关系抽取方法
收稿日期: 2020-09-29
要求修回日期: 2020-12-29
网络出版日期: 2021-09-25
基金资助
国家自然科学基金项目(41971344)
版权
Extracting Entity and Relation of Landscape Plant's Knowledge based on ALBERT Model
Received date: 2020-09-29
Request revised date: 2020-12-29
Online published: 2021-09-25
Supported by
National Natural Science Foundation of China, No.41971344.(41971344)
Copyright
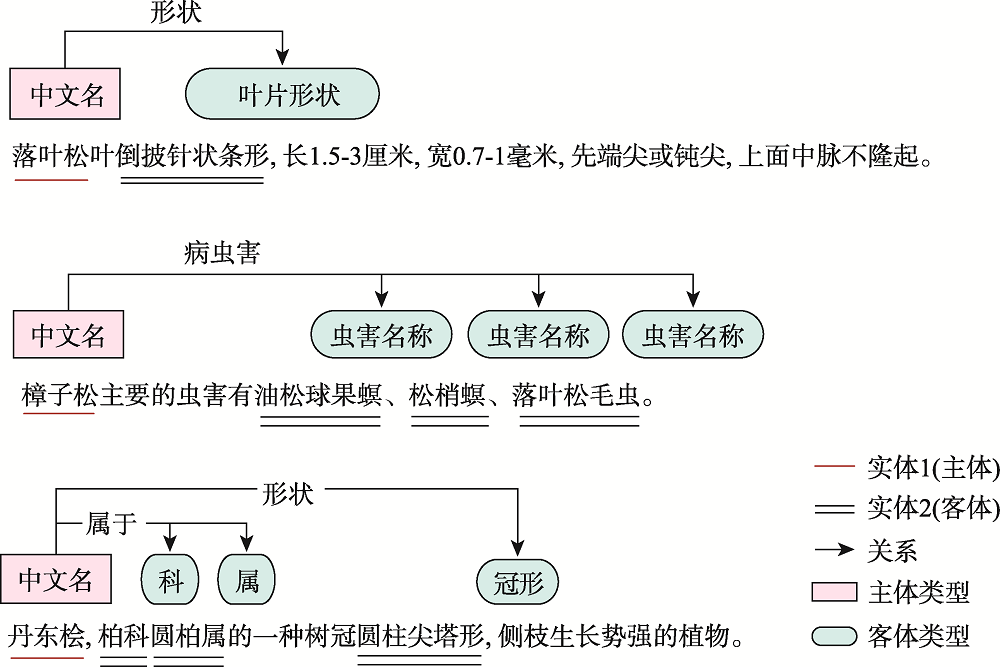
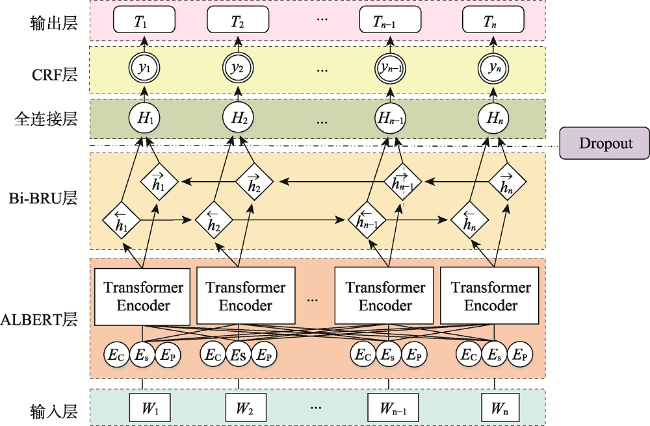
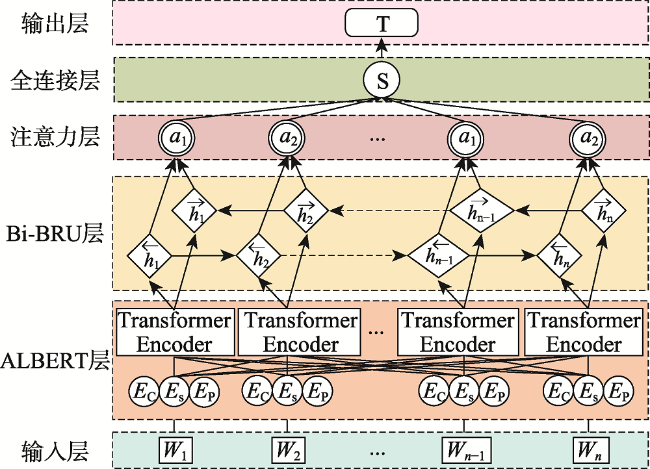
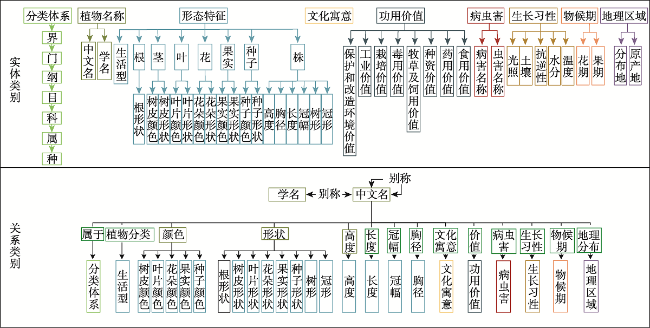
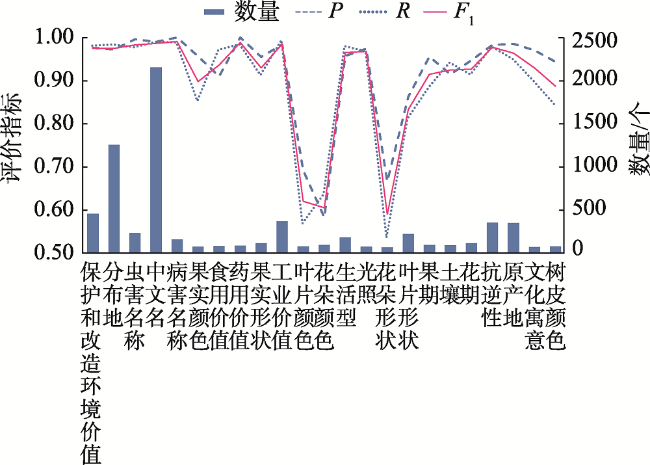
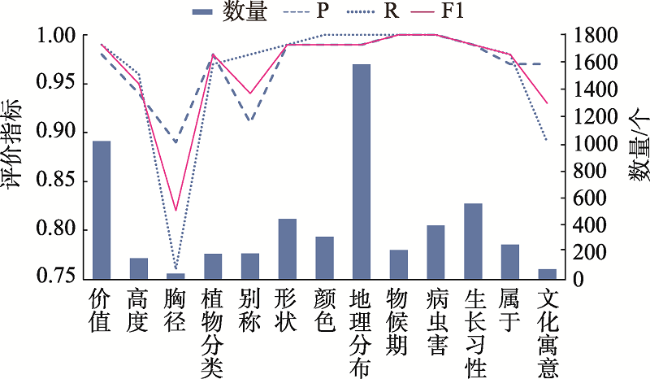
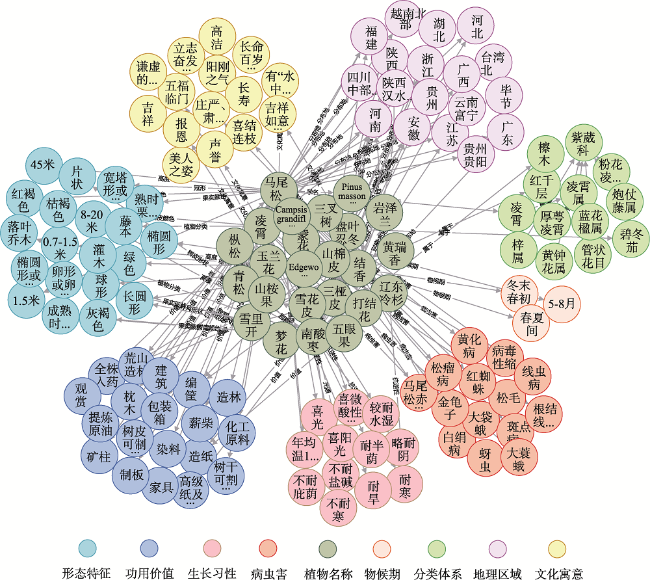
园林植物知识图谱可为顾及区域适应性、观赏性和生态性等因子的绿化树种的选型提供知识支持。植物描述文本的实体识别及关系抽取是知识图谱构建的关键环节。针对植物领域未有公开的标注数据集,本文阐述了园林植物数据集的构建流程,定义了园林植物的概念体系结构,完成了园林植物语料库的构建。针对现有Word2vec、ELMo和BERT等语言模型存在无法解决多义词、融合上下文能力差、运行速度慢等缺点,提出了嵌入ALBERT(A Lite BERT)预训练语言模型的实体识别和关系抽取模型。ALBERT预训练的动态词向量能够有效地表示文本特征,将其分别输入到BiGRU-CRF命名实体识别模型和BiGRU-Attention关系抽取模型中进行训练,进一步提升实体识别和关系抽取的效果。在园林植物语料库上进行方法的有效性验证,结果表明ALBERT-BiGRU-CRF命名实体识别模型的F1值为0.9517,ALBERT-BiGRU-Attention关系抽取模型的F1值为0.9161,相较于经典的语言模型(如Word2vec、ELMo和BERT等)性能有较为显著的提升。因此基于ALBERT模型的实体与关系抽取任务能有效提高识别分类效果,可将其应用于植物描述文本的实体关系抽取任务中,为园林植物知识图谱自动构建提供方法。
陈晓玲 , 唐丽玉 , 胡颖 , 江锋 , 彭巍 , 冯先超 . 基于ALBERT模型的园林植物知识实体与关系抽取方法[J]. 地球信息科学学报, 2021 , 23(7) : 1208 -1220 . DOI: 10.12082/dqxxkx.2021.200565
Knowledge graph of landscape plants provides potential uses in the selection of greening tree species considering regional adaptability, ornamental and ecological factors. Entity and relationship extraction of the plant's description text is a key issue in the construction of knowledge graph. Until now, there has been no publicly available annotated data set for the plant domain. In this paper, a conceptual architecture of landscape plants was defined and briefly described, and the landscape plant corpus was constructed. Existing language models such as word2vec, ELMo, and BERT have various disadvantages, e.g., they can't solve the problem of polysemous words and have poor ability of context fusion and computational efficiency. In this paper, we proposed a named entity recognition model, ALBERT-BiGRU-CRF, and a relationship extraction model, ALBERT-BiGRU-Attention, which were embedded with ALBERT (A Lite Bidirectional Encoder Representation from Transformers) pre-training language model. In the ALBERT-BiGRU-CRF model, the ALBERT model was used to extract text features, the Bi-GRU model was used to learn and excavate deep semantic features between sentences, and the CRF model was used to calculate the probability distribution of the annotation sequence to determine the entities contained in the description text. The ALBERT-BiGRU-Attention model was based on the results of the named entity recognition model. Similarly, the attention model was used to improve the weight of keywords to determine the relationship between entities. The proposed models have the following advantages: (1) The method can effectively identify and extract entities and relationships of landscape plants' knowledge; (2) The models can represent the semantic and sentence characteristics of characters with a good accuracy. The validity of the method was verified on the landscape plant corpus constructed in this paper and compared with other models. Our experimental results of quantitative evaluation show that: (1) The F1 index of the ALBERT-BiGRU-CRF model was 0.9517, indicating that it had good performance in named entity recognition task and can effectively identify 23 main entity types; (2) After comparative experiments and analysis of the relationship extraction results, the F1 index of the ALBERT-BiGRU-Attention model was 0.9161, indicating that it performed well in the relationship extraction of landscape plants; (3) By selecting 6 representative examples to further evaluate the extraction performance of this method, the results show that the method can well identify the knowledge triples of common single-relation and multi-relation texts. Therefore, the entity relationship extraction task based on ALBERT model can effectively improve the recognition and extraction results. It can be applied to the entity relationship extraction task of plant description text, providing a method for automatic construction of landscape plant knowledge graph.
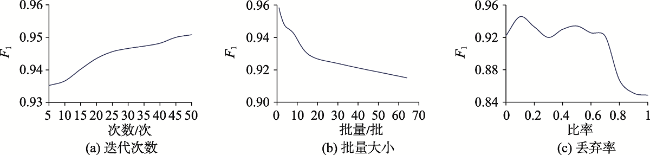
表1 不同实体识别模型对比实验结果Tab. 1 Comparison of experimental results of different entity recognition models |
| 实验模型 | 评价指标 | |||
|---|---|---|---|---|
| P | R | F1 | T/s | |
| 本文模型 | 0.9602 | 0.9442 | 0.9517 | 132.25 |
| ALBERT-BiGRU | 0.9354 | 0.9310 | 0.9321 | 128.71 |
| ALBERT-BiLSTM-CRF | 0.9642 | 0.9247 | 0.9402 | 129.85 |
| Word2vec-BiGRU-CRF | 0.9428 | 0.8450 | 0.8489 | 4.64 |
| ELMo-BiGRU-CRF | 0.9248 | 0.9035 | 0.9140 | 3160.11 |
| BERT-BiGRU-CRF | 0.9596 | 0.9419 | 0.9489 | 1458.26 |
表2 不同关系抽取模型对比实验结果Tab. 2 Comparison of experimental results of different relationship extraction models |
| 实验模型 | 评价指标 | |||
|---|---|---|---|---|
| P | R | F1 | T/s | |
| 本文模型 | 0.9328 | 0.9001 | 0.9161 | 603.31 |
| ALBERT-BiGRU | 0.8544 | 0.8326 | 0.8433 | 554.72 |
| Word2vec-BiGRU-Attention | 0.9010 | 0.8853 | 0.8929 | 5.26 |
| ELMo-BiGRU-Attention | 0.9123 | 0.9008 | 0.9065 | 8767.24 |
| BERT-BiGRU-Attention | 0.9177 | 0.8993 | 0.9084 | 3741.25 |
表3 不同示例三元组抽取结果Tab. 3 Different example triples extraction results |
| 示例 | 文本类型 | 抽取结果 |
|---|---|---|
| 1 | 单关系 | 正确结果: [沙枣]e1,中文名,价值其叶和果是羊的优质 [饲料]e1,工业价值,价值,羊四季均喜食 |
| 本文方法: [沙枣]e1,中文名,价值其叶和果是羊的优质 [饲料]e1,工业价值,价值,羊四季均喜食 | ||
| 2 | 多关系 | 正确结果: [黄蔷薇]e1,中文名,物候期|物候期花期 [5—6月]e2,花期,物候期,果期 [7—8月]e2,果期,物候期 |
| 本文方法: [黄蔷薇]1,中文名,物候期|物候期花期 [5—6月]e2,花期,物候期,果期 [7—8月]e2,果期,物候期 | ||
| 3 | 多关系 | 正确结果: [头花杜鹃]e1,中文名,植物分类|高度: [常绿小灌木]e2,生活型,植物分类,高 [0.5~1.5米]e2,高度,高度,分枝多,枝条直立而稠密 |
| 本文方法: [头花杜鹃]e1,中文名,植物分类|高度: [常绿小灌木]e2,生活型,植物分类,高 [0.5~1.5米]e2,高度,高度,分枝多,枝条直立而稠密 | ||
| 4 | 多关系 | 正确结果: [无梗五加]e1,中文名,形状|颜色果实 [倒卵状椭圆球形]e2,果实形状,形状, [黑色]e2,果实颜色,颜色,长1~1.5厘米,稍有棱,宿存花柱长达3毫米 |
| 本文方法: [无梗五加]ee1,中文名,形状|颜色果实 [倒卵状椭圆球形]e2,果实形状,形状, [黑色]e2,果实颜色,颜色,长1~1.5厘米,稍有棱,宿存花柱长达3毫米 | ||
| 5 | 多关系 | 正确结果: [花椒]e1,中文名,颜色|物候期|物候期果 [紫红色]e2,果实颜色,颜色,单个分果瓣散生微凸起的油点,顶端有甚短的芒尖或无; [4—5月]e2,花期,物候期开花, [8—9月或10月]e2,果期,物候期结果 |
| 本文方法: [花椒]e1,中文名,颜色|物候期|物候期果 [紫红色]e2,果实颜色,颜色,单个分果瓣散生微凸起的油点,顶端有甚短的芒尖或无; [4—5月]e2,花期,物候期开花, [8—9月或10月]e2,果期,物候期结果 | ||
| 6 | 复杂关系 | 正确结果:[[赤松]e1,中文名,病虫害 梢斑螟]e2,虫害名称,病虫害要危害幼林的球果、嫩梢和树干,造成种子产量下降、质量低劣 |
| 本文方法:[[赤松]e1,中文名 梢斑螟]要危害幼林的球果、嫩梢和树干,造成种子产量下降、质量低劣 |
| [1] |
王婉颖, 冯潇. 园林植物三维数字模型的构建与应用探索[J]. 风景园林, 2019, 26(12):103-108.
[
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
贺善安, 顾姻. 植物园发展战略研究[J]. 植物资源与环境学报, 2002(1):44-46.
[
|
| [7] |
|
| [8] |
陆锋, 余丽, 仇培元. 论地理知识图谱[J]. 地球信息科学学报, 2017, 19(6):723-734.
[
|
| [9] |
刘俊楠, 刘海砚, 陈晓慧, 等. 面向多源地理空间数据的知识图谱构建[J]. 地球信息科学学报, 2020, 22(7):1476-1486.
[
|
| [10] |
|
| [11] |
|
| [12] |
陈锦秀, 姬东鸿. 基于图的半监督关系抽取[J]. 软件学报, 2008(11):2843-2852.
[
|
| [13] |
鄂海红, 张文静, 肖思琪, 等. 深度学习实体关系抽取研究综述[J]. 软件学报, 2019, 30(6):1793-1818.
[
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
Xu, Kai, et al. Document-level attention-based BiLSTM-CRF incorporating disease dictionary for disease named entity recognition[J]. Computers in biology and medicine, 2019, 108:122-132.
|
| [19] |
杨培, 杨志豪, 罗凌, 等. 基于注意机制的化学药物命名实体识别[J]. 计算机研究与发展, 2018, 55(7):1548-1556.
[
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
叶育鑫, 薛环, 王璐, 等. 基于带噪观测的远监督神经网络关系抽取[J]. 软件学报, 2020, 31(4):1025-1038.
[
|
| [25] |
|
| [26] |
|
| [27] |
宁尚明, 滕飞, 李天瑞. 基于多通道自注意力机制的电子病历实体关系抽取[J]. 计算机学报, 2020, 43(5):916-929.
[
|
| [28] |
许晶航, 左万利, 梁世宁, 等. 基于图注意力网络的因果关系抽取[J]. 计算机研究与发展, 2020, 57(1):159-174.
[
|
| [29] |
|
| [30] |
杜鹏, 丁世飞. 基于混合词向量深度学习模型的DGA域名检测方法[J]. 计算机研究与发展, 2020, 57(2):433-446.
[
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
李冬梅, 檀稳. 植物属性文本的命名实体识别方法研究[J]. 计算机科学与探索, 2019, 13(12):2085-2093.
[
|
| [38] |
刘建华, 王颖, 张智雄, 等. 植物物种多样性语义知识抽取研究[J]. 数据分析与知识发现, 2017, 1(1):37-46.
[
|
| [39] |
潘远智, 车代弟. 风景园林植物学[M]. 北京: 中国林业出版社, 2018.
[
|
| [40] |
冯志坚. 园林植物学:南方版[M]. 重庆: 重庆大学出版社, 2013.
[
|
| [41] |
孙世洲. 关于中国国家自然地图集中的中国植被区划图[J]. 植物生态学报, 1998(6):44-46, 48-58.
[
|
| [42] |
蒋高明. 植物生理生态学[M]. 北京: 高等教育出版社, 2004.
[
|
| [43] |
苏雪痕. 植物景观规划设计[M]. 北京: 中国林业出版社, 2012.
[
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}